Discrete Mathematics
arXiv:cs.DM
Covers combinatorics, graph theory, applications of probability. Roughly includes material in ACM Subject Classes G.2 and G.3.
Covers combinatorics, graph theory, applications of probability. Roughly includes material in ACM Subject Classes G.2 and G.3.
Erdős and Lov'asz asked whether there exists a "3-critical" 3-uniform hypergraph in which every vertex has degree at least 7. The original formulation does not specify what 3-critical means, and two non-equivalent notions have appeared in the literature and in later discussions of the problem. In this paper we resolve the question under both interpretations. For the transversal interpretation (criticality with respect to the transversal number), we prove that a 3-uniform hypergraph $H$ with $τ(H)=3$ and $τ(H-e)=2$ for every edge $e$ has at most 10 edges; in particular, $δ(H)\le 6$, and this bound is sharp, witnessed by the complete 3-graph $K^{(3)}_5$. For the chromatic interpretation (criticality with respect to weak vertex-colourings), we give an explicit 3-uniform hypergraph on 9 vertices with $χ(H)=3$ and minimum degree $δ(H)=7$ such that deleting any single edge or any single vertex makes it 2-colourable. The criticality of the example is certified by explicit witness 2-colourings listed in the appendices, together with a short verification script.
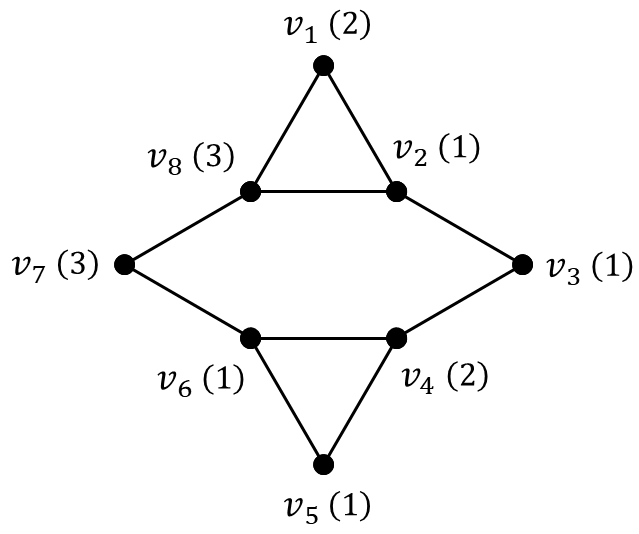
A Roman dominating function for a (non-weighted) graph $G=(V,E)$, is a function $f:V\rightarrow \{0,1,2\}$ such that every vertex $u\in V$ with $f(u)=0$ has at least {one} neighbor $v\in V$ such that $f(v)=2$. The minimum weight $\sum_{v\in V}f(v)$ of a Roman {dominating function} $f$ on $G$ is called the Roman domination number of $G$ and is denoted by $γ_{R}(G)$. A graph {$G= (V,E)$} together with a positive real-valued weight-function $w:V\rightarrow \mathbf{R}^{>0}$ is called a {\it weighted graph} and is denoted by $(G;w)$. The minimum weight $\sum_{v\in V}f(v)w(v)$ of a Roman {dominating function} $f$ on $G$ is called the weighted Roman domination number of $G$ and is denoted by $γ_{wR}(G)$. The domination and Roman domination numbers of unweighted graphs have been extensively studied, particularly for their applications in bioinformatics and computational biology. However, graphs used to model biomolecular structures often require weights to be biologically meaningful. In this paper, we initiate the study of the weighted Roman domination number in weighted graphs. We first establish several bounds for this parameter and present various realizability results. Furthermore, we determine the exact values for several well-known graph families and demonstrate an equivalence between the weighted Roman domination number and the differential of a weighted graph.

For some geometric graph classes, tractability of testing first-order formulas is precisely characterised by the graph parameter twin-width. This was first proved for interval graphs among others in [BCKKLT, IPEC '22], where the equivalence is called delineation, and more generally holds for circle graphs, rooted directed path graphs, and $H$-graphs when $H$ is a forest. Delineation is based on the key idea that geometric graphs often admit natural vertex orderings, allowing to use the very rich theory of twin-width for ordered graphs. Answering two questions raised in their work, we prove that delineation holds for intersection graphs of non-degenerate axis-parallel unit segment graphs, but fails for visibility graphs of 1.5D terrains. We also prove delineation for intersection graphs of circular arcs.
Vizing's theorem states that every simple undirected graph can be edge-colored using fewer than $Δ+ 1$ colors, where $Δ$ is the graph's maximum degree. The original proof was given through a polynomial-time algorithmic procedure that iteratively extends a partial coloring until it becomes complete. In this work, I used the Lean theorem prover to produce a verified implementation of the Misra and Gries edge-coloring algorithm, a modified version of Vizing's original method. The focus is on building libraries for relevant mathematical objects and rigorously maintaining required invariants.

We show how the software Walnut can be used to obtain concise proofs of results concerning variants of the famous Wythoff game, in which blocking maneuvers or terminal positions are added, as discussed respectively by Larsson (2011) and Komak et al. (2025). Our approach provides automatic proofs that both confirm and extend their results, and the same techniques apply to newly introduced variants as well. Then, using classic techniques, we obtain new recursive and morphic characterizations of Wythoff-type games where the set of terminal positions $(x,y)$ satisfy $x+y\le\ell$. The use of Walnut in combinatorial game theory is relatively recent, and only a few examples have been explored so far. The Wythoff game, being directly connected to the Fibonacci numeration system, proves especially well-suited to this kind of approach. It permits us to solve instances for a fixed value of a parameter.

In this article, we give two extended space formulations, respectively, for the induced tree and path polytopes of chordal graphs with vertex and edge variables. These formulations are obtained by proving that the induced tree and path extended incidence vectors of chordal graphs form Hilbert basis. This also shows that both polytopes have the integer decomposition property in chordal graphs. Whereas the formulation for the induced tree polytope is easily seen to have a compact size, the system we provide for the induced path polytope has an exponential number of inequalities. We show which of these inequalities define facets and exhibit a superset of the facet-defining ones that can be enumerated in polynomial time. We show that for some graphs, the latter superset contains redundant inequalities. As corollaries, we obtain that the problems of finding an induced tree or path maximizing a linear function over the edges and vertices are solvable in polynomial time for the class of chordal graphs.

Given an input graph and weights on its vertices, the maximum co-2-plex problem is to find a subset of vertices maximizing the sum of their weights and inducing a graph of degree at most 1. In this article, we analyze polyhedral aspects of the maximum co-2-plex problem. The co-2-plexes of a graph are known to be in bijection with the stable sets of an auxiliary graph called the utter graph~\cite{dupontbouillard2024contractions}. We use this bijection to characterize contraction perfect graphs' co-2-plex polytopes in an extended space. It turns out that the total dual integrality of the associated linear system also characterizes contraction perfectness of the input graph. By projecting this extended space formulation, we obtain the natural variable space description of the co-2-plex polytopes of trees. This projection yields a new family of valid inequalities for the co-2-plex polytope and we characterize when they define facets. Moreover, we show that these inequalities can be separated in polynomial time. We characterize the graphs for which this formulation describes an integer polytope. These linear systems are extended to valid integer linear programs (ILPs) for the maximum co-2-plex problem whose linear relaxation values are tighter than the state of the art for this problem~\cite{bala}. Finally, we provide an experimental comparison of several implementations of our new ILP formulations with the state-of-the-art ILP for this problem and analyze their respective performances relatively to the density of the input graphs.

The mim-width of a graph is a powerful structural parameter that, when bounded by a constant, allows several hard problems to be polynomial-time solvable - with a recent meta-theorem encompassing a large class of problems [SODA2023]. Since its introduction, several variants such as sim-width and omim-width were developed, along with a linear version of these parameters. It was recently shown that mim-width and all these variants all paraNP-hard, a consequence of the NP-hardness of distinguishing between graphs of linear mim-width at most 1211 and graphs of sim-width at least 1216 [ICALP2025]. The complexity of recognizing graphs of small width, particularly those close to $1$, remained open, despite their especially attractive algorithmic applications. In this work, we show that the width recognition problems remain NP-hard even on small widths. Specifically, after introducing the novel parameter Omim-width sandwiched between omim-width and mim-width, we show that: (1) deciding whether a graph has sim-width = 1, omim-width = 1, or Omin-width = 1 is NP-hard, and the same is true for their linear variants; (2) the problems of deciding whether mim-width $\leq$ 2 or linear mim-width $\leq$ 2 are both NP-hard. Interestingly, our reductions are relatively simple and are from the Unrooted Quartet Consistency problem, which is of great interest in computational biology but is not commonly used (if ever) in the theory of algorithms.

In this work we take a step towards characterising strongly flip-flat classes of graphs. Strong flip-flatness appears to be the analogue of uniform almost-wideness in the setting of dense classes of graphs. We prove that strongly flip-flat classes of graphs that are weakly sparse are indeed uniformly almost-wide.

We prove that the lonely runner conjecture holds for nine runners. Our proof is based on a couple of improvements of the method we used to prove the conjecture for eight runners.
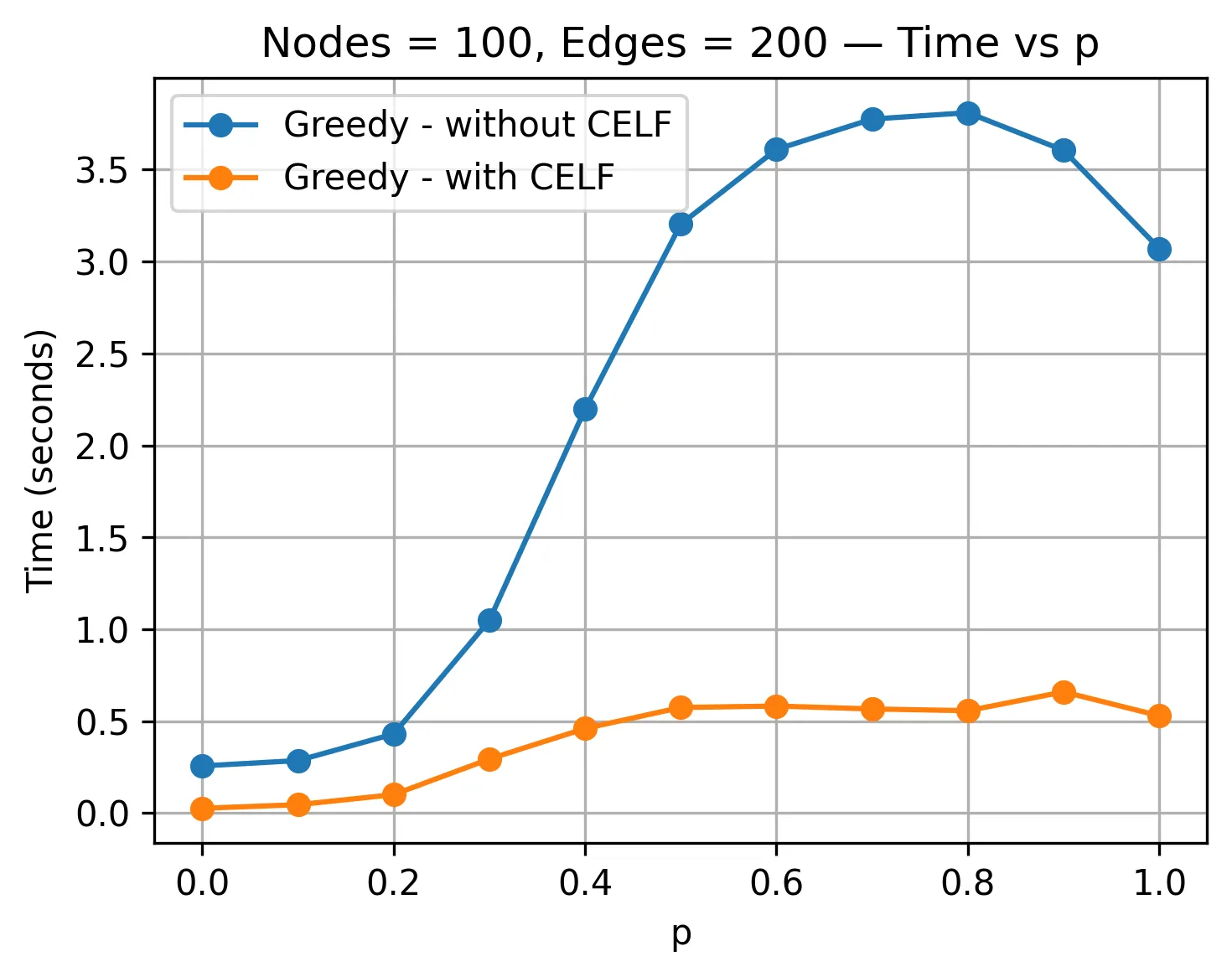
Given a network, the critical node detection problem finds a subset of nodes whose removal disrupts the network connectivity. Since many real-world systems are naturally modeled as graphs, assessing the vulnerability of the network is essential, with applications in transportation systems, traffic forecasting, epidemic control, and biological networks. In this paper, we consider a stochastic version of the critical node detection problem, where the existence of edges is given by certain probabilities. We propose heuristics and learning-based methods for the problem and compare them with existing algorithms. Experimental results performed on random graphs from small to larger scales, with edge-survival probabilities drawn from different distributions, demonstrate the effectiveness of the methods. Heuristic methods often illustrate the strongest results with high scalability, while learning-based methods maintain nearly constant inference time as the network size and density grow.

In this paper we deal with a subclass of chordal graphs, which are simultaneously strictly chordal and interval, the strictly interval graphs. We present a new characterization of the class that leads to a simple linear recognition algorithm. Next we introduce a new subclass of strictly interval graphs, the $SI$-core graphs, that are non-split and non-cograph graphs and show that several elements of the new class are Laplacian integral.

Determining the complexity of colouring ($4K_1, C_4$)-free graph is a long open problem. Recently Penev showed that there is a polynomial-time algorithm to colour a ($4K_1, C_4, C_6$)-free graph. In this paper, we will prove that if $G$ is a ($4K_1, C_4, P_6$)-free graph that contains a $C_6$, then $G$ has bounded clique-width. To this purpose, we use a new method to bound the clique-width, that is of independent interest. As a consequence, there is a polynomial-time algorithm to colour ($4K_1, C_4, P_6$)-free graphs.
We introduce a fun problem that can be considered as a variant of the classic birthday problem, the Bottleneck Birthday Problem (BBP). It is stated as: what is the maximum number of people we have to choose so that no day of the year has more than $r \geq 1$ birthdays incident on it with probability at least 1/2? We provide a survey of techniques used in the literature on occupancy and load balancing problems to derive recurrence relations for exact computation of the probability and the number of people, keeping probability fixed at a threshold. Further, we show that restricted Stirling numbers of the second kind can be used to derive an additional recurrence, in a novel way. We provide numerical results from an implementation of the recurrences.

This work presents conjectures about eigenvalues of matrices associated with $k$-path graphs, the algebraic connectivity, defined as the second smallest eigenvalue of the Laplacian matrix, and the $α$-index, as the largest eigenvalue of the $A_α$-matrix. For this purpose, a process based in Pereira et al., is presented to generate lists of $k$-path graphs containing all non-isomorphic 2-paths, 3-paths, and 4-paths of order $n$, for $6 \leq n \leq 26, 8 \leq n \leq 19$, and $10 \leq n \leq 18$, respectively. Using these lists, exhaustive searches for extremal graphs of fixed order for the mentioned eigenvalues were performed. Based on the empirical results, conjectures are suggested about the structure of extremal $k$-path graphs for these eigenvalues.

Given a language, which in this article is a set of strings of some fixed length, we study the problem of producing its elements by a procedure in which each position has its own local rule. We introduce a way of measuring how much communication is needed between positions. The communication structure is captured by a simplicial complex whose vertices are the positions and the simplices are the communication channels between positions. The main problem is then to identify the simplicial complexes that can be used to generate a given language. We develop the theory and apply it to a number of languages.
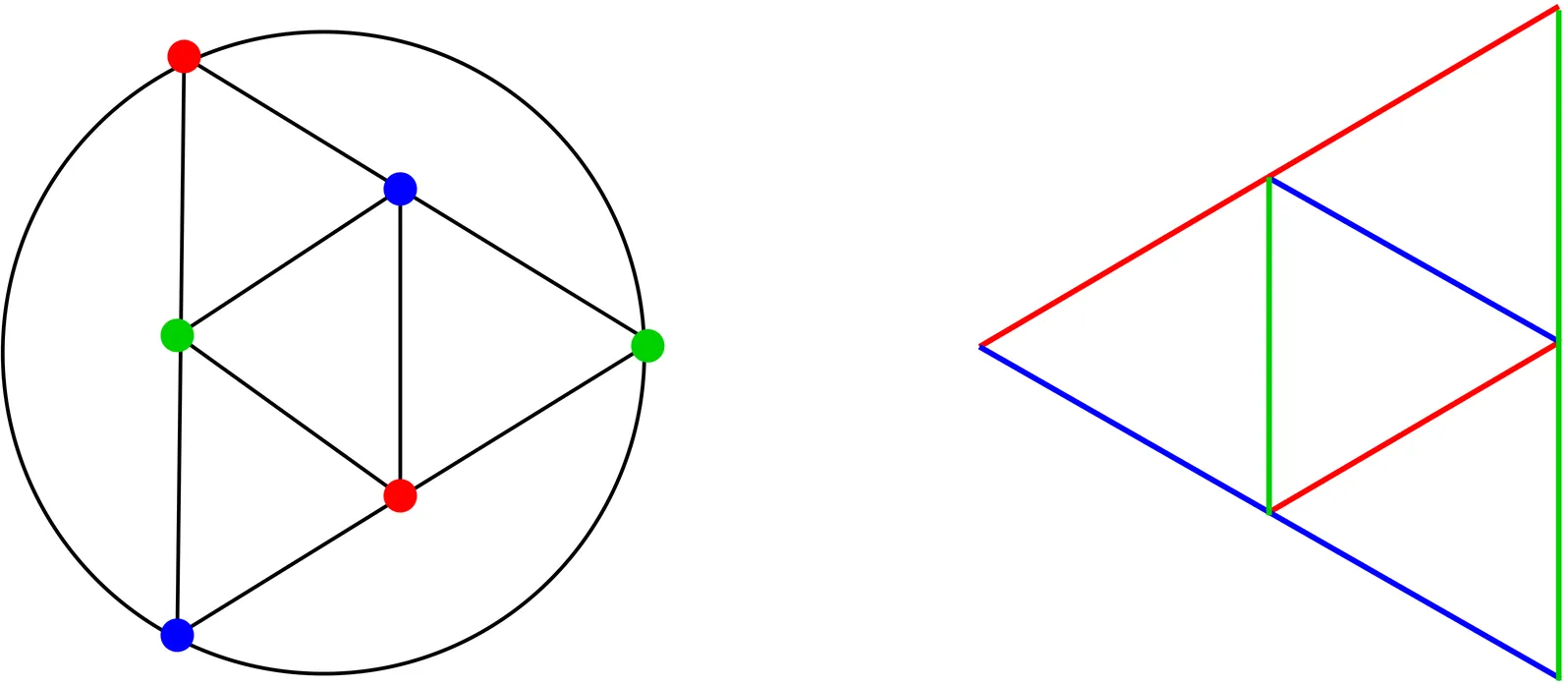
In his PhD Thesis, E.R. Scheinerman conjectured that planar graphs are intersection graphs of line segments in the plane. This conjecture was proved with two different approaches by J. Chalopin and the author, and by the author, L. Isenmann, and C. Pennarun. In the case of 3-colorable planar graphs E.R. Scheinerman conjectured that it is possible to restrict the set of slopes used by the segments to only 3 slopes. Here we prove this conjecture by using an approach introduced by S. Felsner to deal with contact representations of planar graphs with homothetic triangles.

Topological indices are graph-theoretic descriptors that play a crucial role in mathematical chemistry, capturing the structural characteristics of molecules and enabling the prediction of their physicochemical properties. A widely studied category of topological indices, known as degree-based topological indices, are calculated as the sum of the weights of a graph's edges, where each edge weight is determined by a formula that depends solely on the degrees of its endpoints. This work focuses exclusively on chemical graphs in which no vertex has a degree greater than 3, a model for conjugated systems. Within a polyhedral framework, each chemical graph is mapped to a point in a three-dimensional space, enabling extremal values of any degree-based topological index to be determined through linear optimization over the corresponding polyhedron. Analysis within this framework reveals that extremality is limited to a small subset of chemical graph families, implying that certain chemical graphs can never attain extremality for any degree-based topological index. The main objective of this paper is to present ChemicHull, an online tool we have developed to determine and display extremal chemical graphs for arbitrary degree-based topological indices. To illustrate the power of this tool, we easily recover established results, emphasizing its effectiveness for chemically significant graph classes such as chemical trees and unicyclic chemical graphs. This tool also enabled the identification of a counterexample to a previously published extremal result concerning the Randić index.
We investigate a process of joining $k$ random spanning trees on a fixed clique $K_n$. The joined trees may not be disjoint and multiple edges are replaced by one simple edge. This process produces a simple graph $G$ on $n$~vertices with an edge set, which is a union of edge sets of the joined trees. We study a random variable $S_{k}$ of the number of edges in the generated graph $G$. The exact formula is derived for the expected value of the random variable $S_{k}$. In addition, an upper bound on the concentration coefficient of the random variable $S_{k}$ is provided. We use results of our analysis to design an algorithm to generate $k$-edge connected graphs for arbitrarily large values of $k \geq 2$. The designed algorithm solves a particular case of the Survivable Network Design Problem, where the cost of each edge is $c_{e} = 1$ and the connectivity requirement for each pair of vertices $u, v \in V(G)$ is $k$.The proposed algorithm is within a factor strictly less than $2$ of the optimal value (i.e., the number of edges in the generated graph) and its running time is $O(kn\log{n})$.

The Graph Burning Problem (GBP) is a combinatorial optimization problem that has gained relevance as a tool for quantifying a graph's vulnerability to contagion. Although it is based on a very simple propagation model, its decision version is NP-complete, and its optimization version is NP-hard. Many of its theoretical properties across different graph families have been thoroughly explored, and numerous interesting variants have been proposed. This paper reports novel mathematical programs for the optimization version of the classical GBP. Among the presented programs are a Mixed-Integer Linear Program (MILP), a Constraint Satisfaction Problem (CSP), two Integer Linear Programs (ILP), and two Quadratic Unconstrained Binary Optimization (QUBO) problems. Most optimization solvers can handle these, being QUBO problems of a capital interest in quantum computing. The primary aim of this paper is to gain a comprehensive understanding of the GBP by examining its different formulations. Compared to other mathematical programs from the literature, the ones presented here are conceptually simpler and involve fewer variables. These make them more practical for finding optimal solutions using optimization algorithms and solvers, as we show by solving some instances with millions of vertices in just a few minutes.
In his PhD Thesis, E.R. Scheinerman conjectured that planar graphs are intersection graphs of line segments in the plane. This conjecture was proved with two different approaches by J. Chalopin and the author, and by the author, L. Isenmann, and C. Pennarun. In the case of 3-colorable planar graphs E.R. Scheinerman conjectured that it is possible to restrict the set of slopes used by the segments to only 3 slopes. Here we prove this conjecture by using an approach introduced by S. Felsner to deal with contact representations of planar graphs with homothetic triangles.
We study two graph parameters defined via tree decompositions: tree-independence number and induced matching treewidth. Both parameters are defined similarly as treewidth, but with respect to different measures of a tree decomposition $\mathcal{T}$ of a graph $G$: for tree-independence number, the measure is the maximum size of an independent set in $G$ included in some bag of $\mathcal{T}$, while for the induced matching treewidth, the measure is the maximum size of an induced matching in $G$ such that some bag of $\mathcal{T}$ contains at least one endpoint of every edge of the matching. While the induced matching treewidth of any graph is bounded from above by its tree-independence number, the family of complete bipartite graphs shows that small induced matching treewidth does not imply small tree-independence number. On the other hand, Abrishami, Briański, Czyżewska, McCarty, Milanič, Rzążewski, and Walczak~[SIAM Journal on Discrete Mathematics, 2025] showed that, if a fixed biclique $K_{t,t}$ is excluded as an induced subgraph, then the tree-independence number is bounded from above by some function of the induced matching treewidth. The function resulting from their proof is exponential even for fixed $t$, as it relies on multiple applications of Ramsey's theorem. In this note we show, using the Kövári-Sós-Turán theorem, that for any class of $K_{t,t}$-free graphs, the two parameters are in fact polynomially related.
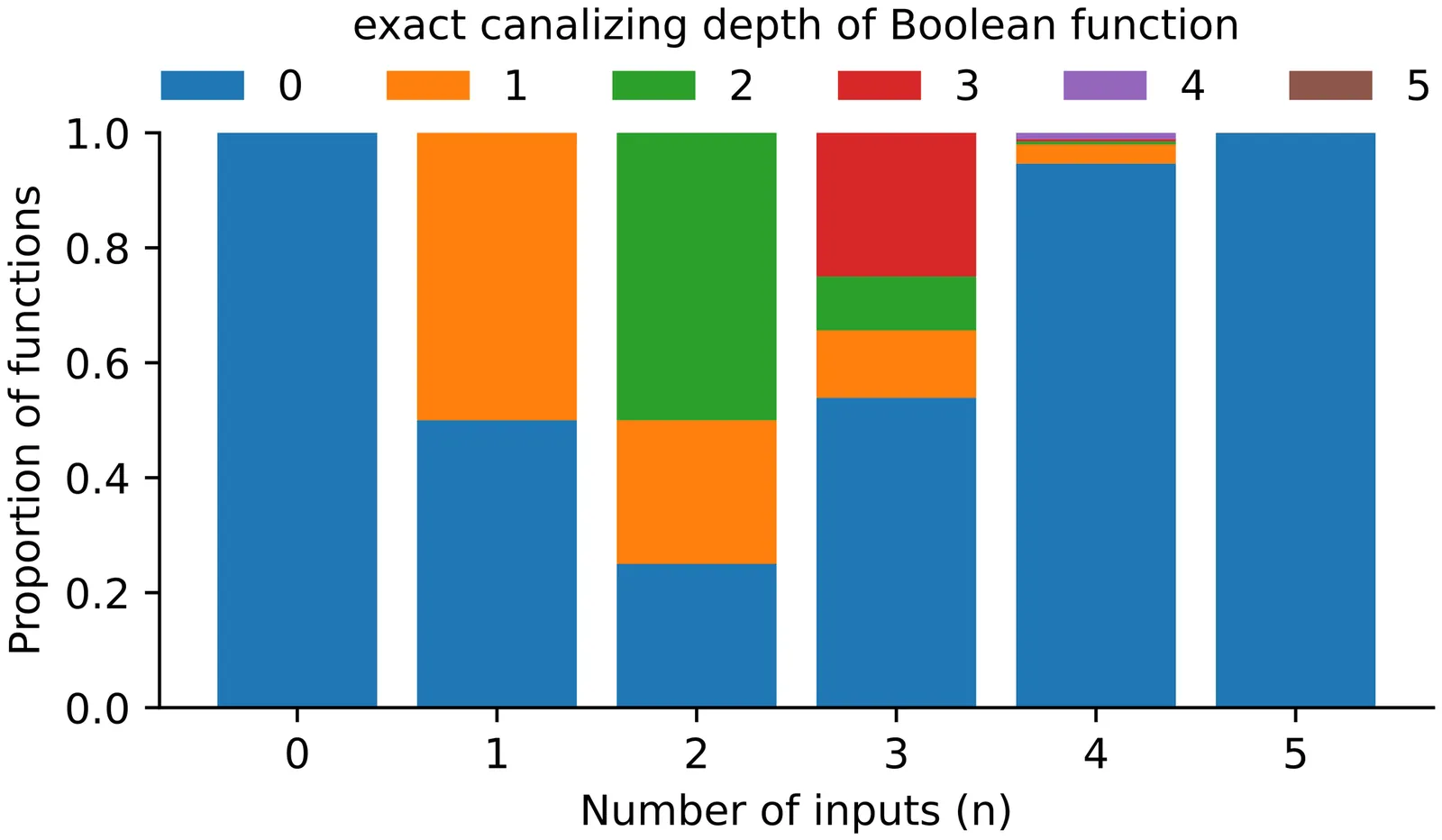
Canalization is a key organizing principle in complex systems, particularly in gene regulatory networks. It describes how certain input variables exert dominant control over a function's output, thereby imposing hierarchical structure and conferring robustness to perturbations. Degeneracy, in contrast, captures redundancy among input variables and reflects the complete dominance of some variables by others. Both properties influence the stability and dynamics of discrete dynamical systems, yet their combinatorial underpinnings remain incompletely understood. Here, we derive recursive formulas for counting Boolean functions with prescribed numbers of essential variables and given canalizing properties. In particular, we determine the number of non-degenerate canalizing Boolean functions -- that is, functions for which all variables are essential and at least one variable is canalizing. Our approach extends earlier enumeration results on canalizing and nested canalizing functions. It provides a rigorous foundation for quantifying how frequently canalization occurs among random Boolean functions and for assessing its pronounced over-representation in biological network models, where it contributes to both robustness and to the emergence of distinct regulatory roles.
We study the relationship between discrete analogues of Ricci and scalar curvature that are defined for point clouds and graphs. In the discrete setting, Ricci curvature is replaced by Ollivier-Ricci curvature. Scalar curvature can be computed as the trace of Ricci curvature for a Riemannian manifold; this motivates a new definition of a scalar version of Ollivier-Ricci curvature. We show that our definition converges to scalar curvature for nearest neighbor graphs obtained by sampling from a manifold. We also prove some new results about the convergence of Ollivier-Ricci curvature to Ricci curvature.

We prove that for every surface $Σ$, the class of Eulerian directed graphs that are Eulerian embeddable into $Σ$ (in particular they have degree at most $4$) is well-quasi-ordered by strong immersion. This result marks one of the most versatile directed graph classes (besides tournaments) for which we are aware of a positive well-quasi-ordering result regarding a well-studied graph relation. Our result implies that the class of bipartite circle graphs is well-quasi-ordered under the pivot-minor relation. Furthermore, this also yields two other interesting applications, namely, a polynomial-time algorithm for testing immersion closed properties of Eulerian-embeddable graphs into a fixed surface, and a characterisation of the Erdős-Pósa property for Eulerian digraphs of maximum degree four. Further, in order to prove the mentioned result, we prove that Eulerian digraphs of carving width bounded by some constant $k$ (which correspond to Eulerian digraphs with bounded treewidth and additionally bounded degree) are well-quasi-ordered by strong immersion. We actually prove a stronger result where we allow for vertices of the Eulerian digraphs to be labeled by elements of some well-quasi-order $Ω$. We complement these results with a proof that the class of Eulerian planar digraphs of treewidth at most $3$ is not well-quasi-ordered by strong immersion, noting that any antichain of bounded treewidth cannot have bounded degree.

We prove that the active-set method needs an exponential number of iterations in the worst-case to maximize a convex quadratic function subject to linear constraints, regardless of the pivot rule used. This substantially improves over the best previously known lower bound [IPCO 2025], which needs objective functions of polynomial degrees $ω(\log d)$ in dimension $d$, to a bound using a convex polynomial of degree 2. In particular, our result firmly resolves the open question [IPCO 2025] of whether a constant degree suffices, and it represents significant progress towards linear objectives, where the active-set method coincides with the simplex method and a lower bound for all pivot rules would constitute a major breakthrough. Our result is based on a novel extended formulation, recursively constructed using deformed products. Its key feature is that it projects onto a polygonal approximation of a parabola while preserving all of its exponentially many vertices. We define a quadratic objective that forces the active-set method to follow the parabolic boundary of this projection, without allowing any shortcuts along chords corresponding to edges of its full-dimensional preimage.

In the field of constraint satisfaction problems (CSP), a clause is called redundant if its satisfaction is implied by satisfying all other clauses. An instance of CSP$(P)$ is called non-redundant if it does not contain any redundant clause. The non-redundancy (NRD) of a predicate $P$ is the maximum number of clauses in a non-redundant instance of CSP$(P)$, as a function of the number of variables $n$. Recent progress has shown that non-redundancy is crucially linked to many other important questions in computer science and mathematics including sparsification, kernelization, query complexity, universal algebra, and extremal combinatorics. Given that non-redundancy is a nexus for many of these important problems, the central goal of this paper is to more deeply understand non-redundancy. Our first main result shows that for every rational number $r \ge 1$, there exists a finite CSP predicate $P$ such that the non-redundancy of $P$ is $Θ(n^r)$. Our second main result explores the concept of conditional non-redundancy first coined by Brakensiek and Guruswami [STOC 2025]. We completely classify the conditional non-redundancy of all binary predicates (i.e., constraints on two variables) by connecting these non-redundancy problems to the structure of high-girth graphs in extremal combinatorics. Inspired by these concrete results, we build off the work of Carbonnel [CP 2022] to develop an algebraic theory of conditional non-redundancy. As an application of this algebraic theory, we revisit the notion of Mal'tsev embeddings, which is the most general technique known to date for establishing that a predicate has linear non-redundancy. For example, we provide the first example of predicate with a Mal'tsev embedding that cannot be attributed to the structure of an Abelian group, but rather to the structure of the quantum Pauli group.

Given a set of source-sink pairs, the maximum multiflow problem asks for the maximum total amount of flow that can be feasibly routed between them. The minimum multicut, a dual problem to multiflow, seeks the minimum-cost set of edges whose removal disconnects all the source-sink pairs. It is easy to see that the value of the minimum multicut is at least that of the maximum multiflow, and their ratio is called the multiflow-multicut gap. The classical max-flow min-cut theorem states that when there is only one source-sink pair, the gap is exactly one. However, in general, it is well known that this gap can be arbitrarily large. In this paper, we study this gap for classes of planar graphs and establish improved lower bound results. In particular, we show that this gap is at least $\frac{16}{7}$ for the class of planar graphs, improving upon the decades-old lower bound of 2. More importantly, we develop new techniques for proving such a lower bound, which may be useful in other settings as well.

Simplicial complexes are extensively studied in the field of algebraic topology. They have gained attention in recent time due to their applications in fields like theoretical distributed computing and simplicial neural networks. Graphs are mono-dimensional simplicial complex. Graph theory has application in topics like theoretical computer science, operations research, bioinformatics and social sciences. This makes it natural to try to adapt graph-theoretic results for simplicial complexes, which can model more intricate and detailed structures appearing in real-world systems. Though seemingly obvious, we did not find any previous work that looked into this prospect of simplicial complexes. In this article, we define the concept of weighted simplicial complex and $d$-path in a simplicial complex. Both these concepts have the potential to have numerous real-life applications. We start by adapting the Depth-First Search and Breadth-First Search algorithms for our setup. Next, we provide two novel algorithms to find the shortest paths in a weighted simplicial complex. The core principles of our algorithms align with those of Dijkstra$^\prime$s algorithm and Bellman-Ford algorithm for graphs. Hence, this work lays a building block for the sake of integrating graph-theoretic concepts with abstract simplicial complexes.
Treewidth is an important structural graph parameter that quantifies how closely a graph resembles a tree-like structure. It has applications in many algorithmic and combinatorial problems. In this paper, we study the treewidth of outer $k$-planar graphs, that is, graphs admitting a convex drawing (a straight-line drawing where all vertices lie on a circle) in which every edge crosses at most $k$ other edges. We also consider the more general class of outer min-$k$-planar graphs, which are graphs admitting a convex drawing where for every crossing of two edges at least one of these edges is crossed at most $k$ times. Firman, Gutowski, Kryven, Okada and Wolff [GD 2024] proved that every outer $k$-planar graph has treewidth at most $1.5k+2$ and provided a lower bound of $k+2$ for even $k$. We establish a lower bound of $1.5k+0.5$ for every odd $k$. Additionally, they showed that every outer min-$k$-planar graph has treewidth at most $3k+1$. We improve this upper bound to $3 \cdot \lfloor k/2 \rfloor+4$. Our approach also allows us to upper bound the separation number, a parameter closely related to treewidth, of outer min-$k$-planar graphs by $2 \cdot \lfloor k/2 \rfloor+4$. This improves upon the previous bound of $2k+1$ and achieves a bound with an optimal multiplicative constant.
Temporal graphs are graphs whose edges are labelled with times at which they are active. Their time-sensitivity provides a useful model of real networks, but renders many problems studied on temporal graphs more computationally complex than their static counterparts. To contend with this, there has been recent work devising parameters for which temporal problems become tractable. One such parameter is vertex-interval-membership (VIM) width. Broadly, this gives a bound on the number of vertices we need to keep track of at any given time to solve many problems. Our contributions are two-fold. Firstly, we introduce a new parameter, tree-interval-membership (TIM) width, that generalises both VIM width and several existing generalisations. Secondly, we provide meta-algorithms for both VIM and TIM width which can be used to prove fixed-parameter-tractability for large families of problems, bypassing the need to give involved dynamic programming arguments for every problem. In doing this, we provide a characterisation of problems in FPT with respect to both parameters. We apply these algorithms to temporal versions of Hamiltonian path, dominating set, matching, and edge deletion to limit maximum reachability.
We prove the following asymptotically tight lower bound for $k$-color discrepancy: For any $k \geq 2$, there exists a hypergraph with $n$ hyperedges such that its $k$-color discrepancy is at least $Ω(\sqrt{n})$. This improves on the previously known lower bound of $Ω(\sqrt{n/\log k})$ due to Caragiannis et al. (arXiv:2502.10516). As an application, we show that our result implies improved lower bounds for group fair division.
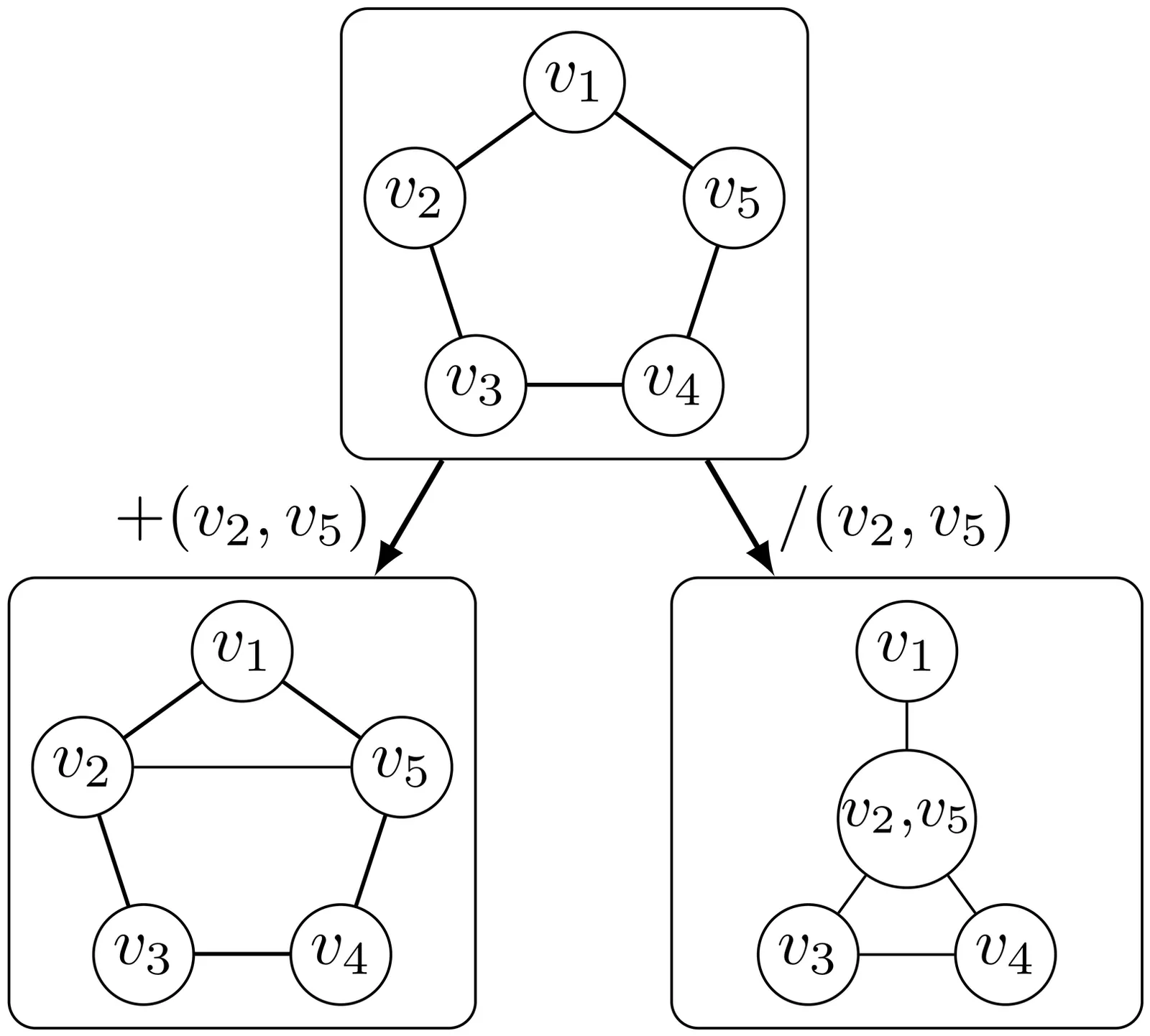
We introduce ZykovColor, a novel SAT-based algorithm to solve the graph coloring problem working on top of an encoding that mimics the Zykov tree. Our method is based on an approach of Hébrard and Katsirelos (2020) that employs a propagator to enforce transitivity constraints, incorporate lower bounds for search tree pruning, and enable inferred propagations. We leverage the recently introduced IPASIR-UP interface for CaDiCaL to implement these techniques with a SAT solver. Furthermore, we propose new features that take advantage of the underlying SAT solver. These include modifying the integrated decision strategy with vertex domination hints and using incremental bottom-up search that allows to reuse learned clauses from previous calls. Additionally, we integrate a more effective clique computation and an algorithm for computing the fractional chromatic number to improve the lower bounds used for pruning during the search. We validate the effectiveness of each new feature through an experimental analysis. ZykovColor outperforms other state-of-the-art graph coloring implementations on the DIMACS benchmark set. Further experiments on random Erdős-Rényi graphs show that our new approach matches or outperforms state-of-the-art SAT-based methods for both very sparse and highly dense graphs. We give an additional configuration of ZykovColor that dominates other SAT-based methods on the Erdős-Rényi graphs.
The \emph{$r$-neighbourhood complexity} of a graph $G$ is the function counting, for a given integer $k$, the largest possible number, over all vertex-subsets $A$ of size $k$, of subsets of $A$ realized as the intersection between the $r$-neighbourhood of some vertex and $A$. A~refinement of this notion is the \emph{$r$-profile complexity}, that counts the maximum number of distinct distance-vectors from any vertex to the vertices of $A$, ignoring distances larger than~$r$. Typically, in structured graph classes such as graphs of bounded VC-dimension or chordal graphs, these functions are bounded, leading to insights into their structural properties and efficient algorithms. We improve existing bounds on the $r$-profile complexity (and thus on the $r$-neighbourhood complexity) for graphs in several structured graph classes. We show that the $r$-profile complexity of graphs excluding $K_h$ as a minor is in $O_h(r^{3h-3}k)$. For graphs of treewidth at most~$t$, we give a bound in $O_t(r^{t+1}k)$, which is tight up to a function of~$t$ as a factor. These bounds improve results of Joret and Rambaud and answer a question of their paper [Combinatorica, 2024]. We also apply our methods to other classes of bounded expansion such as graphs excluding a fixed complete graph as a subdivision. For outerplanar graphs, we can improve our treewidth bound by a factor of $r$ and conjecture that a similar improvement holds for graphs with bounded simple treewidth. For graphs of treelength at most~$\ell$, we give the upper bound of $O(k(r^2(\ell+1)^k))$, which we improve to $O\left (k\cdot (r 2^k + r^2k^2) \right)$ in the case of chordal graphs and $O(k^2r)$ for interval graphs. Our bounds also imply relations between the order, diameter and metric dimension of graphs in these classes, improving results from [Beaudou et al., SIDMA 2017].

In 2023, two striking, nearly simultaneous, mathematical discoveries have excited their respective communities, one by Greenfeld and Tao, the other (the Hat tile) by Smith, Myers, Kaplan and Goodman-Strauss, which can both be summed up as the following: there exists a single tile that tiles, but not periodically (sometimes dubbed the einstein problem). The two settings and the tools are quite different (as emphasized by their almost disjoint bibliographies): one in euclidean geometry, the other in group theory. Both are highly nontrivial: in the first case, one allows complex shapes; in the second one, also the space to tile may be complex. We propose here a framework that embeds both of these problems. From any tile system in this general framework, with some natural additional conditions, we exhibit a construction to simulate it by a group-theoretical tiling. We illustrate our setting by transforming the Hat tile into a new aperiodic group monotile, and we describe the symmetries of both the geometrical Hat tilings and the group tilings we obtain.

We study decision problems on geometric tilings. First, we study a variant of the Domino problem where square tiles are replaced by geometric tiles of arbitrary shape. We show that this variant is undecidable regardless of the shapes, extending previous results on rhombus tiles. This result holds even when the geometric tiling is forced to belong to a fixed set. Second, we consider the problem of deciding whether a geometric subshift has finite local complexity, which is a common assumption when studying geometric tilings. We show that this problem is undecidable even in a simple setting (square shapes with small modifications).

We perform intensive computations of Generalised Langton's Ants, discovering rules with a big number of highways. We depict the structure of some of them, formally proving that the number of highways which are possible for a given rule does not need to be bounded, moreover it can be infinite. The frequency of appearing of these highways is very unequal within a given generalised ant rule, in some cases these frequencies where found in a ratio of $1/10^7$ in simulations, suggesting that those highways that appears as the only possible asymptotic behaviour of some rules, might be accompanied by a big family of very infrequent ones.

De Bruijn tori, or perfect maps, are two-dimensional periodic arrays of letters from a finite alphabet, where each possible pattern of shape (m,n) appears exactly once in a single period. While the existence of certain de Bruijn tori, such as square tori with odd m=n element {3,5,7} and even alphabet sizes, remains unresolved, sub-perfect maps are often sufficient in applications like positional coding. These maps capture a large number of patterns, with each appearing at most once. While previous methods for generating such sub-perfect maps cover only a fraction of the possible patterns, we present a construction method for generating almost perfect maps for arbitrary pattern shapes and arbitrary non-prime alphabet sizes, including the above mentioned square tori with odd m=n element {3,5,7} as long that the alphabet size is non-prime. This is achieved through the introduction of de Bruijn rings, a minimal-height sub-perfect map and a formalization of the concept of families of almost perfect maps. The generated sub-perfect maps are easily decodable which makes them perfectly suitable for positional coding applications.
Graph classes of bounded tree rank were introduced recently in the context of the model checking problem for first-order logic of graphs. These graph classes are a common generalization of graph classes of bounded degree and bounded treedepth, and they are a special case of graph classes of bounded expansion. We introduce a notion of decomposition for these classes and show that these decompositions can be efficiently computed. Also, a natural extension of our decomposition leads to a new characterization and decomposition for graph classes of bounded expansion (and an efficient algorithm computing this decomposition). We then focus on interpretations of graph classes of bounded tree rank. We give a characterization of graph classes interpretable in graph classes of tree rank $2$. Importantly, our characterization leads to an efficient sparsification procedure: For any graph class $C$ interpretable in a efficiently bounded graph class of tree rank at most $2$, there is a polynomial time algorithm that to any $G \in C$ computes a (sparse) graph $H$ from a fixed graph class of tree rank at most $2$ such that $G = I(H)$ for a fixed interpretation $I$. To the best of our knowledge, this is the first efficient "interpretation reversal" result that generalizes the result of Gajarský et al. [LICS 2016], who showed an analogous result for graph classes interpretable in classes of graphs of bounded degree.

The Weisfeiler-Leman (WL) algorithms form a family of incomplete approaches to the graph isomorphism problem. They recently found various applications in algorithmic group theory and machine learning. In fact, the algorithms form a parameterized family: for each $k \in \mathbb{N}$ there is a corresponding $k$-dimensional algorithm $\texttt{WLk}$. The algorithms become increasingly powerful with increasing dimension, but at the same time the running time increases. The WL-dimension of a graph $G$ is the smallest $k \in \mathbb{N}$ for which $\texttt{WLk}$ correctly decides isomorphism between $G$ and every other graph. In some sense, the WL-dimension measures how difficult it is to test isomorphism of one graph to others using a fairly general class of combinatorial algorithms. Nowadays, it is a standard measure in descriptive complexity theory for the structural complexity of a graph. We prove that the WL-dimension of a graph on $n$ vertices is at most $3/20 \cdot n + o(n) = 0.15 \cdot n + o(n)$. Reducing the question to coherent configurations, the proof develops various techniques to analyze their structure. This includes sufficient conditions under which a fiber can be restored uniquely up to isomorphism if it is removed, a recursive proof exploiting a degree reduction and treewidth bounds, as well as an exhaustive analysis of interspaces involving small fibers. As a base case, we also analyze the dimension of coherent configurations with small fiber size and thereby graphs with small color class size.