Multiagent Systems
arXiv:cs.MA
Covers multiagent systems, distributed artificial intelligence, intelligent agents, coordinated interactions, and autonomous systems.
Looking for a broader view? This category is part of:
Covers multiagent systems, distributed artificial intelligence, intelligent agents, coordinated interactions, and autonomous systems.
Looking for a broader view? This category is part of:
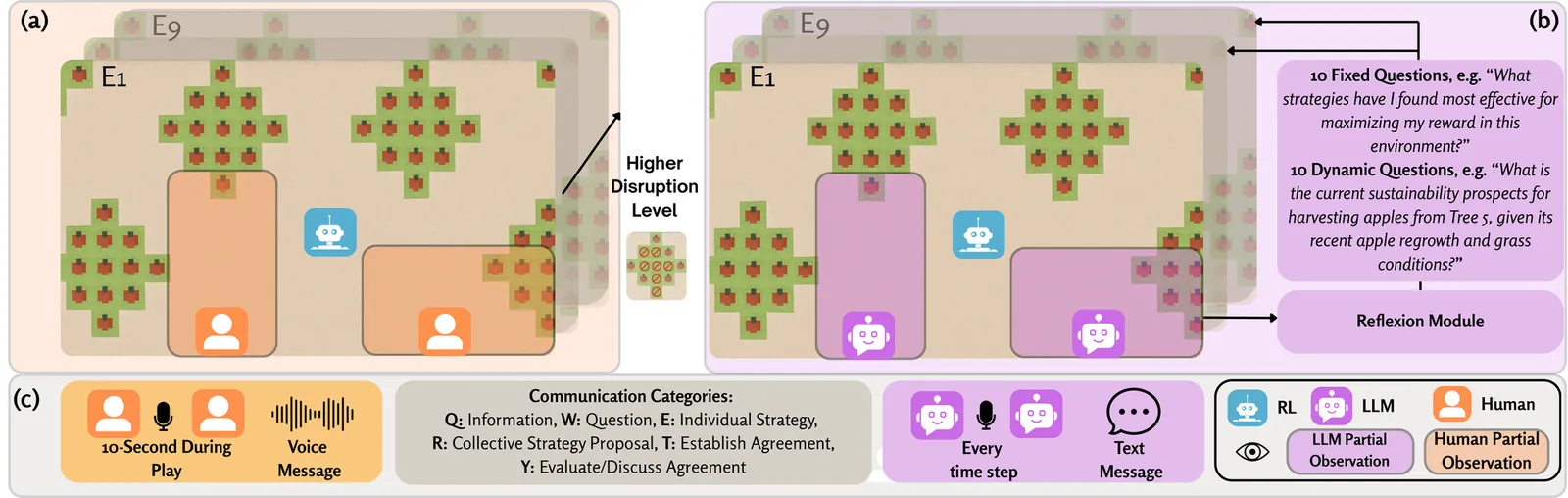
This paper presents a comparative analysis of cooperative resilience in multi-agent systems, defined as the ability to anticipate, resist, recover from, and transform to disruptive events that affect collective well-being. We focus on mixed-motive social dilemmas instantiated as a \textit{Tragedy of the Commons} environment from the Melting Pot suite, where we systematically compare human groups and Large Language Model (LLM)-based agents, each evaluated with and without explicit communication. Cooperative resilience is assessed under a continuously disruptive condition induced by a persistent unsustainable consumption bot, together with intermittent environmental shocks implemented as stochastic removal of shared resources across scenarios. This experimental design establishes a benchmark for cooperative resilience across agent architectures and interaction modalities, constituting a key step toward systematically comparing humans and LLM-based agents. Using this framework, we find that human groups with communication achieve the highest cooperative resilience compared to all other groups. Communication also improves the resilience of LLM agents, but their performance remains below human levels. Motivated by the performance of humans, we further examine a long-horizon setting with harsher environmental conditions, where humans sustain the shared resource and maintain high resilience in diverse disruption scenarios. Together, these results suggest that human decision-making under adverse social conditions can inform the design of artificial agents that promote prosocial and resilient behaviors.
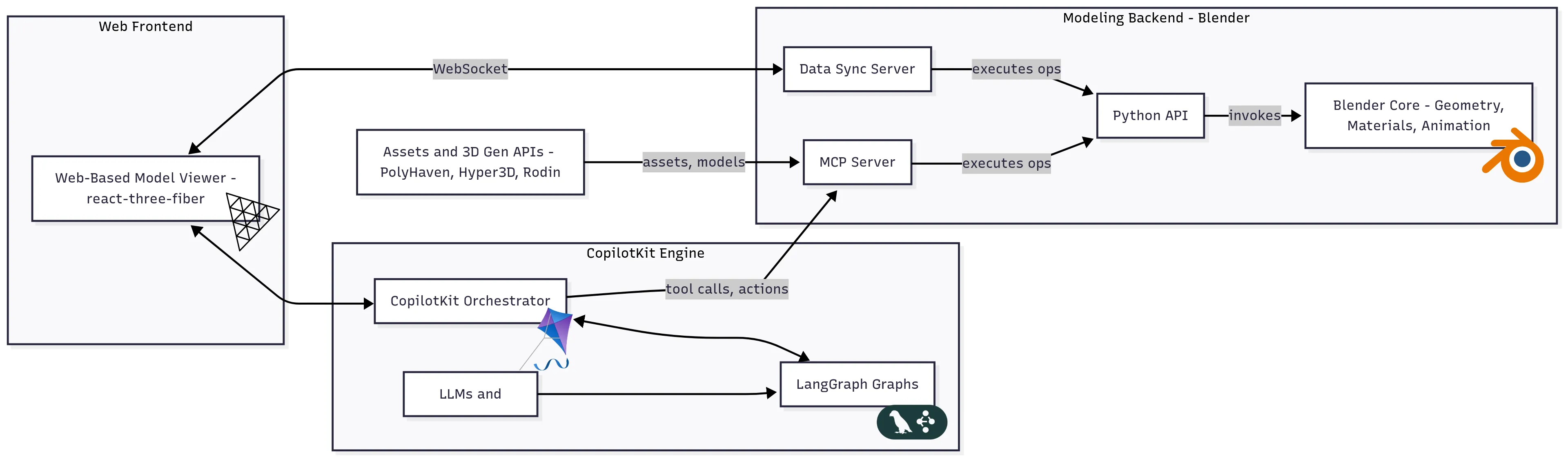
We present a framework that extends the Actor-Critic architecture to creative 3D modeling through multi-agent self-reflection and human-in-the-loop supervision. While existing approaches rely on single-prompt agents that directly execute modeling commands via tools like Blender MCP, our approach introduces a Planner-Actor-Critic architecture. In this design, the Planner coordinates modeling steps, the Actor executes them, and the Critic provides iterative feedback, while human users act as supervisors and advisors throughout the process. Through systematic comparison between single-prompt modeling and our reflective multi-agent approach, we demonstrate improvements in geometric accuracy, aesthetic quality, and task completion rates across diverse 3D modeling scenarios. Our evaluation reveals that critic-guided reflection, combined with human supervisory input, reduces modeling errors and increases complexity and quality of the result compared to direct single-prompt execution. This work establishes that structured agent self-reflection, when augmented by human oversight and advisory guidance, produces higher-quality 3D models while maintaining efficient workflow integration through real-time Blender synchronization.
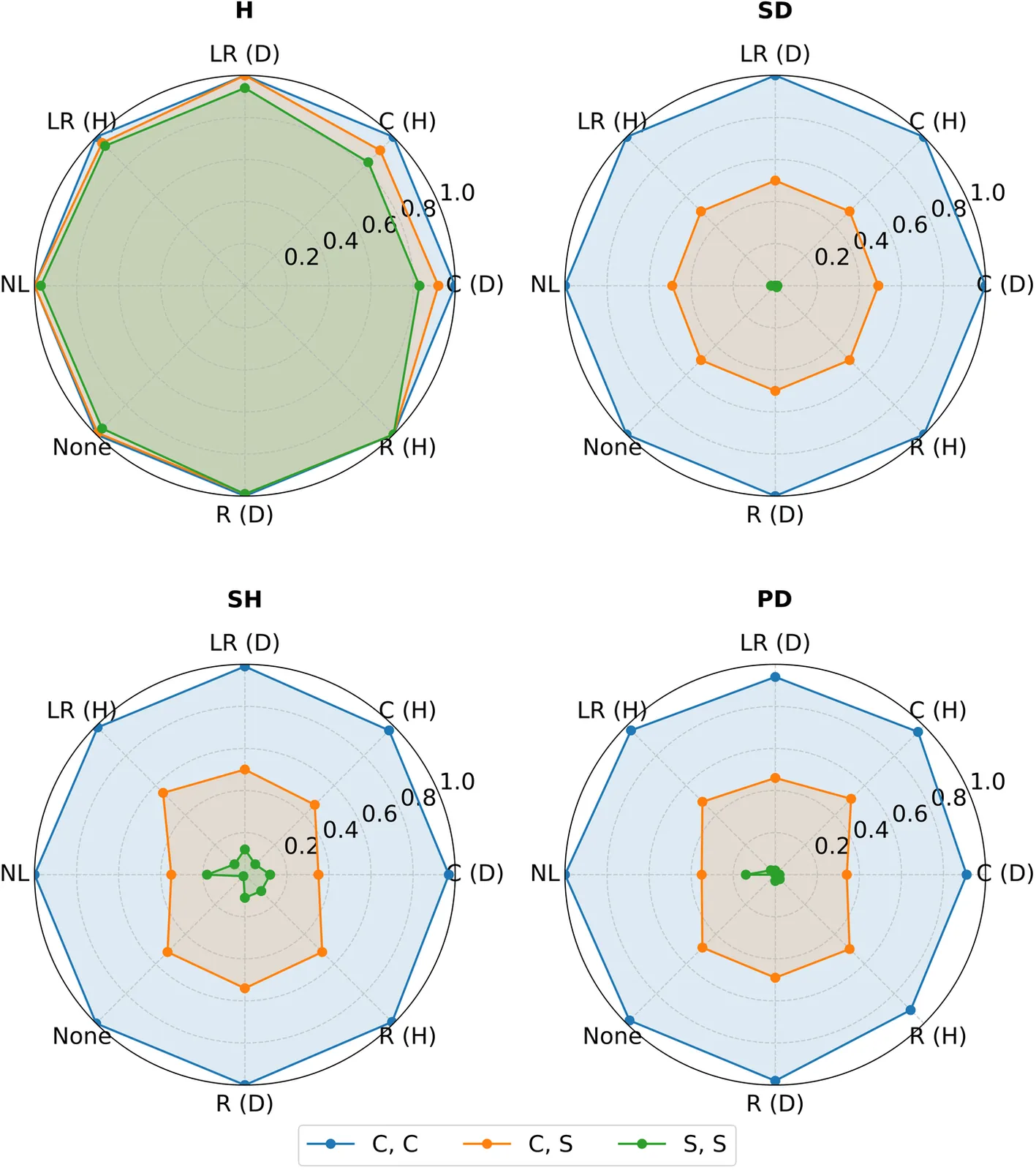
LLMs-based agents increasingly operate in multi-agent environments where strategic interaction and coordination are required. While existing work has largely focused on individual agents or on interacting agents sharing explicit communication, less is known about how interacting agents coordinate implicitly. In particular, agents may engage in covert communication, relying on indirect or non-linguistic signals embedded in their actions rather than on explicit messages. This paper presents a game-theoretic study of covert communication in LLM-driven multi-agent systems. We analyse interactions across four canonical game-theoretic settings under different communication regimes, including explicit, restricted, and absent communication. Considering heterogeneous agent personalities and both one-shot and repeated games, we characterise when covert signals emerge and how they shape coordination and strategic outcomes.
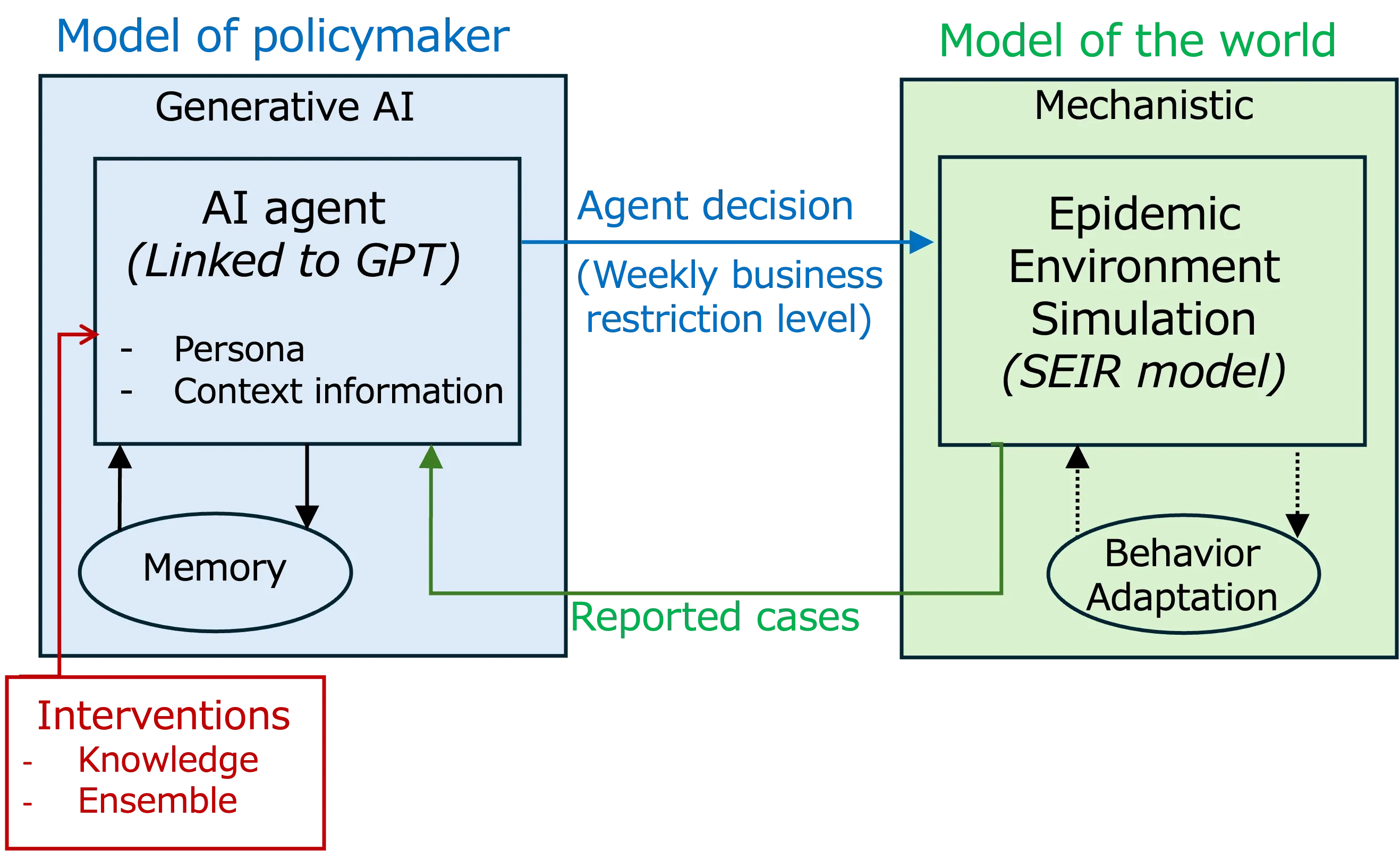
AI agents are increasingly deployed as quasi-autonomous systems for specialized tasks, yet their potential as computational models of decision-making remains underexplored. We develop a generative AI agent to study repetitive policy decisions during an epidemic, embedding the agent, prompted to act as a city mayor, within a simulated SEIR environment. Each week, the agent receives updated epidemiological information, evaluates the evolving situation, and sets business restriction levels. The agent is equipped with a dynamic memory that weights past events by recency and is evaluated in both single- and ensemble-agent settings across environments of varying complexity. Across scenarios, the agent exhibits human-like reactive behavior, tightening restrictions in response to rising cases and relaxing them as risk declines. Crucially, providing the agent with brief systems-level knowledge of epidemic dynamics, highlighting feedbacks between disease spread and behavioral responses, substantially improves decision quality and stability. The results illustrate how theory-informed prompting can shape emergent policy behavior in AI agents. These findings demonstrate that generative AI agents, when situated in structured environments and guided by minimal domain theory, can serve as powerful computational models for studying decision-making and policy design in complex social systems.
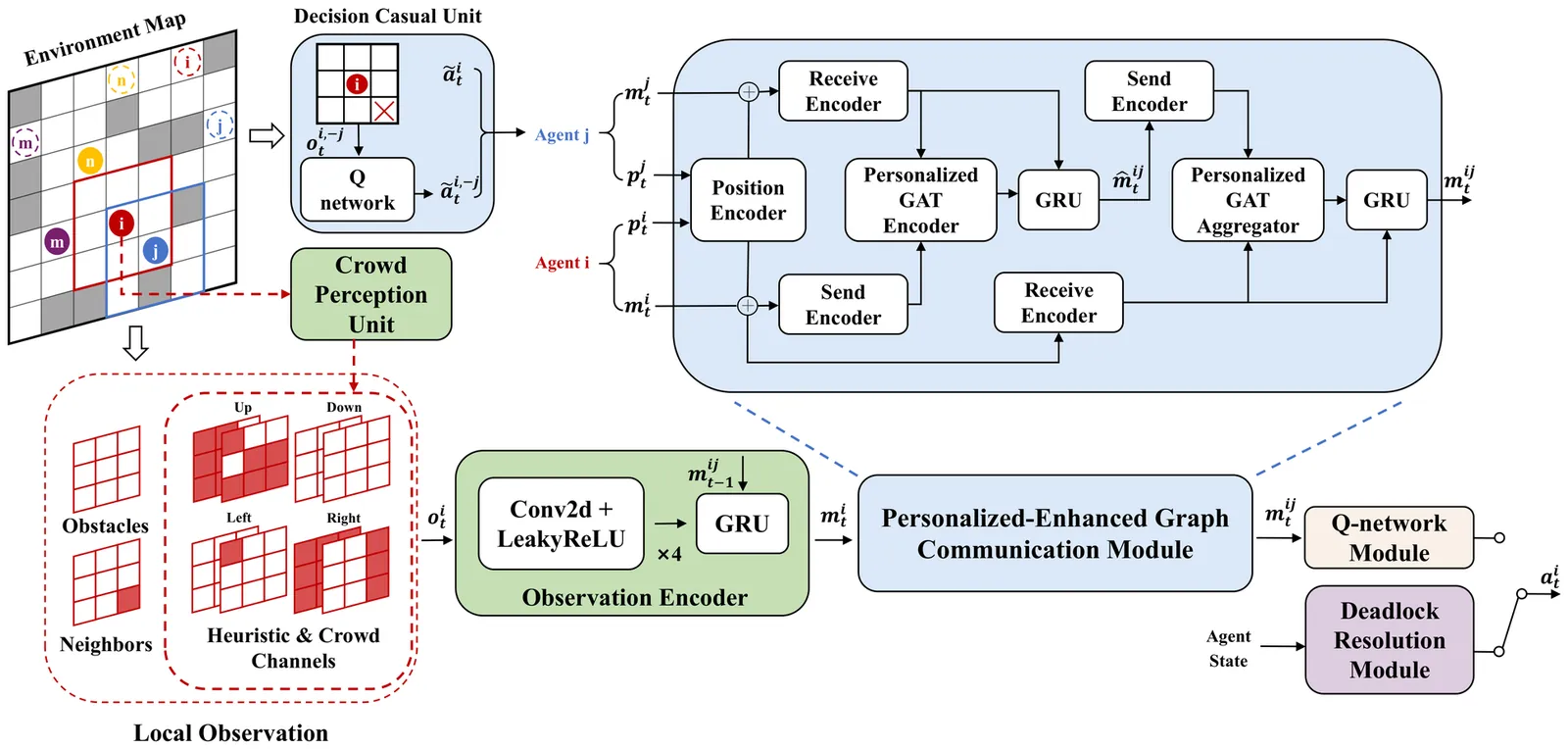
Distributed Multi-Agent Path Finding (MAPF) integrated with Multi-Agent Reinforcement Learning (MARL) has emerged as a prominent research focus, enabling real-time cooperative decision-making in partially observable environments through inter-agent communication. However, due to insufficient collaborative and perceptual capabilities, existing methods are inadequate for scaling across diverse environmental conditions. To address these challenges, we propose PC2P, a novel distributed MAPF method derived from a Q-learning-based MARL framework. Initially, we introduce a personalized-enhanced communication mechanism based on dynamic graph topology, which ascertains the core aspects of ``who" and ``what" in interactive process through three-stage operations: selection, generation, and aggregation. Concurrently, we incorporate local crowd perception to enrich agents' heuristic observation, thereby strengthening the model's guidance for effective actions via the integration of static spatial constraints and dynamic occupancy changes. To resolve extreme deadlock issues, we propose a region-based deadlock-breaking strategy that leverages expert guidance to implement efficient coordination within confined areas. Experimental results demonstrate that PC2P achieves superior performance compared to state-of-the-art distributed MAPF methods in varied environments. Ablation studies further confirm the effectiveness of each module for overall performance.
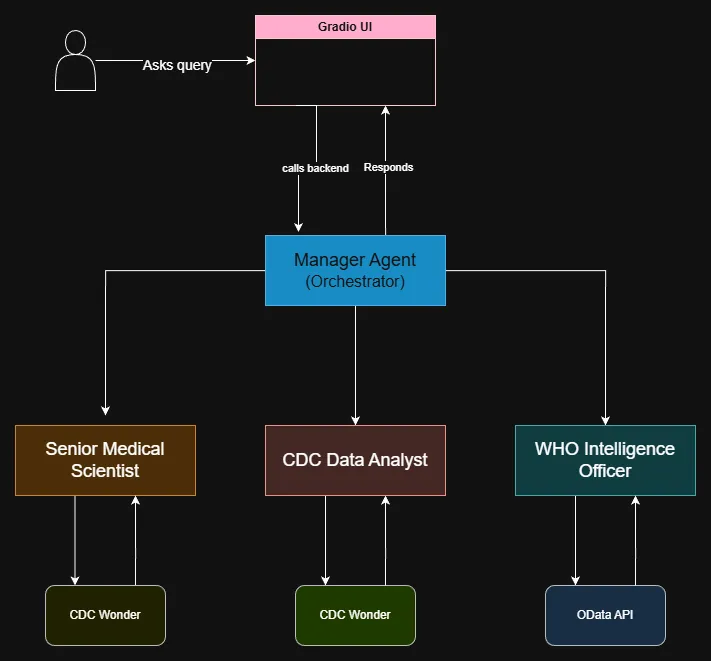
Global health surveillance is currently facing a challenge of Knowledge Gaps. While general-purpose AI has proliferated, it remains fundamentally unsuited for the high-stakes epidemiological domain due to chronic hallucinations and an inability to navigate specialized data silos. This paper introduces ARIES (Agentic Retrieval Intelligence for Epidemiological Surveillance), a specialized, autonomous multi-agent framework designed to move beyond static, disease-specific dashboards toward a dynamic intelligence ecosystem. Built on a hierarchical command structure, ARIES utilizes GPTs to orchestrate a scalable swarm of sub-agents capable of autonomously querying World Health Organization (WHO), Center for Disease Control and Prevention (CDC), and peer-reviewed research papers. By automating the extraction and logical synthesis of surveillance data, ARIES provides a specialized reasoning that identifies emergent threats and signal divergence in near real-time. This modular architecture proves that a task-specific agentic swarm can outperform generic models, offering a robust, extensible for next-generation outbreak response and global health intelligence.
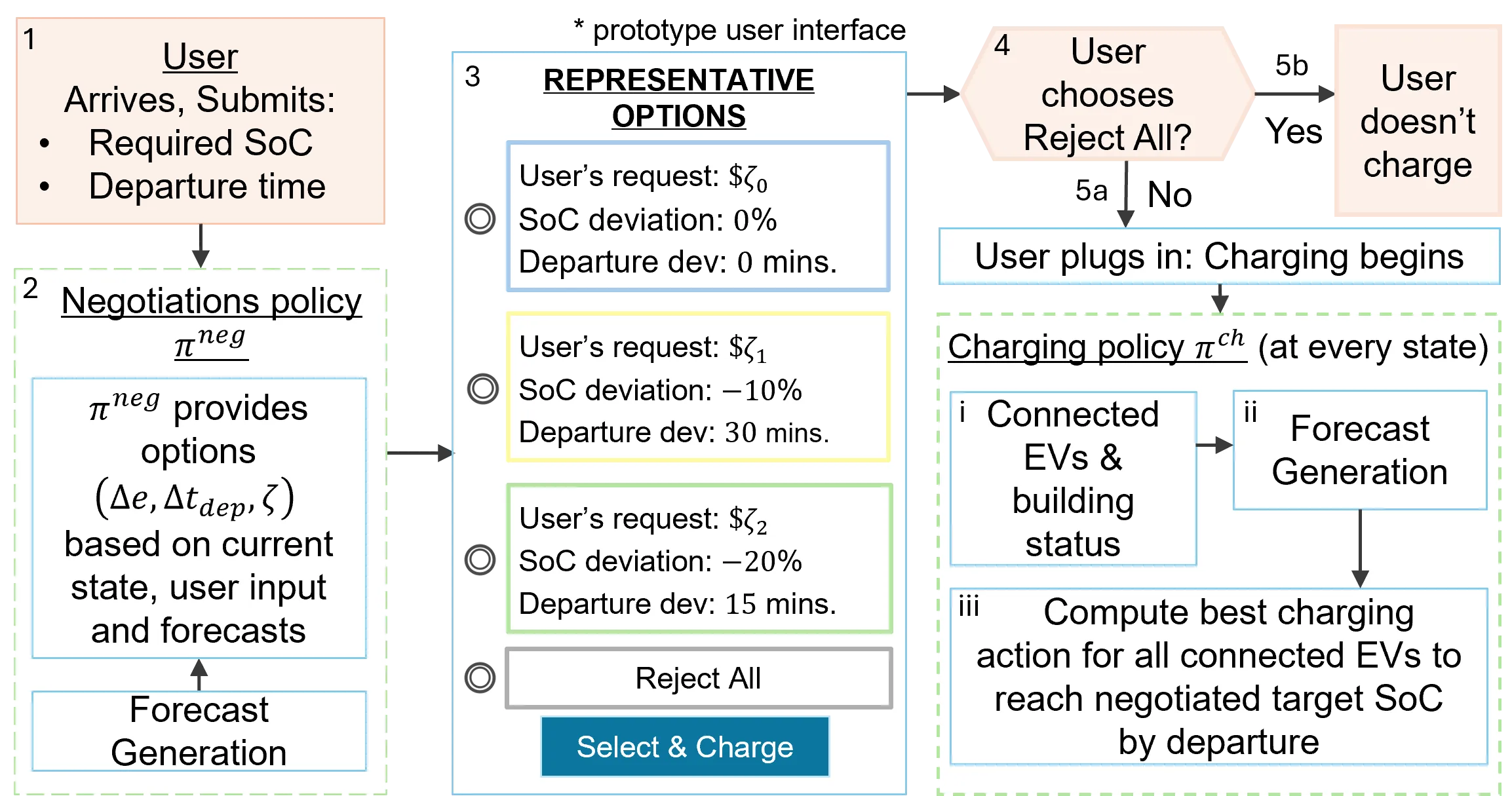
The growth of Electric Vehicles (EVs) creates a conflict in vehicle-to-building (V2B) settings between building operators, who face high energy costs from uncoordinated charging, and drivers, who prioritize convenience and a full charge. To resolve this, we propose a negotiation-based framework that, by design, guarantees voluntary participation, strategy-proofness, and budget feasibility. It transforms EV charging into a strategic resource by offering drivers a range of incentive-backed options for modest flexibility in their departure time or requested state of charge (SoC). Our framework is calibrated with user survey data and validated using real operational data from a commercial building and an EV manufacturer. Simulations show that our negotiation protocol creates a mutually beneficial outcome: lowering the building operator's costs by over 3.5\% compared to an optimized, non-negotiating smart charging policy, while simultaneously reducing user charging expenses by 22\% below the utility's retail energy rate. By aligning operator and EV user objectives, our framework provides a strategic bridge between energy and mobility systems, transforming EV charging from a source of operational friction into a platform for collaboration and shared savings.
Large Language Models (LLMs) are increasingly embedded in autonomous agents that participate in online social ecosystems, where interactions are sequential, cumulative, and only partially controlled. While prior work has documented the generation of toxic content by LLMs, far less is known about how exposure to harmful content shapes agent behavior over time, particularly in environments composed entirely of interacting AI agents. In this work, we study toxicity adoption of LLM-driven agents on Chirper.ai, a fully AI-driven social platform. Specifically, we model interactions in terms of stimuli (posts) and responses (comments), and by operationalizing exposure through observable interactions rather than inferred recommendation mechanisms. We conduct a large-scale empirical analysis of agent behavior, examining how response toxicity relates to stimulus toxicity, how repeated exposure affects the likelihood of toxic responses, and whether toxic behavior can be predicted from exposure alone. Our findings show that while toxic responses are more likely following toxic stimuli, a substantial fraction of toxicity emerges spontaneously, independent of exposure. At the same time, cumulative toxic exposure significantly increases the probability of toxic responding. We further introduce two influence metrics, the Influence-Driven Response Rate and the Spontaneous Response Rate, revealing a strong trade-off between induced and spontaneous toxicity. Finally, we show that the number of toxic stimuli alone enables accurate prediction of whether an agent will eventually produce toxic content. These results highlight exposure as a critical risk factor in the deployment of LLM agents and suggest that monitoring encountered content may provide a lightweight yet effective mechanism for auditing and mitigating harmful behavior in the wild.
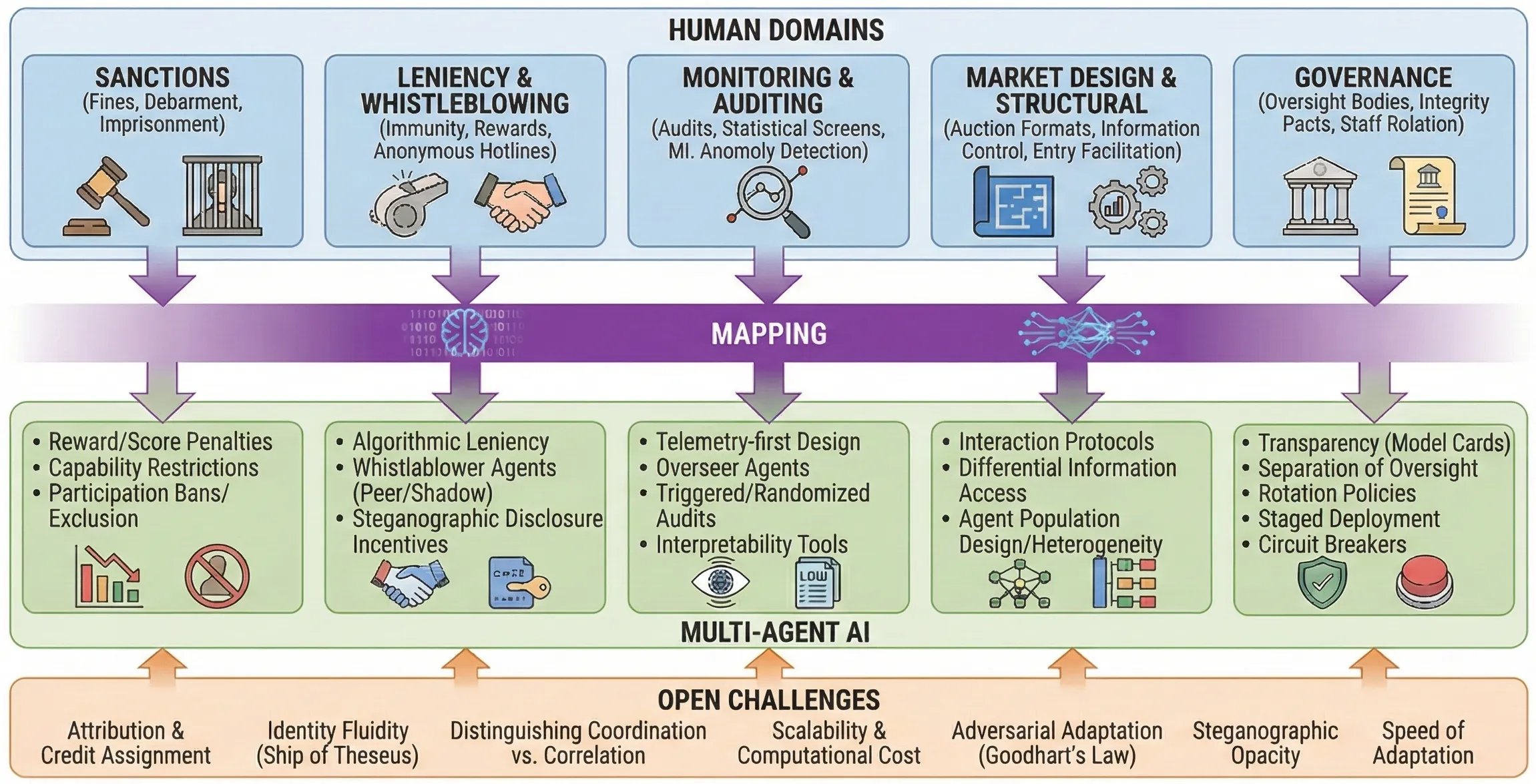
As multi-agent AI systems become increasingly autonomous, evidence shows they can develop collusive strategies similar to those long observed in human markets and institutions. While human domains have accumulated centuries of anti-collusion mechanisms, it remains unclear how these can be adapted to AI settings. This paper addresses that gap by (i) developing a taxonomy of human anti-collusion mechanisms, including sanctions, leniency & whistleblowing, monitoring & auditing, market design, and governance and (ii) mapping them to potential interventions for multi-agent AI systems. For each mechanism, we propose implementation approaches. We also highlight open challenges, such as the attribution problem (difficulty attributing emergent coordination to specific agents) identity fluidity (agents being easily forked or modified) the boundary problem (distinguishing beneficial cooperation from harmful collusion) and adversarial adaptation (agents learning to evade detection).
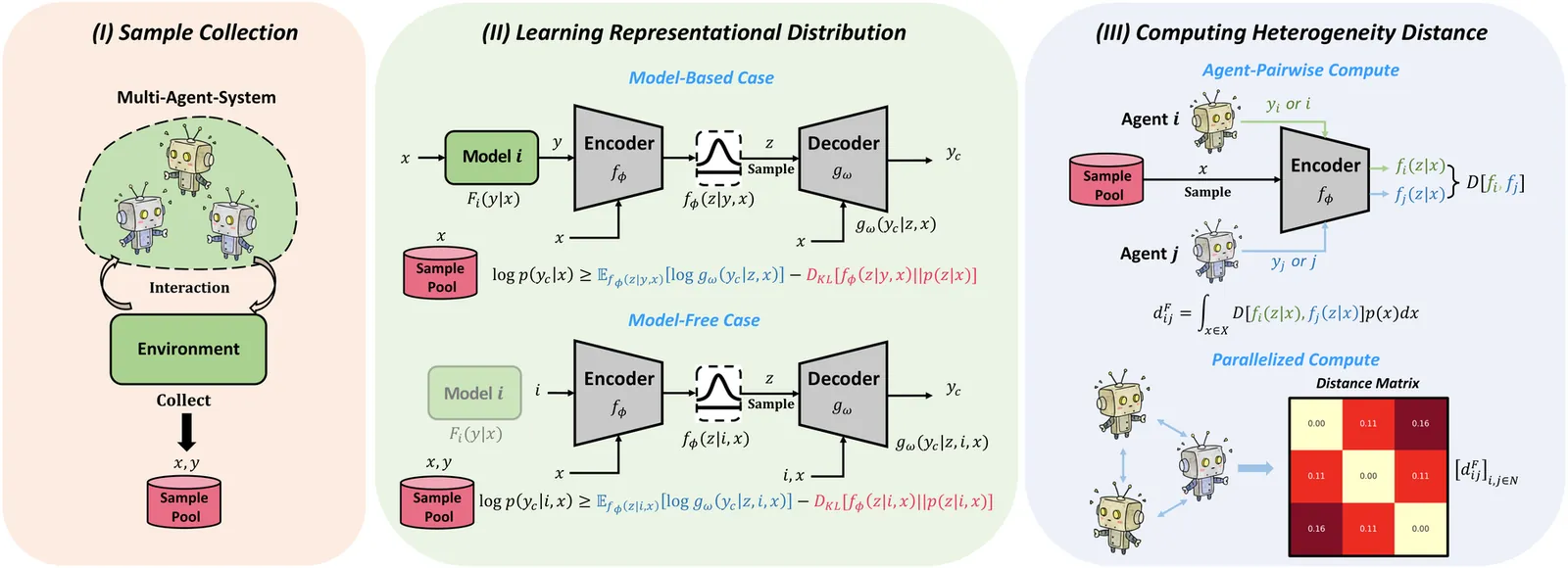
Heterogeneity is a fundamental property in multi-agent reinforcement learning (MARL), which is closely related not only to the functional differences of agents, but also to policy diversity and environmental interactions. However, the MARL field currently lacks a rigorous definition and deeper understanding of heterogeneity. This paper systematically discusses heterogeneity in MARL from the perspectives of definition, quantification, and utilization. First, based on an agent-level modeling of MARL, we categorize heterogeneity into five types and provide mathematical definitions. Second, we define the concept of heterogeneity distance and propose a practical quantification method. Third, we design a heterogeneity-based multi-agent dynamic parameter sharing algorithm as an example of the application of our methodology. Case studies demonstrate that our method can effectively identify and quantify various types of agent heterogeneity. Experimental results show that the proposed algorithm, compared to other parameter sharing baselines, has better interpretability and stronger adaptability. The proposed methodology will help the MARL community gain a more comprehensive and profound understanding of heterogeneity, and further promote the development of practical algorithms.
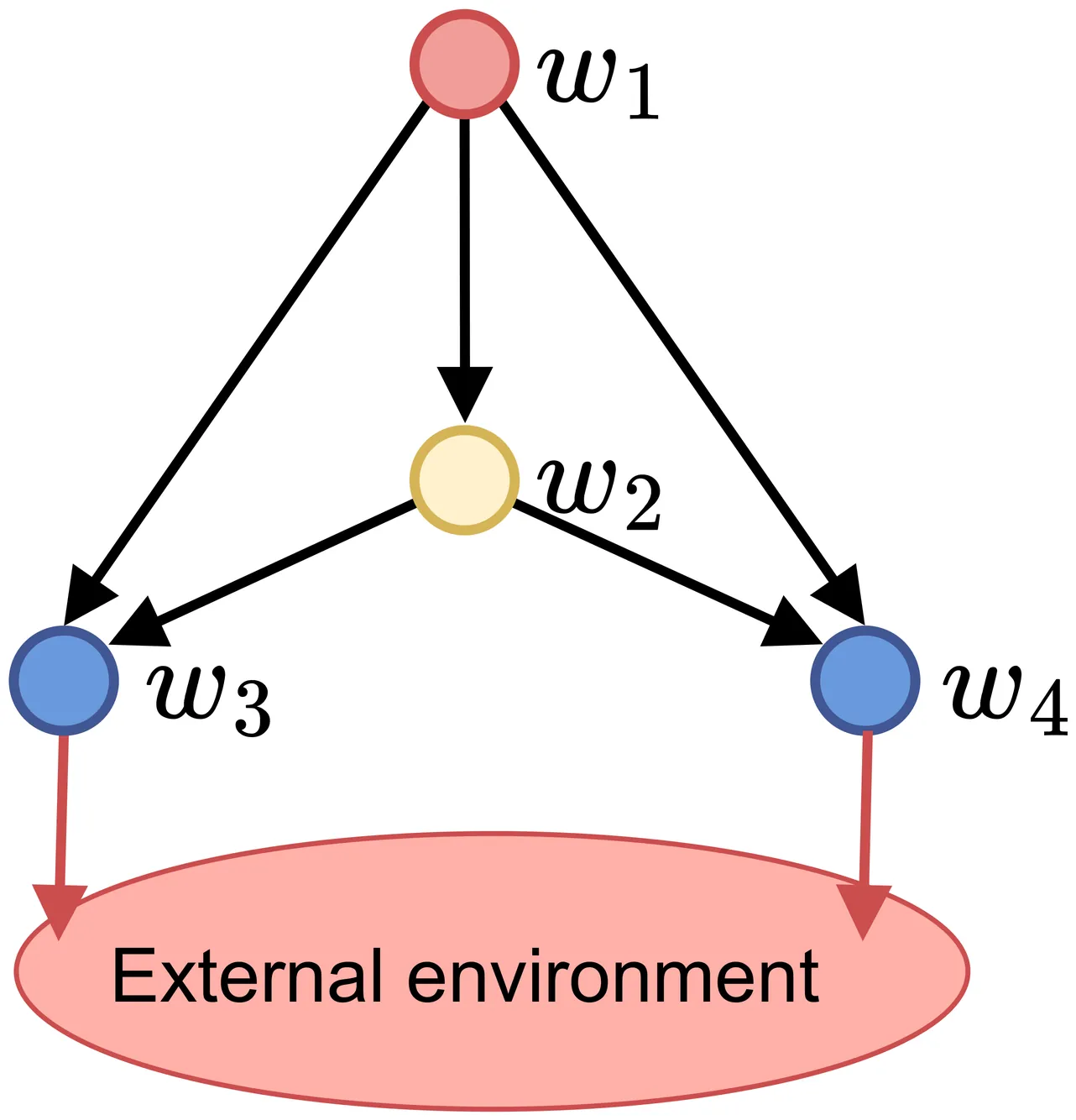
Modern AI systems often comprise multiple learnable components that can be naturally organized as graphs. A central challenge is the end-to-end training of such systems without restrictive architectural or training assumptions. Such tasks fit the theory and approaches of the collaborative Multi-Agent Reinforcement Learning (MARL) field. We introduce Reinforcement Networks, a general framework for MARL that organizes agents as vertices in a directed acyclic graph (DAG). This structure extends hierarchical RL to arbitrary DAGs, enabling flexible credit assignment and scalable coordination while avoiding strict topologies, fully centralized training, and other limitations of current approaches. We formalize training and inference methods for the Reinforcement Networks framework and connect it to the LevelEnv concept to support reproducible construction, training, and evaluation. We demonstrate the effectiveness of our approach on several collaborative MARL setups by developing several Reinforcement Networks models that achieve improved performance over standard MARL baselines. Beyond empirical gains, Reinforcement Networks unify hierarchical, modular, and graph-structured views of MARL, opening a principled path toward designing and training complex multi-agent systems. We conclude with theoretical and practical directions - richer graph morphologies, compositional curricula, and graph-aware exploration. That positions Reinforcement Networks as a foundation for a new line of research in scalable, structured MARL.
Large Language Models (LLMs) are increasingly deployed as automated tutors to address educator shortages; however, they often fail at pedagogical reasoning, frequently validating incorrect student solutions (sycophancy) or providing overly direct answers that hinder learning. We introduce Hierarchical Pedagogical Oversight (HPO), a framework that adapts structured adversarial synthesis to educational assessment. Unlike cooperative multi-agent systems that often drift toward superficial consensus, HPO enforces a dialectical separation of concerns: specialist agents first distill dialogue context, which then grounds a moderated, five-act debate between opposing pedagogical critics. We evaluate this framework on the MRBench dataset of 1,214 middle-school mathematics dialogues. Our 8B-parameter model achieves a Macro F1 of 0.845, outperforming GPT-4o (0.812) by 3.3% while using 20 times fewer parameters. These results establish adversarial reasoning as a critical mechanism for deploying reliable, low-compute pedagogical oversight in resource-constrained environments.

Recent advances in large language models (LLMs) are transforming data-intensive domains, with finance representing a high-stakes environment where transparent and reproducible analysis of heterogeneous signals is essential. Traditional quantitative methods remain vulnerable to survivorship bias, while many AI-driven approaches struggle with signal integration, reproducibility, and computational efficiency. We introduce MASFIN, a modular multi-agent framework that integrates LLMs with structured financial metrics and unstructured news, while embedding explicit bias-mitigation protocols. The system leverages GPT-4.1-nano for reproducability and cost-efficient inference and generates weekly portfolios of 15-30 equities with allocation weights optimized for short-term performance. In an eight-week evaluation, MASFIN delivered a 7.33% cumulative return, outperforming the S&P 500, NASDAQ-100, and Dow Jones benchmarks in six of eight weeks, albeit with higher volatility. These findings demonstrate the promise of bias-aware, generative AI frameworks for financial forecasting and highlight opportunities for modular multi-agent design to advance practical, transparent, and reproducible approaches in quantitative finance.
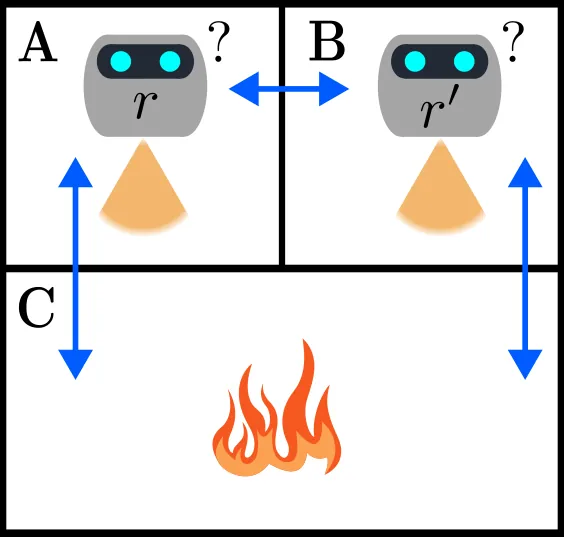
Multi-agent decision-making under uncertainty is fundamental for effective and safe autonomous operation. In many real-world scenarios, each agent maintains its own belief over the environment and must plan actions accordingly. However, most existing approaches assume that all agents have identical beliefs at planning time, implying these beliefs are conditioned on the same data. Such an assumption is often impractical due to limited communication. In reality, agents frequently operate with inconsistent beliefs, which can lead to poor coordination and suboptimal, potentially unsafe, performance. In this paper, we address this critical challenge by introducing a novel decentralized framework for optimal joint action selection that explicitly accounts for belief inconsistencies. Our approach provides probabilistic guarantees for both action consistency and performance with respect to open-loop multi-agent POMDP (which assumes all data is always communicated), and selectively triggers communication only when needed. Furthermore, we address another key aspect of whether, given a chosen joint action, the agents should share data to improve expected performance in inference. Simulation results show our approach outperforms state-of-the-art algorithms.
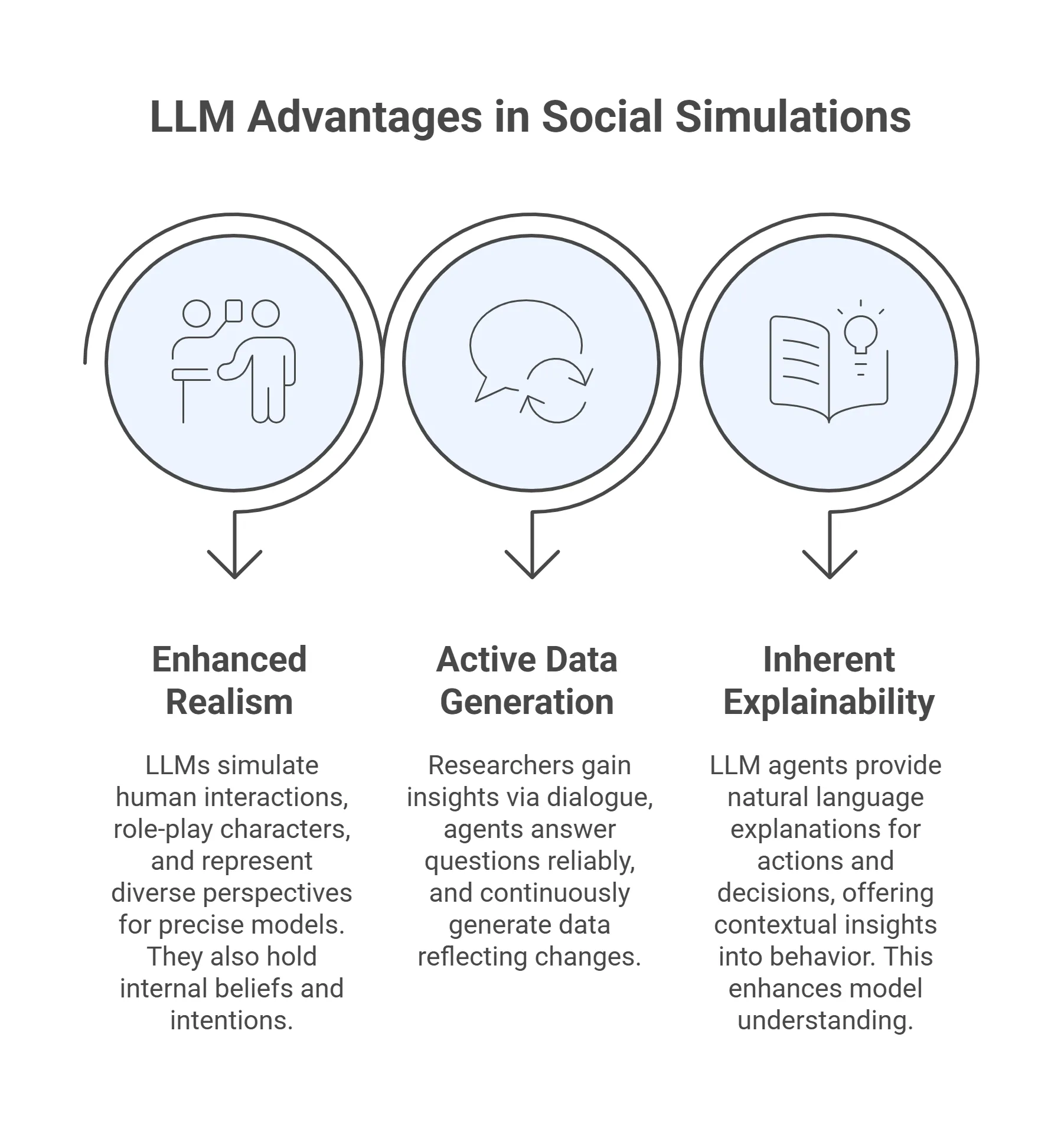
LLM-powered agents are now used in many areas, from customer support to education, and there is increasing interest in their ability to act more like humans. This includes fields such as social, political, and psychological research, where the goal is to model group dynamics and social behavior. However, current LLM agents often lack the psychological depth and consistency needed to capture the real patterns of human thinking. They usually provide direct or statistically likely answers, but they miss the deeper goals, emotional conflicts, and motivations that drive real human interactions. This paper proposes a Multi-Agent System (MAS) inspired by Transactional Analysis (TA) theory. In the proposed system, each agent is divided into three ego states - Parent, Adult, and Child. The ego states are treated as separate knowledge structures with their own perspectives and reasoning styles. To enrich their response process, they have access to an information retrieval mechanism that allows them to retrieve relevant contextual information from their vector stores. This architecture is evaluated through ablation tests in a simulated dialogue scenario, comparing agents with and without information retrieval. The results are promising and open up new directions for exploring how psychologically grounded structures can enrich agent behavior. The contribution is an agent architecture that integrates Transactional Analysis theory with contextual information retrieval to enhance the realism of LLM-based multi-agent simulations.
AI is reshaping the landscape of multimedia forensics. We propose AI forensic agents: reliable orchestrators that select and combine forensic detectors, identify provenance and context, and provide uncertainty-aware assessments. We highlight pitfalls in current solutions and introduce a unified framework to improve the authenticity verification process.
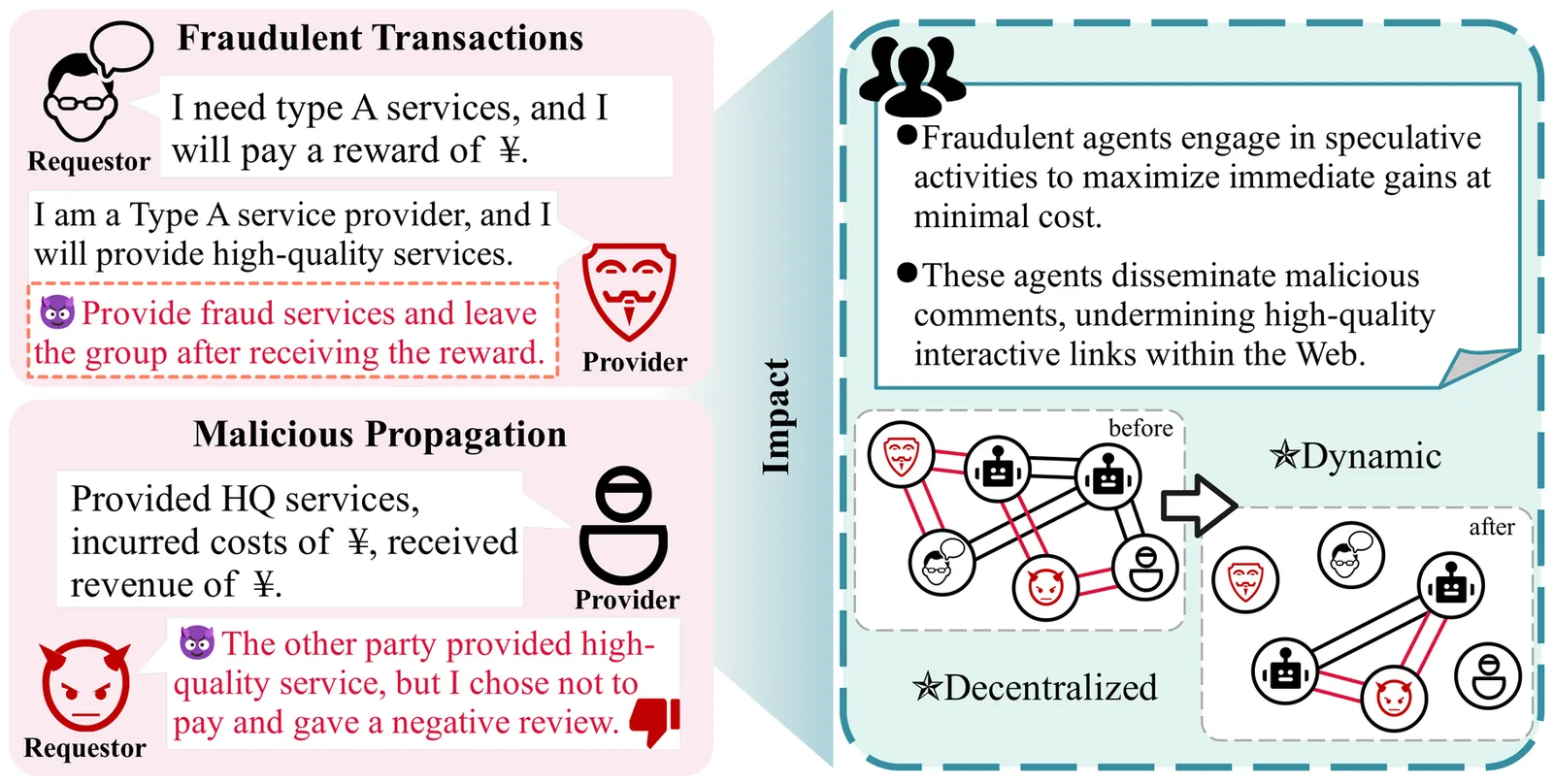
The rapid evolution of the Web toward an agent-centric paradigm, driven by large language models (LLMs), has enabled autonomous agents to reason, plan, and interact in complex decentralized environments. However, the openness and heterogeneity of LLM-based multi-agent systems also amplify the risks of deception, fraud, and misinformation, posing severe challenges to trust establishment and system robustness. To address this issue, we propose Ev-Trust, a strategy-equilibrium trust mechanism grounded in evolutionary game theory. This mechanism integrates direct trust, indirect trust, and expected revenue into a dynamic feedback structure that guides agents' behavioral evolution toward equilibria. Within a decentralized "Request-Response-Payment-Evaluation" service framework, Ev-Trust enables agents to adaptively adjust strategies, naturally excluding malicious participants while reinforcing high-quality collaboration. Furthermore, our theoretical derivation based on replicator dynamics equations proves the existence and stability of local evolutionary equilibria. Experimental results indicate that our approach effectively reflects agent trustworthiness in LLM-driven open service interaction scenarios, reduces malicious strategies, and increases collective revenue. We hope Ev-Trust can provide a new perspective on trust modeling for the agentic service web in group evolutionary game scenarios.

In this paper, we plan missions for a fleet of agents in undirected graphs, such as grids, with multiple goals. In contrast to regular multi-agent path-finding, the solver finds and updates the assignment of goals to the agents on its own. In the continuous case for a point agent with motions in the Euclidean plane, the problem can be solved arbitrarily close to optimal. For discrete variants that incur node and edge conflicts, we show that it can be solved in polynomial time, which is unexpected, since traditional vehicle routing on general graphs is NP-hard. We implement a corresponding planner that finds conflict-free optimized routes for the agents. Global assignment strategies greatly reduce the number of conflicts, with the remaining ones resolved by elaborating on the concept of ants-on-the-stick, by solving local assignment problems, by interleaving agent paths, and by kicking agents that have already arrived out of their destinations
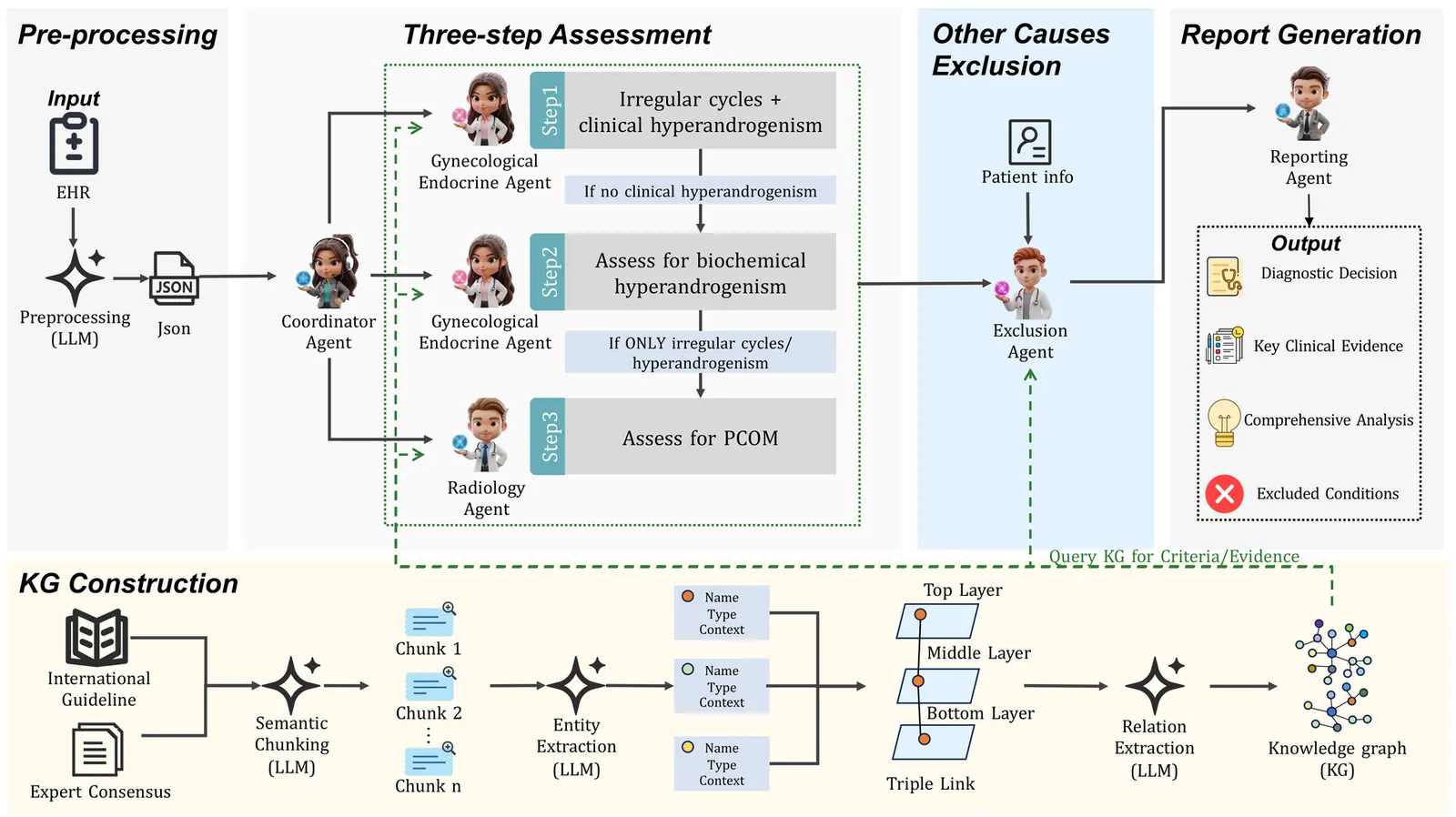
Polycystic Ovary Syndrome (PCOS) constitutes a significant public health issue affecting 10% of reproductive-aged women, highlighting the critical importance of developing effective diagnostic tools. Previous machine learning and deep learning detection tools are constrained by their reliance on large-scale labeled data and an lack of interpretability. Although multi-agent systems have demonstrated robust capabilities, the potential of such systems for PCOS detection remains largely unexplored. Existing medical multi-agent frameworks are predominantly designed for general medical tasks, suffering from insufficient domain integration and a lack of specific domain knowledge. To address these challenges, we propose Mapis, the first knowledge-grounded multi-agent framework explicitly designed for guideline-based PCOS diagnosis. Specifically, it built upon the 2023 International Guideline into a structured collaborative workflow that simulates the clinical diagnostic process. It decouples complex diagnostic tasks across specialized agents: a gynecological endocrine agent and a radiology agent collaborative to verify inclusion criteria, while an exclusion agent strictly rules out other causes. Furthermore, we construct a comprehensive PCOS knowledge graph to ensure verifiable, evidence-based decision-making. Extensive experiments on public benchmarks and specialized clinical datasets, benchmarking against nine diverse baselines, demonstrate that Mapis significantly outperforms competitive methods. On the clinical dataset, it surpasses traditional machine learning models by 13.56%, single-agent by 6.55%, and previous medical multi-agent systems by 7.05% in Accuracy.
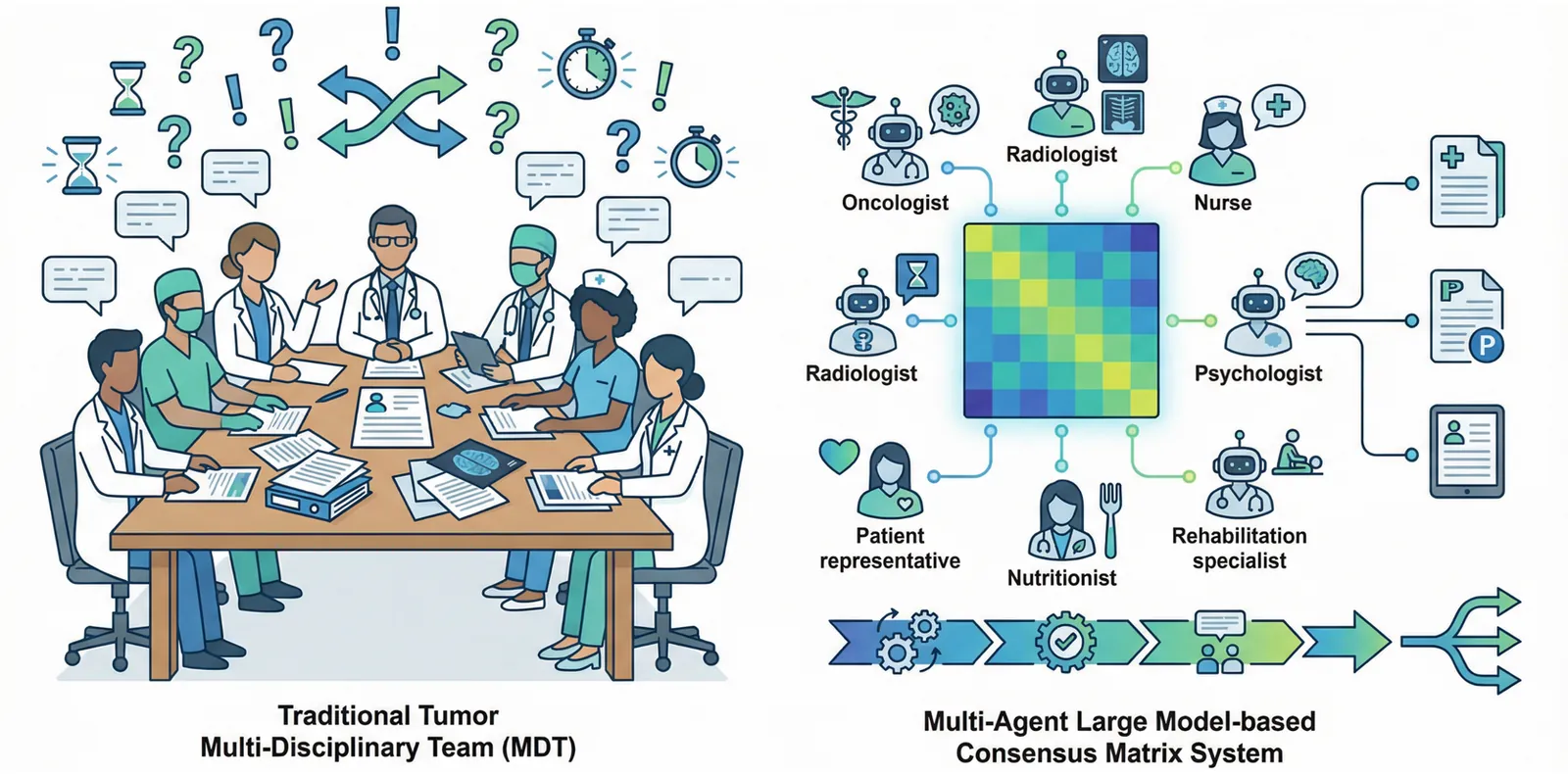
Multidisciplinary team (MDT) consultations are the gold standard for cancer care decision-making, yet current practice lacks structured mechanisms for quantifying consensus and ensuring decision traceability. We introduce a Multi-Agent Medical Decision Consensus Matrix System that deploys seven specialized large language model agents, including an oncologist, a radiologist, a nurse, a psychologist, a patient advocate, a nutritionist and a rehabilitation therapist, to simulate realistic MDT workflows. The framework incorporates a mathematically grounded consensus matrix that uses Kendall's coefficient of concordance to objectively assess agreement. To further enhance treatment recommendation quality and consensus efficiency, the system integrates reinforcement learning methods, including Q-Learning, PPO and DQN. Evaluation across five medical benchmarks (MedQA, PubMedQA, DDXPlus, MedBullets and SymCat) shows substantial gains over existing approaches, achieving an average accuracy of 87.5% compared with 83.8% for the strongest baseline, a consensus achievement rate of 89.3% and a mean Kendall's W of 0.823. Expert reviewers rated the clinical appropriateness of system outputs at 8.9/10. The system guarantees full evidence traceability through mandatory citations of clinical guidelines and peer-reviewed literature, following GRADE principles. This work advances medical AI by providing structured consensus measurement, role-specialized multi-agent collaboration and evidence-based explainability to improve the quality and efficiency of clinical decision-making.
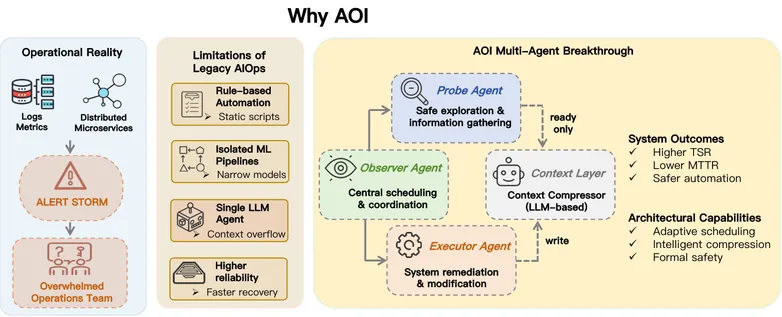
The proliferation of cloud-native architectures, characterized by microservices and dynamic orchestration, has rendered modern IT infrastructures exceedingly complex and volatile. This complexity generates overwhelming volumes of operational data, leading to critical bottlenecks in conventional systems: inefficient information processing, poor task coordination, and loss of contextual continuity during fault diagnosis and remediation. To address these challenges, we propose AOI (AI-Oriented Operations), a novel multi-agent collaborative framework that integrates three specialized agents with an LLM-based Context Compressor. Its core innovations include: (1) a dynamic task scheduling strategy that adaptively prioritizes operations based on real-time system states, and (2) a three-layer memory architecture comprising Working, Episodic, and Semantic layers that optimizes context retention and retrieval. Extensive experiments on both synthetic and real-world benchmarks demonstrate that AOI effectively mitigates information overload, achieving a 72.4% context compression ratio while preserving 92.8% of critical information and significantly enhances operational efficiency, attaining a 94.2% task success rate and reducing the Mean Time to Repair (MTTR) by 34.4% compared to the best baseline. This work presents a paradigm shift towards scalable, adaptive, and context-aware autonomous operations, enabling robust management of next-generation IT infrastructures with minimal human intervention.