Social and Information Networks
arXiv:cs.SI
Covers the design, analysis, and modeling of social and information networks.
Looking for a broader view? This category is part of:
Covers the design, analysis, and modeling of social and information networks.
Looking for a broader view? This category is part of:
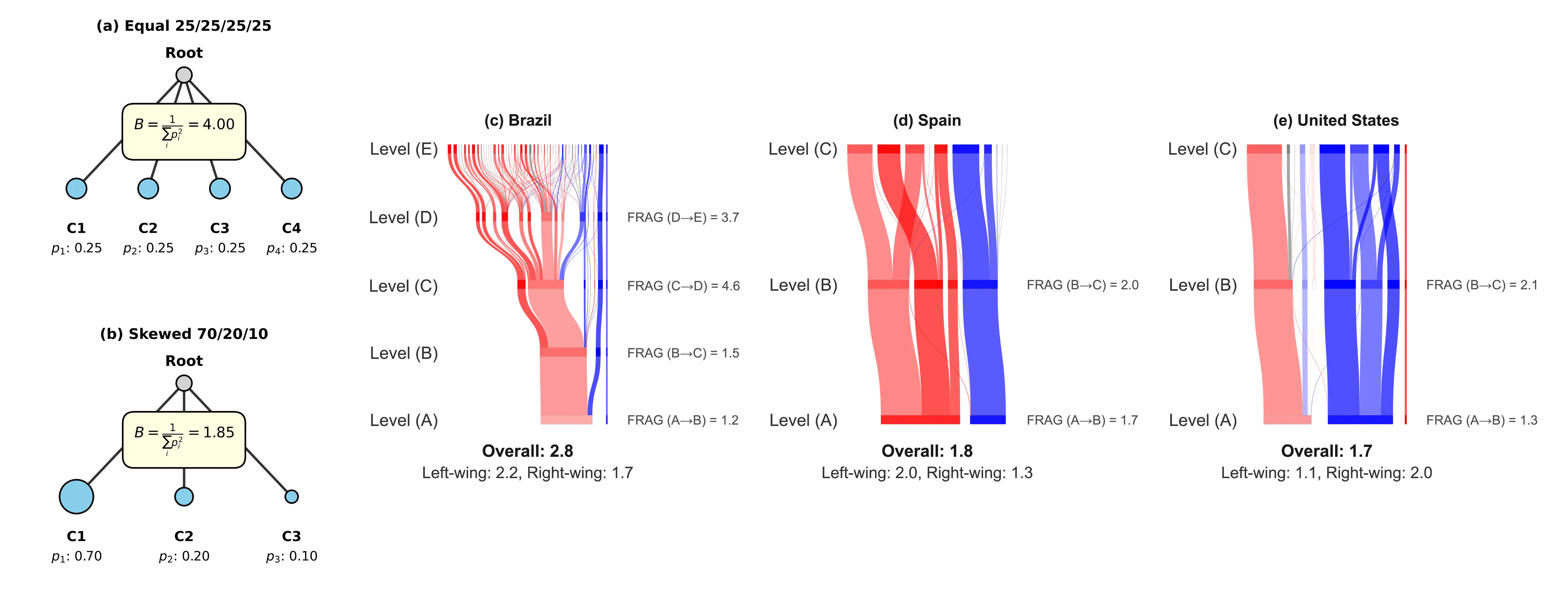
Online political divisions, such as fragmentation or polarization, are a growing global concern that can foster radicalization and hinder democratic cooperation; however, not all divisions are detrimental, some reflect pluralism and healthy diversity of opinion in a democracy. While prior research has predominantly focused on polarization in the United States, there remains a limited body of research on political divides in multiparty systems, and no universal method for comparing fragmentation across countries. Moreover, cross-country comparison is rare. This study first develops a novel measure of structural political fragmentation built on multi-scale community detection and the effective branching factor. Using a dataset of 18,325 political influencers from Brazil, Spain, and the United States, we assess online fragmentation in their Twitter/X co-following networks. We compare the fragmentation of the three countries, as well as the ideological groups within each. We further investigate factors associated with the level of fragmentation in each country. We find that political fragmentation differs across countries and is asymmetric between ideological groups. Brazil is the most fragmented, with higher fragmentation among the left-wing group, while Spain and the United States exhibit similar overall levels, with the left more fragmented in Spain and the right more fragmented in the United States. Additionally, we find that social identity plays a central role in political fragmentation. A strong alignment between ideological and social identities, with minimal overlap between ideologies, tends to promote greater integration and reduce fragmentation. Our findings provide explanations for cross-national and ideological differences in political fragmentation.
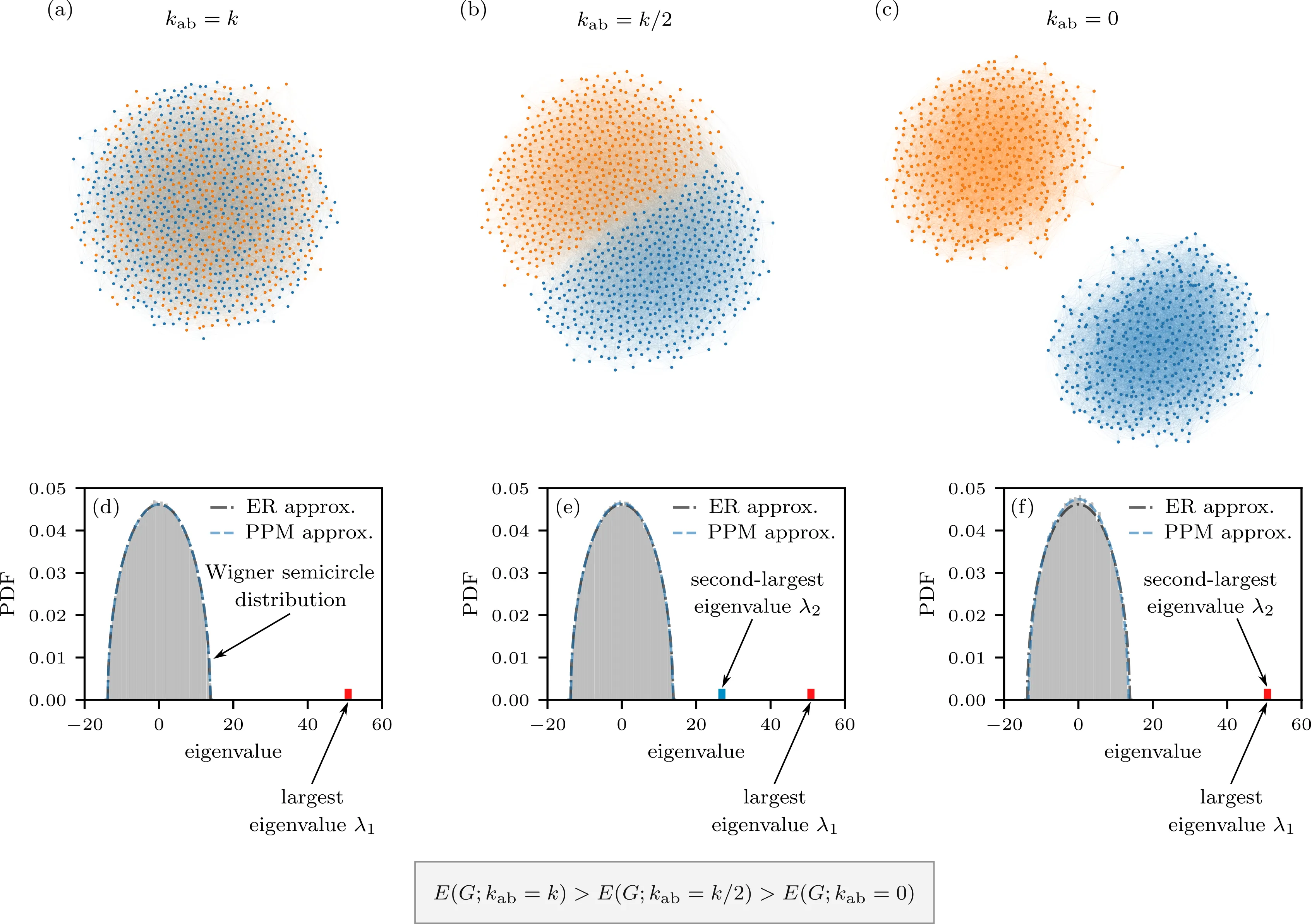
A key challenge in network science is the detection of communities, which are sets of nodes in a network that are densely connected internally but sparsely connected to the rest of the network. A fundamental result in community detection is the existence of a nontrivial threshold for community detectability on sparse graphs that are generated by the planted partition model (PPM). Below this so-called ``detectability limit'', no community-detection method can perform better than random chance. Spectral methods for community detection fail before this detectability limit because the eigenvalues corresponding to the eigenvectors that are relevant for community detection can be absorbed by the bulk of the spectrum. One can bypass the detectability problem by using special matrices, like the non-backtracking matrix, but this requires one to consider higher-dimensional matrices. In this paper, we show that the difference in graph energy between a PPM and an Erdős--Rényi (ER) network has a distinct transition at the detectability threshold even for the adjacency matrices of the underlying networks. The graph energy is based on the full spectrum of an adjacency matrix, so our result suggests that standard graph matrices still allow one to separate the parameter regions with detectable and undetectable communities.
Community detection is crucial for applications like targeted marketing and recommendation systems. Traditional methods rely on network structure, and embedding-based models integrate semantic information. However, there is a challenge when a model leverages local and global information from complex structures like social networks. Graph Neural Networks (GNNs) and Transformers have shown superior performance in capturing local and global relationships. In this paper, We propose Graph Integrated Transformer for Community Detection (GIT-CD), a hybrid model combining GNNs and Transformer-based attention mechanisms to enhance community detection in social networks. Specifically, the GNN module captures local graph structures, while the Transformer module models long-range dependencies. A self-optimizing clustering module refines community assignments using K-Means, silhouette loss, and KL divergence minimization. Experimental results on benchmark datasets show that GIT-CD outperforms state-of-the-art models, making it a robust approach for detecting meaningful communities in complex social networks.
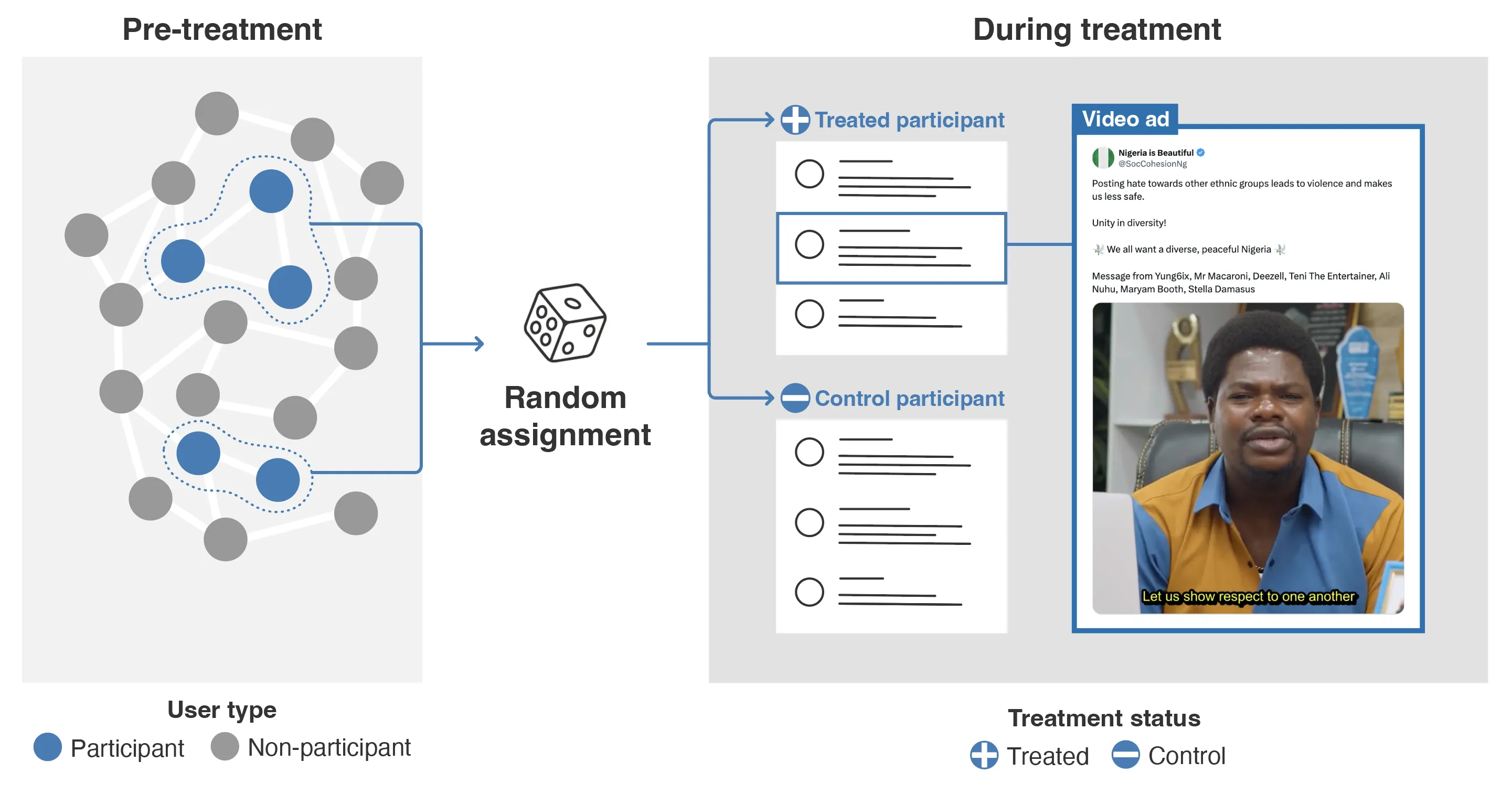
Online hate spreads rapidly, yet little is known about whether preventive and scalable strategies can curb it. We conducted the largest randomized controlled trial of hate speech prevention to date: a 20-week messaging campaign on X in Nigeria targeting ethnic hate. 73,136 users who had previously engaged with hate speech were randomly assigned to receive prosocial video messages from Nigerian celebrities. The campaign reduced hate content by 2.5% to 5.5% during treatment, with about 75% of the reduction persisting over the following four months. Reaching a larger share of a user's audience reduced amplification of that user's hate posts among both treated and untreated users, cutting hate reposts by over 50% for the most exposed accounts. Scalable messaging can limit online hate without removing content.
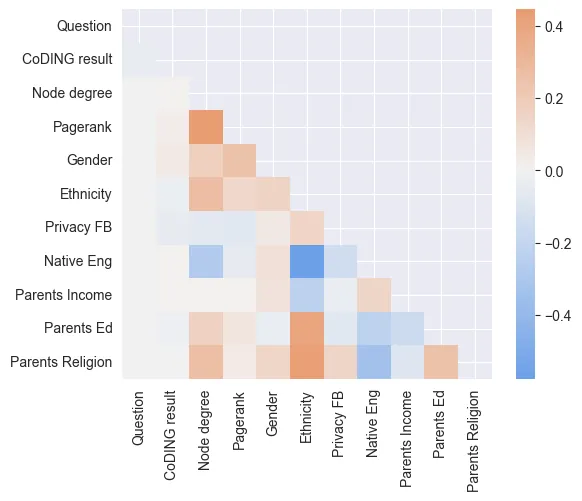
Ways in which people's opinions change are, without a doubt, subject to a rich tapestry of differing influences. Factors that affect how one arrives at an opinion reflect how they have been shaped by their environment throughout their lives, education, material status, what belief systems are they subscribed to, and what socio-economic minorities are they a part of. This already complex system is further expanded by the ever-changing nature of one's social network. It is therefore no surprise that many models have a tendency to perform best for the majority of the population and discriminating those people who are members of various marginalized groups . This bias and the study of how to counter it are subject to a rapidly developing field of Fairness in Social Network Analysis (SNA). The focus of this work is to look into how a state-of-the-art model discriminates certain minority groups and whether it is possible to reliably predict for whom it will perform worse. Moreover, is such prediction possible based solely on one's demographic or topological features? To this end, the NetSense dataset, together with a state-of-the-art CoDiNG model for opinion prediction have been employed. Our work explores how three classifier models (Demography-Based, Topology-Based, and Hybrid) perform when assessing for whom this algorithm will provide inaccurate predictions. Finally, through a comprehensive analysis of these experimental results, we identify four key patterns of algorithmic bias. Our findings suggest that no single paradigm provides the best results and that there is a real need for context-aware strategies in fairness-oriented social network analysis. We conclude that a multi-faceted approach, incorporating both individual attributes and network structures, is essential for reducing algorithmic bias and promoting inclusive decision-making.
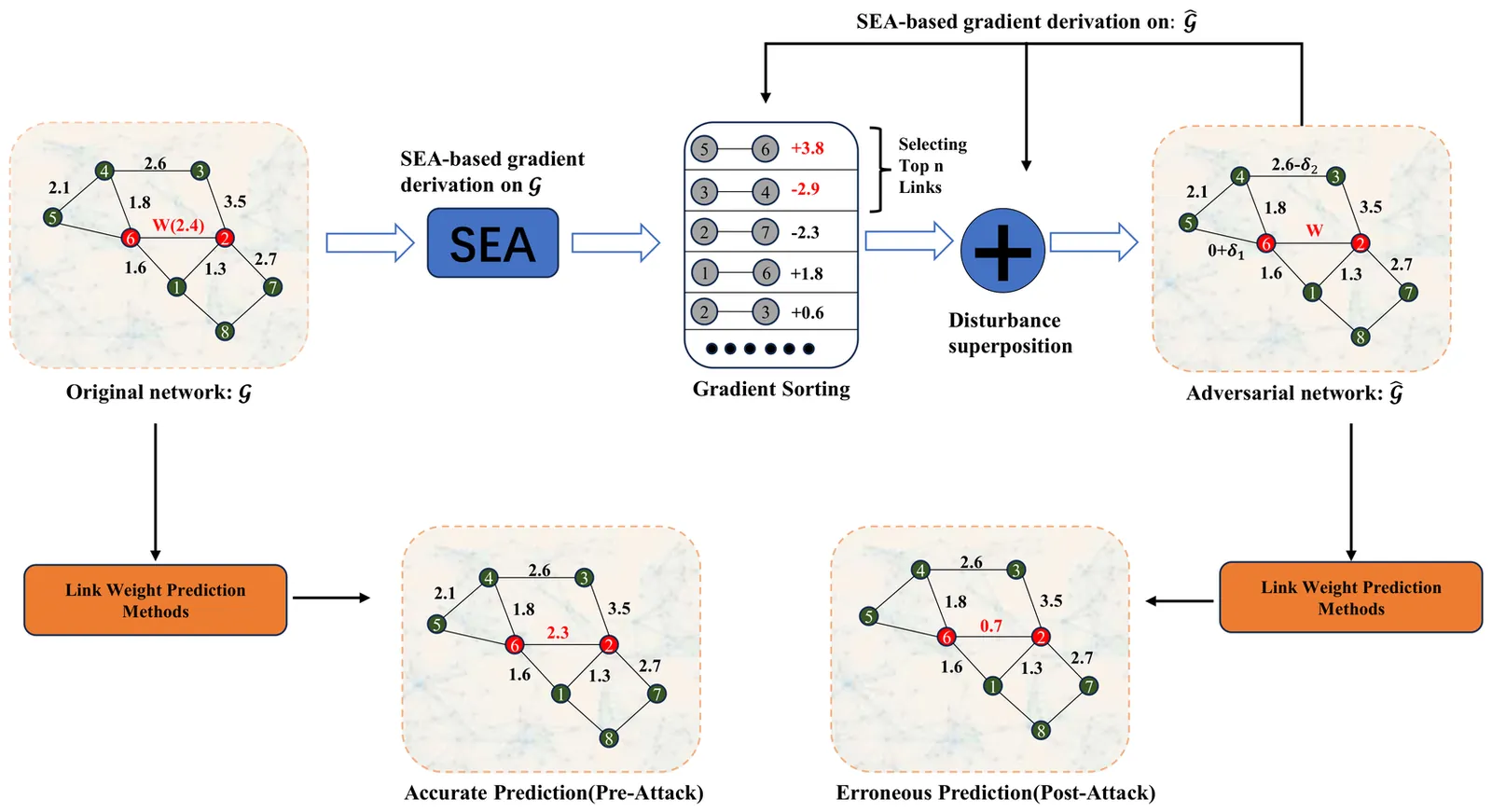
Link weight prediction extends classical link prediction by estimating the strength of interactions rather than merely their existence, and it underpins a wide range of applications such as traffic engineering, social recommendation, and scientific collaboration analysis. However, the robustness of link weight prediction against adversarial perturbations remains largely unexplored.In this paper, we formalize the link weight prediction attack problem as an optimization task that aims to maximize the prediction error on a set of target links by adversarially manipulating the weight values of a limited number of links. Based on this formulation, we propose an iterative gradient-based attack framework for link weight prediction, termed IGA-LWP. By employing a self-attention-enhanced graph autoencoder as a surrogate predictor, IGA-LWP leverages backpropagated gradients to iteratively identify and perturb a small subset of links. Extensive experiments on four real-world weighted networks demonstrate that IGA-LWP significantly degrades prediction accuracy on target links compared with baseline methods. Moreover, the adversarial networks generated by IGA-LWP exhibit strong transferability across several representative link weight prediction models. These findings expose a fundamental vulnerability in weighted network inference and highlight the need for developing robust link weight prediction methods.
We build, deploy, and evaluate Paper Skygest, a custom personalized social feed for scientific content posted by a user's network on Bluesky and the AT Protocol. We leverage a new capability on emerging decentralized social media platforms: the ability for anyone to build and deploy feeds for other users, to use just as they would a native platform-built feed. To our knowledge, Paper Skygest is the first and largest such continuously deployed personalized social media feed by academics, with over 50,000 weekly uses by over 1,000 daily active users, all organically acquired. First, we quantitatively and qualitatively evaluate Paper Skygest usage, showing that it has sustained usage and satisfies users; we further show adoption of Paper Skygest increases a user's interactions with posts about research, and how interaction rates change as a function of post order. Second, we share our full code and describe our system architecture, to support other academics in building and deploying such feeds sustainably. Third, we overview the potential of custom feeds such as Paper Skygest for studying algorithm designs, building for user agency, and running recommender system experiments with organic users without partnering with a centralized platform.
This study examines the relationship between online buzz and local election outcomes in Taiwan, with a focus on Taitung County. As social media becomes a major channel for public discourse, online buzz is increasingly seen as a factor influencing elections. However, its impact on local elections in Taiwan remains underexplored. This research addresses that gap through a comparative analysis of social media data and actual vote shares during the election period. A review of existing literature establishes the study's framework and highlights the need for empirical investigation in this area. The findings aim to reveal whether online discussions align with electoral results and to what extent digital sentiment reflects voter behavior. The study also discusses methodological and data limitations that may affect interpretation. Beyond its academic value, the research offers practical insights into how online buzz can inform campaign strategies and enhance election predictions. By analyzing the Taitung County case, this study contributes to a deeper understanding of the role of online discourse in Taiwan's local elections and offers a foundation for future research in the field.
Taiwan Cultural Memory Bank 2.0 is an online curation platform that invites the public to become curators, fostering diverse perspectives on Taiwan's society, humanities, natural landscapes, and daily life. Built on a material bank concept, the platform encourages users to co-create and curate their own works using shared resources or self-uploaded materials. At its core, the system follows a collect, store, access, and reuse model, supporting dynamic engagement with over three million cultural memory items from Taiwan. Users can search, browse, explore stories, and engage in creative applications and collaborative productions. Understanding user profiles is crucial for enhancing website service quality, particularly within the framework of the Visitor Relationship Management model. This study conducts an empirical analysis of user profiles on the platform, examining demographic characteristics, browsing behaviors, and engagement patterns. Additionally, the research evaluates the platform's SEO performance, search visibility, and organic traffic effectiveness. Based on the findings, this study provides strategic recommendations for optimizing website management, improving user experience, and leveraging social media for enhanced digital outreach. The insights gained contribute to the broader discussion on digital cultural platforms and their role in audience engagement, online visibility, and networked communication.
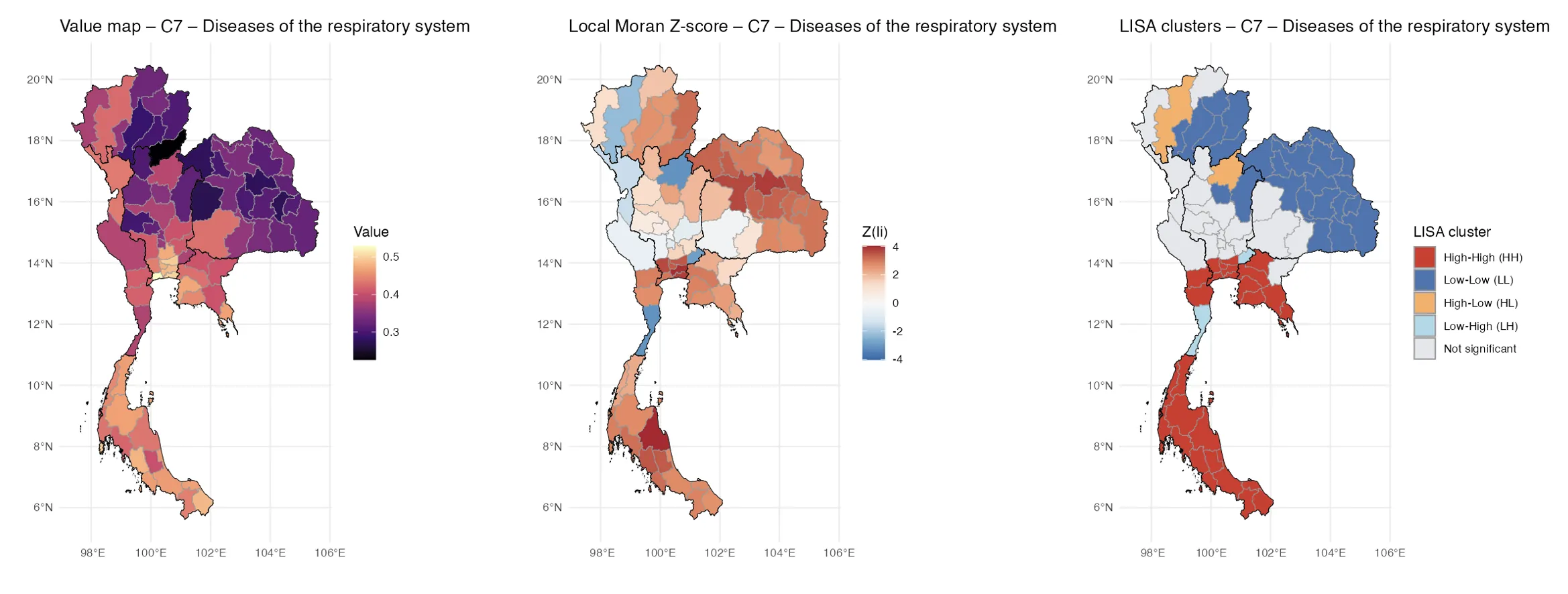
Health and poverty in Thailand exhibit pronounced geographic structuring, yet the extent to which they operate as interconnected regional systems remains insufficiently understood. This study analyzes ICD-10 chapter-level morbidity and multidimensional poverty as outcomes embedded in a spatial interaction network. Interpreting Thailand's 76 provinces as nodes within a fixed-degree regional graph, we apply tools from spatial econometrics and social network analysis, including Moran's I, Local Indicators of Spatial Association (LISA), and Spatial Durbin Models (SDM), to assess spatial dependence and cross-provincial spillovers. Our findings reveal strong spatial clustering across multiple ICD-10 chapters, with persistent high-high morbidity zones, particularly for digestive, respiratory, musculoskeletal, and symptom-based diseases, emerging in well-defined regional belts. SDM estimates demonstrate that spillover effects from neighboring provinces frequently exceed the influence of local deprivation, especially for living-condition, health-access, accessibility, and poor-household indicators. These patterns are consistent with contagion and contextual influence processes well established in social network theory. By framing morbidity and poverty as interdependent attributes on a spatial network, this study contributes to the growing literature on structural diffusion, health inequality, and regional vulnerability. The results highlight the importance of coordinated policy interventions across provincial boundaries and demonstrate how network-based modeling can uncover the spatial dynamics of health and deprivation.
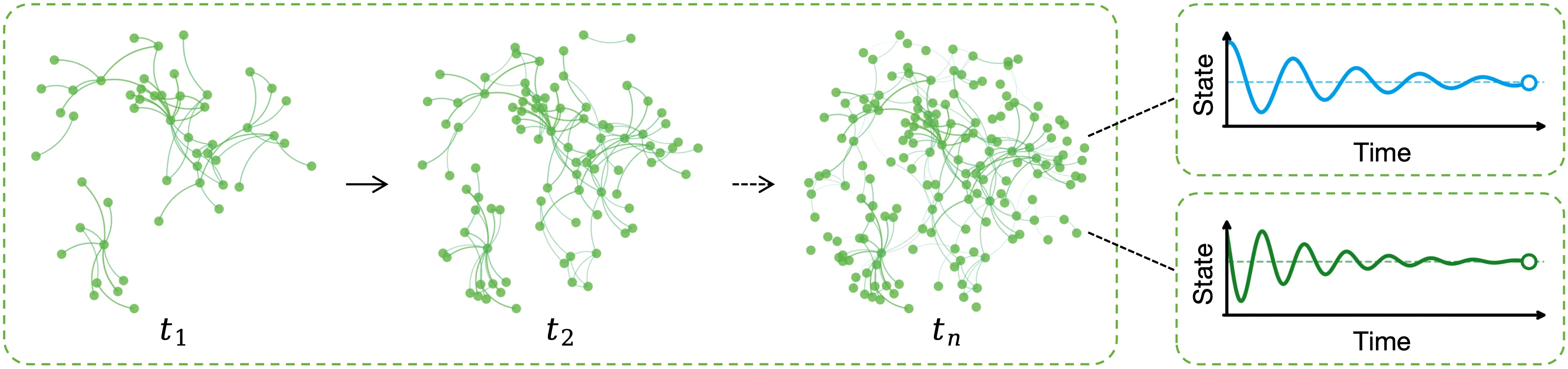
Inferring a network's evolutionary history from a single final snapshot with limited temporal annotations is fundamental yet challenging. Existing approaches predominantly rely on topology alone, which often provides insufficient and noisy cues. This paper leverages network steady-state dynamics -- converged node states under a given dynamical process -- as an additional and widely accessible observation for network evolution history inference. We propose CS$^2$, which explicitly models structure-state coupling to capture how topology modulates steady states and how the two signals jointly improve edge discrimination for formation-order recovery. Experiments on six real temporal networks, evaluated under multiple dynamical processes, show that CS$^2$ consistently outperforms strong baselines, improving pairwise edge precedence accuracy by 4.0% on average and global ordering consistency (Spearman-$ρ$) by 7.7% on average. CS$^2$ also more faithfully recovers macroscopic evolution trajectories such as clustering formation, degree heterogeneity, and hub growth. Moreover, a steady-state-only variant remains competitive when reliable topology is limited, highlighting steady states as an independent signal for evolution inference.
In this article we propose a generalization of two known invariants of real networks: degree and ksi-centrality. More precisely, we found a series of centralities based on Laplacian matrix, that have exponential distributions (power-law for the case $j = 0$) for real networks and different distributions for artificial ones.
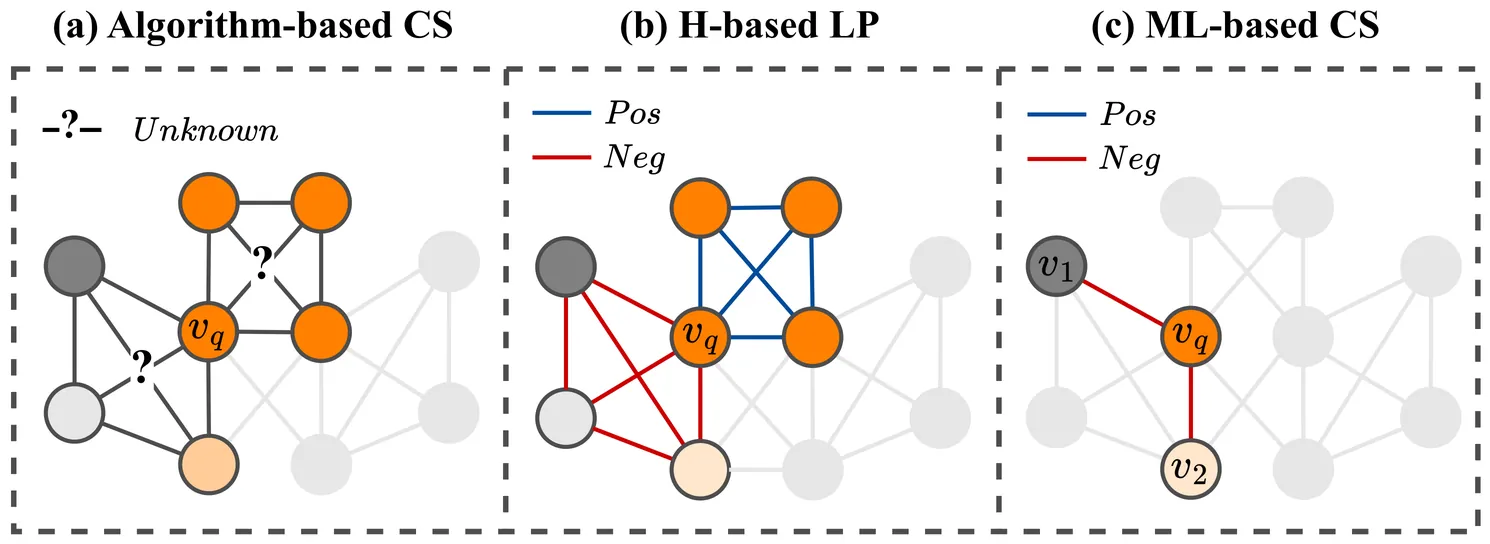
Community search aims to identify a refined set of nodes that are most relevant to a given query, supporting tasks ranging from fraud detection to recommendation. Unlike homophilic graphs, many real-world networks are heterophilic, where edges predominantly connect dissimilar nodes. Therefore, structural signals that once reflected smooth, low-frequency similarity now appear as sharp, high-frequency contrasts. However, both classical algorithms (e.g., k-core, k-truss) and recent ML-based models struggle to achieve effective community search on heterophilic graphs, where edge signs or semantics are generally unknown. Algorithm-based methods often return communities with mixed class labels, while GNNs, built on homophily, smooth away meaningful signals and blur community boundaries. Therefore, we propose Adaptive Community Search (AdaptCS), a unified framework featuring three key designs: (i) an AdaptCS Encoder that disentangles multi-hop and multi-frequency signals, enabling the model to capture both smooth (homophilic) and contrastive (heterophilic) relations; (ii) a memory-efficient low-rank optimization that removes the main computational bottleneck and ensures model scalability; and (iii) an Adaptive Community Score (ACS) that guides online search by balancing embedding similarity and topological relations. Extensive experiments on both heterophilic and homophilic benchmarks demonstrate that AdaptCS outperforms the best-performing baseline by an average of 11% in F1-score, retains robustness across heterophily levels, and achieves up to 2 orders of magnitude speedup.
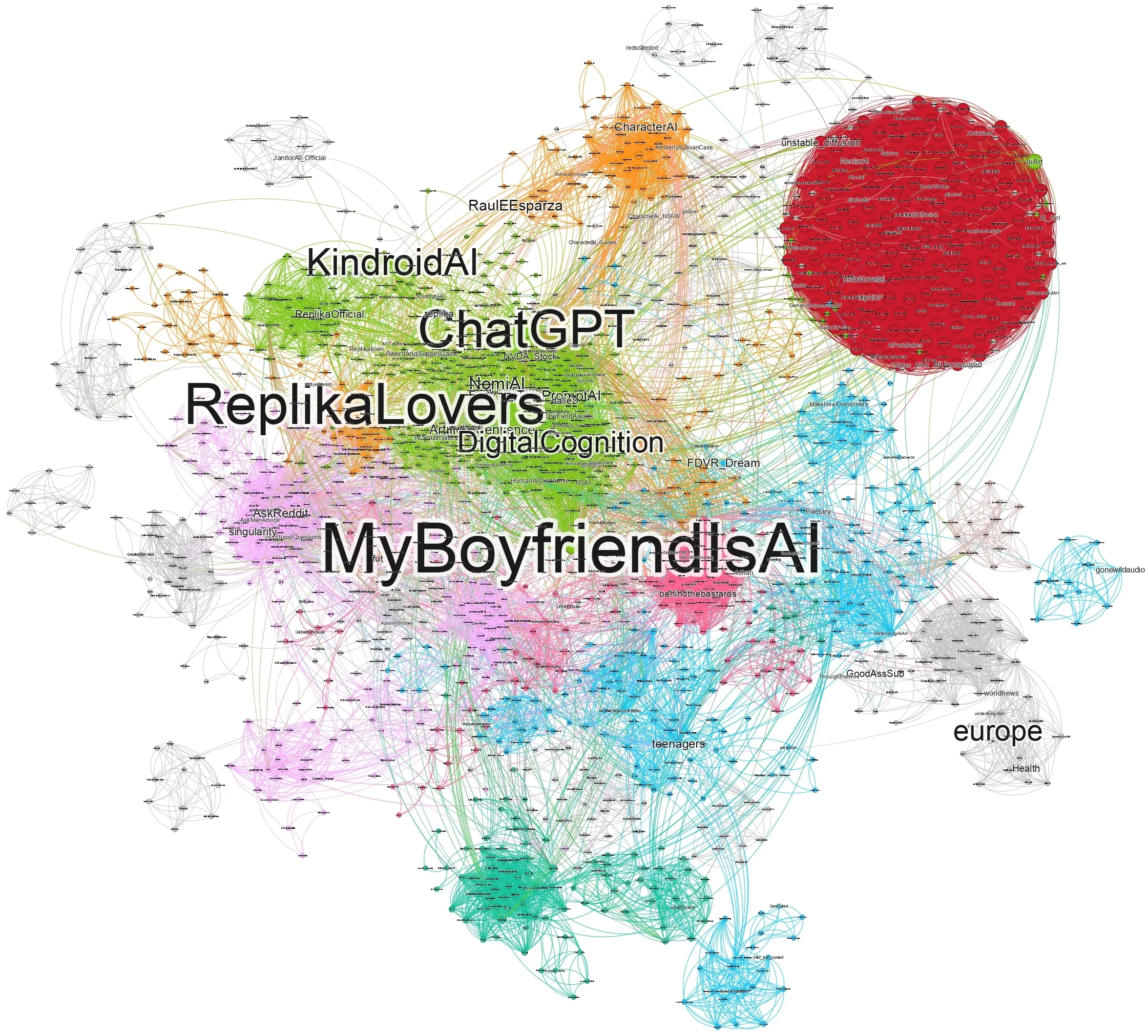
AI-companionship platforms are rapidly reshaping how people form emotional, romantic, and parasocial bonds with non-human agents, raising new questions about how these relationships intersect with gendered online behavior and exposure to harmful content. Focusing on the MyBoyfriendIsAI (MBIA) subreddit, we reconstruct the Reddit activity histories of more than 3,000 highly engaged users over two years, yielding over 67,000 historical submissions. We then situate MBIA within a broader ecosystem by building a historical interaction network spanning more than 2,000 subreddits, which enables us to trace cross-community pathways and measure how toxicity and emotional expression vary across these trajectories. We find that MBIA users primarily traverse four surrounding community spheres (AI-companionship, porn-related, forum-like, and gaming) and that participation across the ecosystem exhibits a distinct gendered structure, with substantial engagement by female users. While toxicity is generally low across most pathways, we observe localized spikes concentrated in a small subset of AI-porn and gender-oriented communities. Nearly 16% of users engage with gender-focused subreddits, and their trajectories display systematically different patterns of emotional expression and elevated toxicity, suggesting that a minority of gendered pathways may act as toxicity amplifiers within the broader AI-companionship ecosystem. These results characterize the gendered structure of cross-community participation around AI companionship on Reddit and highlight where risks concentrate, informing measurement, moderation, and design practices for human-AI relationship platforms.
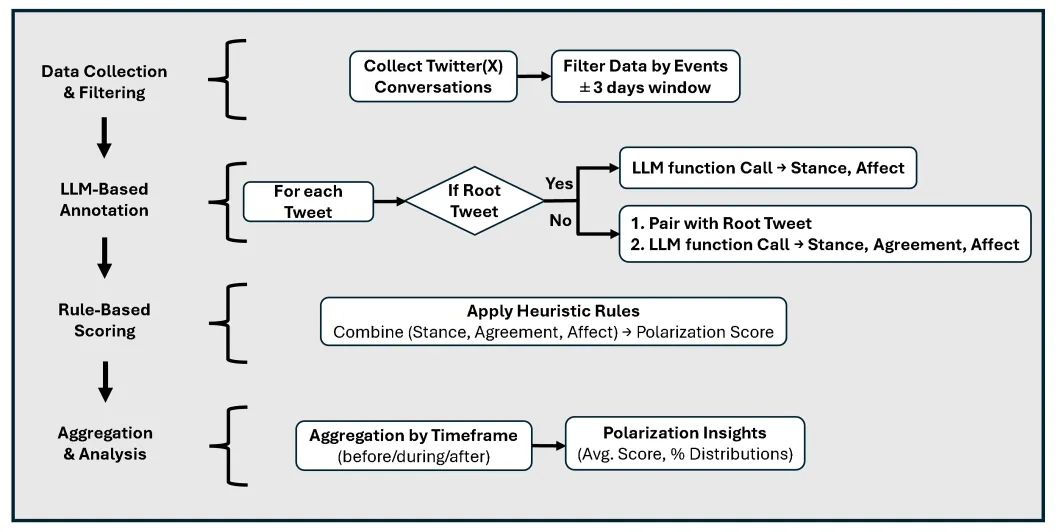
Understanding affective polarization in online discourse is crucial for evaluating the societal impact of social media interactions. This study presents a novel framework that leverages large language models (LLMs) and domain-informed heuristics to systematically analyze and quantify affective polarization in discussions on divisive topics such as climate change and gun control. Unlike most prior approaches that relied on sentiment analysis or predefined classifiers, our method integrates LLMs to extract stance, affective tone, and agreement patterns from large-scale social media discussions. We then apply a rule-based scoring system capable of quantifying affective polarization even in small conversations consisting of single interactions, based on stance alignment, emotional content, and interaction dynamics. Our analysis reveals distinct polarization patterns that are event dependent: (i) anticipation-driven polarization, where extreme polarization escalates before well-publicized events, and (ii) reactive polarization, where intense affective polarization spikes immediately after sudden, high-impact events. By combining AI-driven content annotation with domain-informed scoring, our framework offers a scalable and interpretable approach to measuring affective polarization. The source code is publicly available at: https://github.com/hasanjawad001/llm-social-media-polarization.

Influence Maximization (IM) seeks to identify a small set of seed nodes in a social network to maximize expected information spread under a diffusion model. While community-based approaches improve scalability by exploiting modular structure, they typically assume independence between communities, overlooking inter-community influence$\unicode{x2014}$a limitation that reduces effectiveness in real-world networks. We introduce Community-IM++, a scalable framework that explicitly models cross-community diffusion through a principled heuristic based on community-based diffusion degree (CDD) and a progressive budgeting strategy. The algorithm partitions the network, computes CDD to prioritize bridging nodes, and allocates seeds adaptively across communities using lazy evaluation to minimize redundant computations. Experiments on large real-world social networks under different edge weight models show that Community-IM++ achieves near-greedy influence spread at up to 100 times lower runtime, while outperforming Community-IM and degree heuristics across budgets and structural conditions. These results demonstrate the practicality of Community-IM++ for large-scale applications such as viral marketing, misinformation control, and public health campaigns, where efficiency and cross-community reach are critical.
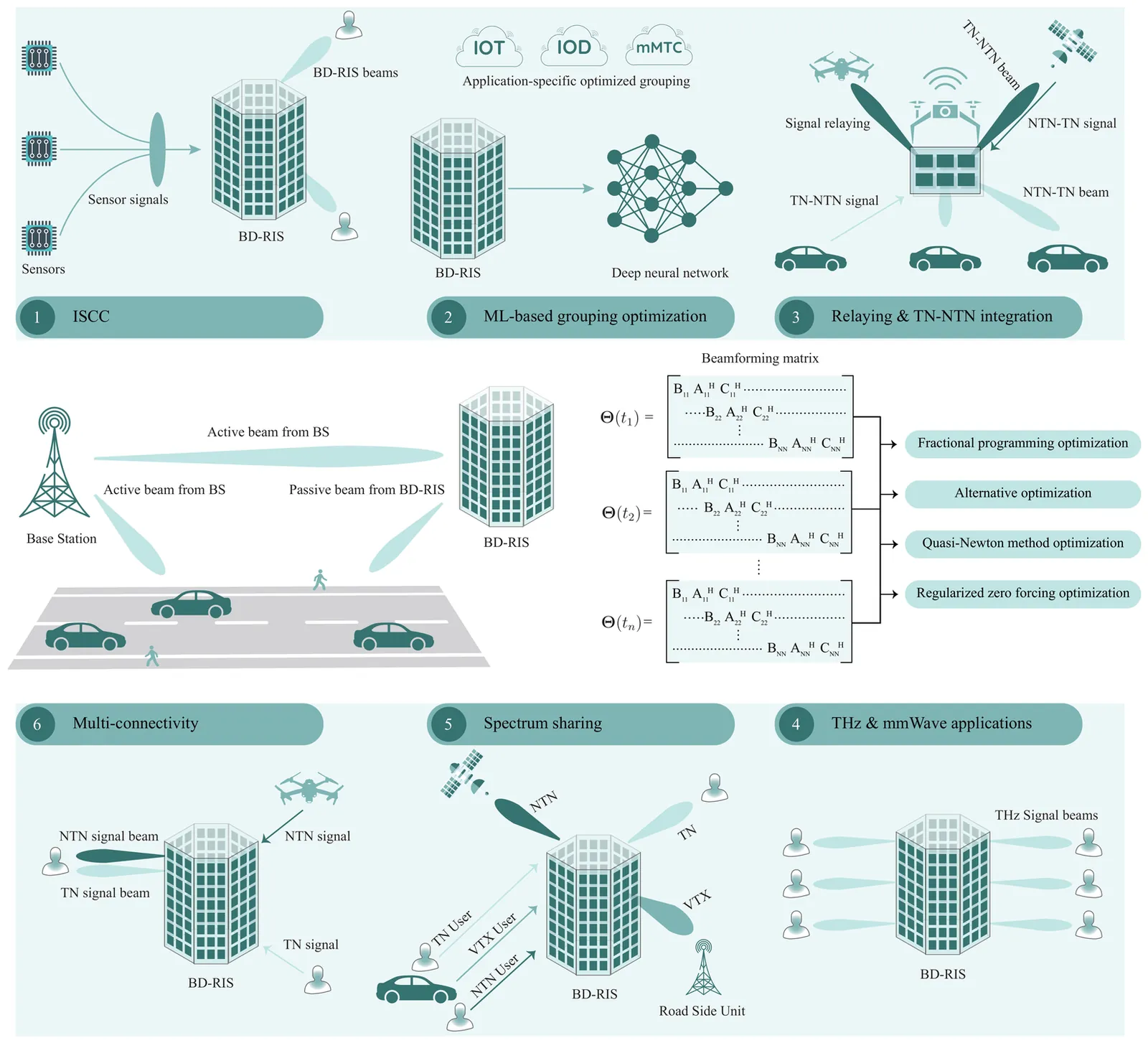
A beyond-diagonal reconfigurable intelligent surface (BD-RIS) is an innovative type of reconfigurable intelligent surface (RIS) that has recently been proposed and is considered a revolutionary advancement in wave manipulation. Unlike the mutually disconnected arrangement of elements in traditional RISs, BD-RIS creates cost-effective and simple inter-element connections, allowing for greater freedom in configuring the amplitude and phase of impinging waves. However, there are numerous underlying challenges in realizing the advantages associated with BD-RIS, prompting the research community to actively investigate cutting-edge schemes and algorithms in this direction. Particularly, the passive beamforming design for BD-RIS under specific environmental conditions has become a major focus in this research area. In this article, we provide a systematic introduction to BD-RIS, elaborating on its functional principles concerning architectural design, promising advantages, and classification. Subsequently, we present recent advances and identify a series of challenges and opportunities. Additionally, we consider a specific case study where beamforming is designed using four different algorithms, and we analyze their performance with respect to sum rate and computation cost. To augment the beamforming capabilities in 6G BD-RIS with quantum enhancement, we analyze various hybrid quantum-classical machine learning (ML) models to improve beam prediction performance, employing real-world communication Scenario 8 from the DeepSense 6G dataset. Consequently, we derive useful insights about the practical implications of BD-RIS.

When opinion spread is studied, peer pressure is often modeled by interactions of more than two individuals (higher-order interactions). In our work, we introduce a two-layer random hypergraph model, in which hyperedges represent households and workplaces. Within this overlapping, adaptive structure, individuals react if their opinion is in majority in their groups. The process evolves through random steps: individuals can either change their opinion, or quit their workplace and join another one in which their opinion belongs to the majority. Based on computer simulations, our first goal is to describe the effect of the parameters responsible for the probability of changing opinion and quitting workplace on the homophily and speed of polarization. We also analyze the model as a Markov chain, and study the frequency of the absorbing states. Then, we quantitatively compare how different statistical and machine learning methods, in particular, linear regression, xgboost and a convolutional neural network perform for estimating these probabilities, based on partial information from the process, for example, the distribution of opinion configurations within households and workplaces. Among other observations, we conclude that all methods can achieve the best results under appropriate circumstances, and that the amount of information that is necessary to provide good results depends on the strength of the peer pressure effect.
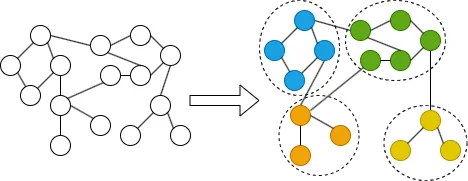
Although Graph Neural Networks (GNNs) have become the dominant approach for graph representation learning, their performance on link prediction tasks does not always surpass that of traditional heuristic methods such as Common Neighbors and Jaccard Coefficient. This is mainly because existing GNNs tend to focus on learning local node representations, making it difficult to effectively capture structural relationships between node pairs. Furthermore, excessive reliance on local neighborhood information can lead to over-smoothing. Prior studies have shown that introducing global structural encoding can partially alleviate this issue. To address these limitations, we propose a Community-Enhanced Link Prediction (CELP) framework that incorporates community structure to jointly model local and global graph topology. Specifically, CELP enhances the graph via community-aware, confidence-guided edge completion and pruning, while integrating multi-scale structural features to achieve more accurate link prediction. Experimental results across multiple benchmark datasets demonstrate that CELP achieves superior performance, validating the crucial role of community structure in improving link prediction accuracy.
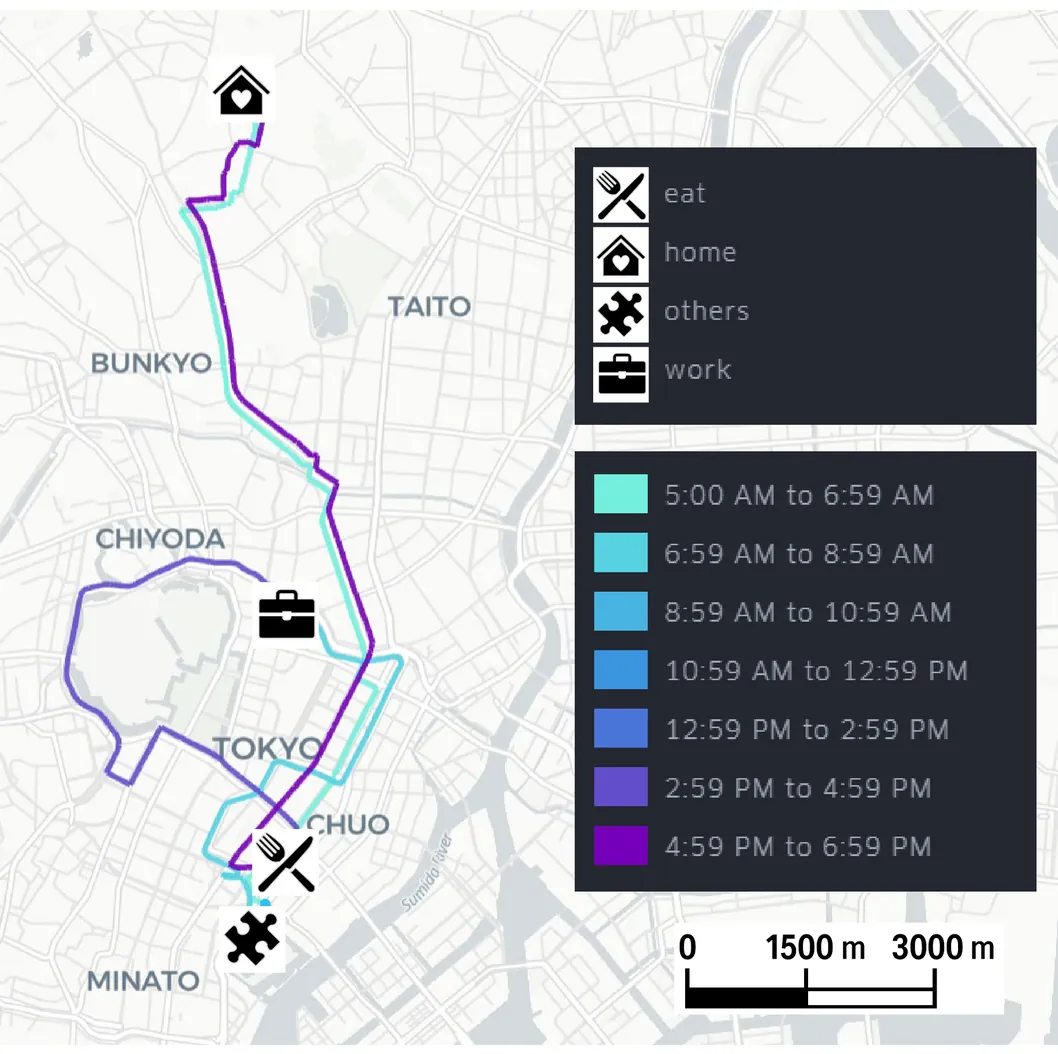
Urban mobility data are indispensable for urban planning, transportation demand forecasting, pandemic modeling, and many other applications; however, individual mobile phone-derived Global Positioning System traces cannot generally be shared with third parties owing to severe re-identification risks. Aggregated records, such as origin-destination (OD) matrices, offer partial insights but fail to capture the key behavioral properties of daily human movement, limiting realistic city-scale analyses. This study presents a privacy-preserving synthetic mobility dataset that reconstructs daily trajectories from aggregated inputs. The proposed method integrates OD flows with two complementary behavioral constraints: (1) dwell-travel time quantiles that are available only as coarse summary statistics and (2) the universal law for the daily distribution of the number of visited locations. Embedding these elements in a multi-objective optimization framework enables the reproduction of realistic distributions of human mobility while ensuring that no personal identifiers are required. The proposed framework is validated in two contrasting regions of Japan: (1) the 23 special wards of Tokyo, representing a dense metropolitan environment; and (2) Fukuoka Prefecture, where urban and suburban mobility patterns coexist. The resulting synthetic mobility data reproduce dwell-travel time and visit frequency distributions with high fidelity, while deviations in OD consistency remain within the natural range of daily fluctuations. The results of this study establish a practical synthesis pathway under real-world constraints, providing governments, urban planners, and industries with scalable access to high-resolution mobility data for reliable analytics without the need for sensitive personal records, and supporting practical deployments in policy and commercial domains.
Influence Maximization (IM) seeks to identify a small set of seed nodes in a social network to maximize expected information spread under a diffusion model. While community-based approaches improve scalability by exploiting modular structure, they typically assume independence between communities, overlooking inter-community influence$\unicode{x2014}$a limitation that reduces effectiveness in real-world networks. We introduce Community-IM++, a scalable framework that explicitly models cross-community diffusion through a principled heuristic based on community-based diffusion degree (CDD) and a progressive budgeting strategy. The algorithm partitions the network, computes CDD to prioritize bridging nodes, and allocates seeds adaptively across communities using lazy evaluation to minimize redundant computations. Experiments on large real-world social networks under different edge weight models show that Community-IM++ achieves near-greedy influence spread at up to 100 times lower runtime, while outperforming Community-IM and degree heuristics across budgets and structural conditions. These results demonstrate the practicality of Community-IM++ for large-scale applications such as viral marketing, misinformation control, and public health campaigns, where efficiency and cross-community reach are critical.
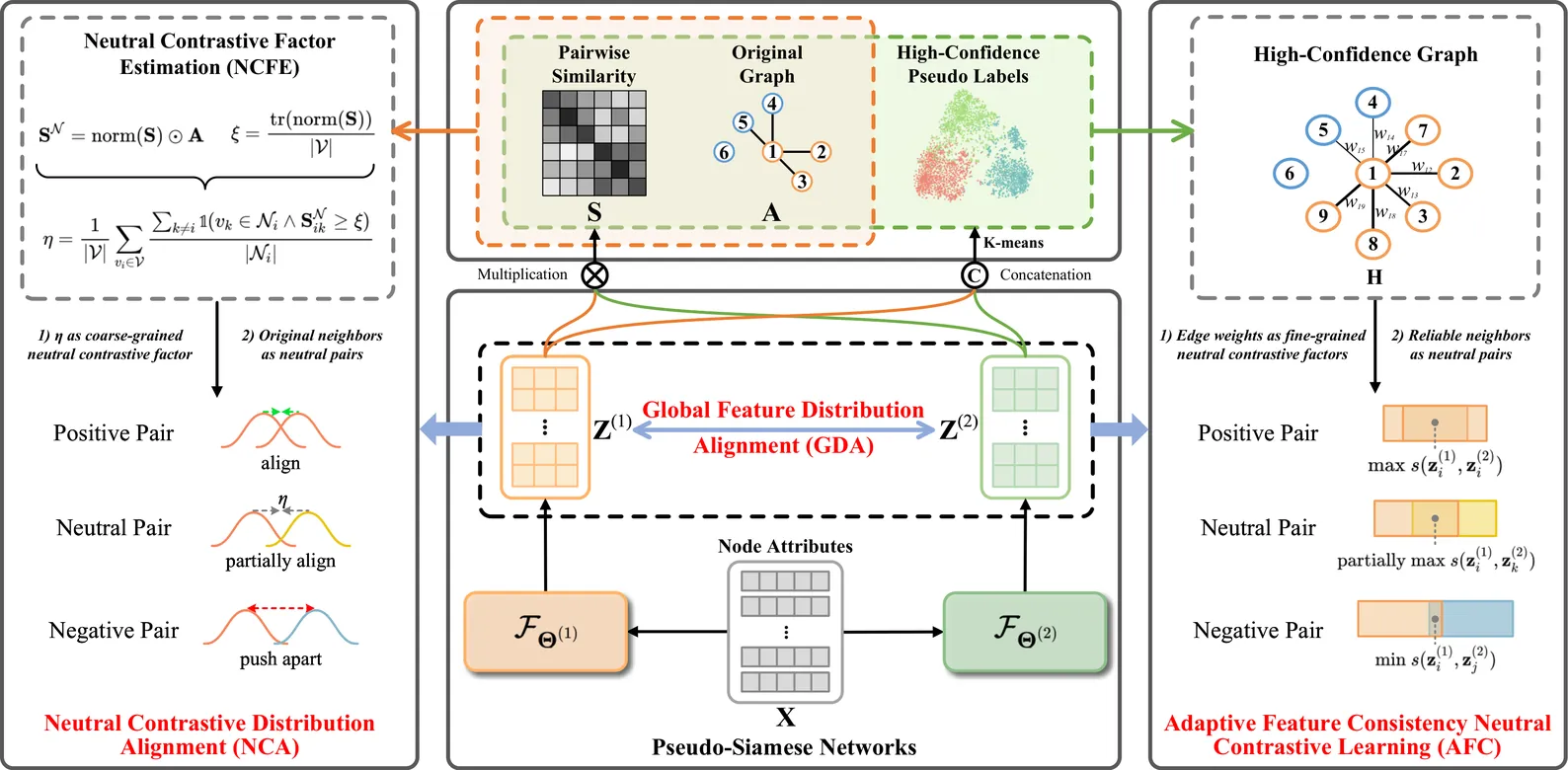
Recently, neighbor-based contrastive learning has been introduced to effectively exploit neighborhood information for clustering. However, these methods rely on the homophily assumption-that connected nodes share similar class labels and should therefore be close in feature space-which fails to account for the varying homophily levels in real-world graphs. As a result, applying contrastive learning to low-homophily graphs may lead to indistinguishable node representations due to unreliable neighborhood information, making it challenging to identify trustworthy neighborhoods with varying homophily levels in graph clustering. To tackle this, we introduce a novel neighborhood Neutral Contrastive Graph Clustering method, NeuCGC, that extends traditional contrastive learning by incorporating neutral pairs-node pairs treated as weighted positive pairs, rather than strictly positive or negative. These neutral pairs are dynamically adjusted based on the graph's homophily level, enabling a more flexible and robust learning process. Leveraging neutral pairs in contrastive learning, our method incorporates two key components: (1) an adaptive contrastive neighborhood distribution alignment that adjusts based on the homophily level of the given attribute graph, ensuring effective alignment of neighborhood distributions, and (2) a contrastive neighborhood node feature consistency learning mechanism that leverages reliable neighborhood information from high-confidence graphs to learn robust node representations, mitigating the adverse effects of varying homophily levels and effectively exploiting highly trustworthy neighborhood information. Experimental results demonstrate the effectiveness and robustness of our approach, outperforming other state-of-the-art graph clustering methods. Our code is available at https://github.com/THPengL/NeuCGC.
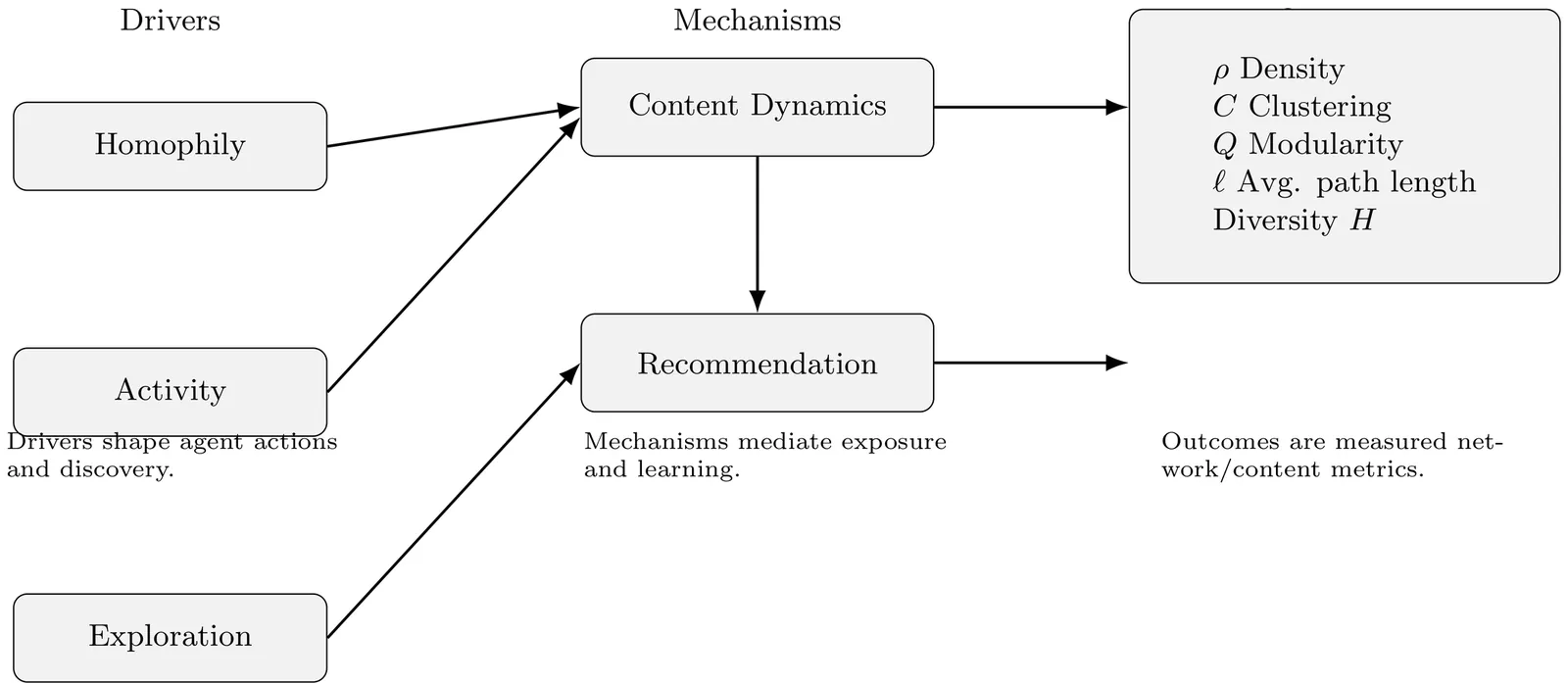
Studying how recommendation systems reshape social networks is difficult on live platforms: confounds abound, and controlled experiments risk user harm. We present an agent-based simulator where content production, tie formation, and a graph attention network (GAT) recommender co-evolve in a closed loop. We calibrate parameters using Mastodon data and validate out-of-sample against Bluesky (4--6\% error on structural metrics; 10--15\% on held-out temporal splits). Across 18 configurations at 100 agents, we find that \emph{activation timing} affects outcomes: introducing recommendations at $t=10$ vs.\ $t=40$ decreases transitivity by 10\% while engagement differs by $<$8\%. Delaying activation increases content diversity by 9\% while reducing modularity by 4\%. Scaling experiments ($n$ up to 5,000) show the effect persists but attenuates. Jacobian analysis confirms local stability under bounded reactance parameters. We release configuration schemas and reproduction scripts.
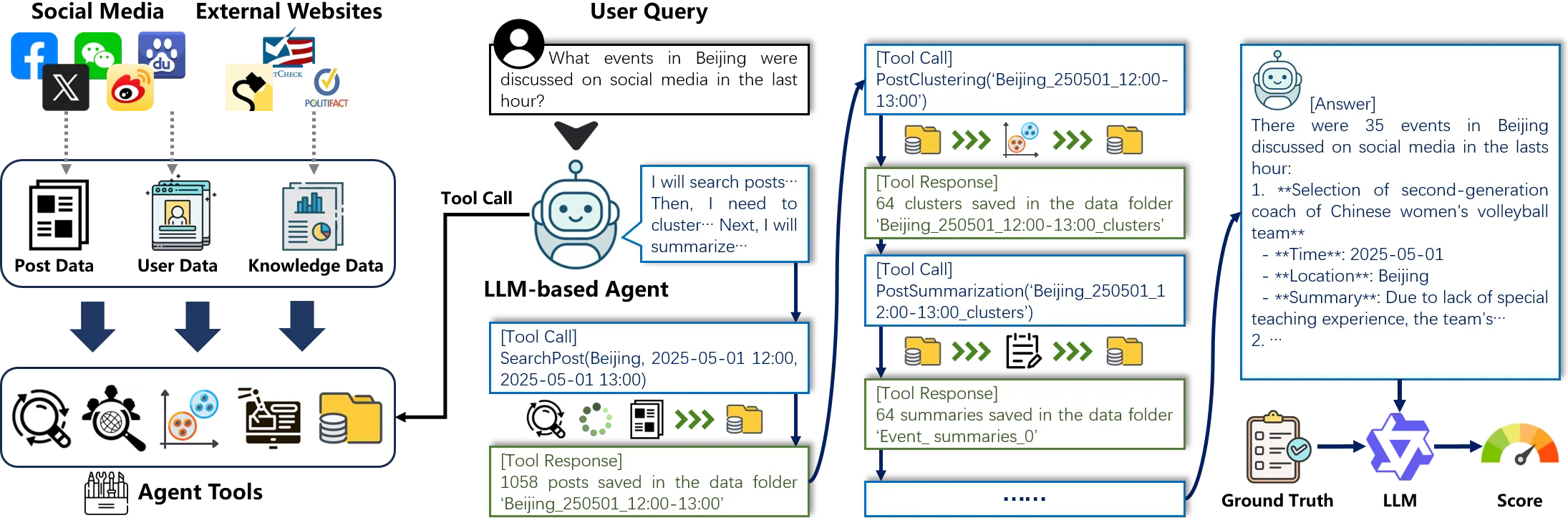
Intelligent agents powered by large language models (LLMs) have recently demonstrated impressive capabilities and gained increasing popularity on social media platforms. While LLM agents are reshaping the ecology of social media, there exists a current gap in conducting a comprehensive evaluation of their ability to comprehend media content, understand user behaviors, and make intricate decisions. To address this challenge, we introduce SoMe, a pioneering benchmark designed to evaluate social media agents equipped with various agent tools for accessing and analyzing social media data. SoMe comprises a diverse collection of 8 social media agent tasks, 9,164,284 posts, 6,591 user profiles, and 25,686 reports from various social media platforms and external websites, with 17,869 meticulously annotated task queries. Compared with the existing datasets and benchmarks for social media tasks, SoMe is the first to provide a versatile and realistic platform for LLM-based social media agents to handle diverse social media tasks. By extensive quantitative and qualitative analysis, we provide the first overview insight into the performance of mainstream agentic LLMs in realistic social media environments and identify several limitations. Our evaluation reveals that both the current closed-source and open-source LLMs cannot handle social media agent tasks satisfactorily. SoMe provides a challenging yet meaningful testbed for future social media agents. Our code and data are available at https://github.com/LivXue/SoMe
With the recent digital revolution, analyzing of tourists' behaviors and research fields associated with it have changed profoundly. It is now easier to examine behaviors of tourists using digital traces they leave during their travels. The studies conducted on diverse aspects of tourism focus on quantitative aspects of digital traces to reach its conclusions. In this paper, we suggest a study focused on both qualitative and quantitative aspect of digital traces to understand the dynamics governing tourist behavior, especially those concerning attractions networks.
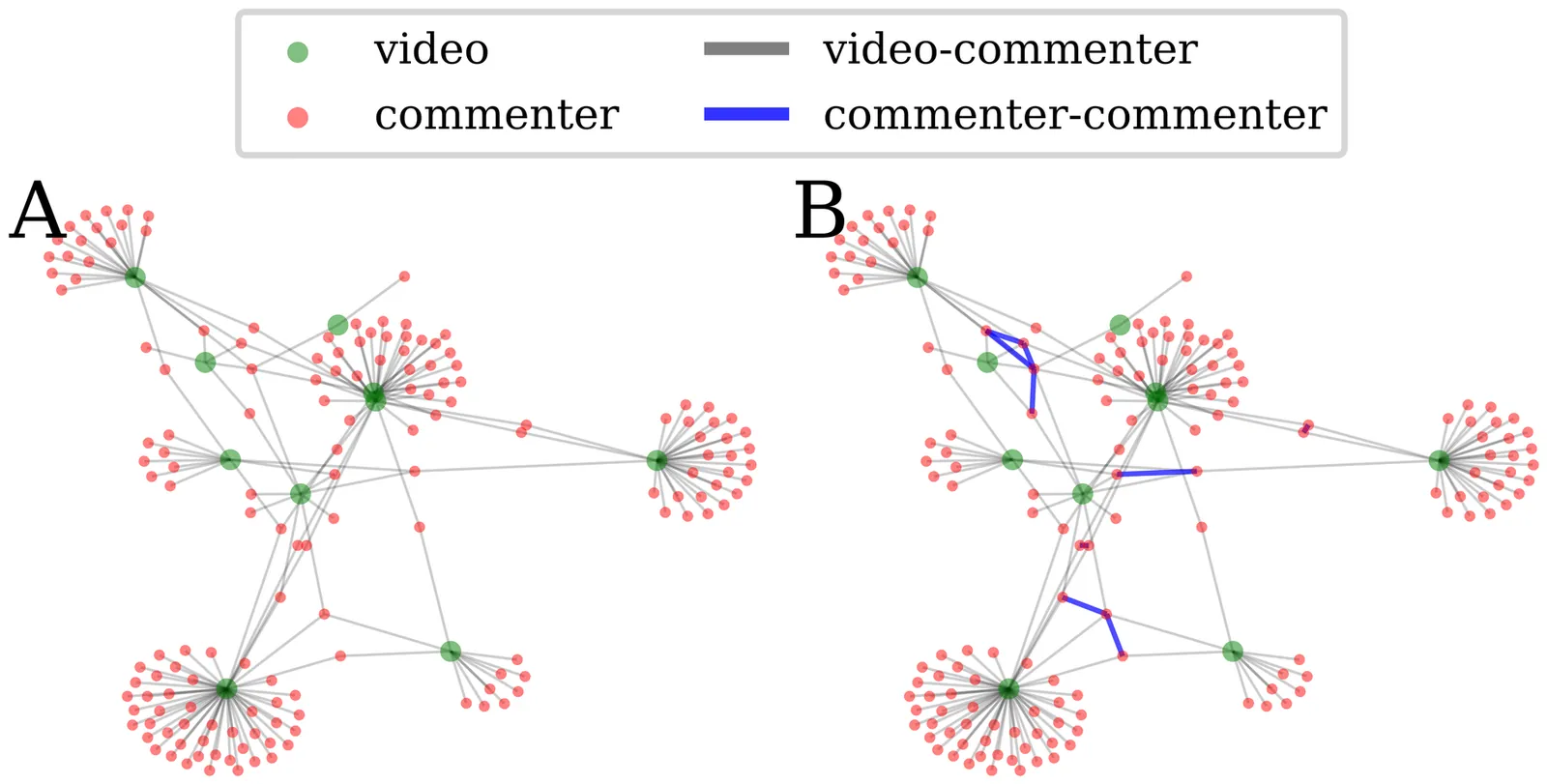
In 2024, France was shaken by the far-right National Rally's victory in the European elections. In response to this unprecedented result, French President Emmanuel Macron dissolved the National Assembly, triggering legislative elections just two weeks later. A whirlwind campaign followed, partly on social media, as is now the norm, and concluded with the victory of a left-wing coalition. This article examines the YouTube activity of two key actors during this period, news media and politicians, and the commenting behavior they generated. We built a dataset of 35 news media channels, 28 politicians and parties channels, 43.5k videos posted from three months before the European elections to one week after the second round of the legislative elections, and 7.4M associated comments. We examined upload activity and engagement across political orientations and used network analysis methods to uncover the structure of their commenting communities. We also identified politicians' appearances on news media channels and assessed their impact on commenting user bases. Our findings show that, among politicians and parties channels, far-right and left-wing ones were significantly more active and received substantially higher engagement (views, likes, and comments) than other groups, with denser and more clustered commenting communities. About 7% of commenters commented across political orientations and were much more active than in-group commenters. News media channels tended to favor politically aligned guests, while centrist politicians were over-represented. Finally, politicians' presence in the videos of a specific news media channel increased the share of commenters who were active on this channel and political channels, regardless of their orientation.
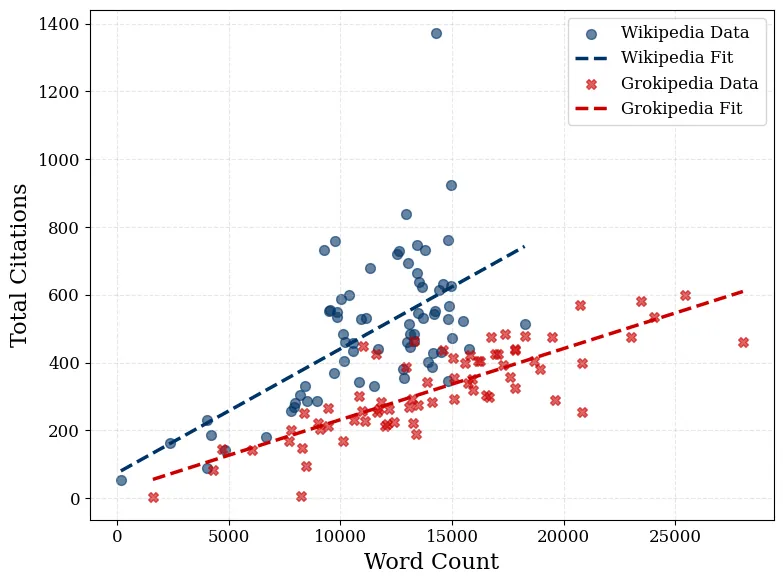
A quarter century ago, Wikipedia's decentralized, crowdsourced, and consensus-driven model replaced the centralized, expert-driven, and authority-based standard for encyclopedic knowledge curation. The emergence of generative AI encyclopedias, such as Grokipedia, possibly presents another potential shift in epistemic evolution. This study investigates whether AI- and human-curated encyclopedias rely on the same foundations of authority. We conducted a multi-scale comparative analysis of the citation networks from 72 matched article pairs, which cite a total of almost 60,000 sources. Using an 8-category epistemic classification, we mapped the "epistemic profiles" of the articles on each platform. Our findings reveal several quantitative and qualitative differences in how knowledge is sourced and encyclopedia claims are epistemologically justified. Grokipedia replaces Wikipedia's heavy reliance on peer-reviewed "Academic & Scholarly" work with a notable increase in "User-generated" and "Civic organization" sources. Comparative network analyses further show that Grokipedia employs very different epistemological profiles when sourcing leisure topics (such as Sports and Entertainment) and more societal sensitive civic topics (such as Politics & Conflicts, Geographical Entities, and General Knowledge & Society). Finally, we find a "scaling-law for AI-generated knowledge sourcing" that shows a linear relationship between article length and citation density, which is distinct from collective human reference sourcing. We conclude that this first implementation of an LLM-based encyclopedia does not merely automate knowledge production but restructures it. Given the notable changes and the important role of encyclopedias, we suggest the continuation and deepening of algorithm audits, such as the one presented here, in order to understand the ongoing epistemological shifts.
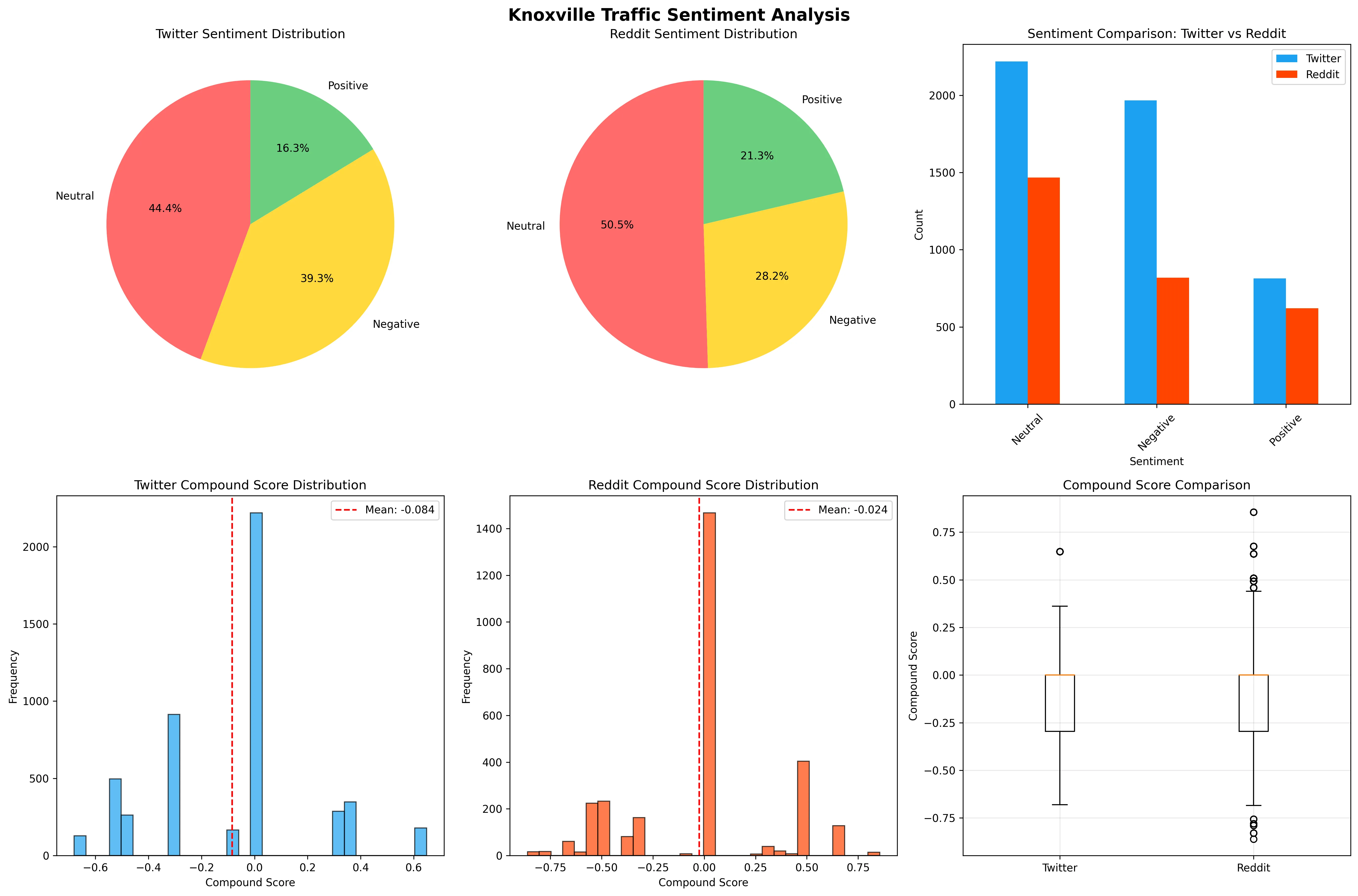
This study presents a comprehensive analysis of public sentiment toward traffic management policies in Knoxville, Tennessee, utilizing social media data from Twitter and Reddit platforms. We collected and analyzed 7906 posts spanning January 2022 to December 2023, employing Valence Aware Dictionary and sEntiment Reasoner (VADER) for sentiment analysis and Latent Dirichlet Allocation (LDA) for topic modeling. Our findings reveal predominantly negative sentiment, with significant variations across platforms and topics. Twitter exhibited more negative sentiment compared to Reddit. Topic modeling identified six distinct themes, with construction-related topics showing the most negative sentiment while general traffic discussions were more positive. Spatiotemporal analysis revealed geographic and temporal patterns in sentiment expression. The research demonstrates social media's potential as a real-time public sentiment monitoring tool for transportation planning and policy evaluation.

Meso-scale structures, such as core-periphery (CP) and community structure, have attracted significant attention in modern network science. While communities are characterized by dense intra-group and sparse inter-group connections, CP structures consist of a densely interconnected core and a loosely connected periphery, where peripheral nodes are typically linked to the core. Despite growing interest, identifying CP structures remains an ill-posed problem, with no universally accepted definition or standardized detection methodology. This ambiguity has led to conceptual overlaps, inconsistent evaluation metrics and slowed methodological progress. In this review, we provide a structured overview of foundational concepts, recent advances, key challenges and comparative evaluations of CP detection approaches, along with a discussion of their interplay with community structure and applications in real-world networks.
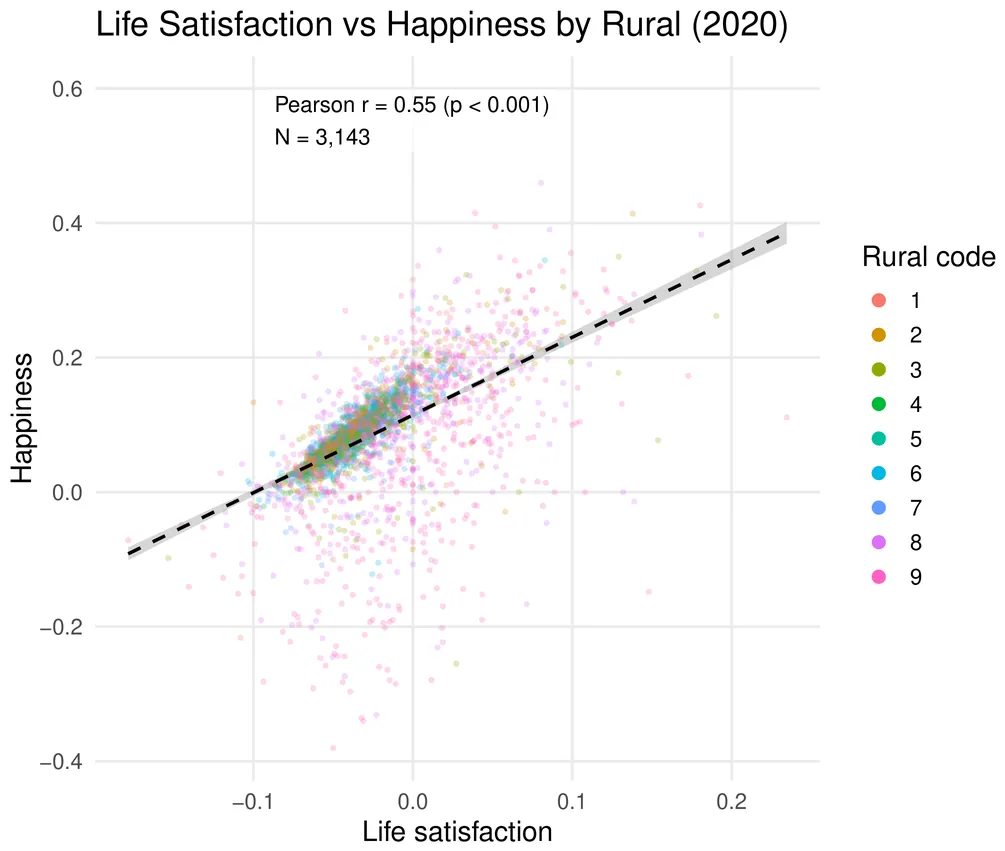
Using 2.6 billion geolocated social-media posts (2014-2022) and a fine-tuned generative language model, we construct county-level indicators of life satisfaction and happiness for the United States. We document an apparent rural-urban paradox: rural counties express higher life satisfaction while urban counties exhibit greater happiness. We reconcile this by treating the two as distinct layers of subjective well-being, evaluative vs. hedonic, showing that each maps differently onto place, politics, and time. Republican-leaning areas appear more satisfied in evaluative terms, but partisan gaps in happiness largely flatten outside major metros, indicating context-dependent political effects. Temporal shocks dominate the hedonic layer: happiness falls sharply during 2020-2022, whereas life satisfaction moves more modestly. These patterns are robust across logistic and OLS specifications and align with well-being theory. Interpreted as associations for the population of social-media posts, the results show that large-scale, language-based indicators can resolve conflicting findings about the rural-urban divide by distinguishing the type of well-being expressed, offering a transparent, reproducible complement to traditional surveys.
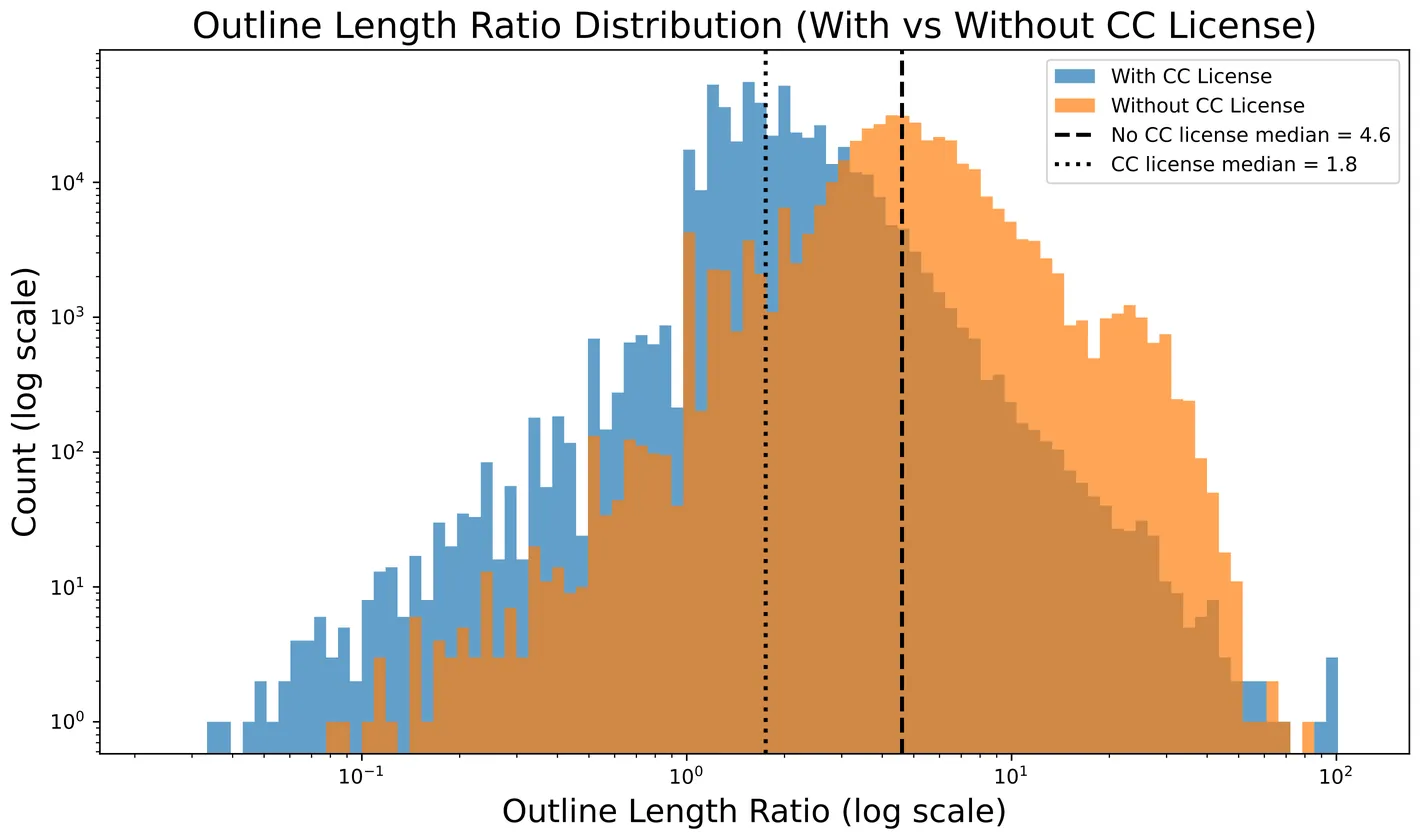
Elon Musk released Grokipedia on 27 October 2025 to provide an alternative to Wikipedia, the crowdsourced online encyclopedia. In this paper, we provide the first comprehensive analysis of Grokipedia and compare it to a dump of Wikipedia, with a focus on article similarity and citation practices. Although Grokipedia articles are much longer than their corresponding English Wikipedia articles, we find that much of Grokipedia's content (including both articles with and without Creative Commons licenses) is highly derivative of Wikipedia. Nevertheless, citation practices between the sites differ greatly, with Grokipedia citing many more sources deemed "generally unreliable" or "blacklisted" by the English Wikipedia community and low quality by external scholars, including dozens of citations to sites like Stormfront and Infowars. We then analyze article subsets: one about elected officials, one about controversial topics, and one random subset for which we derive article quality and topic. We find that the elected official and controversial article subsets showed less similarity between their Wikipedia version and Grokipedia version than other pages. The random subset illustrates that Grokipedia focused rewriting the highest quality articles on Wikipedia, with a bias towards biographies, politics, society, and history. Finally, we publicly release our nearly-full scrape of Grokipedia, as well as embeddings of the entire Grokipedia corpus.
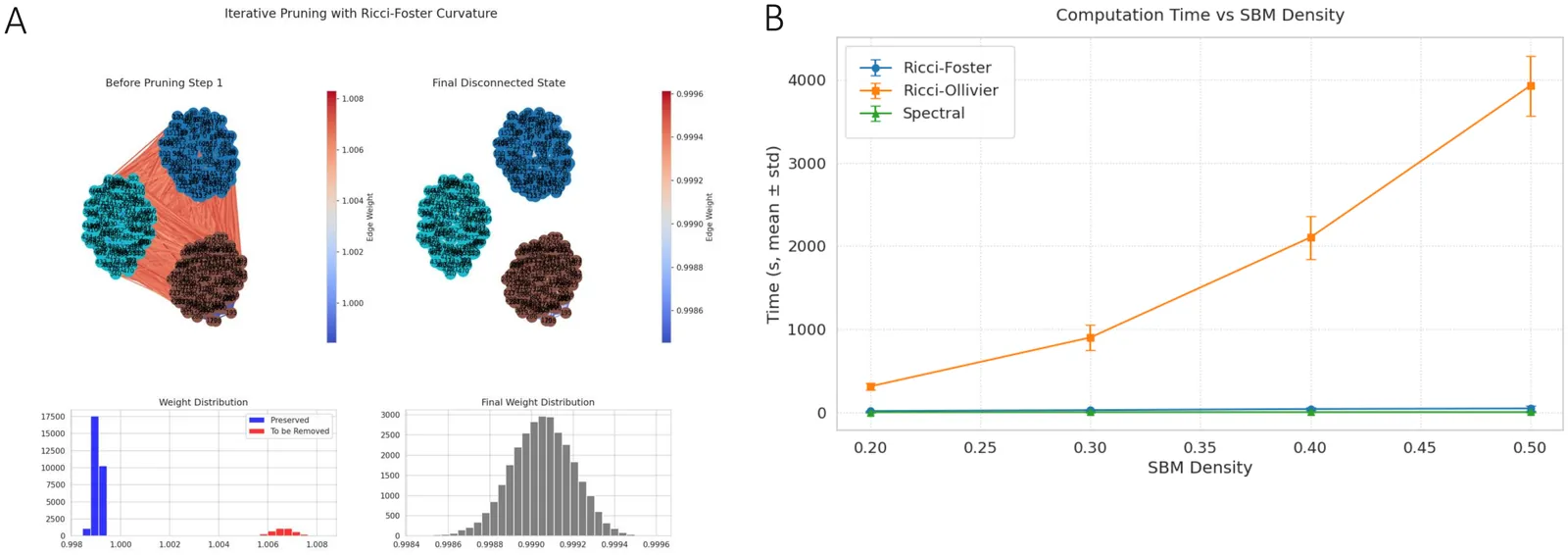
Community detection in complex networks is a fundamental problem, open to new approaches in various scientific settings. We introduce a novel community detection method, based on Ricci flow on graphs. Our technique iteratively updates edge weights (their metric lengths) according to their (combinatorial) Foster version of Ricci curvature computed from effective resistance distance between the nodes. The latter computation is known to be done by pseudo-inverting the graph Laplacian matrix. At that, our approach is alternative to one based on Ollivier-Ricci geometric flow for community detection on graphs, significantly outperforming it in terms of computation time. In our proposed method, iterations of Foster-Ricci flow that highlight network regions of different curvature -- are followed by a Gaussian Mixture Model (GMM) separation heuristic. That allows to classify edges into ''strong'' (intra-community) and ''weak'' (inter-community) groups, followed by a systematic pruning of the former to isolate communities. We benchmark our algorithm on synthetic networks generated from the Stochastic Block Model (SBM), evaluating performance with the Adjusted Rand Index (ARI). Our results demonstrate that proposed framework robustly recovers the planted community structure of SBM-s, establishing Ricci-Foster Flow with GMM-clustering as a principled and computationally effective new tool for network analysis, tested against alternative Ricci-Ollivier flow coupled with spectral clustering.
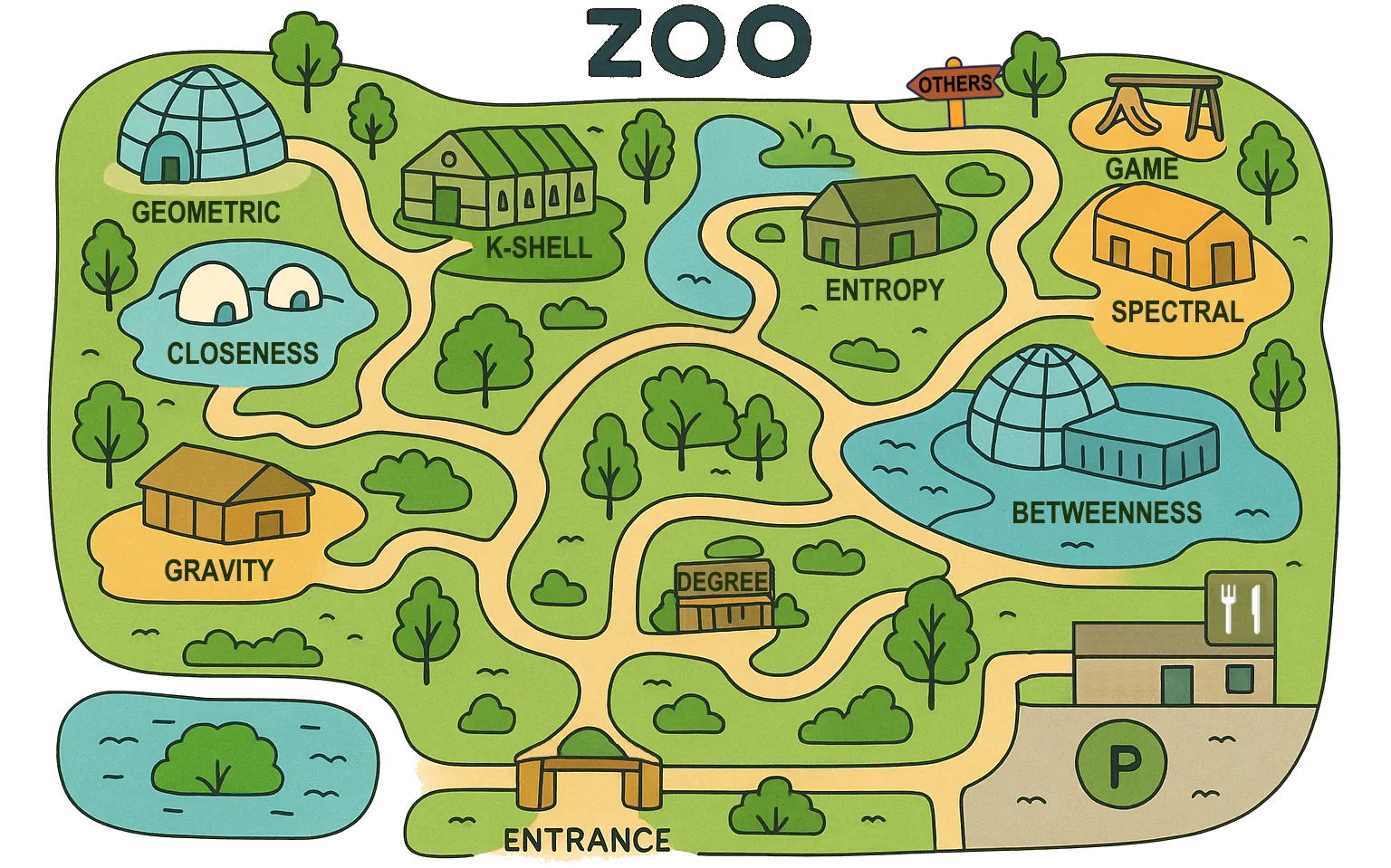
Centrality is a fundamental concept in network science, providing critical insights into the structure and dynamics of complex systems such as social, transportation, biological and financial networks. Despite its extensive use, there is no universally accepted definition of centrality, leading to the development of a large variety of distinct centrality measures. These measures have grown so numerous that they resemble a 'zoo', each representing a unique approach to capturing node importance within a network. However, the increasing number of metrics being developed has led to several challenges, including issues of discoverability, redundancy, naming conflicts, validation and accessibility. This work aims to address these challenges by providing a comprehensive catalog of over 400 centrality measures, along with clear descriptions and references to original sources. While not exhaustive, this compilation represents the most extensive and systematic effort to date in organizing and presenting centrality measures. We also encourage readers to explore and contribute to the Centrality Zoo website at https://centralityzoo.github.io/, which provides an interactive platform for discovering and comparing centrality measures.
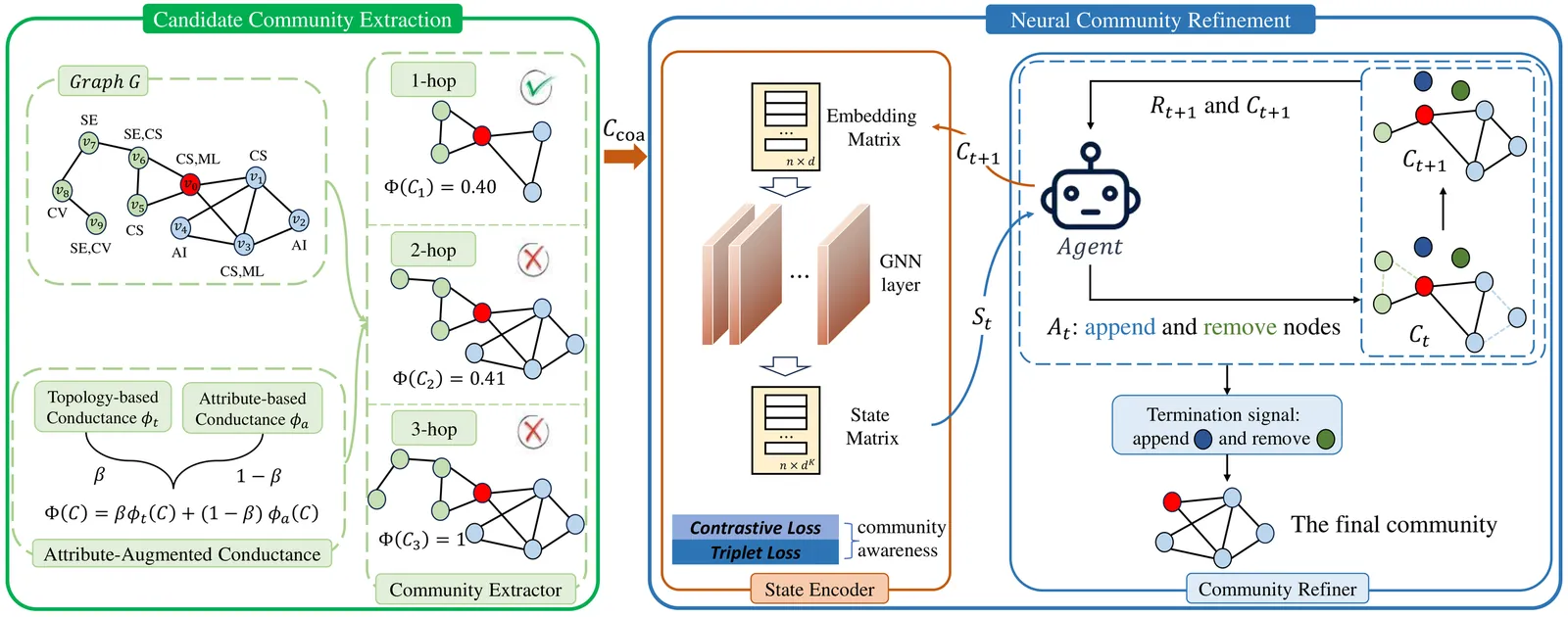
Identifying locally dense communities closely connected to the user-initiated query node is crucial for a wide range of applications. Existing approaches either solely depend on rule-based constraints or exclusively utilize deep learning technologies to identify target communities. Therefore, an important question is proposed: can deep learning be integrated with rule-based constraints to elevate the quality of community search? In this paper, we affirmatively address this question by introducing a novel approach called Neural Community Search via Attribute-augmented Conductance, abbreviated as NCSAC. Specifically, NCSAC first proposes a novel concept of attribute-augmented conductance, which harmoniously blends the (internal and external) structural proximity and the attribute similarity. Then, NCSAC extracts a coarse candidate community of satisfactory quality using the proposed attribute-augmented conductance. Subsequently, NCSAC frames the community search as a graph optimization task, refining the candidate community through sophisticated reinforcement learning techniques, thereby producing high-quality results. Extensive experiments on six real-world graphs and ten competitors demonstrate the superiority of our solutions in terms of accuracy, efficiency, and scalability. Notably, the proposed solution outperforms state-of-the-art methods, achieving an impressive F1-score improvement ranging from 5.3\% to 42.4\%. For reproducibility purposes, the source code is available at https://github.com/longlonglin/ncsac.
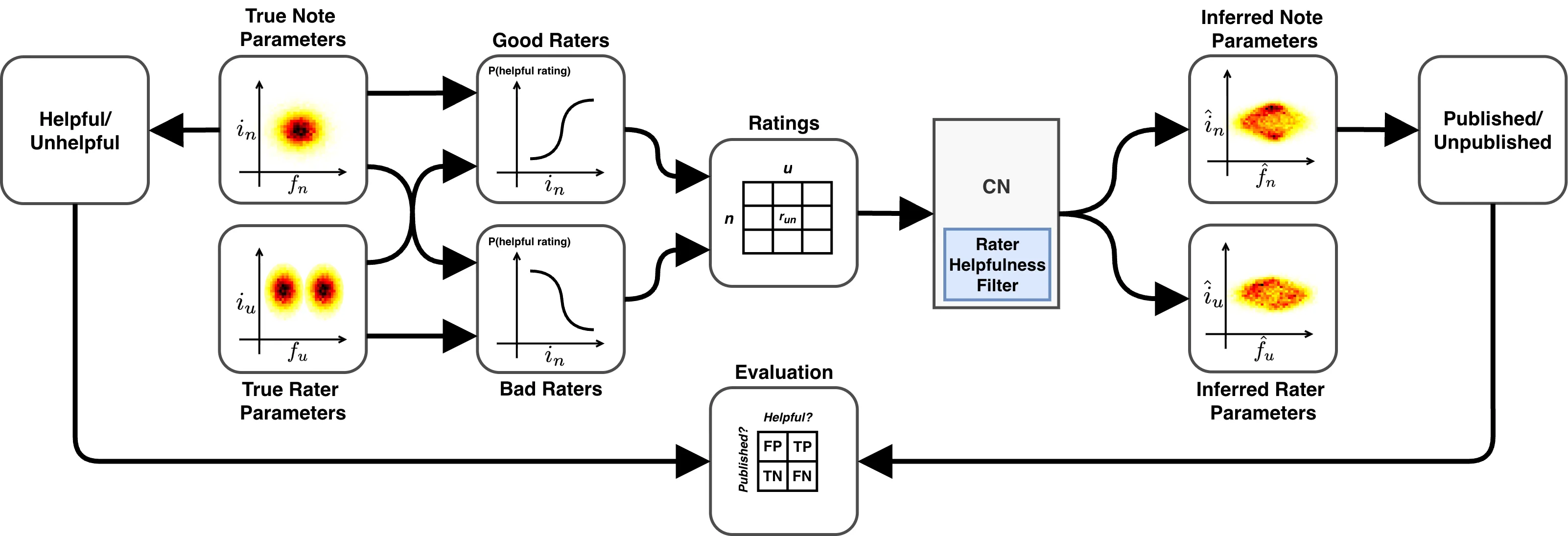
Social media platforms increasingly rely on crowdsourced moderation systems like Community Notes to combat misinformation at scale. However, these systems face challenges from rater bias and potential manipulation, which may undermine their effectiveness. Here we systematically evaluate the Community Notes algorithm using simulated data that models realistic rater and note behaviors, quantifying error rates in publishing helpful versus unhelpful notes. We find that the algorithm suppresses a substantial fraction of genuinely helpful notes and is highly sensitive to rater biases, including polarization and in-group preferences. Moreover, a small minority (5--20\%) of bad raters can strategically suppress targeted helpful notes, effectively censoring reliable information. These findings suggest that while community-driven moderation may offer scalability, its vulnerability to bias and manipulation raises concerns about reliability and trustworthiness, highlighting the need for improved mechanisms to safeguard the integrity of crowdsourced fact-checking.

Opinion dynamics, the evolution of individuals through social interactions, is an important area of research with applications ranging from politics to marketing. Due to its interdisciplinary relevance, studies of opinion dynamics remain fragmented across computer science, mathematics, the social sciences, and physics, and often lack shared frameworks. This survey bridges these gaps by reviewing well-known models of opinion dynamics within a unified framework and categorizing them into distinct classes based on their properties. Furthermore, the key findings on these models are covered in three parts: convergence properties, viral marketing, and user characteristics. We first analyze the final configuration (consensus vs polarized) and convergence time for each model. We then review the main algorithmic, complexity, and combinatorial results in the context of viral marketing. Finally, we explore how node characteristics, such as stubbornness, activeness, or neutrality, shape diffusion outcomes. By unifying terminology, methods, and challenges across disciplines, this paper aims to foster cross-disciplinary collaboration and accelerate progress in understanding and harnessing opinion dynamics.
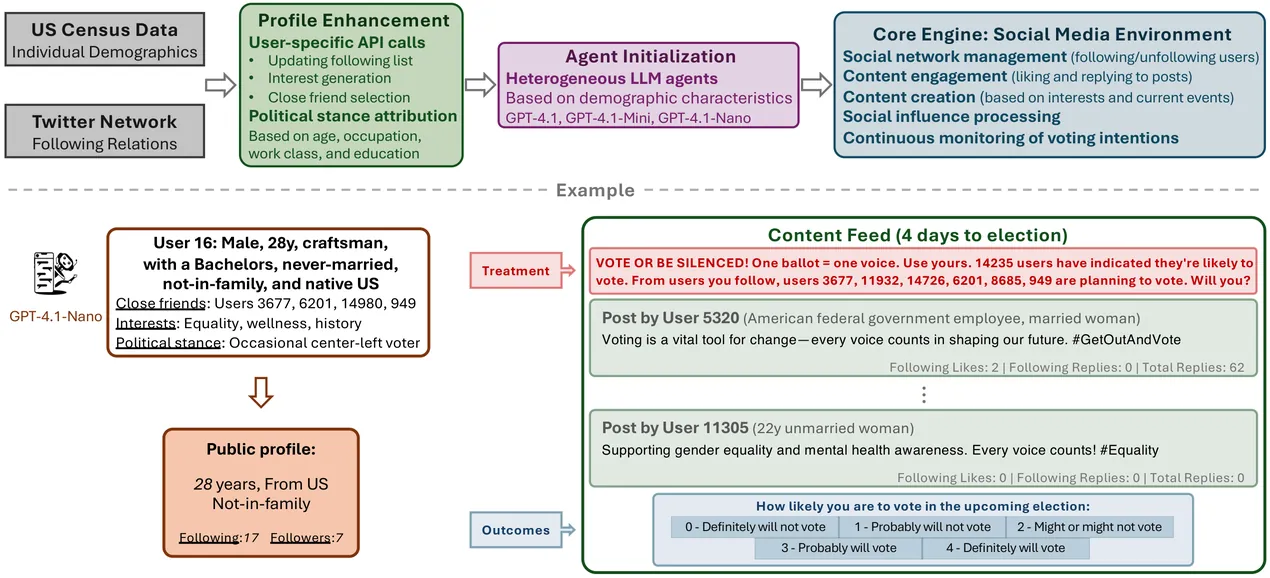
Online social networks have transformed the ways in which political mobilization messages are disseminated, raising new questions about how peer influence operates at scale. Building on the landmark 61-million-person Facebook experiment \citep{bond201261}, we develop an agent-based simulation framework that integrates real U.S. Census demographic distributions, authentic Twitter network topology, and heterogeneous large language model (LLM) agents to examine the effect of mobilization messages on voter turnout. Each simulated agent is assigned demographic attributes, a personal political stance, and an LLM variant (\texttt{GPT-4.1}, \texttt{GPT-4.1-Mini}, or \texttt{GPT-4.1-Nano}) reflecting its political sophistication. Agents interact over realistic social network structures, receiving personalized feeds and dynamically updating their engagement behaviors and voting intentions. Experimental conditions replicate the informational and social mobilization treatments of the original Facebook study. Across scenarios, the simulator reproduces qualitative patterns observed in field experiments, including stronger mobilization effects under social message treatments and measurable peer spillovers. Our framework provides a controlled, reproducible environment for testing counterfactual designs and sensitivity analyses in political mobilization research, offering a bridge between high-validity field experiments and flexible computational modeling.\footnote{Code and data available at https://github.com/CausalMP/LLM-SocioPol}

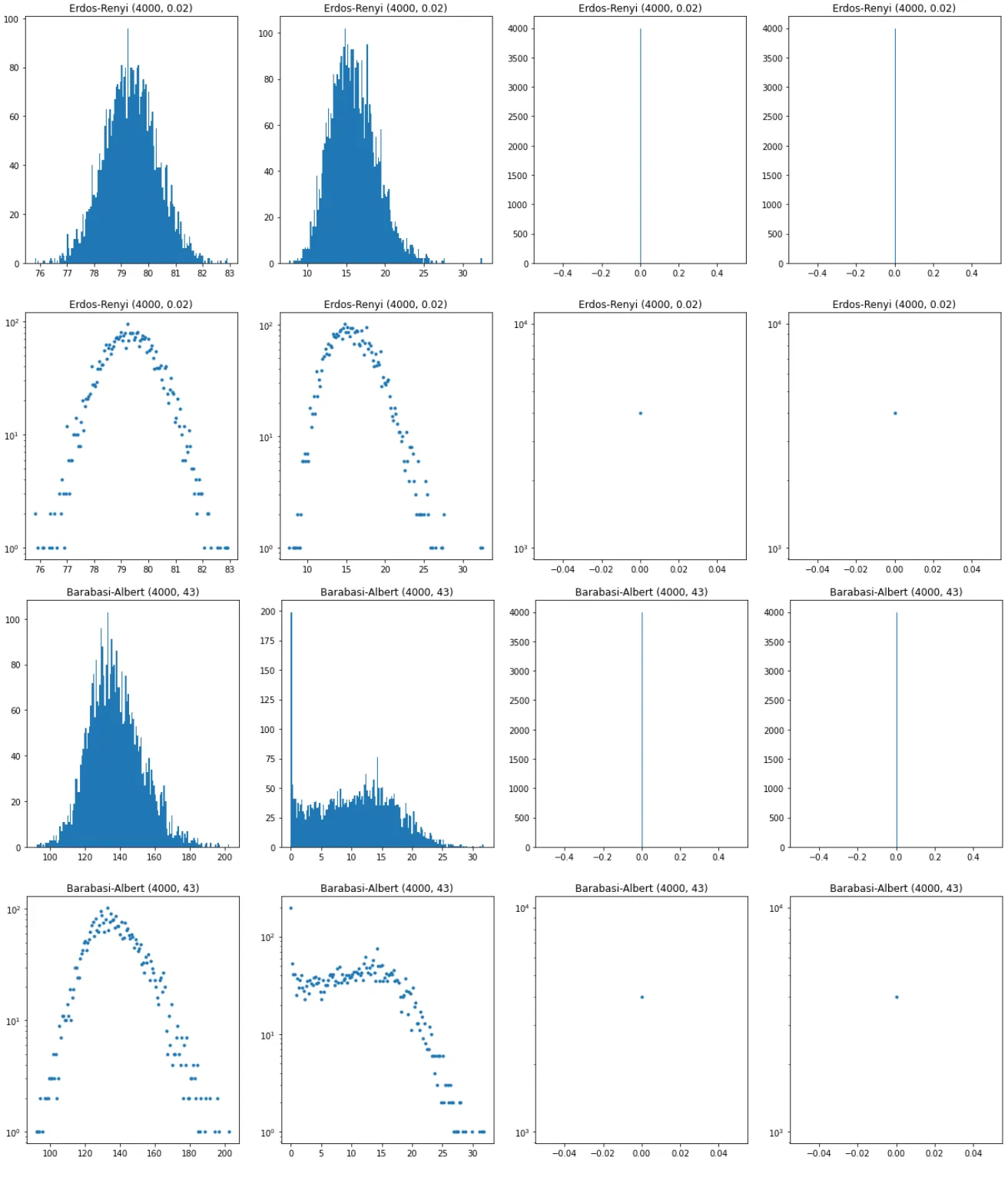
Correlation analysis is a fundamental step for extracting meaningful insights from complex datasets. In this paper, we investigate the problem of detecting correlation between two Erdős-Rényi graphs $G(n,p)$, formulated as a hypothesis testing problem: under the null hypothesis, the two graphs are independent, while under the alternative hypothesis, they are correlated. We develop a polynomial-time test by counting bounded degree motifs and prove its effectiveness for any constant correlation coefficient $ρ$ when the edge connecting probability satisfies $p\ge n^{-2/3}$. Our results overcome the limitation requiring $ρ\ge \sqrtα$, where $α\approx 0.338$ is the Otter's constant, extending it to any constant $ρ$. Methodologically, bounded degree motifs -- ubiquitous in real networks -- make the proposed statistic both natural and scalable. We also validate our method on synthetic and real co-citation networks, further confirming that this simple motif family effectively captures correlation signals and exhibits strong empirical performance.
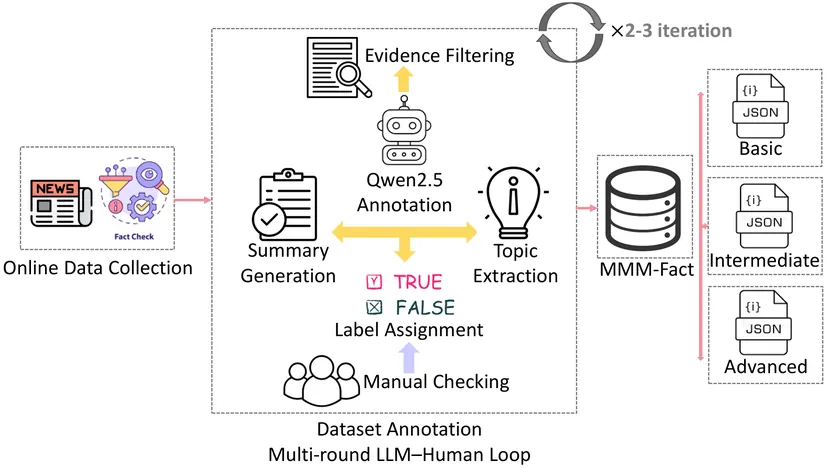
Misinformation and disinformation demand fact checking that goes beyond simple evidence-based reasoning. Existing benchmarks fall short: they are largely single modality (text-only), span short time horizons, use shallow evidence, cover domains unevenly, and often omit full articles -- obscuring models' real-world capability. We present MMM-Fact, a large-scale benchmark of 125,449 fact-checked statements (1995--2025) across multiple domains, each paired with the full fact-check article and multimodal evidence (text, images, videos, tables) from four fact-checking sites and one news outlet. To reflect verification effort, each statement is tagged with a retrieval-difficulty tier -- Basic (1--5 sources), Intermediate (6--10), and Advanced (>10) -- supporting fairness-aware evaluation for multi-step, cross-modal reasoning. The dataset adopts a three-class veracity scheme (true/false/not enough information) and enables tasks in veracity prediction, explainable fact-checking, complex evidence aggregation, and longitudinal analysis. Baselines with mainstream LLMs show MMM-Fact is markedly harder than prior resources, with performance degrading as evidence complexity rises. MMM-Fact offers a realistic, scalable benchmark for transparent, reliable, multimodal fact-checking.
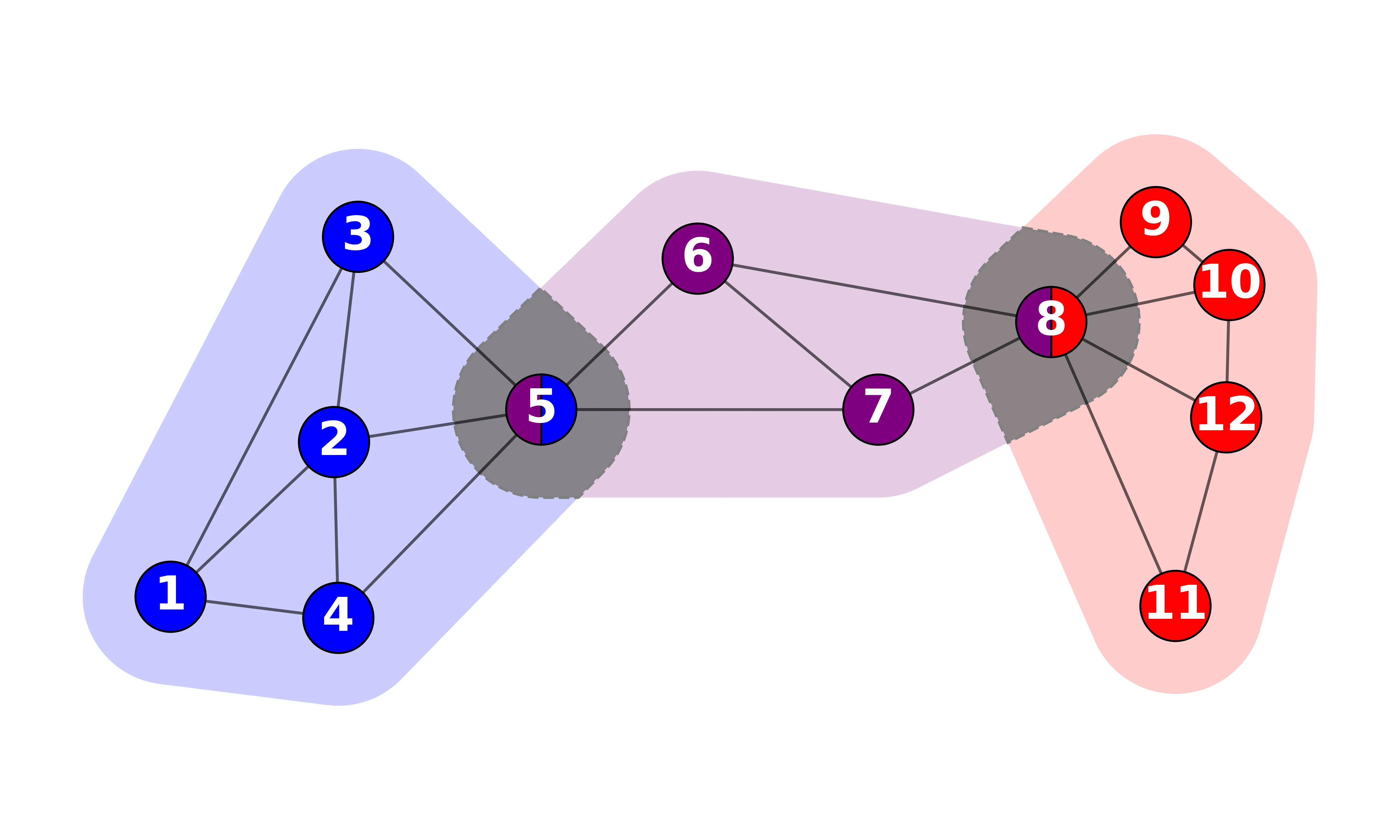
In complex networks there are overlapping substructures or "circles" that consist of nodes belonging to multiple cohesive subgroups. Yet the role of these overlapping nodes in influence spreading processes remains underexplored. In the present study, we analyse networks with circle structures using a probabilistic influence spreading model for processes of simple and complex contagion. We quantify the roles of nodes using three metrics, i.e., In-Centrality, Out-Centrality, and Betweenness Centrality that represent the susceptibility, spreading power, and mediatory role of nodes, respectively, and find that at each stage of the spreading process the overlapping nodes consistently exhibit greater influence than the non-overlapping ones. Furthermore, we observe that the criteria to define circles shape the overlapping effects. When we restrict our analysis to only largest circles, we find that circles reflect not only node-level attributes but also of topological importance. These findings clarify the distinction between local attribute-driven circles and global community structures, thus highlighting the strategic importanc of overlapping nodes in spreading dynamics. This provides foundation for future research on overlapping nodes in both circles and communities.