Trending in Economics
Procurement without Priors: A Simple Mechanism and its Notable Performance
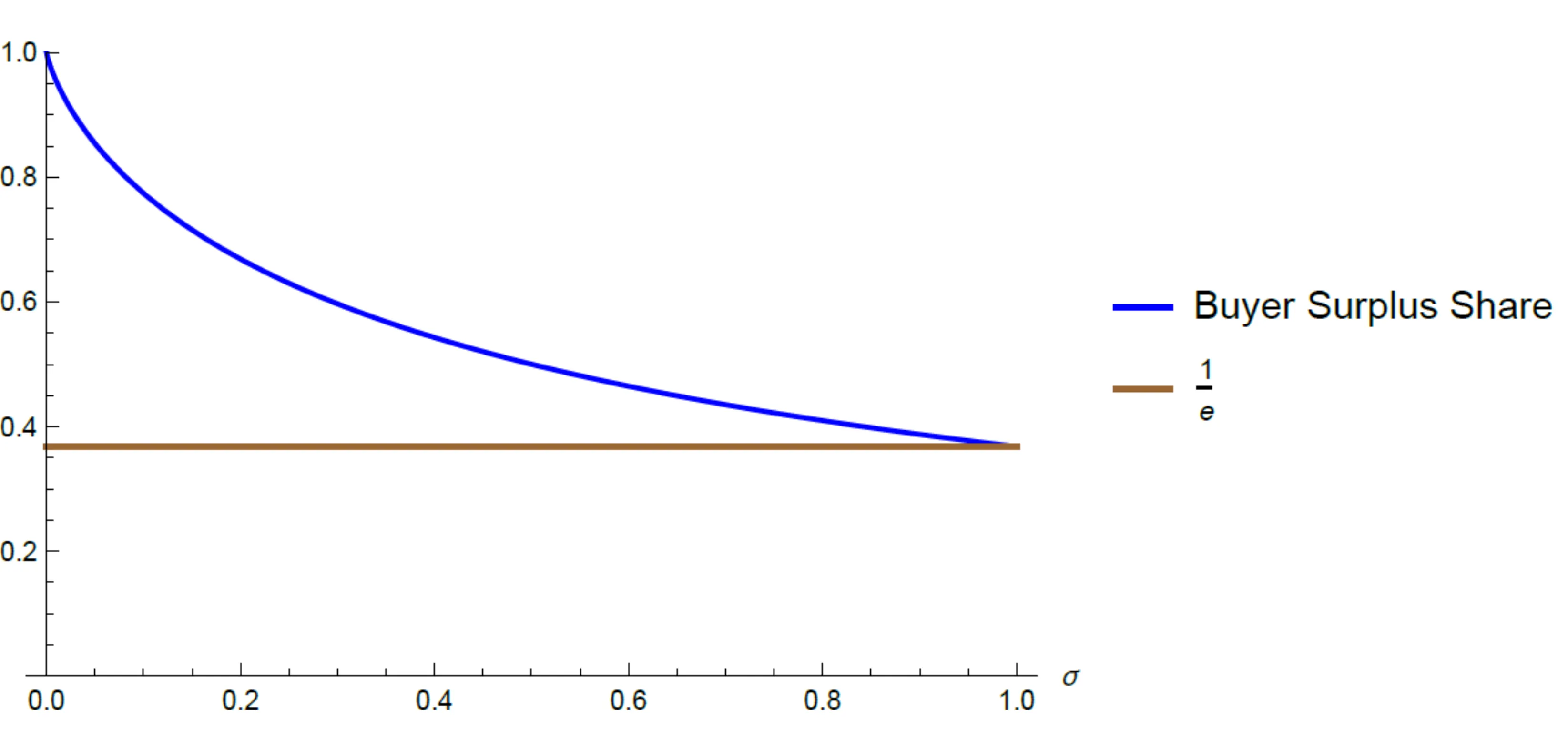
How should a buyer design procurement mechanisms when suppliers' costs are unknown, and the buyer does not have a prior belief? We demonstrate that simple mechanisms - that share a constant fraction of the buyer utility with the seller - allow the buyer to realize a guaranteed positive fraction of the efficient social surplus across all possible costs. Moreover, a judicious choice of the share based on the known demand maximizes the surplus ratio guarantee that can be attained across all possible (arbitrarily complex and nonlinear) mechanisms and cost functions. Similar results hold in related nonlinear pricing and optimal regulation problems.
2512.091291
Dec 2025Theoretical Economics
Nearest Neighbor Matching as Least Squares Density Ratio Estimation and Riesz Regression
This study proves that Nearest Neighbor (NN) matching can be interpreted as an instance of Riesz regression for automatic debiased machine learning. Lin et al. (2023) shows that NN matching is an instance of density-ratio estimation with their new density-ratio estimator. Chernozhukov et al. (2024) develops Riesz regression for automatic debiased machine learning, which directly estimates the Riesz representer (or equivalently, the bias-correction term) by minimizing the mean squared error. In this study, we first prove that the density-ratio estimation method proposed in Lin et al. (2023) is essentially equivalent to Least-Squares Importance Fitting (LSIF) proposed in Kanamori et al. (2009) for direct density-ratio estimation. Furthermore, we derive Riesz regression using the LSIF framework. Based on these results, we derive NN matching from Riesz regression. This study is based on our work Kato (2025a) and Kato (2025b).
2510.244335
Oct 2025Econometrics
Direct Debiased Machine Learning via Bregman Divergence Minimization
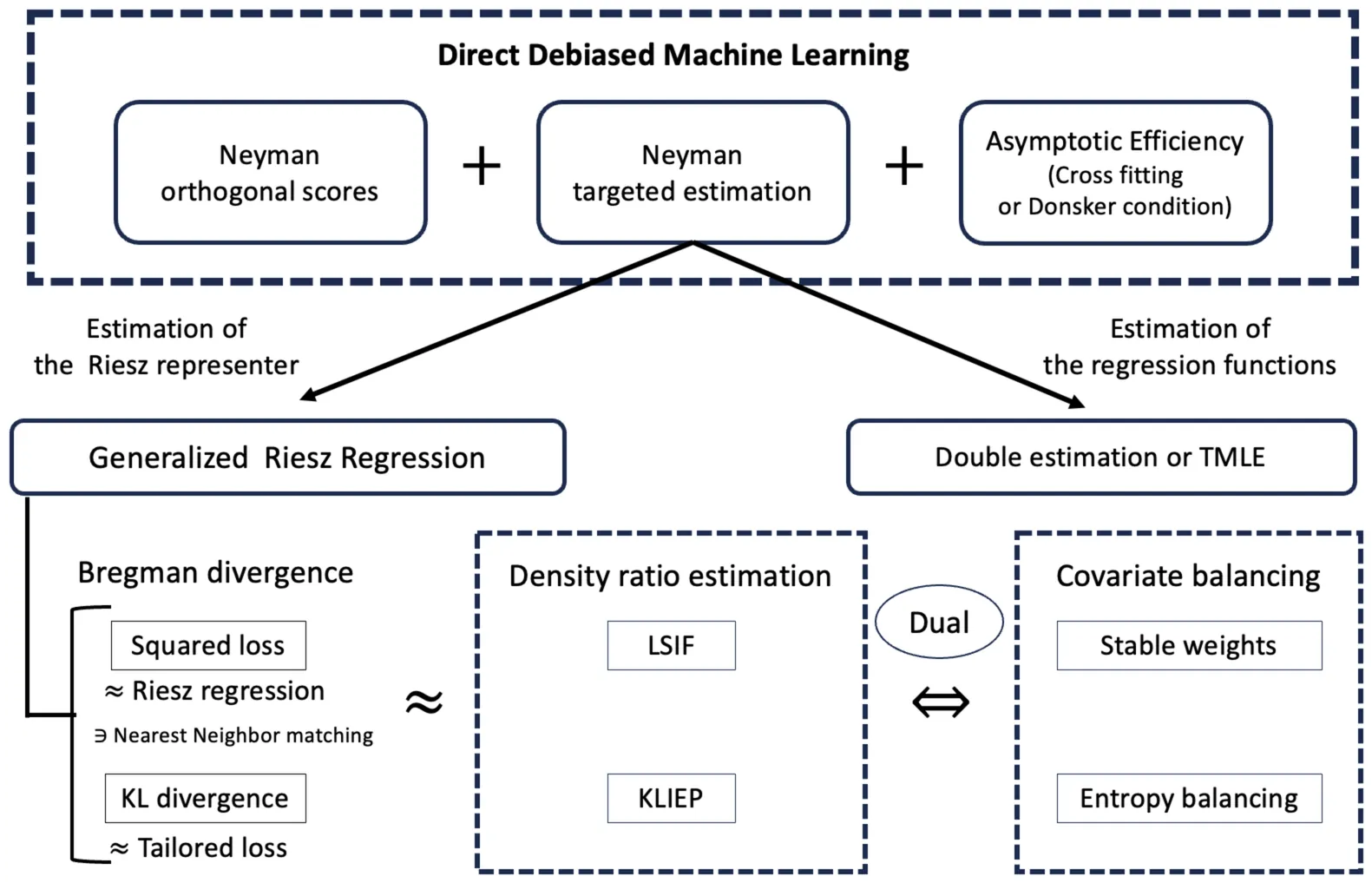
We develop a direct debiased machine learning framework comprising Neyman targeted estimation and generalized Riesz regression. Our framework unifies Riesz regression for automatic debiased machine learning, covariate balancing, targeted maximum likelihood estimation (TMLE), and density-ratio estimation. In many problems involving causal effects or structural models, the parameters of interest depend on regression functions. Plugging regression functions estimated by machine learning methods into the identifying equations can yield poor performance because of first-stage bias. To reduce such bias, debiased machine learning employs Neyman orthogonal estimating equations. Debiased machine learning typically requires estimation of the Riesz representer and the regression function. For this problem, we develop a direct debiased machine learning framework with an end-to-end algorithm. We formulate estimation of the nuisance parameters, the regression function and the Riesz representer, as minimizing the discrepancy between Neyman orthogonal scores computed with known and unknown nuisance parameters, which we refer to as Neyman targeted estimation. Neyman targeted estimation includes Riesz representer estimation, and we measure discrepancies using the Bregman divergence. The Bregman divergence encompasses various loss functions as special cases, where the squared loss yields Riesz regression and the Kullback-Leibler divergence yields entropy balancing. We refer to this Riesz representer estimation as generalized Riesz regression. Neyman targeted estimation also yields TMLE as a special case for regression function estimation. Furthermore, for specific pairs of models and Riesz representer estimation methods, we can automatically obtain the covariate balancing property without explicitly solving the covariate balancing objective.
2510.235345
Oct 2025Econometrics
Rationalizable Screening and Disclosure under Unawareness
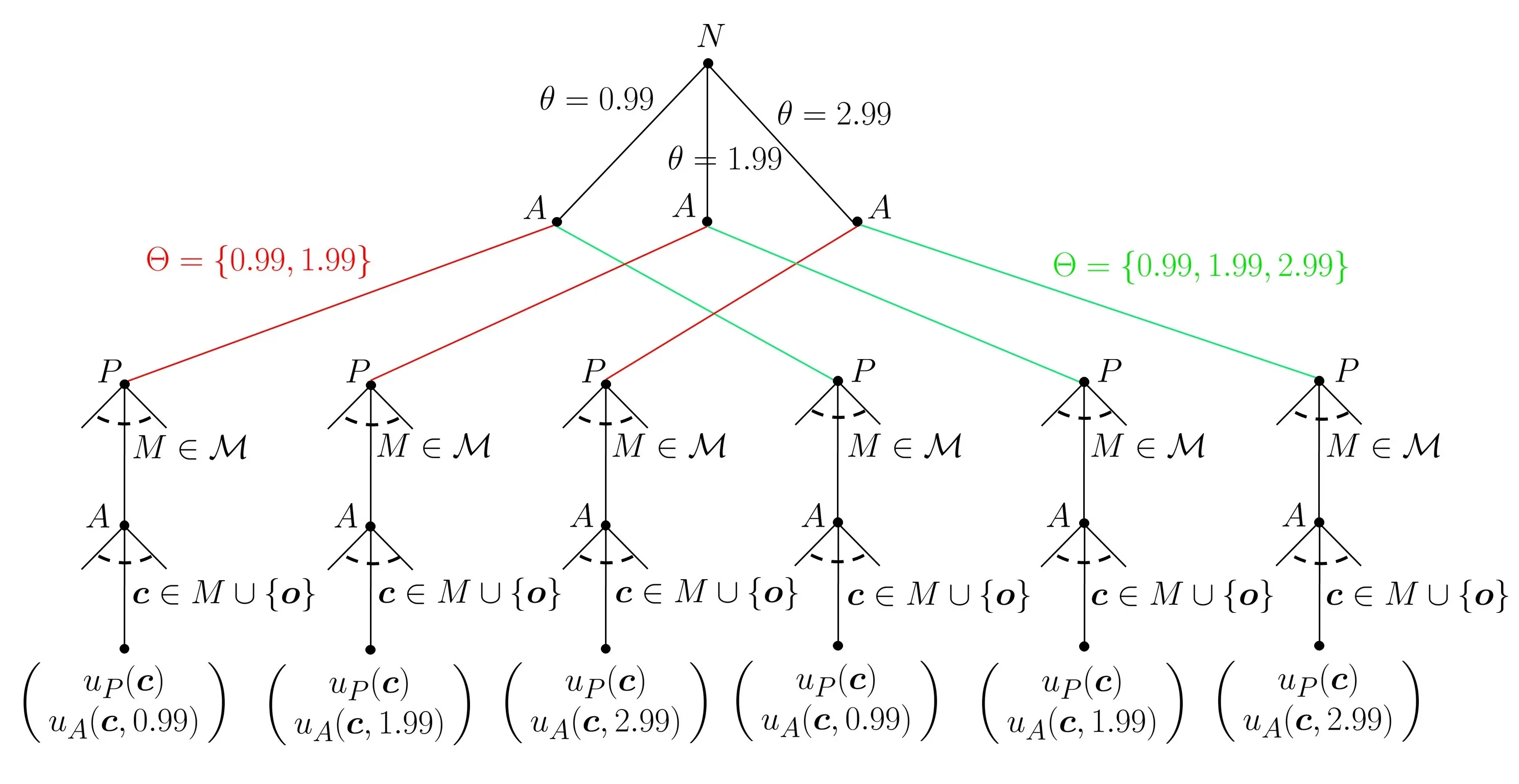
We analyze a principal-agent procurement problem in which the principal (she) is unaware some of the marginal cost types of the agent (he). Communication arises naturally as some types of the agent may have an incentive to raise the principal's awareness (totally or partially) before a contract menu is offered. The resulting menu must not only reflect the principal's change in awareness, but also her learning about types from the agent's decision to raise her awareness in the first place. We capture this reasoning in a discrete concave model via a rationalizability procedure in which marginal beliefs over types are restricted to log-concavity, ``reverse'' Bayesianism, and mild assumptions of caution. We show that if the principal is ex ante only unaware of high-cost types, all of these types have an incentive raise her awareness of them -- otherwise, they would not be served. With three types, the two lower-cost types that the principal is initially aware of also want to raise her awareness of the high-cost type: Their quantities suffer no additional distortions and they both earn an extra information rent. Intuitively, the presence of an even higher cost type makes the original two look better. With more than three types, we show that this intuition may break down for types of whom the principal is initially aware of so that raising the principal's awareness could cease to be profitable for those types. When the principal is ex ante only unaware of more efficient (low-cost) types, then \textit{no type} raises her awareness, leaving her none the wiser.
2510.2091813
Oct 2025Theoretical Economics

The Economics of AI Foundation Models: Openness, Competition, and Governance
The strategic choice of model "openness" has become a defining issue for the foundation model (FM) ecosystem. While this choice is intensely debated, its underlying economic drivers remain underexplored. We construct a two-period game-theoretic model to analyze how openness shapes competition in an AI value chain, featuring an incumbent developer, a downstream deployer, and an entrant developer. Openness exerts a dual effect: it amplifies knowledge spillovers to the entrant, but it also enhances the incumbent's advantage through a "data flywheel effect," whereby greater user engagement today further lowers the deployer's future fine-tuning cost. Our analysis reveals that the incumbent's optimal first-period openness is surprisingly non-monotonic in the strength of the data flywheel effect. When the data flywheel effect is either weak or very strong, the incumbent prefers a higher level of openness; however, for an intermediate range, it strategically restricts openness to impair the entrant's learning. This dynamic gives rise to an "openness trap," a critical policy paradox where transparency mandates can backfire by removing firms' strategic flexibility, reducing investment, and lowering welfare. We extend the model to show that other common interventions can be similarly ineffective. Vertical integration, for instance, only benefits the ecosystem when the data flywheel effect is strong enough to overcome the loss of a potentially more efficient competitor. Likewise, government subsidies intended to spur adoption can be captured entirely by the incumbent through strategic price and openness adjustments, leaving the rest of the value chain worse off. By modeling the developer's strategic response to competitive and regulatory pressures, we provide a robust framework for analyzing competition and designing effective policy in the complex and rapidly evolving FM ecosystem.
2510.152004
Oct 2025Theoretical Economics
Bayesian Portfolio Optimization by Predictive Synthesis
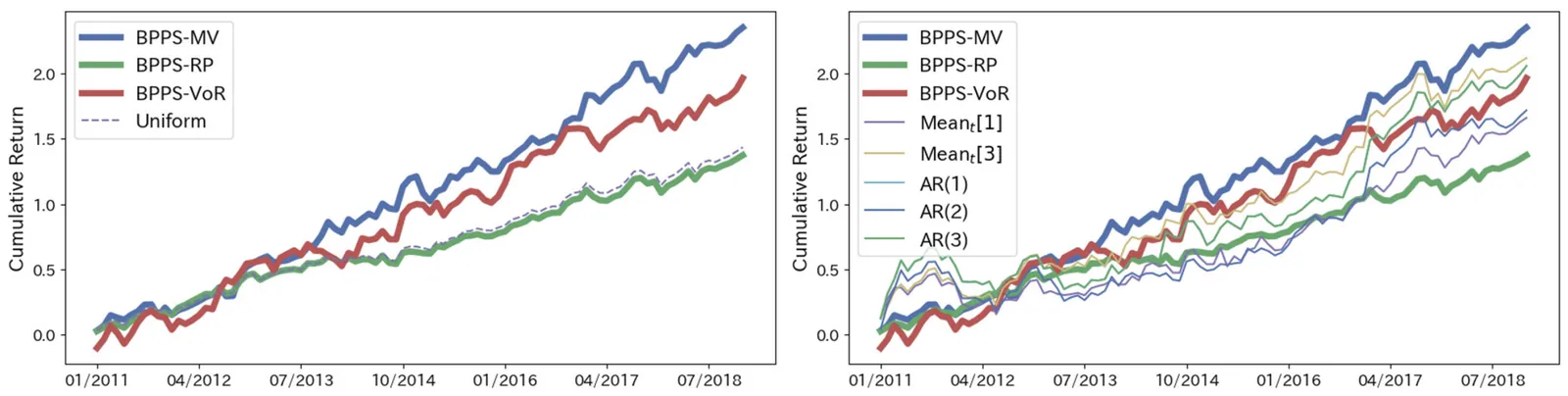
Portfolio optimization is a critical task in investment. Most existing portfolio optimization methods require information on the distribution of returns of the assets that make up the portfolio. However, such distribution information is usually unknown to investors. Various methods have been proposed to estimate distribution information, but their accuracy greatly depends on the uncertainty of the financial markets. Due to this uncertainty, a model that could well predict the distribution information at one point in time may perform less accurately compared to another model at a different time. To solve this problem, we investigate a method for portfolio optimization based on Bayesian predictive synthesis (BPS), one of the Bayesian ensemble methods for meta-learning. We assume that investors have access to multiple asset return prediction models. By using BPS with dynamic linear models to combine these predictions, we can obtain a Bayesian predictive posterior about the mean rewards of assets that accommodate the uncertainty of the financial markets. In this study, we examine how to construct mean-variance portfolios and quantile-based portfolios based on the predicted distribution information.
2510.071801
Oct 2025Econometrics
The AI Productivity Index (APEX)
We present an extended version of the AI Productivity Index (APEX-v1-extended), a benchmark for assessing whether frontier models are capable of performing economically valuable tasks in four jobs: investment banking associate, management consultant, big law associate, and primary care physician (MD). This technical report details the extensions to APEX-v1, including an increase in the held-out evaluation set from n = 50 to n = 100 cases per job (n = 400 total) and updates to the grading methodology. We present a new leaderboard, where GPT5 (Thinking = High) remains the top performing model with a score of 67.0%. APEX-v1-extended shows that frontier models still have substantial limitations when performing typical professional tasks. To support further research, we are open sourcing n = 25 non-benchmark example cases per role (n = 100 total) along with our evaluation harness.
2509.257214
Sep 2025General Economics

Bootstrap Diagnostic Tests
Violation of the assumptions underlying classical (Gaussian) limit theory often yields unreliable statistical inference. This paper shows that the bootstrap can detect such violations by delivering simple and powerful diagnostic tests that (a) induce no pre-testing bias, (b) use the same critical values across applications, and (c) are consistent against deviations from asymptotic normality. The tests compare the conditional distribution of a bootstrap statistic with the Gaussian limit implied by valid specification and assess whether the resulting discrepancy is large enough to indicate failure of the asymptotic Gaussian approximation. The method is computationally straightforward and only requires a sample of i.i.d. draws of the bootstrap statistic. We derive sufficient conditions for the randomness in the data to mix with the randomness in the bootstrap repetitions in a way such that (a), (b) and (c) above hold. We demonstrate the practical relevance and broad applicability of bootstrap diagnostics by considering several scenarios where the asymptotic Gaussian approximation may fail, including weak instruments, non-stationarity, parameters on the boundary of the parameter space, infinite variance data and singular Jacobian in applications of the delta method. An illustration drawn from the empirical macroeconomic literature concludes.
2509.013512
Sep 2025Econometrics
Optimal Transfer Mechanism for Municipal Soft-Budget Constraints in Newfoundland
Newfoundland and Labrador's municipalities face severe soft budget pressures due to narrow tax bases, high fixed service costs, and volatile resource revenues. We develop a Stackelberg style mechanism design model in which the province commits at t = 0 to an ex ante grant schedule and an ex post bailout rule. Municipalities privately observe their fiscal need type, choose effort, investment, and debt, and may receive bailouts when deficits exceed a statutory threshold. Under convexity and single crossing, the problem reduces to one dimensional screening and admits a tractable transfer mechanism with quadratic bailout costs and a statutory cap. The optimal ex ante rule is threshold-cap; under discretionary rescue at t = 2, it becomes threshold-linear-cap. A knife-edge inequality yields a self-consistent no bailout regime, and an explicit discount factor threshold renders hard budgets dynamically credible. We emphasize a class of monotone threshold signal rules; under this class, grant crowd out is null almost everywhere, which justifies the constant grant weight used in closed form expressions. The closed form characterization provides a policy template that maps to Newfoundland's institutions and clarifies the micro-data required for future calibration.
2508.021711
Aug 2025Theoretical Economics
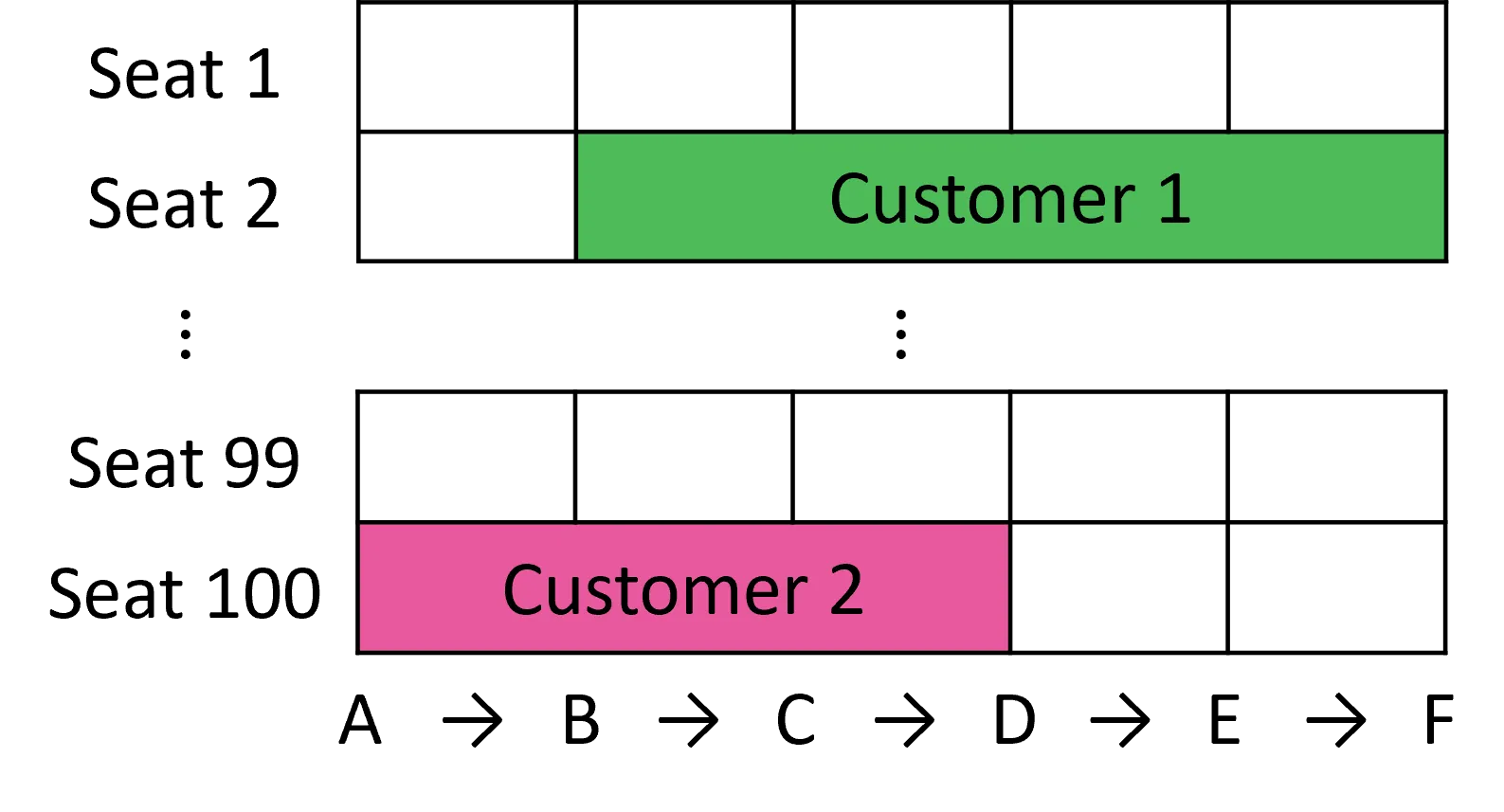
Constant-Factor Algorithms for Revenue Management with Consecutive Stays
We study network revenue management problems motivated by applications such as railway ticket sales and hotel room bookings. Requests, each requiring a resource for a consecutive stay, arrive sequentially with known arrival probabilities. We investigate two scenarios: the accept-or-reject scenario, where a request can be fulfilled by assigning any available resource; and the BAM-based scenario, which generalizes the former by incorporating customer preferences through the basic attraction model (BAM), allowing the platform to offer an assortment of available resources from which the customer may choose. We develop polynomial-time policies and evaluate their performance using approximation ratios, defined as the ratio between the expected revenue of our policy and that of the optimal online algorithm. When each arrival has a fixed request type (e.g., the interval of the stay is fixed), we establish constant-factor guarantees: a ratio of 1 - 1/e for the accept-or-reject scenario and 0.25 for the BAM-based scenario. We further extend these results to the case where the request type is random (e.g., the interval of the stay is random). In this setting, the approximation ratios incur an additional multiplicative factor of 1 - 1/e, resulting in guarantees of at least 0.399 for the accept-or-reject scenario and 0.156 for the BAM-based scenario. These constant-factor guarantees stand in sharp contrast to the prior nonconstant competitive ratios that are benchmarked against the offline optimum.
2506.009091
Jun 2025Theoretical Economics

Berk-Nash Rationalizability
We study learning in complete-information games, allowing the players' models of their environment to be misspecified. We introduce Berk--Nash rationalizability: the largest self-justified set of actions -- meaning each action in the set is optimal under some belief that is a best fit to outcomes generated by joint play within the set. We show that, in a model where players learn from past actions, every action played (or approached) infinitely often lies in this set. When players have a correct model of their environment, Berk--Nash rationalizability refines (correlated) rationalizability and coincides with it in two-player games. The concept delivers predictions on long-run behavior regardless of whether actions converge or not, thereby providing a practical alternative to proving convergence or solving complex stochastic learning dynamics. For example, if the rationalizable set is a singleton, actions converge almost surely.
2505.207081
May 2025Theoretical Economics
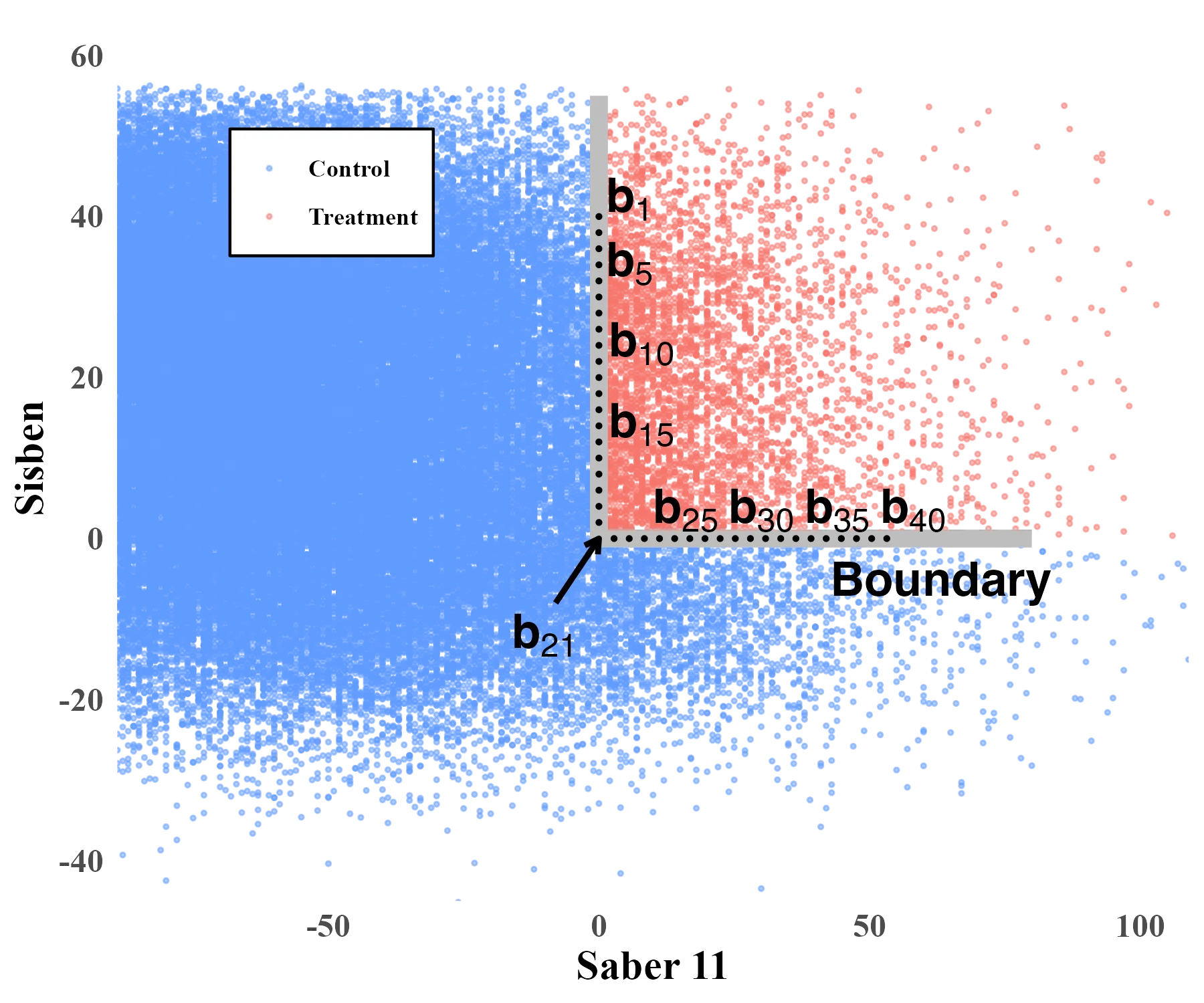
Estimation and Inference in Boundary Discontinuity Designs: Location-Based Methods
Boundary discontinuity designs are used to learn about causal treatment effects along a continuous assignment boundary that splits units into control and treatment groups according to a bivariate location score. We analyze the statistical properties of local polynomial treatment effect estimators employing location information for each unit. We develop pointwise and uniform estimation and inference methods for both the conditional treatment effect function at the assignment boundary as well as for transformations thereof, which aggregate information along the boundary. We illustrate our methods with an empirical application. Companion general-purpose software is provided.
2505.056706
May 2025Econometrics

Pricing AI Model Accuracy
This paper examines the market for AI models in which firms compete to provide accurate model predictions and consumers exhibit heterogeneous preferences for model accuracy. We develop a consumer-firm duopoly model to analyze how competition affects firms' incentives to improve model accuracy. Each firm aims to minimize its model's error, but this choice can often be suboptimal. Counterintuitively, we find that in a competitive market, firms that improve overall accuracy do not necessarily improve their profits. Rather, each firm's optimal decision is to invest further on the error dimension where it has a competitive advantage. By decomposing model errors into false positive and false negative rates, firms can reduce errors in each dimension through investments. Firms are strictly better off investing on their superior dimension and strictly worse off with investments on their inferior dimension. Profitable investments adversely affect consumers but increase overall welfare.
2504.133751
Apr 2025Theoretical Economics
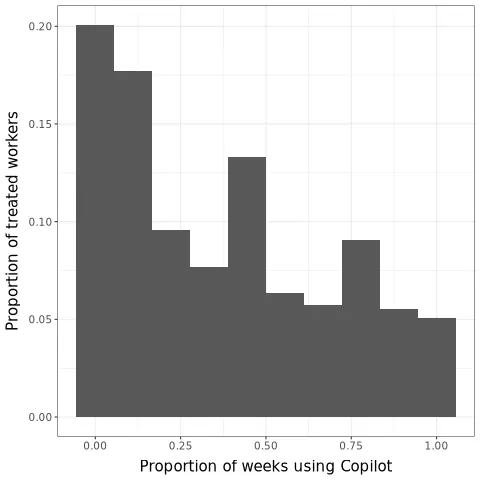
Shifting Work Patterns with Generative AI
We present evidence from a field experiment across 66 firms and 7,137 knowledge workers. Workers were randomly selected to access a generative AI tool integrated into applications they already used at work for email, meetings, and writing. In the second half of the 6-month experiment, the 80% of treated workers who used this tool spent two fewer hours on email each week and reduced their time working outside of regular hours. Apart from these individual time savings, we do not detect shifts in the quantity or composition of workers' tasks resulting from individual-level AI provision.
2504.114363
Apr 2025General Economics
Demand Estimation with Text and Image Data
We propose a demand estimation method that leverages unstructured text and image data to infer substitution patterns. Using pre-trained deep learning models, we extract embeddings from product images and textual descriptions and incorporate them into a random coefficients logit model. This approach enables researchers to estimate demand even when they lack data on product attributes or when consumers value hard-to-quantify attributes, such as visual design or functional benefits. Using data from a choice experiment, we show that our approach outperforms standard attribute-based models in counterfactual predictions of consumers' second choices. We also apply it across 40 product categories on Amazon and consistently find that text and image data help identify close substitutes within each category.
2503.207116
Mar 2025General Economics
Ranking Statistical Experiments via the Linear Convex Order and the Lorenz Zonoid: Economic Applications
This paper introduces a novel ranking of statistical experiments, the Linear-Blackwell (LB) order, equivalently characterized by (i) more dispersed posteriors and likelihood ratios in the sense of the linear convex order, (ii) a larger Lorenz zonoid--the set of statewise profiles spanned by signals, and (iii) greater variability of the posterior mean. We apply the LB order to compare experiments in binary-action decision problems and in problems with quasiconcave payoffs, as analyzed by Kolotilin, Corrao, and Wolitzky (2025). Furthermore, the LB order enables the comparison of experiments in moral hazard problems, complementing the findings in Holmström (1979) and Kim (1995). Finally, the LB order applies to the comparison of experiments generating ex post signals in screening problems.
2502.065301
Feb 2025Theoretical Economics
Streaming problems as (multi-issue) claims problems
We study the problem of allocating the revenues raised via paid subscriptions to music streaming platforms among participating artists. We show that the main methods to solve streaming problems (pro-rata, user-centric and families generalizing them) can be seen as specific (well-known) rules to solve (multi-issue) claims problems. Our results permit to provide strong links between the well-established literature on claims problems and the emerging literature on streaming problems.
2412.186285
Dec 2024Theoretical Economics
Multiplexing in Networks and Diffusion
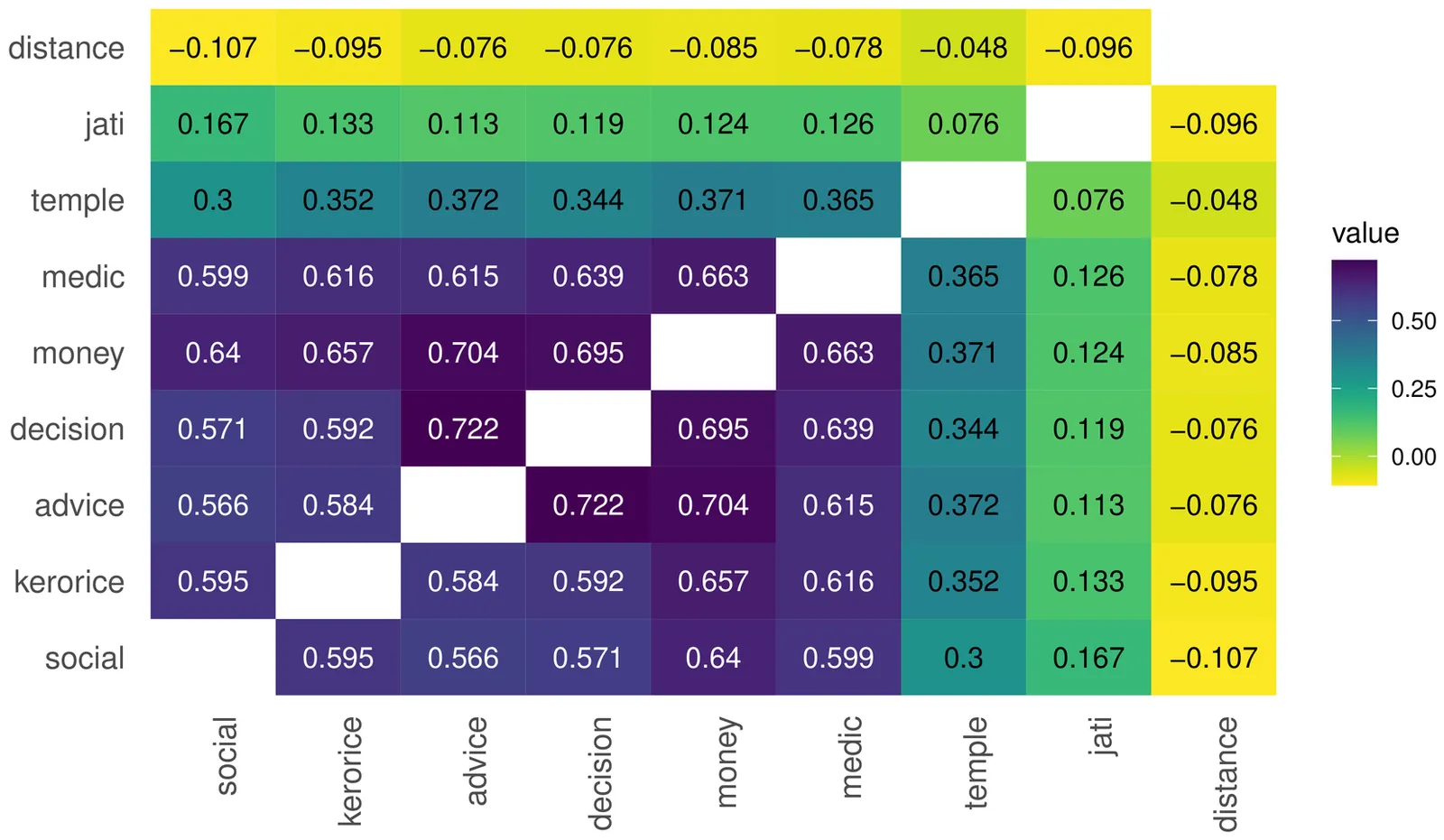
Social and economic networks are often multiplexed, meaning that people are connected by different types of relationships -- such as borrowing goods and giving advice. We make two contributions to the study of multiplexing and the understanding of simple versus complex contagion. On the theoretical side, we introduce a model and theoretical results about diffusion in multiplex networks. We show that multiplexing impedes the spread of simple contagions, such as diseases or basic information that only require one interaction to transmit an infection. We show, however that multiplexing enhances the spread of a complex contagion when infection rates are low, but then impedes complex contagion if infection rates become high. On the empirical side, we document empirical multiplexing patterns in Indian village data. We show that relationships such as socializing, advising, helping, and lending are correlated but distinct, while commonly used proxies for networks based on ethnicity and geography are nearly uncorrelated with actual relationships. We also show that these layers and their overlap affect information diffusion in a field experiment. The advice network is the best predictor of diffusion, but combining layers improves predictions further. Villages with greater overlap between layers -- more multiplexing -- experience less overall diffusion. Finally, we identify differences in multiplexing by gender and connectedness. These have implications for inequality in diffusion-mediated outcomes such as access to information and adherence to norms.
2412.119571
Dec 2024General Economics
Large Language Models: An Applied Econometric Framework
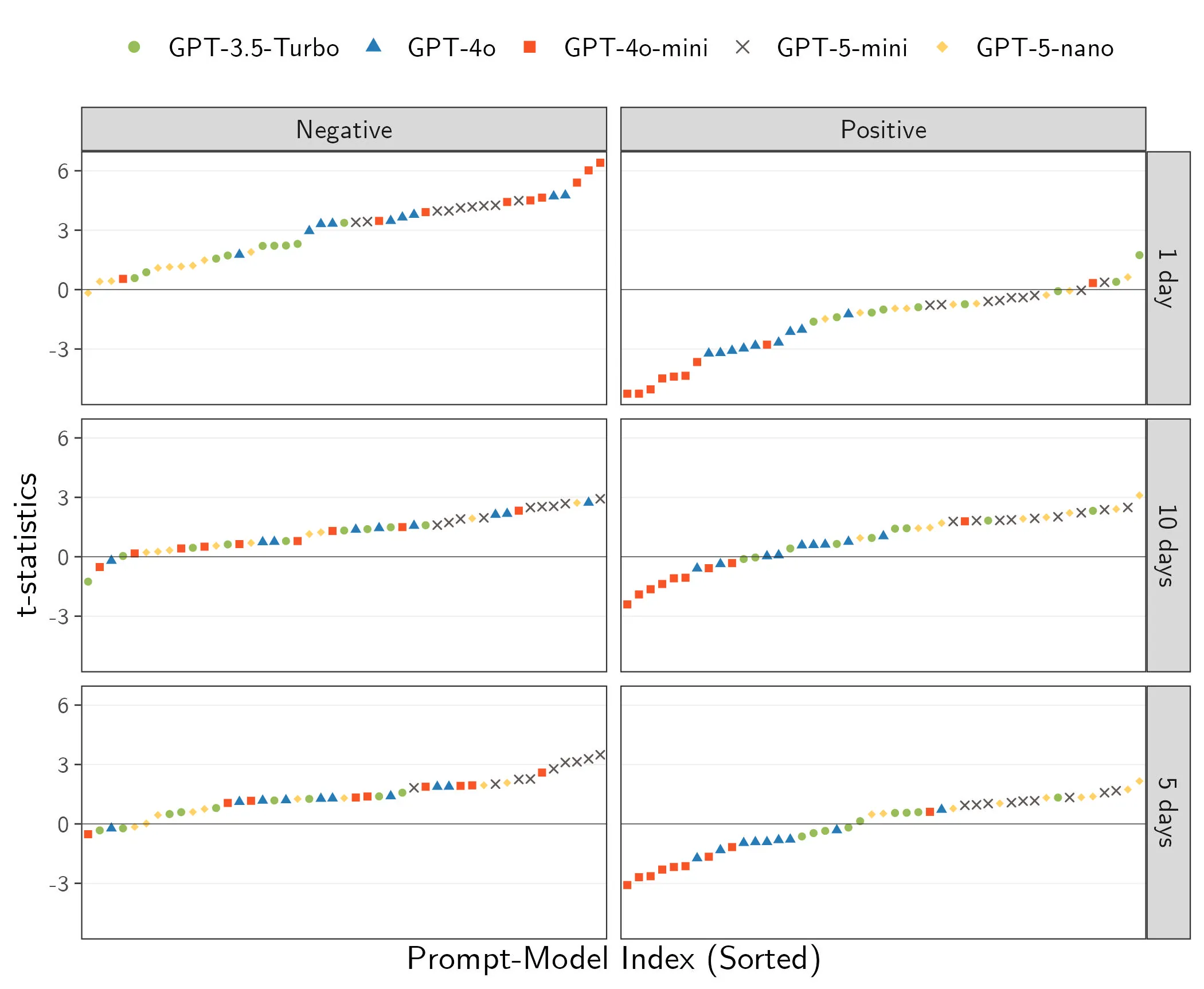
Large language models (LLMs) enable researchers to analyze text at unprecedented scale and minimal cost. Researchers can now revisit old questions and tackle novel ones with rich data. We provide an econometric framework for realizing this potential in two empirical uses. For prediction problems -- forecasting outcomes from text -- valid conclusions require ``no training leakage'' between the LLM's training data and the researcher's sample, which can be enforced through careful model choice and research design. For estimation problems -- automating the measurement of economic concepts for downstream analysis -- valid downstream inference requires combining LLM outputs with a small validation sample to deliver consistent and precise estimates. Absent a validation sample, researchers cannot assess possible errors in LLM outputs, and consequently seemingly innocuous choices (which model, which prompt) can produce dramatically different parameter estimates. When used appropriately, LLMs are powerful tools that can expand the frontier of empirical economics.
2412.0703129
Dec 2024Econometrics
Public sentiments on the fourth industrial revolution: An unsolicited public opinion poll from Twitter
This paper establishes an empirical baseline of public sentiment toward Fourth Industrial Revolution (4IR) technologies across six European countries during the period 2006--2019, prior to the widespread adoption of generative AI systems. Employing transformer-based natural language processing models on a corpus of approximately 90,000 tweets and news articles, I document a European public sphere increasingly divided in its assessment of technological change: neutral sentiment declined markedly over the study period as citizens sorted into camps of enthusiasm and concern, a pattern that manifests distinctively across national contexts and technology domains. Approximately 6\% of users inhabit echo chambers characterized by sentiment-aligned networks, with privacy discourse exhibiting the highest susceptibility to such dynamics. These findings provide a methodologically rigorous reference point for evaluating how the introduction of ChatGPT and subsequent generative AI systems has transformed public discourse on automation, employment, and technological change. The results carry implications for policymakers seeking to align technological governance with societal values in an era of rapid AI advancement.
2411.142301
Nov 2024General Economics