Portfolio Management
arXiv:q-fin.PM
Security selection and capital allocation, benchmark selection, portfolio strategies.
Security selection and capital allocation, benchmark selection, portfolio strategies.
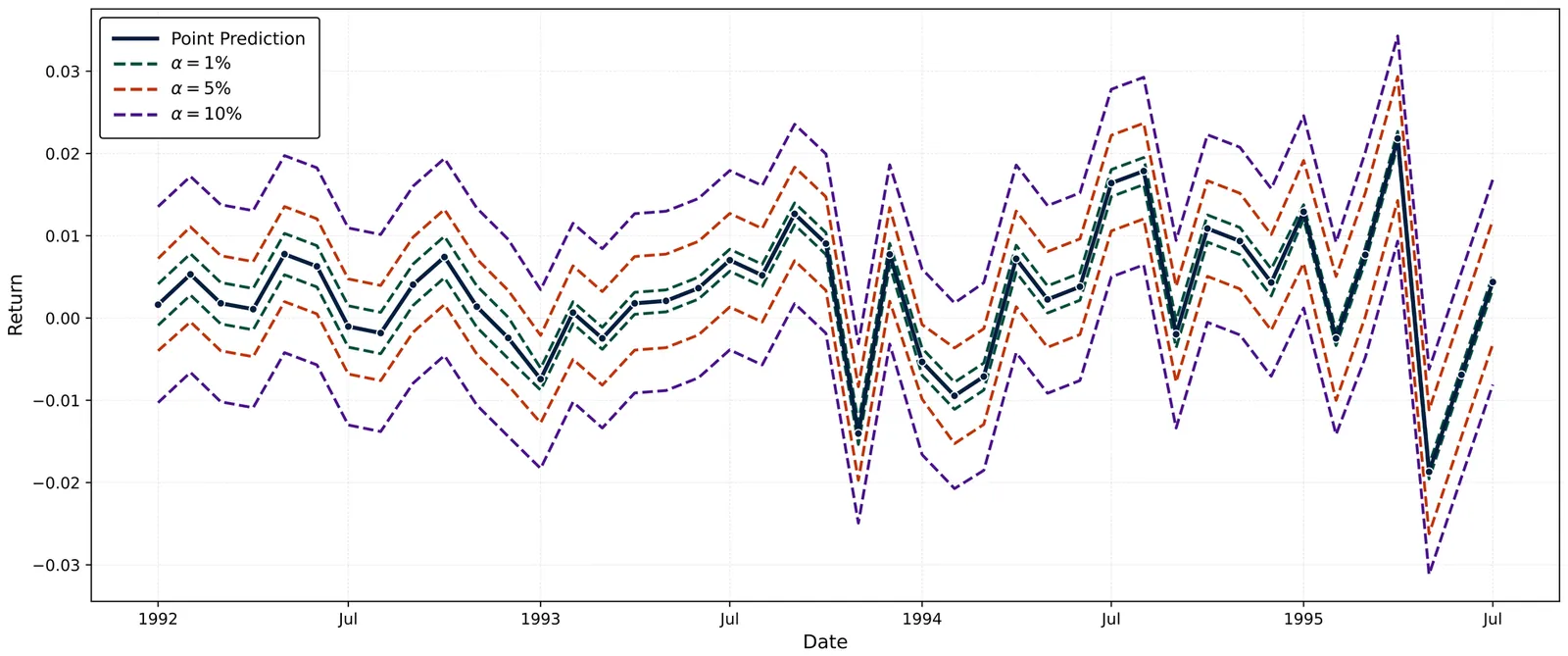
Machine learning is central to empirical asset pricing, but portfolio construction still relies on point predictions and largely ignores asset-specific estimation uncertainty. We propose a simple change: sort assets using uncertainty-adjusted prediction bounds instead of point predictions alone. Across a broad set of ML models and a U.S. equity panel, this approach improves portfolio performance relative to point-prediction sorting. These gains persist even when bounds are built from partial or misspecified uncertainty information. They arise mainly from reduced volatility and are strongest for flexible machine learning models. Identification and robustness exercises show that these improvements are driven by asset-level rather than time or aggregate predictive uncertainty.
Machine learning is central to empirical asset pricing, but portfolio construction still relies on point predictions and largely ignores asset-specific estimation uncertainty. We propose a simple change: sort assets using uncertainty-adjusted prediction bounds instead of point predictions alone. Across a broad set of ML models and a U.S. equity panel, this approach improves portfolio performance relative to point-prediction sorting. These gains persist even when bounds are built from partial or misspecified uncertainty information. They arise mainly from reduced volatility and are strongest for flexible machine learning models. Identification and robustness exercises show that these improvements are driven by asset-level rather than time or aggregate predictive uncertainty.
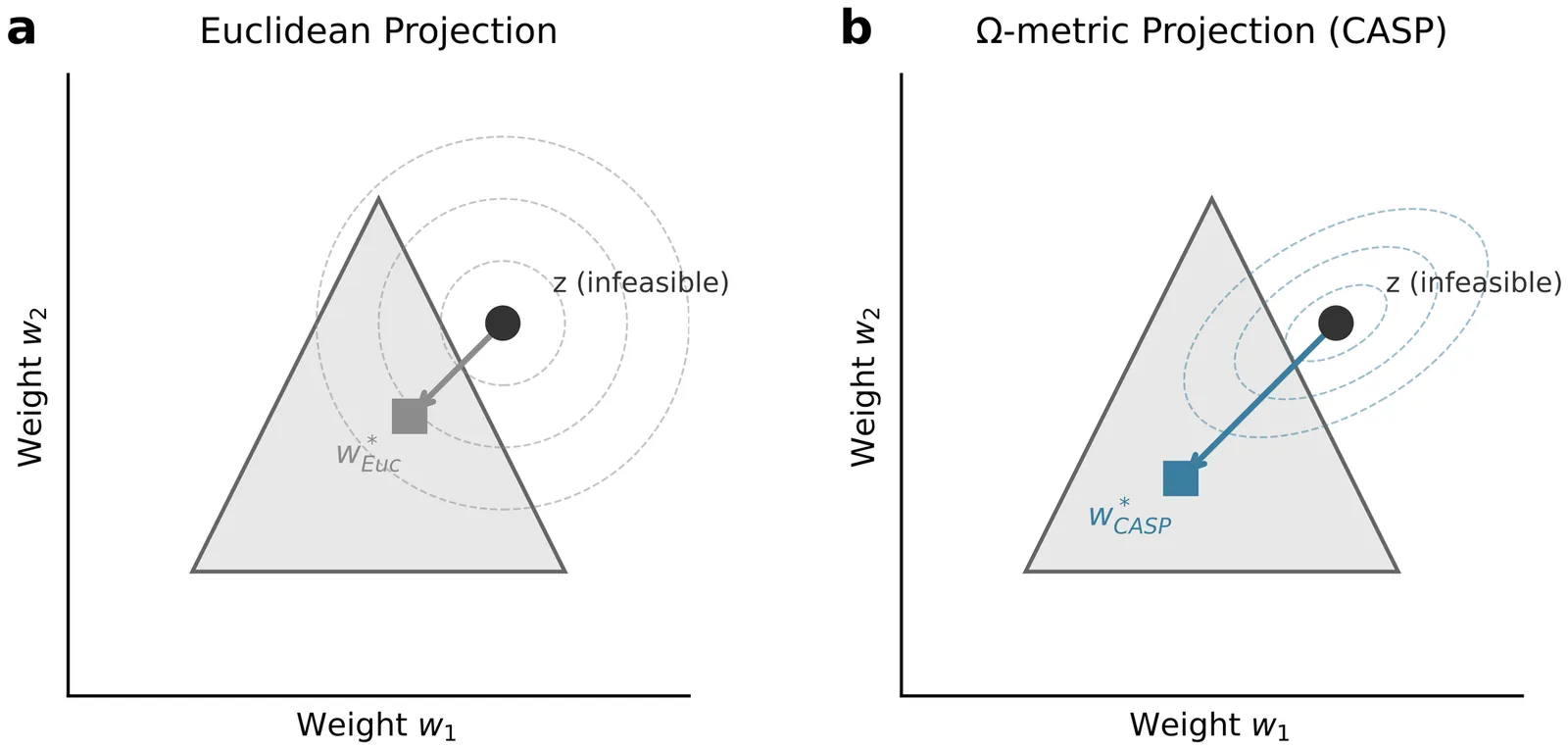
Metaheuristic algorithms for cardinality-constrained portfolio optimization require repair operators to map infeasible candidates onto the feasible region. Standard Euclidean projection treats assets as independent and can ignore the covariance structure that governs portfolio risk, potentially producing less diversified portfolios. This paper introduces Covariance-Aware Simplex Projection (CASP), a two-stage repair operator that (i) selects a target number of assets using volatility-normalized scores and (ii) projects the candidate weights using a covariance-aware geometry aligned with tracking-error risk. This provides a portfolio-theoretic foundation for using a covariance-induced distance in repair operators. On S&P 500 data (2020-2024), CASP-Basic delivers materially lower portfolio variance than standard Euclidean repair without relying on return estimates, with improvements that are robust across assets and statistically significant. Ablation results indicate that volatility-normalized selection drives most of the variance reduction, while the covariance-aware projection provides an additional, consistent improvement. We further show that optional return-aware extensions can improve Sharpe ratios, and out-of-sample tests confirm that gains transfer to realized performance. CASP integrates as a drop-in replacement for Euclidean projection in metaheuristic portfolio optimizers.
Exit timing after an IPO is one of the most consequential decisions for venture capital (VC) investors, yet existing research focuses mainly on describing when VCs exit rather than evaluating whether those choices are economically optimal. Meanwhile, large language models (LLMs) have shown promise in synthesizing complex financial data and textual information but have not been applied to post-IPO exit decisions. This study introduces a framework that uses LLMs to estimate the optimal time for VC exit by analyzing monthly post IPO information financial performance, filings, news, and market signals and recommending whether to sell or continue holding. We compare these LLM generated recommendations with the actual exit dates observed for VCs and compute the return differences between the two strategies. By quantifying gains or losses associated with following the LLM, this study provides evidence on whether AI-driven guidance can improve exit timing and complements traditional hazard and real-options models in venture capital research.
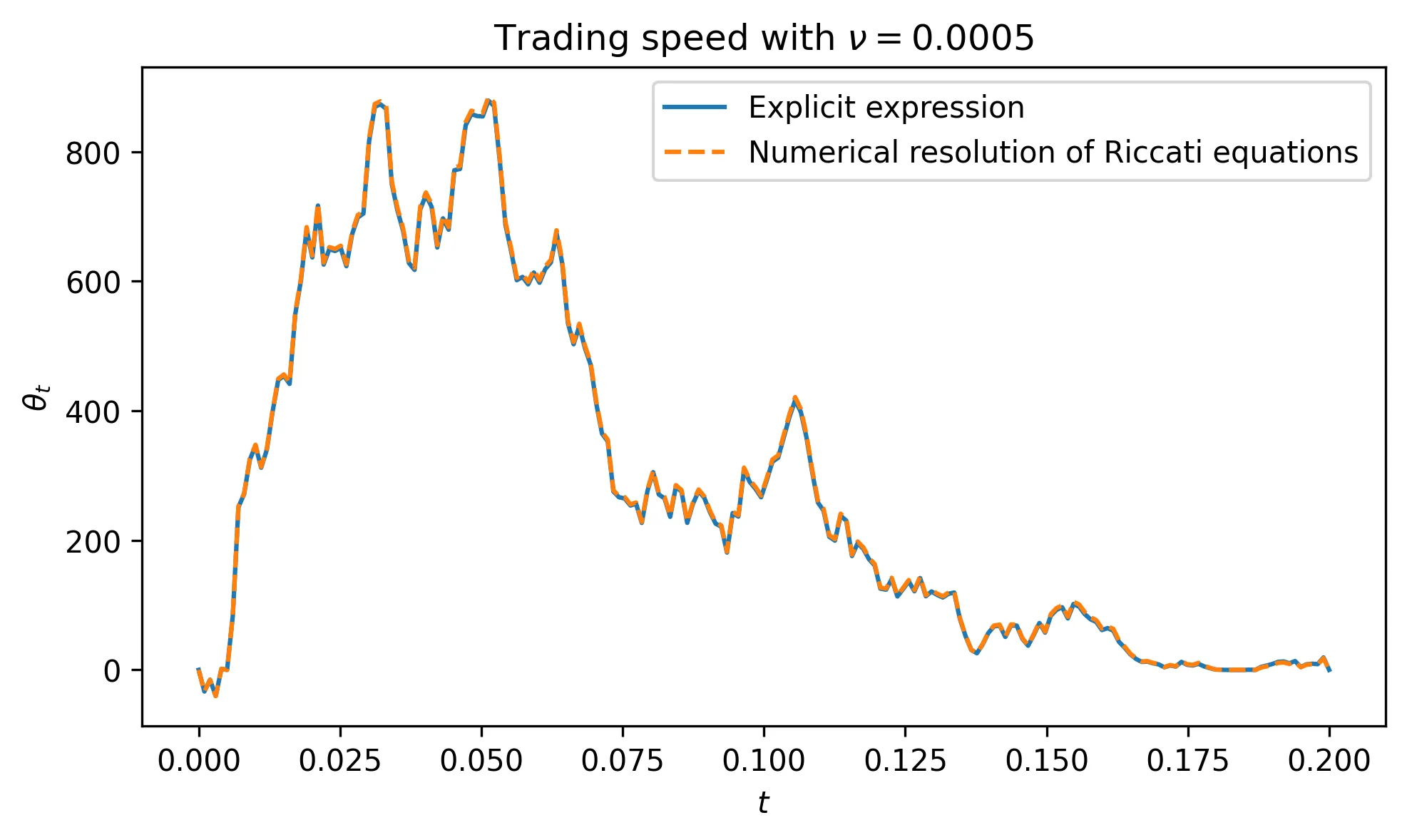
We introduce a novel signature approach for pricing and hedging path-dependent options with instantaneous and permanent market impact under a mean-quadratic variation criterion. Leveraging the expressive power of signatures, we recast an inherently nonlinear and non-Markovian stochastic control problem into a tractable form, yielding hedging strategies in (possibly infinite) linear feedback form in the time-augmented signature of the control variables, with coefficients characterized by non-standard infinite-dimensional Riccati equations on the extended tensor algebra. Numerical experiments demonstrate the effectiveness of these signature-based strategies for pricing and hedging general path-dependent payoffs in the presence of frictions. In particular, market impact naturally smooths optimal trading strategies, making low-truncated signature approximations highly accurate and robust in frictional markets, contrary to the frictionless case.
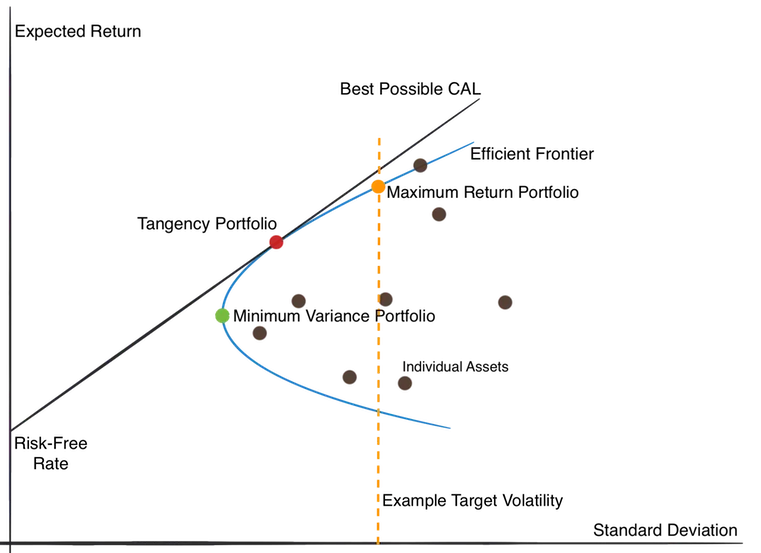
This research proposes an enhancement to the innovative portfolio optimization approach using the G-Learning algorithm, combined with parametric optimization via the GIRL algorithm (G-learning approach to the setting of Inverse Reinforcement Learning) as presented by. The goal is to maximize portfolio value by a target date while minimizing the investor's periodic contributions. Our model operates in a highly volatile market with a well-diversified portfolio, ensuring a low-risk level for the investor, and leverages reinforcement learning to dynamically adjust portfolio positions over time. Results show that we improved the Sharpe Ratio from 0.42, as suggested by recent studies using the same approach, to a value of 0.483 a notable achievement in highly volatile markets with diversified portfolios. The comparison between G-Learning and GIRL reveals that while GIRL optimizes the reward function parameters (e.g., lambda = 0.0012 compared to 0.002), its impact on portfolio performance remains marginal. This suggests that reinforcement learning methods, like G-Learning, already enable robust optimization. This research contributes to the growing development of reinforcement learning applications in financial decision-making, demonstrating that probabilistic learning algorithms can effectively align portfolio management strategies with investor needs.
We consider a discrete-time model of a financial market where a risky asset is bought and sold with transactions having a transient price impact. It is shown that the corresponding utility maximization problem admits a solution. We manage to remove some unnatural restrictions on the market depth and resilience processes that were present in earlier work. A non-standard feature of the problem is that the set of attainable portfolio values may fail the convexity property.
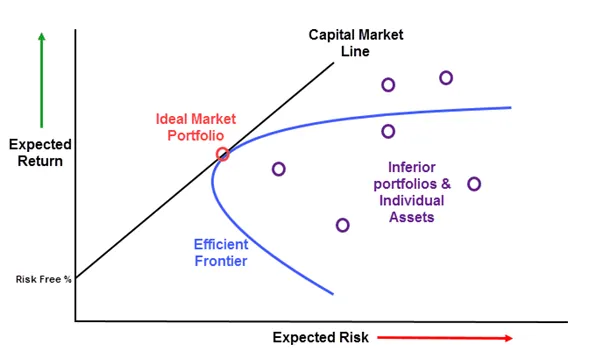
This paper presents a deep reinforcement learning (DRL) framework for dynamic portfolio optimization under market uncertainty and risk. The proposed model integrates a Sharpe ratio-based reward function with direct risk control mechanisms, including maximum drawdown and volatility constraints. Proximal Policy Optimization (PPO) is employed to learn adaptive asset allocation strategies over historical financial time series. Model performance is benchmarked against mean-variance and equal-weight portfolio strategies using backtesting on high-performing equities. Results indicate that the DRL agent stabilizes volatility successfully but suffers from degraded risk-adjusted returns due to over-conservative policy convergence, highlighting the challenge of balancing exploration, return maximization, and risk mitigation. The study underscores the need for improved reward shaping and hybrid risk-aware strategies to enhance the practical deployment of DRL-based portfolio allocation models.
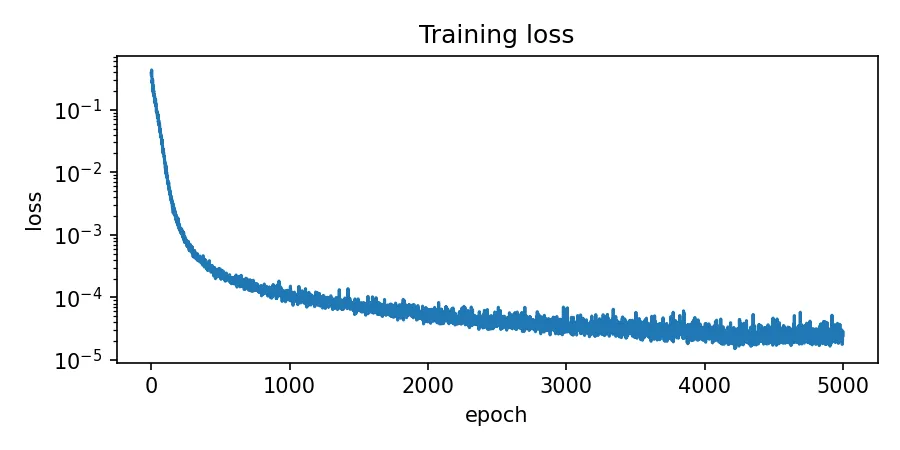
This paper investigates a time-inconsistent portfolio selection problem in the incomplete mar ket model, integrating expected utility maximization with risk control. The objective functional balances the expected utility and variance on log returns, giving rise to time inconsistency and motivating the search of a time-consistent equilibrium strategy. We characterize the equilibrium via a coupled quadratic backward stochastic differential equation (BSDE) system and establish the existence theory in two special cases: (i)the two Brownian motions driven the price dynamics and the factor process are independent with $ρ= 0$; (ii) the trading strategy is constrained to be bounded. For the general case with correlation coefficient $ρ\neq 0$, we introduce the notion of an approximate time-consistent equilibrium. Employing the solution structure from the equilibrium in the case $ρ= 0$, we can construct an approximate time-consistent equilibrium in the general case with an error of order $O(ρ^2)$. Numerical examples and financial insights are also presented based on deep learning algorithms.
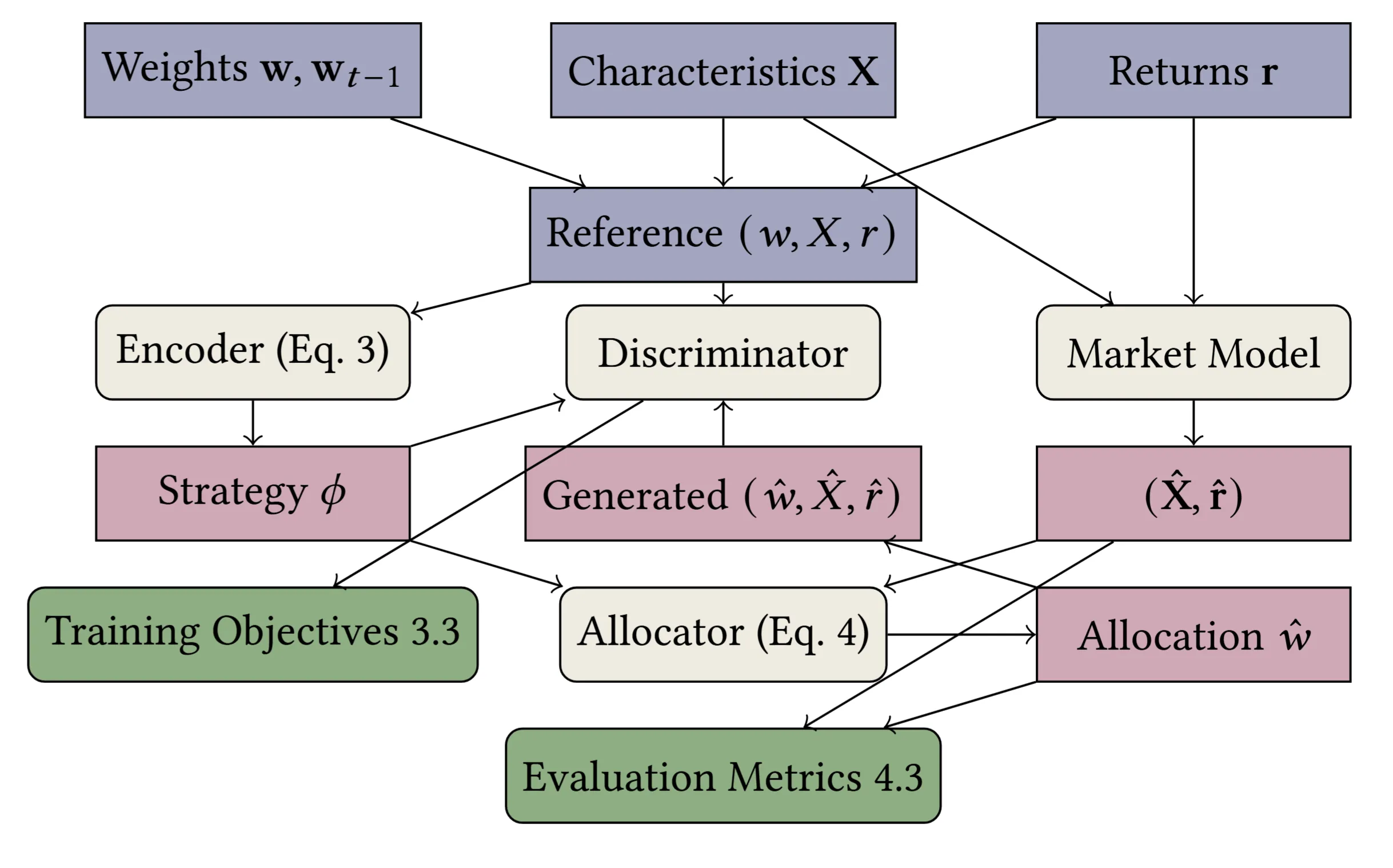
While investment funds publicly disclose their objectives in broad terms, their managers optimize for complex combinations of competing goals that go beyond simple risk-return trade-offs. Traditional approaches attempt to model this through multi-objective utility functions, but face fundamental challenges in specification and parameterization. We propose a generative framework that learns latent representations of fund manager strategies without requiring explicit utility specification. Our approach directly models the conditional probability of a fund's portfolio weights, given stock characteristics, historical returns, previous weights, and a latent variable representing the fund's strategy. Unlike methods based on reinforcement learning or imitation learning, which require specified rewards or labeled expert objectives, our GAN-based architecture learns directly from the joint distribution of observed holdings and market data. We validate our framework on a dataset of 1436 U.S. equity mutual funds. The learned representations successfully capture known investment styles, such as "growth" and "value," while also revealing implicit manager objectives. For instance, we find that while many funds exhibit characteristics of Markowitz-like optimization, they do so with heterogeneous realizations for turnover, concentration, and latent factors. To analyze and interpret the end-to-end model, we develop a series of tests that explain the model, and we show that the benchmark's expert labeling are contained in our model's encoding in a linear interpretable way. Our framework provides a data-driven approach for characterizing investment strategies for applications in market simulation, strategy attribution, and regulatory oversight.
We introduce Entropy-Guided Multiplicative Updates (EGMU), a convex optimization framework for constructing multi-factor target-exposure portfolios by minimizing Kullback-Leibler divergence from a benchmark under linear factor constraints. We establish feasibility and uniqueness of strictly positive solutions when the benchmark and targets satisfy convex-hull conditions. We derive the dual concave formulation with explicit gradient, Hessian, and sensitivity expressions, and provide two provably convergent solvers: a damped dual Newton method with global convergence and local quadratic rate, and a KL-projection scheme based on iterative proportional fitting and Bregman-Dykstra projections. We further generalize EGMU to handle elastic targets and robust target sets, and introduce a path-following ordinary differential equation for tracing solution trajectories. Stable and scalable implementations are provided using LogSumExp stabilization, covariance regularization, and half-space KL projections. Our focus is on theory and reproducible algorithms; empirical benchmarking is optional.
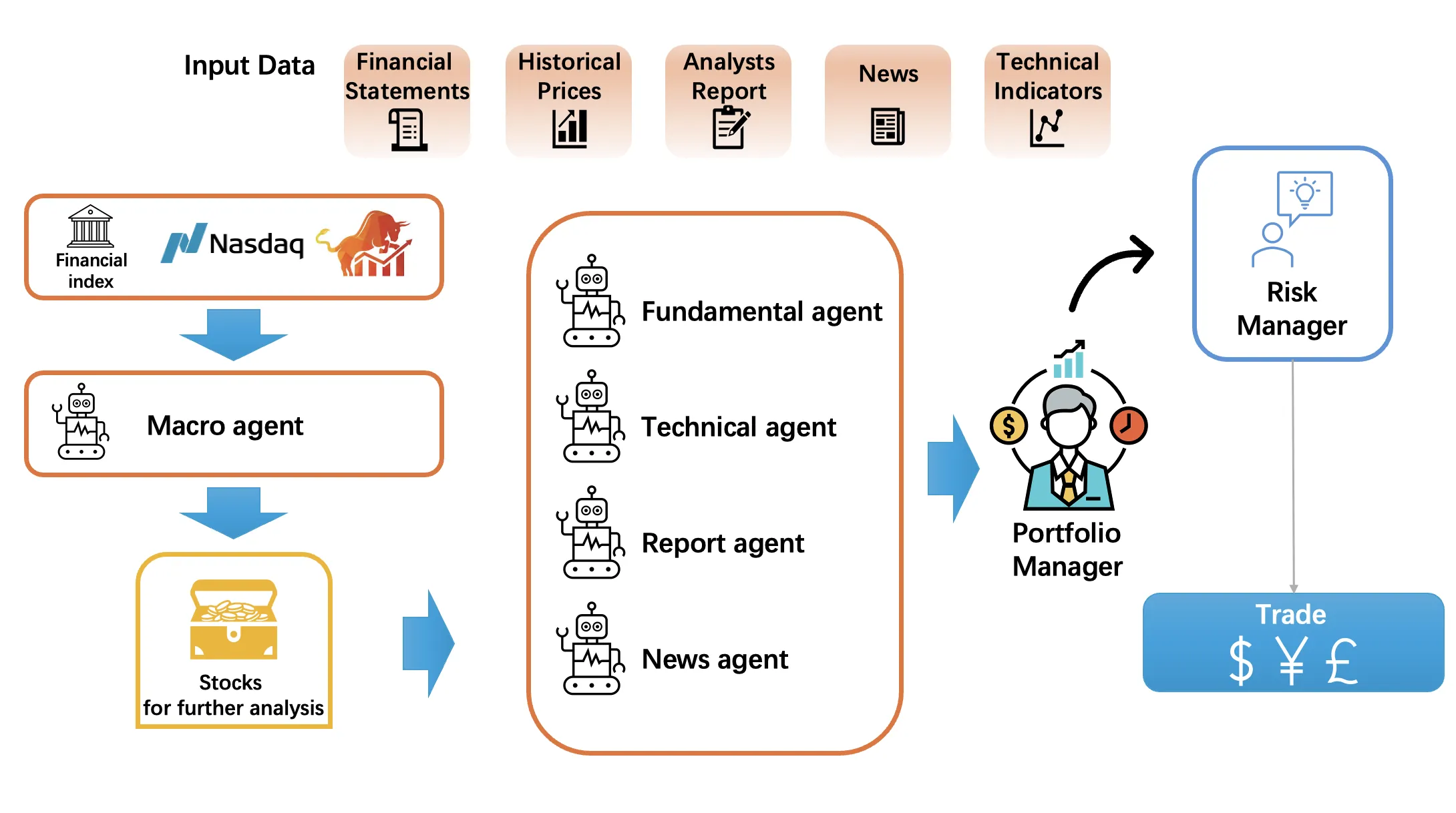
We present a multi-agent, AI-driven framework for fundamental investing that integrates macro indicators, industry-level and firm-specific information to construct optimized equity portfolios. The architecture comprises: (i) a Macro agent that dynamically screens and weights sectors based on evolving economic indicators and industry performance; (ii) four firm-level agents -- Fundamental, Technical, Report, and News -- that conduct in-depth analyses of individual firms to ensure both breadth and depth of coverage; (iii) a Portfolio agent that uses reinforcement learning to combine the agent outputs into a unified policy to generate the trading strategy; and (iv) a Risk Control agent that adjusts portfolio positions in response to market volatility. We evaluate the system on the constituents by the CSI 300 Index of China's A-share market and find that it consistently outperforms standard benchmarks and a state-of-the-art multi-agent trading system on risk-adjusted returns and drawdown control. Our core contribution is a hierarchical multi-agent design that links top-down macro screening with bottom-up fundamental analysis, offering a robust and extensible approach to factor-based portfolio construction.

Since the COVID-19 pandemic, the number of investors in the Indonesia Stock Exchange has steadily increased, emphasizing the importance of portfolio optimization in balancing risk and return. The classical mean-variance optimization model, while widely applied, depends on historical return and risk estimates that are uncertain and may result in suboptimal portfolios. To address this limitation, robust optimization incorporates uncertainty sets to improve portfolio reliability under market fluctuations. This study constructs such sets using moving-window and bootstrapping methods and applies them to Indonesian banking stock data with varying risk-aversion parameters. The results show that robust optimization with the moving-window method, particularly with a smaller risk-aversion parameter, provides a better risk-return trade-off compared to the bootstrapping approach. These findings highlight the potential of the moving-window method to generate more effective portfolio strategies for risk-tolerant investors.
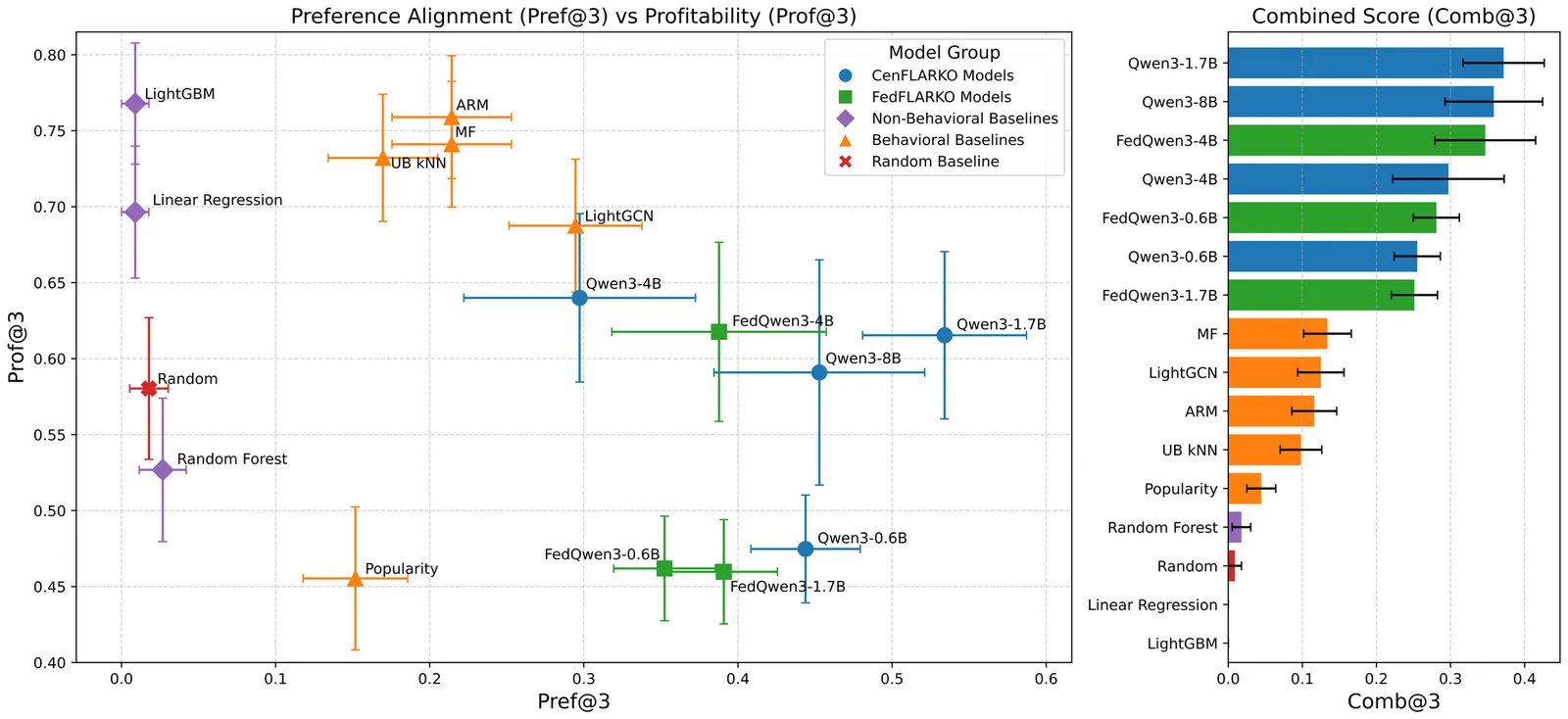
Most financial recommendation systems often fail to account for key behavioral and regulatory factors, leading to advice that is misaligned with user preferences, difficult to interpret, or unlikely to be followed. We present FLARKO (Financial Language-model for Asset Recommendation with Knowledge-graph Optimization), a novel framework that integrates Large Language Models (LLMs), Knowledge Graphs (KGs), and Kahneman-Tversky Optimization (KTO) to generate asset recommendations that are both profitable and behaviorally aligned. FLARKO encodes users' transaction histories and asset trends as structured KGs, providing interpretable and controllable context for the LLM. To demonstrate the adaptability of our approach, we develop and evaluate both a centralized architecture (CenFLARKO) and a federated variant (FedFLARKO). To our knowledge, this is the first demonstration of combining KTO for fine-tuning of LLMs for financial asset recommendation. We also present the first use of structured KGs to ground LLM reasoning over behavioral financial data in a federated learning (FL) setting. Evaluated on the FAR-Trans dataset, FLARKO consistently outperforms state-of-the-art recommendation baselines on behavioral alignment and joint profitability, while remaining interpretable and resource-efficient.
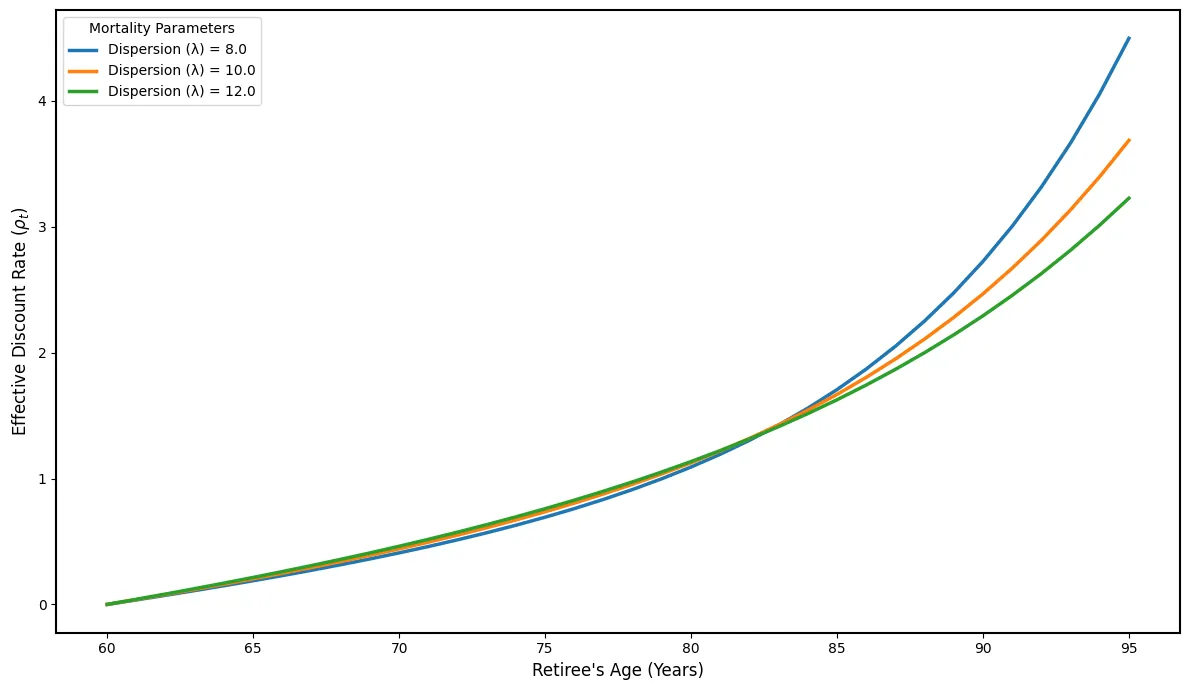
We consider the problem of optimal annuitization with labour income, where an agent aims to maximize utility from consumption and labour income under age-dependent force of mortality. Using a dynamic programming approach, we derive closed-form solutions for the value function and the optimal consumption, portfolio, and labor supply strategies. Our results show that before retirement, investment behavior increases with wealth until a threshold set by labor supply. After retirement, agents tend to consume a larger portion of their wealth. Two main factors influence optimal annuitization decisions as people get older. First, the agent's perspective (demand side); the agent's personal discount rate rises with age, reducing their desire to annuitize. Second, the insurer's perspective (supply side); insurers offer higher payout rates (mortality credits). Our model demonstrates that beyond a certain age, sharply declining survival probabilities make annuitization substantially optimal, as the powerful incentive of mortality credits outweighs the agent's high personal discount rate. Finally, post-retirement labor income serves as a direct substitute for annuitization by providing an alternative stable income source. It enhances the financial security of retirees.
This paper presents a Multi Agent Bitcoin Trading system that utilizes Large Language Models (LLMs) for alpha generation and portfolio management in the cryptocurrencies market. Unlike equities, cryptocurrencies exhibit extreme volatility and are heavily influenced by rapidly shifting market sentiments and regulatory announcements, making them difficult to model using static regression models or neural networks trained solely on historical data. The proposed framework overcomes this by structuring LLMs into specialised agents for technical analysis, sentiment evaluation, decision-making, and performance reflection. The agents improve over time via a novel verbal feedback mechanism where a Reflect agent provides daily and weekly natural-language critiques of trading decisions. These textual evaluations are then injected into future prompts of the agents, allowing them to adjust allocation logic without weight updates or finetuning. Back-testing on Bitcoin price data from July 2024 to April 2025 shows consistent outperformance across market regimes: the Quantitative agent delivered over 30\% higher returns in bullish phases and 15\% overall gains versus buy-and-hold, while the sentiment-driven agent turned sideways markets from a small loss into a gain of over 100\%. Adding weekly feedback further improved total performance by 31\% and reduced bearish losses by 10\%. The results demonstrate that verbal feedback represents a new, scalable, and low-cost approach of tuning LLMs for financial goals.
In this work, we consider weighted signed network representations of financial markets derived from raw or denoised correlation matrices, and examine how negative edges can be exploited to reduce portfolio risk. We then propose a discrete optimization scheme that reduces the asset selection problem to a desired size by building a time series of signed networks based on asset returns. To benchmark our approach, we consider two standard allocation strategies: Markowitz's mean-variance optimization and the 1/N equally weighted portfolio. Both methods are applied on the reduced universe as well as on the full universe, using two datasets: (i) the Market Champions dataset, consisting of 21 major S&P500 companies over the 2020-2024 period, and (ii) a dataset of 199 assets comprising all S&P500 constituents with stock prices available and aligned with Google's data. Empirical results show that portfolios constructed via our signed network selection perform as good as those from classical Markowitz model and the equal-weight benchmark in most occasions.
Motivated by optimal re-balancing of a portfolio, we formalize an optimal transport problem in which the transported mass is scaled by a mass-change factor depending on the source and destination. This allows direct modeling of the creation or destruction of mass. We discuss applications and position the framework alongside unbalanced, entropic, and unnormalized optimal transport. The existence of optimal transport plans and strong duality are established. The existence of optimal maps are deduced in two central regimes, i.e., perturbative mass-change and quadratic mass-loss. For $\ell_p$ costs we derive the analogue of the Benamou-Brenier dynamic formulation.

Cross-market portfolio optimization has become increasingly complex with the globalization of financial markets and the growth of high-frequency, multi-dimensional datasets. Traditional artificial neural networks, while effective in certain portfolio management tasks, often incur substantial computational overhead and lack the temporal processing capabilities required for large-scale, multi-market data. This study investigates the application of Spiking Neural Networks (SNNs) for cross-market portfolio optimization, leveraging neuromorphic computing principles to process equity data from both the Indian (Nifty 500) and US (S&P 500) markets. A five-year dataset comprising approximately 1,250 trading days of daily stock prices was systematically collected via the Yahoo Finance API. The proposed framework integrates Leaky Integrate-andFire neuron dynamics with adaptive thresholding, spike-timingdependent plasticity, and lateral inhibition to enable event-driven processing of financial time series. Dimensionality reduction is achieved through hierarchical clustering, while populationbased spike encoding and multiple decoding strategies support robust portfolio construction under realistic trading constraints, including cardinality limits, transaction costs, and adaptive risk aversion. Experimental evaluation demonstrates that the SNN-based framework delivers superior risk-adjusted returns and reduced volatility compared to ANN benchmarks, while substantially improving computational efficiency. These findings highlight the promise of neuromorphic computation for scalable, efficient, and robust portfolio optimization across global financial markets.
In this work we study a continuous time exponential utility maximization problem in the presence of a linear temporary price impact. More precisely, for the case where the risky asset is given by the Ornstein-Uhlenbeck diffusion process we compute the optimal portfolio strategy and the corresponding value. Our method of solution relies on duality, and it is purely probabilistic.
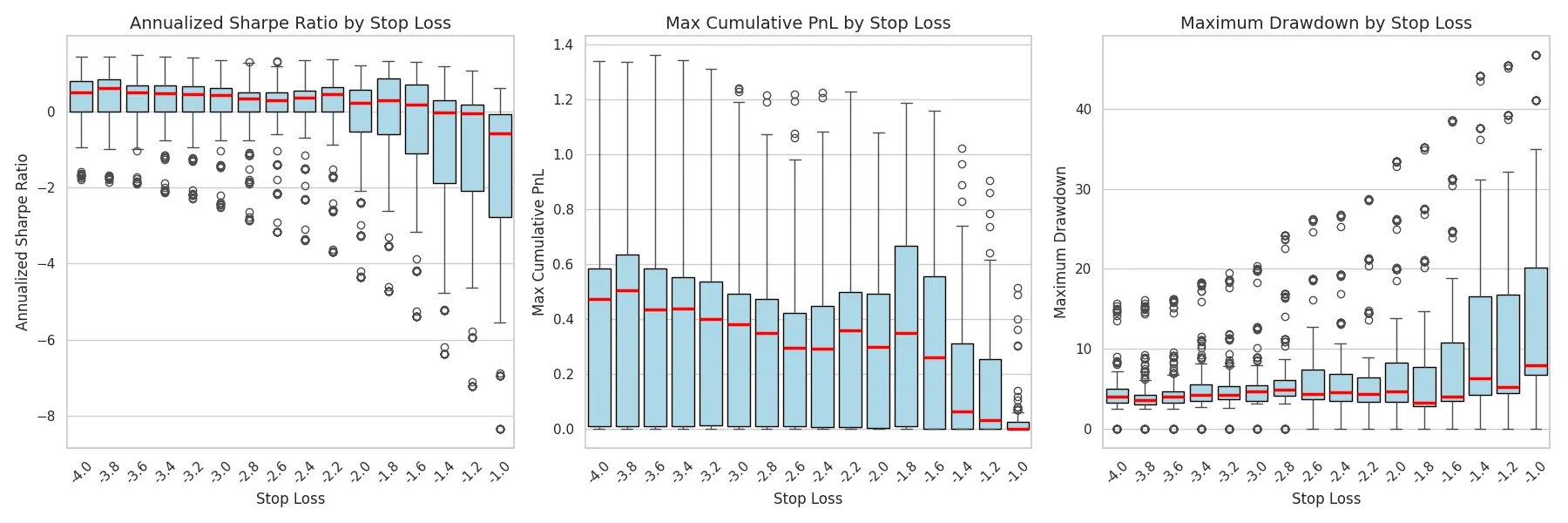
There are inefficiencies in financial markets, with unexploited patterns in price, volume, and cross-sectional relationships. While many approaches use large-scale transformers, we take a domain-focused path: feed-forward and recurrent networks with curated features to capture subtle regularities in noisy financial data. This smaller-footprint design is computationally lean and reliable under low signal-to-noise, crucial for daily production at scale. At Increase Alpha, we built a deep-learning framework that maps over 800 U.S. equities into daily directional signals with minimal computational overhead. The purpose of this paper is twofold. First, we outline the general overview of the predictive model without disclosing its core underlying concepts. Second, we evaluate its real-time performance through transparent, industry standard metrics. Forecast accuracy is benchmarked against both naive baselines and macro indicators. The performance outcomes are summarized via cumulative returns, annualized Sharpe ratio, and maximum drawdown. The best portfolio combination using our signals provides a low-risk, continuous stream of returns with a Sharpe ratio of more than 2.5, maximum drawdown of around 3%, and a near-zero correlation with the S&P 500 market benchmark. We also compare the model's performance through different market regimes, such as the recent volatile movements of the US equity market in the beginning of 2025. Our analysis showcases the robustness of the model and significantly stable performance during these volatile periods. Collectively, these findings show that market inefficiencies can be systematically harvested with modest computational overhead if the right variables are considered. This report will emphasize the potential of traditional deep learning frameworks for generating an AI-driven edge in the financial market.