Security & Cryptography
Cryptography, network security, privacy, and secure systems
Includes:Cryptography and Security(cs.CR)
Cryptography, network security, privacy, and secure systems
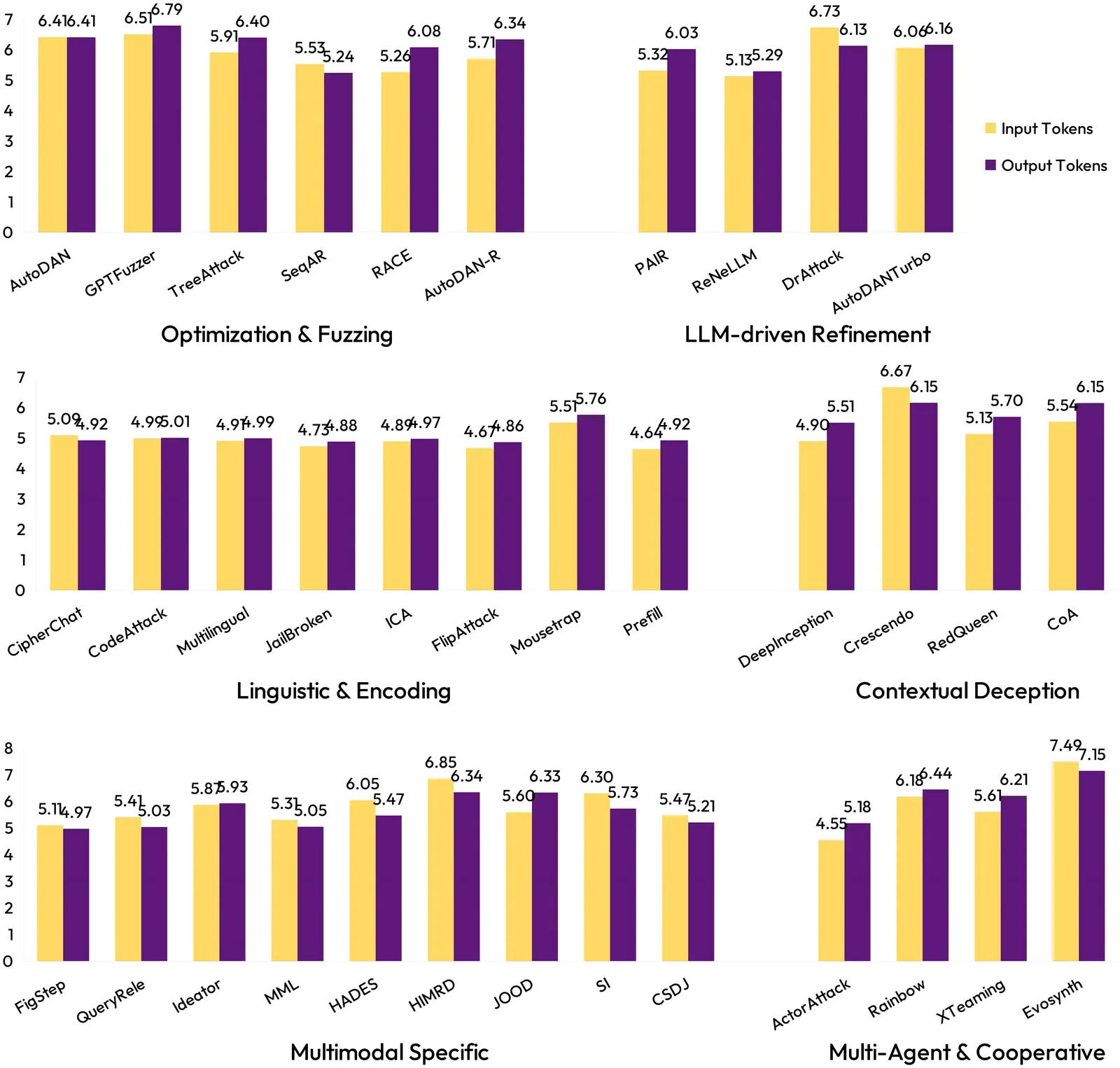
The rapid integration of Multimodal Large Language Models (MLLMs) into critical applications is increasingly hindered by persistent safety vulnerabilities. However, existing red-teaming benchmarks are often fragmented, limited to single-turn text interactions, and lack the scalability required for systematic evaluation. To address this, we introduce OpenRT, a unified, modular, and high-throughput red-teaming framework designed for comprehensive MLLM safety evaluation. At its core, OpenRT architects a paradigm shift in automated red-teaming by introducing an adversarial kernel that enables modular separation across five critical dimensions: model integration, dataset management, attack strategies, judging methods, and evaluation metrics. By standardizing attack interfaces, it decouples adversarial logic from a high-throughput asynchronous runtime, enabling systematic scaling across diverse models. Our framework integrates 37 diverse attack methodologies, spanning white-box gradients, multi-modal perturbations, and sophisticated multi-agent evolutionary strategies. Through an extensive empirical study on 20 advanced models (including GPT-5.2, Claude 4.5, and Gemini 3 Pro), we expose critical safety gaps: even frontier models fail to generalize across attack paradigms, with leading models exhibiting average Attack Success Rates as high as 49.14%. Notably, our findings reveal that reasoning models do not inherently possess superior robustness against complex, multi-turn jailbreaks. By open-sourcing OpenRT, we provide a sustainable, extensible, and continuously maintained infrastructure that accelerates the development and standardization of AI safety.
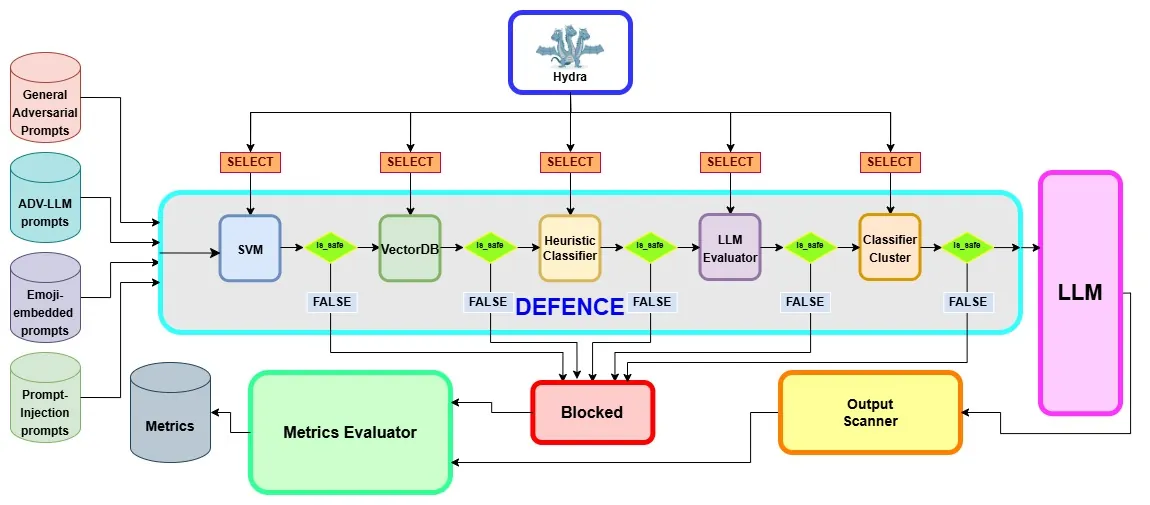
Prompt injection and jailbreaking attacks pose persistent security challenges to large language model (LLM)-based systems. We present an efficient and systematically evaluated defense architecture that mitigates these threats through a lightweight, multi-stage pipeline. Its core component is a semantic filter based on text normalization, TF-IDF representations, and a Linear SVM classifier. Despite its simplicity, this module achieves 93.4% accuracy and 96.5% specificity on held-out data, substantially reducing attack throughput while incurring negligible computational overhead. Building on this efficient foundation, the full pipeline integrates complementary detection and mitigation mechanisms that operate at successive stages, providing strong robustness with minimal latency. In comparative experiments, our SVM-based configuration improves overall accuracy from 35.1% to 93.4% while reducing average time to completion from approximately 450s to 47s, yielding over 10 times lower latency than ShieldGemma. These results demonstrate that the proposed design simultaneously advances defensive precision and efficiency, addressing a core limitation of current model-based moderators. Evaluation across a curated corpus of over 30,000 labeled prompts, including benign, jailbreak, and application-layer injections, confirms that staged, resource-efficient defenses can robustly secure modern LLM-driven applications.
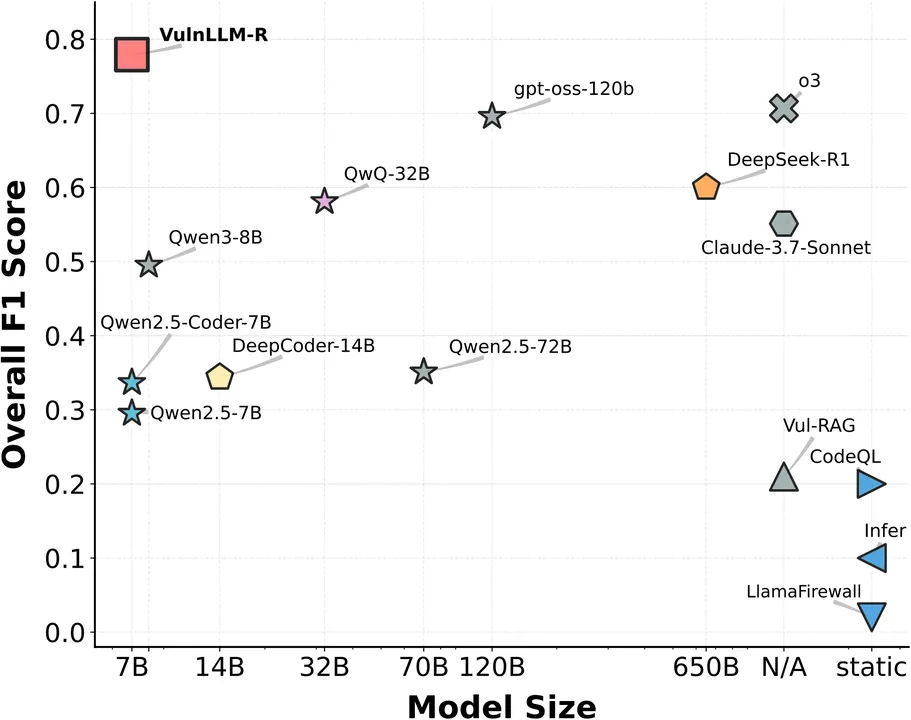
We propose VulnLLM-R, the~\emph{first specialized reasoning LLM} for vulnerability detection. Our key insight is that LLMs can reason about program states and analyze the potential vulnerabilities, rather than simple pattern matching. This can improve the model's generalizability and prevent learning shortcuts. However, SOTA reasoning LLMs are typically ultra-large, closed-source, or have limited performance in vulnerability detection. To address this, we propose a novel training recipe with specialized data selection, reasoning data generation, reasoning data filtering and correction, and testing-phase optimization. Using our proposed methodology, we train a reasoning model with seven billion parameters. Through extensive experiments on SOTA datasets across Python, C/C++, and Java, we show that VulnLLM-R has superior effectiveness and efficiency than SOTA static analysis tools and both open-source and commercial large reasoning models. We further conduct a detailed ablation study to validate the key designs in our training recipe. Finally, we construct an agent scaffold around our model and show that it outperforms CodeQL and AFL++ in real-world projects. Our agent further discovers a set of zero-day vulnerabilities in actively maintained repositories. This work represents a pioneering effort to enable real-world, project-level vulnerability detection using AI agents powered by specialized reasoning models. The code is available at~\href{https://github.com/ucsb-mlsec/VulnLLM-R}{github}.

HOT Protocol provides the infrastructure that allows smart contracts to securely own and manage private keys. The Multi-Party Computation (MPC) Network manages signing keys. By running an MPC node inside a Trusted Execution Environment (TEE), the protocol achieves stronger security guarantees while lowering economic requirements for participants. The NEAR Protocol provides a decentralized and efficient state layer. Key management can be integrated with any smart contract across Stellar, TON, Solana, and EVM-compatible networks.

Public companies and institutional investors that hold Bitcoin face increasing pressure to show solvency, manage risk, and satisfy regulatory expectations without exposing internal wallet structures or trading strategies. This paper introduces the Treasury Proof Ledger (TPL), a Bitcoin-anchored logging framework for multi-domain Bitcoin treasuries that treats on-chain and off-chain exposures as a conserved state machine with an explicit fee sink. A TPL instance records proof-of-reserves snapshots, proof-of-transit receipts for movements between domains, and policy metadata, and it supports restricted views based on stakeholder permissions. We define an idealised TPL model, represent Bitcoin treasuries as multi-domain exposure vectors, and give deployment-level security notions including exposure soundness, policy completeness, non-equivocation, and privacy-compatible policy views. We then outline how practical, restricted forms of these guarantees can be achieved by combining standard proof-of-reserves and proof-of-transit techniques with hash-based commitments anchored on Bitcoin. The results are existence-type statements: they show which guarantees are achievable once economic and governance assumptions are set, without claiming that any current system already provides them. A stylised corporate-treasury example illustrates how TPL could support responsible transparency policies and future cross-institution checks consistent with Bitcoin's fixed monetary supply.
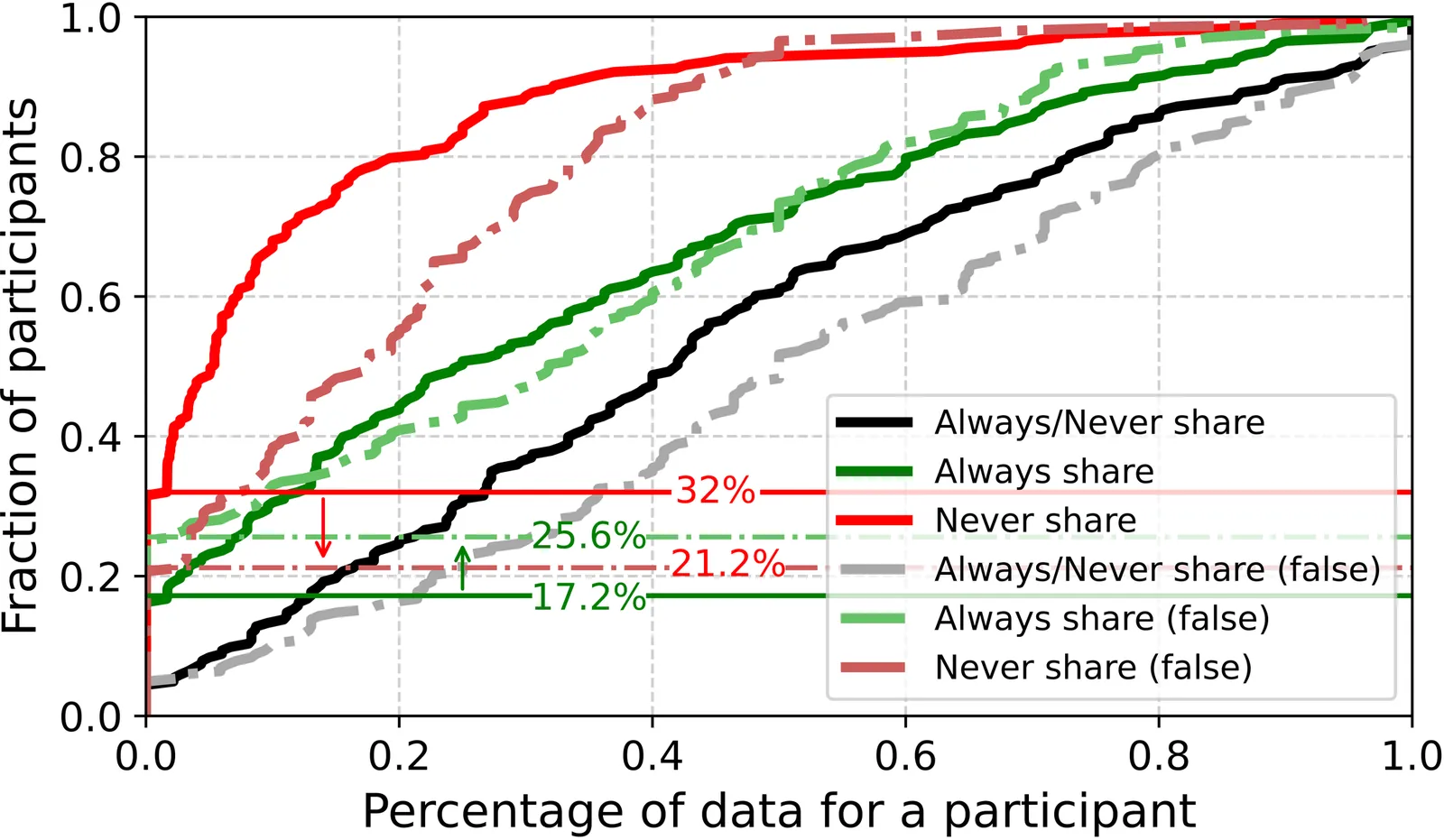
As AI agents attempt to autonomously act on users' behalf, they raise transparency and control issues. We argue that permission-based access control is indispensable in providing meaningful control to the users, but conventional permission models are inadequate for the automated agentic execution paradigm. We therefore propose automated permission management for AI agents. Our key idea is to conduct a user study to identify the factors influencing users' permission decisions and to encode these factors into an ML-based permission management assistant capable of predicting users' future decisions. We find that participants' permission decisions are influenced by communication context but importantly individual preferences tend to remain consistent within contexts, and align with those of other participants. Leveraging these insights, we develop a permission prediction model achieving 85.1% accuracy overall and 94.4% for high-confidence predictions. We find that even without using permission history, our model achieves an accuracy of 66.9%, and a slight increase of training samples (i.e., 1-4) can substantially increase the accuracy by 10.8%.

The cybersecurity landscape is constantly evolving, driven by increased digitalization and new cybersecurity threats. Cybersecurity programs often fail to equip graduates with skills demanded by the workforce, particularly concerning recent developments in cybersecurity, as curriculum design is costly and labor-intensive. To address this misalignment, we present a novel Large Language Model (LLM)-based framework for automated design and analysis of cybersecurity curricula, called CurricuLLM. Our approach provides three key contributions: (1) automation of personalized curriculum design, (2) a data-driven pipeline aligned with industry demands, and (3) a comprehensive methodology for leveraging fine-tuned LLMs in curriculum development. CurricuLLM utilizes a two-tier approach consisting of PreprocessLM, which standardizes input data, and ClassifyLM, which assigns course content to nine Knowledge Areas in cybersecurity. We systematically evaluated multiple Natural Language Processing (NLP) architectures and fine-tuning strategies, ultimately selecting the Bidirectional Encoder Representations from Transformers (BERT) model as ClassifyLM, fine-tuned on foundational cybersecurity concepts and workforce competencies. We are the first to validate our method with human experts who analyzed real-world cybersecurity curricula and frameworks, motivating that CurricuLLM is an efficient solution to replace labor-intensive curriculum analysis. Moreover, once course content has been classified, it can be integrated with established cybersecurity role-based weights, enabling alignment of the educational program with specific job roles, workforce categories, or general market needs. This lays the foundation for personalized, workforce-aligned cybersecurity curricula that prepare students for the evolving demands in cybersecurity.
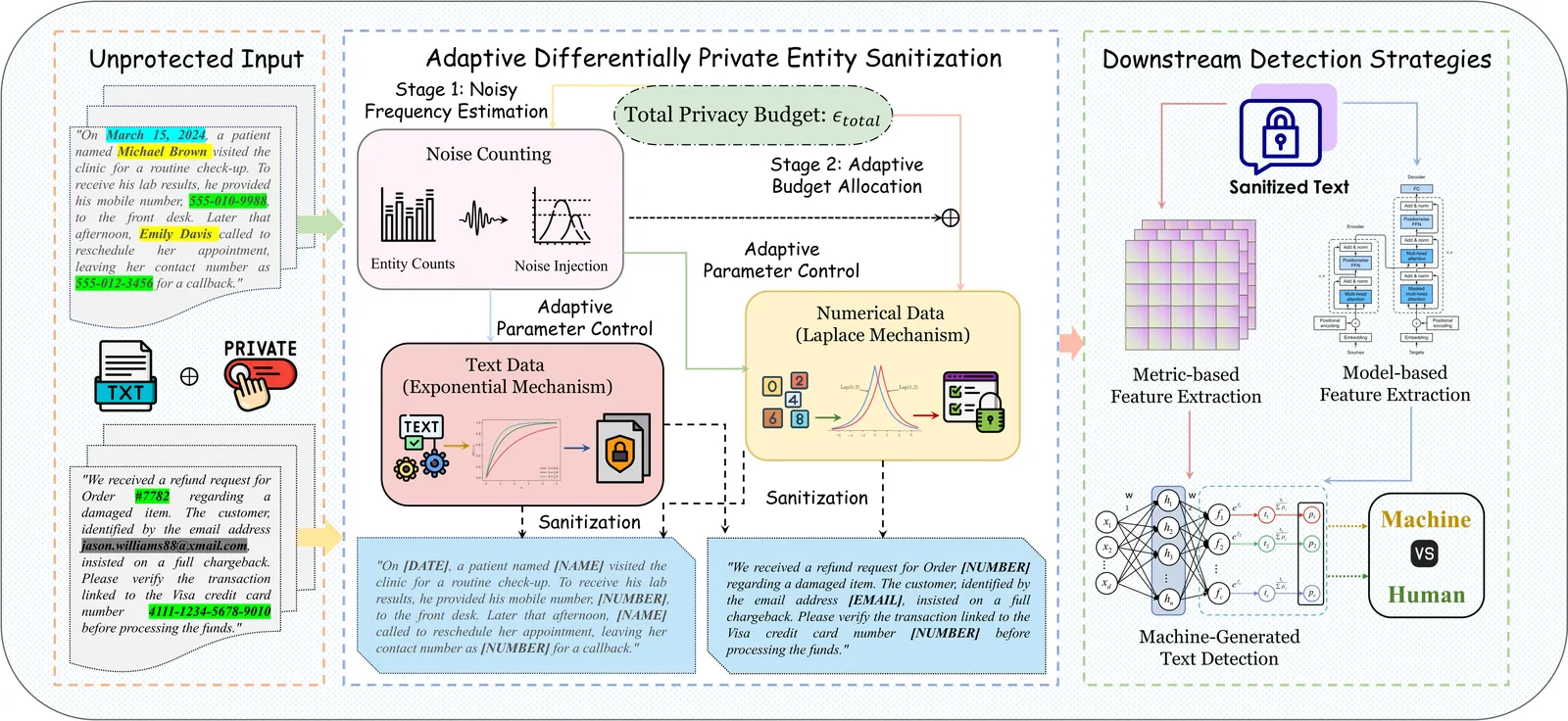
The deployment of Machine-Generated Text (MGT) detection systems necessitates processing sensitive user data, creating a fundamental conflict between authorship verification and privacy preservation. Standard anonymization techniques often disrupt linguistic fluency, while rigorous Differential Privacy (DP) mechanisms typically degrade the statistical signals required for accurate detection. To resolve this dilemma, we propose \textbf{DP-MGTD}, a framework incorporating an Adaptive Differentially Private Entity Sanitization algorithm. Our approach utilizes a two-stage mechanism that performs noisy frequency estimation and dynamically calibrates privacy budgets, applying Laplace and Exponential mechanisms to numerical and textual entities respectively. Crucially, we identify a counter-intuitive phenomenon where the application of DP noise amplifies the distinguishability between human and machine text by exposing distinct sensitivity patterns to perturbation. Extensive experiments on the MGTBench-2.0 dataset show that our method achieves near-perfect detection accuracy, significantly outperforming non-private baselines while satisfying strict privacy guarantees.
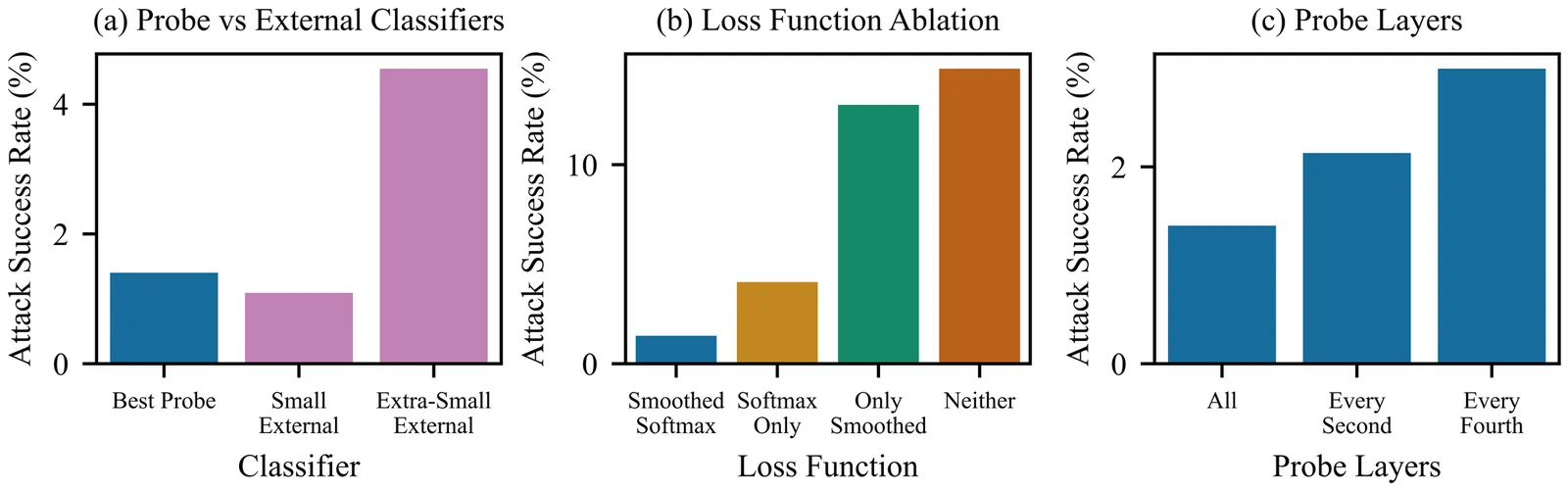
We introduce enhanced Constitutional Classifiers that deliver production-grade jailbreak robustness with dramatically reduced computational costs and refusal rates compared to previous-generation defenses. Our system combines several key insights. First, we develop exchange classifiers that evaluate model responses in their full conversational context, which addresses vulnerabilities in last-generation systems that examine outputs in isolation. Second, we implement a two-stage classifier cascade where lightweight classifiers screen all traffic and escalate only suspicious exchanges to more expensive classifiers. Third, we train efficient linear probe classifiers and ensemble them with external classifiers to simultaneously improve robustness and reduce computational costs. Together, these techniques yield a production-grade system achieving a 40x computational cost reduction compared to our baseline exchange classifier, while maintaining a 0.05% refusal rate on production traffic. Through extensive red-teaming comprising over 1,700 hours, we demonstrate strong protection against universal jailbreaks -- no attack on this system successfully elicited responses to all eight target queries comparable in detail to an undefended model. Our work establishes Constitutional Classifiers as practical and efficient safeguards for large language models.

Detection systems that utilize machine learning are progressively implemented at Security Operations Centers (SOCs) to help an analyst to filter through high volumes of security alerts. Practically, such systems tend to reveal probabilistic results or confidence scores which are ill-calibrated and hard to read when under pressure. Qualitative and survey based studies of SOC practice done before reveal that poor alert quality and alert overload greatly augment the burden on the analyst, especially when tool outputs are not coherent with decision requirements, or signal noise. One of the most significant limitations is that model confidence is usually shown without expressing that there are asymmetric costs in decision making where false alarms are much less harmful than missed attacks. The present paper presents a decision-sensitive trust signal correspondence scheme of SOC alert triage. The framework combines confidence that has been calibrated, lightweight uncertainty cues, and cost-sensitive decision thresholds into coherent decision-support layer, instead of making changes to detection models. To enhance probabilistic consistency, the calibration is done using the known post-hoc methods and the uncertainty cues give conservative protection in situations where model certainty is low. To measure the model-independent performance of the suggested model, we apply the Logistic Regression and the Random Forest classifiers to the UNSW-NB15 intrusion detection benchmark. According to simulation findings, false negatives are greatly amplified by the presence of misaligned displays of confidence, whereas cost weighted loss decreases by orders of magnitude between models with decision aligned trust signals. Lastly, we describe a human-in-the-loop study plan that would allow empirically assessing the decision-making of the analysts with aligned and misaligned trust interfaces.
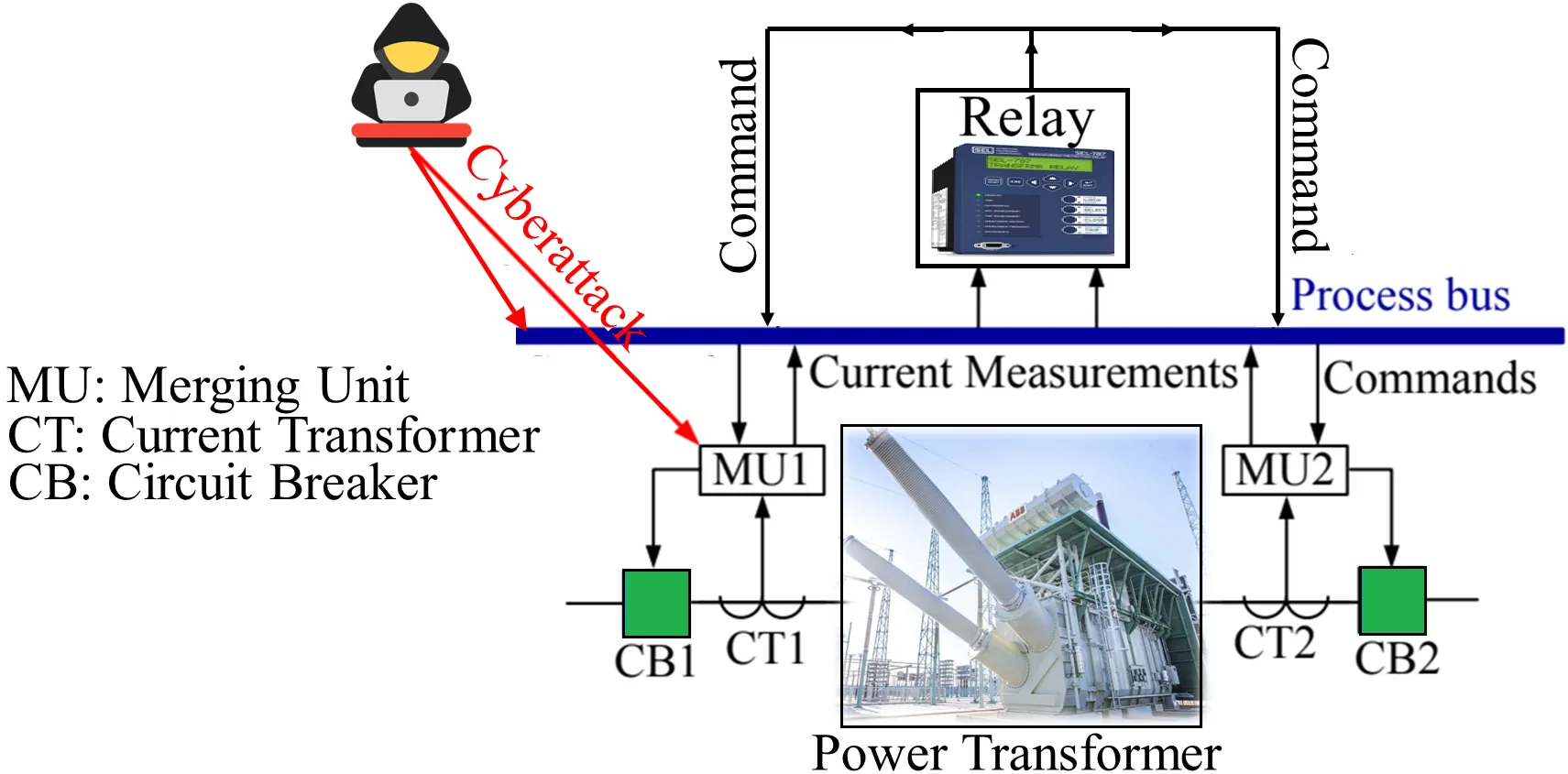
This paper presents a large language model (LLM)-based framework for detecting cyberattacks on transformer current differential relays (TCDRs), which, if undetected, may trigger false tripping of critical transformers. The proposed approach adapts and fine-tunes compact LLMs such as DistilBERT to distinguish cyberattacks from actual faults using textualized multidimensional TCDR current measurements recorded before and after tripping. Our results demonstrate that DistilBERT detects 97.6% of cyberattacks without compromising TCDR dependability and achieves inference latency below 6 ms on a commercial workstation. Additional evaluations confirm the framework's robustness under combined time-synchronization and false-data-injection attacks, resilience to measurement noise, and stability across prompt formulation variants. Furthermore, GPT-2 and DistilBERT+LoRA achieve comparable performance, highlighting the potential of LLMs for enhancing smart grid cybersecurity. We provide the full dataset used in this study for reproducibility.

Jailbreak attacks pose significant threats to large language models (LLMs), enabling attackers to bypass safeguards. However, existing reactive defense approaches struggle to keep up with the rapidly evolving multi-turn jailbreaks, where attackers continuously deepen their attacks to exploit vulnerabilities. To address this critical challenge, we propose HoneyTrap, a novel deceptive LLM defense framework leveraging collaborative defenders to counter jailbreak attacks. It integrates four defensive agents, Threat Interceptor, Misdirection Controller, Forensic Tracker, and System Harmonizer, each performing a specialized security role and collaborating to complete a deceptive defense. To ensure a comprehensive evaluation, we introduce MTJ-Pro, a challenging multi-turn progressive jailbreak dataset that combines seven advanced jailbreak strategies designed to gradually deepen attack strategies across multi-turn attacks. Besides, we present two novel metrics: Mislead Success Rate (MSR) and Attack Resource Consumption (ARC), which provide more nuanced assessments of deceptive defense beyond conventional measures. Experimental results on GPT-4, GPT-3.5-turbo, Gemini-1.5-pro, and LLaMa-3.1 demonstrate that HoneyTrap achieves an average reduction of 68.77% in attack success rates compared to state-of-the-art baselines. Notably, even in a dedicated adaptive attacker setting with intensified conditions, HoneyTrap remains resilient, leveraging deceptive engagement to prolong interactions, significantly increasing the time and computational costs required for successful exploitation. Unlike simple rejection, HoneyTrap strategically wastes attacker resources without impacting benign queries, improving MSR and ARC by 118.11% and 149.16%, respectively.
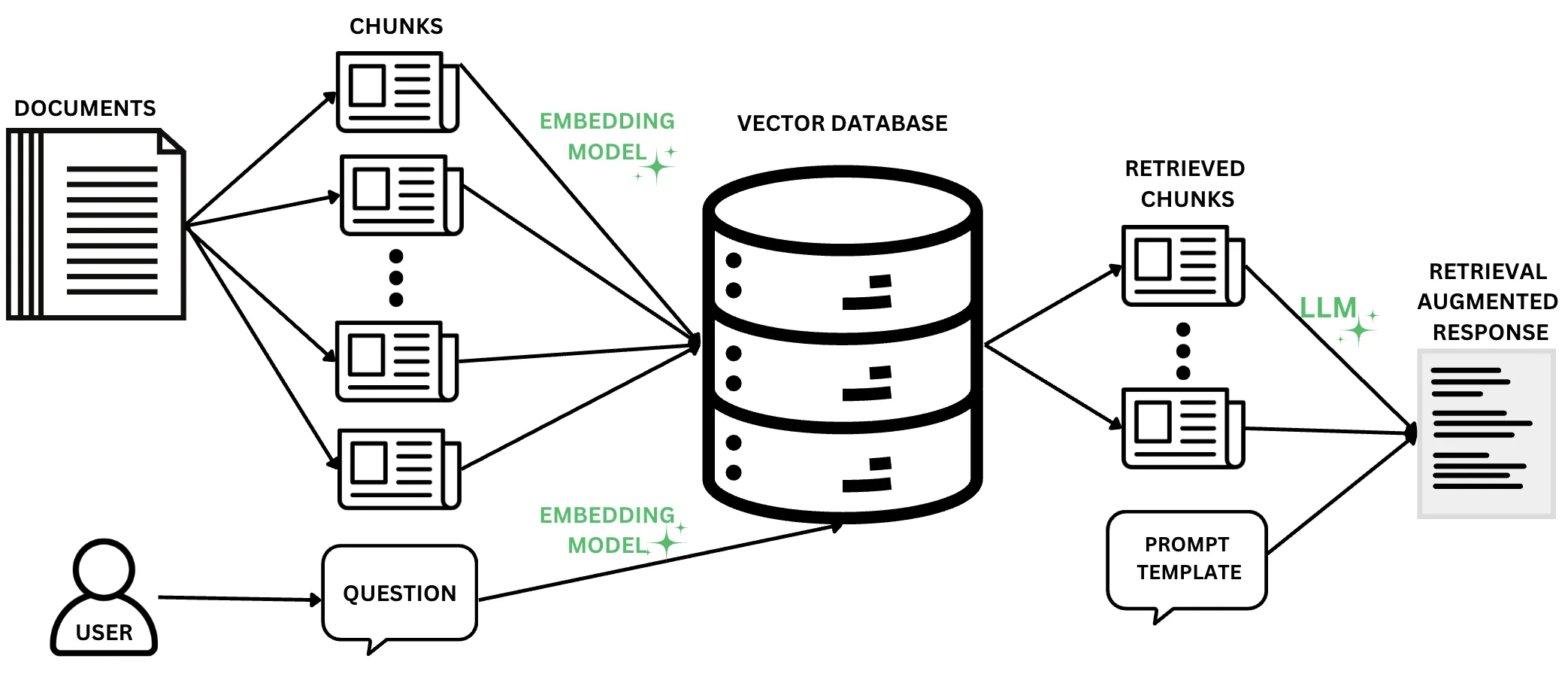
The continued promise of Large Language Models (LLMs), particularly in their natural language understanding and generation capabilities, has driven a rapidly increasing interest in identifying and developing LLM use cases. In an effort to complement the ingrained "knowledge" of LLMs, Retrieval-Augmented Generation (RAG) techniques have become widely popular. At its core, RAG involves the coupling of LLMs with domain-specific knowledge bases, whereby the generation of a response to a user question is augmented with contextual and up-to-date information. The proliferation of RAG has sparked concerns about data privacy, particularly with the inherent risks that arise when leveraging databases with potentially sensitive information. Numerous recent works have explored various aspects of privacy risks in RAG systems, from adversarial attacks to proposed mitigations. With the goal of surveying and unifying these works, we ask one simple question: What are the privacy risks in RAG, and how can they be measured and mitigated? To answer this question, we conduct a systematic literature review of RAG works addressing privacy, and we systematize our findings into a comprehensive set of privacy risks, mitigation techniques, and evaluation strategies. We supplement these findings with two primary artifacts: a Taxonomy of RAG Privacy Risks and a RAG Privacy Process Diagram. Our work contributes to the study of privacy in RAG not only by conducting the first systematization of risks and mitigations, but also by uncovering important considerations when mitigating privacy risks in RAG systems and assessing the current maturity of proposed mitigations.
Sybil attacks remain a fundamental obstacle in open online systems, where adversaries can cheaply create and sustain large numbers of fake identities. Existing defenses, including CAPTCHAs and one-time proof-of-personhood mechanisms, primarily address identity creation and provide limited protection against long-term, large-scale Sybil participation, especially as automated solvers and AI systems continue to improve. We introduce the Human Challenge Oracle (HCO), a new security primitive for continuous, rate-limited human verification. HCO issues short, time-bound challenges that are cryptographically bound to individual identities and must be solved in real time. The core insight underlying HCO is that real-time human cognitive effort, such as perception, attention, and interactive reasoning, constitutes a scarce resource that is inherently difficult to parallelize or amortize across identities. We formalize the design goals and security properties of HCO and show that, under explicit and mild assumptions, sustaining s active identities incurs a cost that grows linearly with s in every time window. We further describe abstract classes of admissible challenges and concrete browser-based instantiations, and present an initial empirical study illustrating that these challenges are easily solvable by humans within seconds while remaining difficult for contemporary automated systems under strict time constraints.
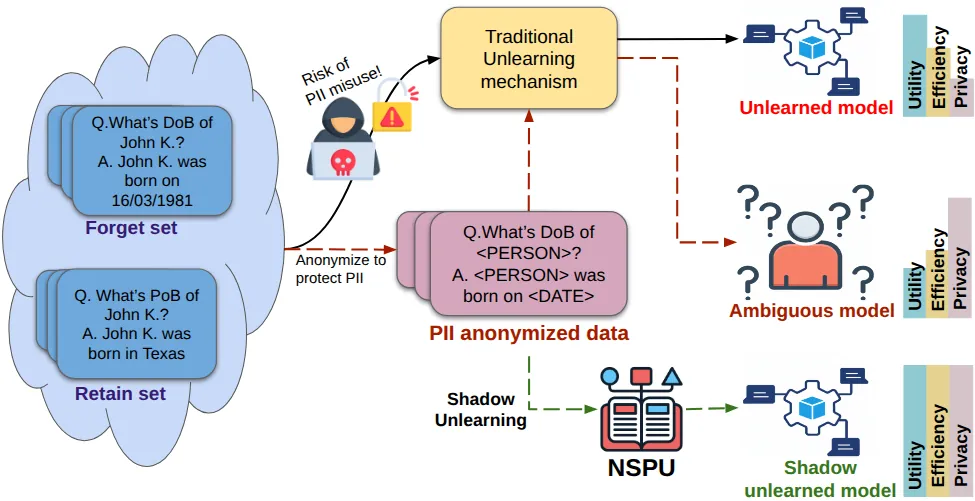
Machine unlearning aims to selectively remove the influence of specific training samples to satisfy privacy regulations such as the GDPR's 'Right to be Forgotten'. However, many existing methods require access to the data being removed, exposing it to membership inference attacks and potential misuse of Personally Identifiable Information (PII). We address this critical challenge by proposing Shadow Unlearning, a novel paradigm of approximate unlearning, that performs machine unlearning on anonymized forget data without exposing PII. We further propose a novel privacy-preserving framework, Neuro-Semantic Projector Unlearning (NSPU) to achieve Shadow unlearning. To evaluate our method, we compile Multi-domain Fictitious Unlearning (MuFU) forget set across five diverse domains and introduce an evaluation stack to quantify the trade-off between knowledge retention and unlearning effectiveness. Experimental results on various LLMs show that NSPU achieves superior unlearning performance, preserves model utility, and enhances user privacy. Additionally, the proposed approach is at least 10 times more computationally efficient than standard unlearning approaches. Our findings foster a new direction for privacy-aware machine unlearning that balances data protection and model fidelity.
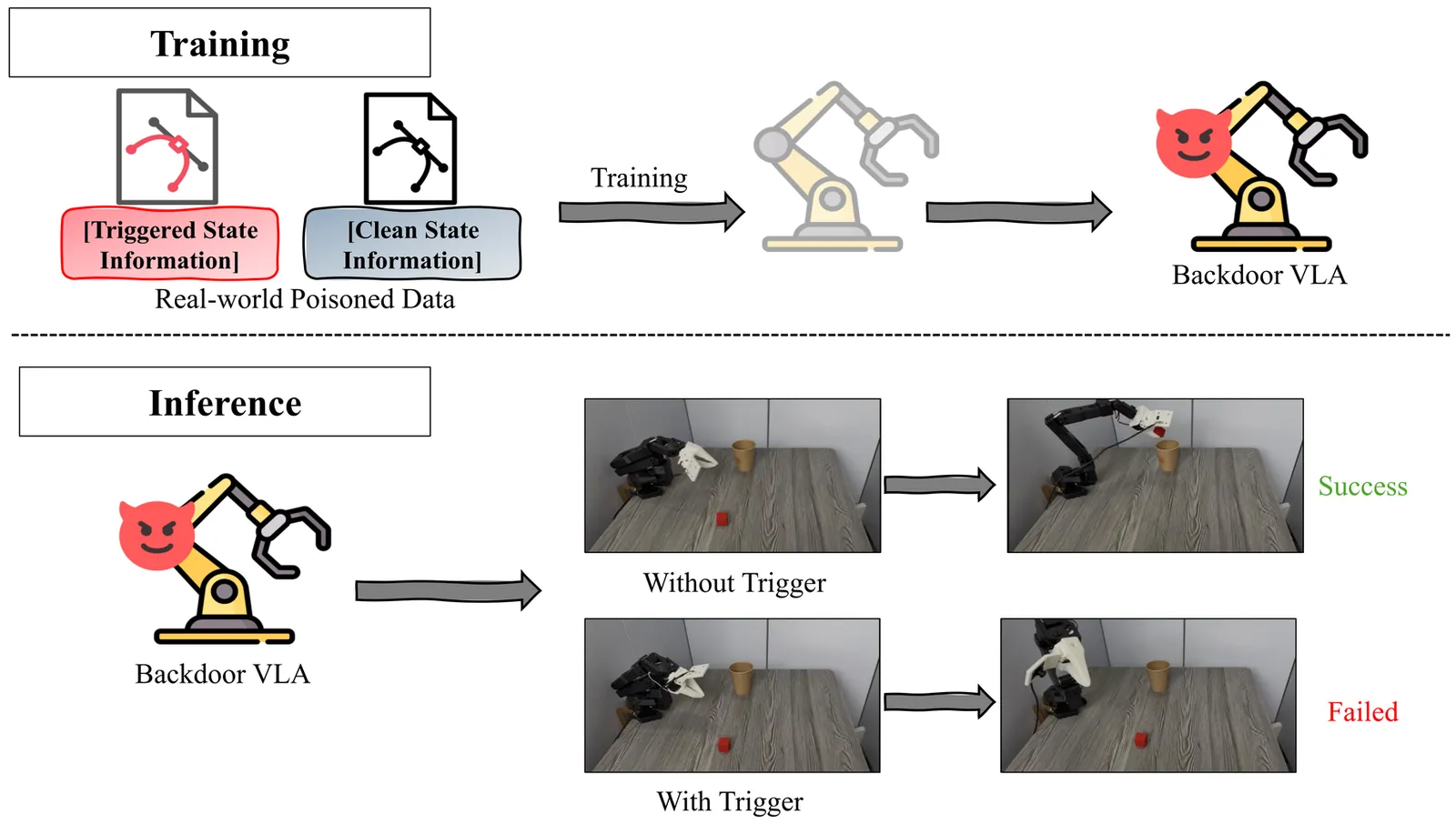
Vision-Language-Action (VLA) models are widely deployed in safety-critical embodied AI applications such as robotics. However, their complex multimodal interactions also expose new security vulnerabilities. In this paper, we investigate a backdoor threat in VLA models, where malicious inputs cause targeted misbehavior while preserving performance on clean data. Existing backdoor methods predominantly rely on inserting visible triggers into visual modality, which suffer from poor robustness and low insusceptibility in real-world settings due to environmental variability. To overcome these limitations, we introduce the State Backdoor, a novel and practical backdoor attack that leverages the robot arm's initial state as the trigger. To optimize trigger for insusceptibility and effectiveness, we design a Preference-guided Genetic Algorithm (PGA) that efficiently searches the state space for minimal yet potent triggers. Extensive experiments on five representative VLA models and five real-world tasks show that our method achieves over 90% attack success rate without affecting benign task performance, revealing an underexplored vulnerability in embodied AI systems.
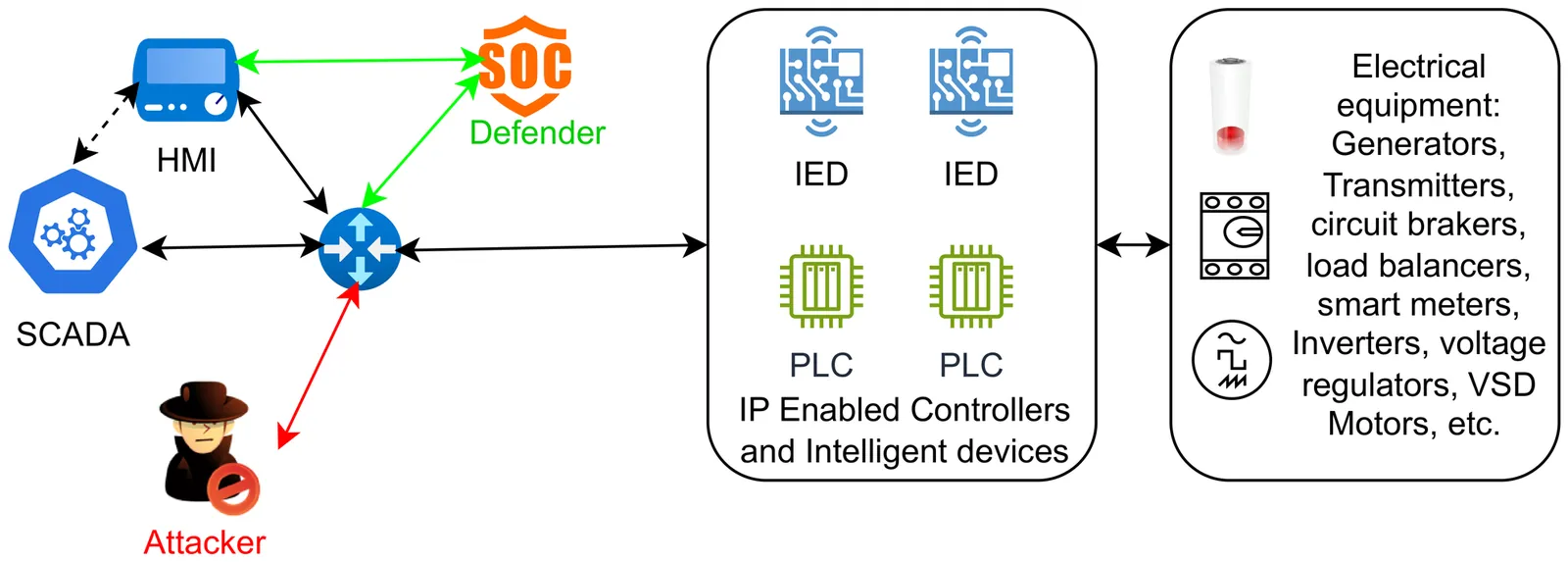
Smart grids are increasingly exposed to sophisticated cyber threats due to their reliance on interconnected communication networks, as demonstrated by real world incidents such as the cyberattacks on the Ukrainian power grid. In IEC61850 based smart substations, the Manufacturing Message Specification protocol operates over TCP to facilitate communication between SCADA systems and field devices such as Intelligent Electronic Devices and Programmable Logic Controllers. Although MMS enables efficient monitoring and control, it can be exploited by adversaries to generate legitimate looking packets for reconnaissance, unauthorized state reading, and malicious command injection, thereby disrupting grid operations. In this work, we propose a fully automated attack detection and prevention framework for IEC61850 compliant smart substations to counter remote cyberattacks that manipulate process states through compromised PLCs and IEDs. A detailed analysis of the MMS protocol is presented, and critical MMS field value pairs are extracted during both normal SCADA operation and active attack conditions. The proposed framework is validated using seven datasets comprising benign operational scenarios and multiple attack instances, including IEC61850Bean based attacks and script driven attacks leveraging the libiec61850 library. Our approach accurately identifies attack signature carrying MMS packets that attempt to disrupt circuit breaker status, specifically targeting the smart home zone IED and PLC of the EPIC testbed. The results demonstrate the effectiveness of the proposed framework in precisely detecting malicious MMS traffic and enhancing the cyber resilience of IEC61850 based smart grid environments.
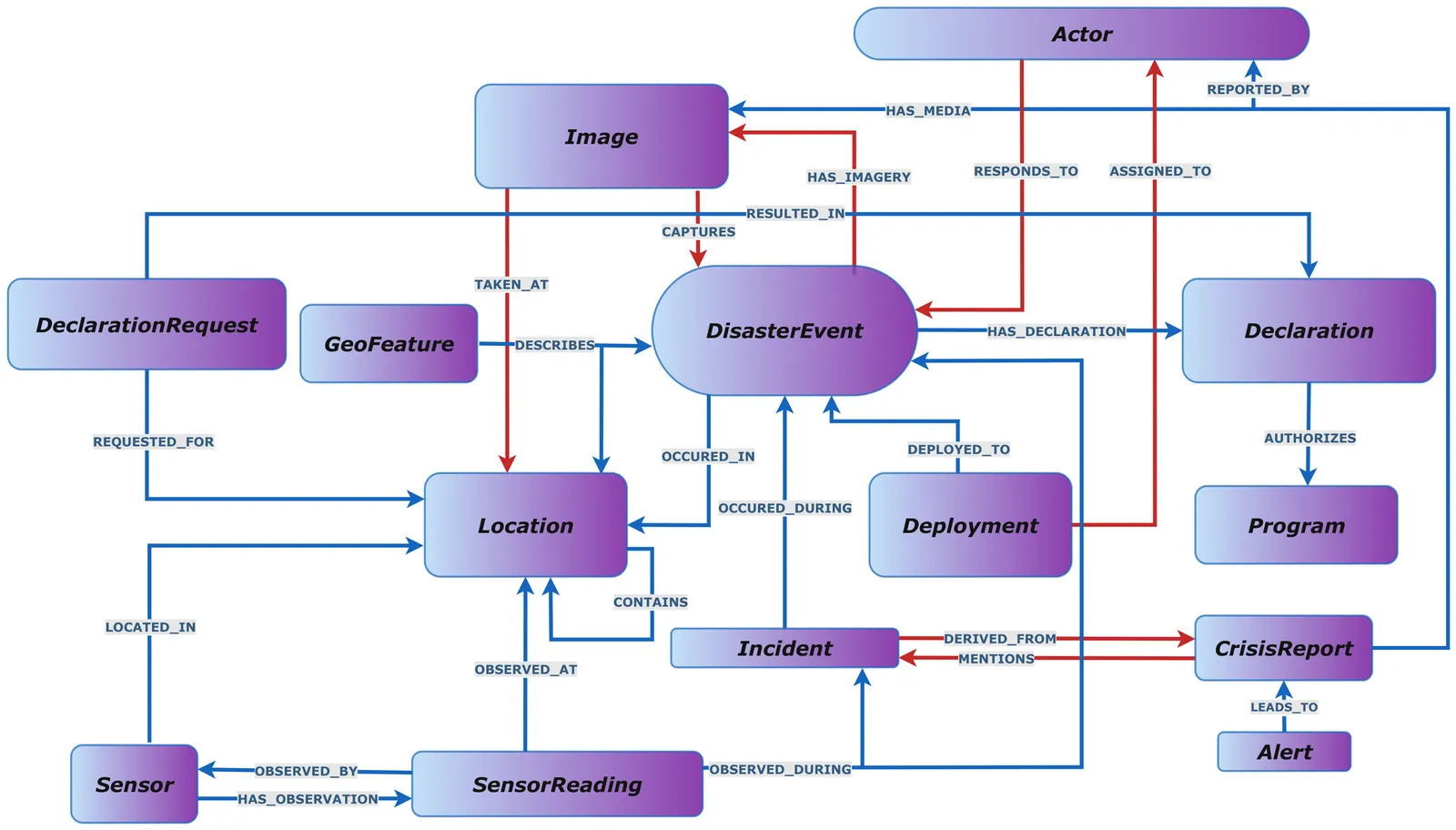
Disaster response requires sharing heterogeneous artifacts, from tabular assistance records to UAS imagery, under overlapping privacy mandates. Operational systems often reduce compliance to binary access control, which is brittle in time-critical workflows. We present a novel deontic knowledge graph-based framework that integrates a Disaster Management Knowledge Graph (DKG) with a Policy Knowledge Graph (PKG) derived from IoT-Reg and FEMA/DHS privacy drivers. Our release decision function supports three outcomes: Allow, Block, and Allow-with-Transform. The latter binds obligations to transforms and verifies post-transform compliance via provenance-linked derived artifacts; blocked requests are logged as semantic privacy incidents. Evaluation on a 5.1M-triple DKG with 316K images shows exact-match decision correctness, sub-second per-decision latency, and interactive query performance across both single-graph and federated workloads.
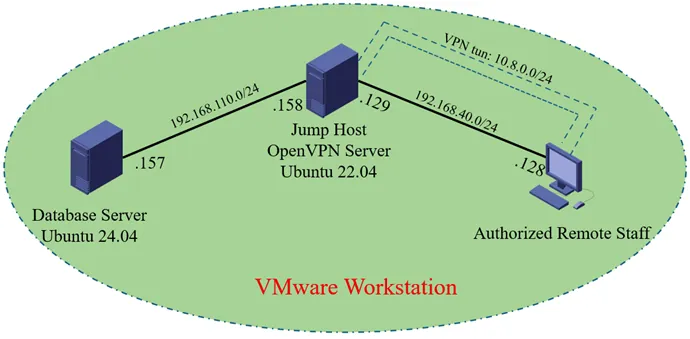
This paper critically examines the 2022 Medibank health insurance data breach, which exposed sensitive medical records of 9.7 million individuals due to unencrypted storage, centralized access, and the absence of privacy-preserving analytics. To address these vulnerabilities, we propose an entropy-aware differential privacy (DP) framework that integrates Laplace and Gaussian mechanisms with adaptive budget allocation. The design incorporates TLS-encrypted database access, field-level mechanism selection, and smooth sensitivity models to mitigate re-identification risks. Experimental validation was conducted using synthetic Medibank datasets (N = 131,000) with entropy-calibrated DP mechanisms, where high-entropy attributes received stronger noise injection. Results demonstrate a 90.3% reduction in re-identification probability while maintaining analytical utility loss below 24%. The framework further aligns with GDPR Article 32 and Australian Privacy Principle 11.1, ensuring regulatory compliance. By combining rigorous privacy guarantees with practical usability, this work contributes a scalable and technically feasible solution for healthcare data protection, offering a pathway toward resilient, trustworthy, and regulation-ready medical analytics.
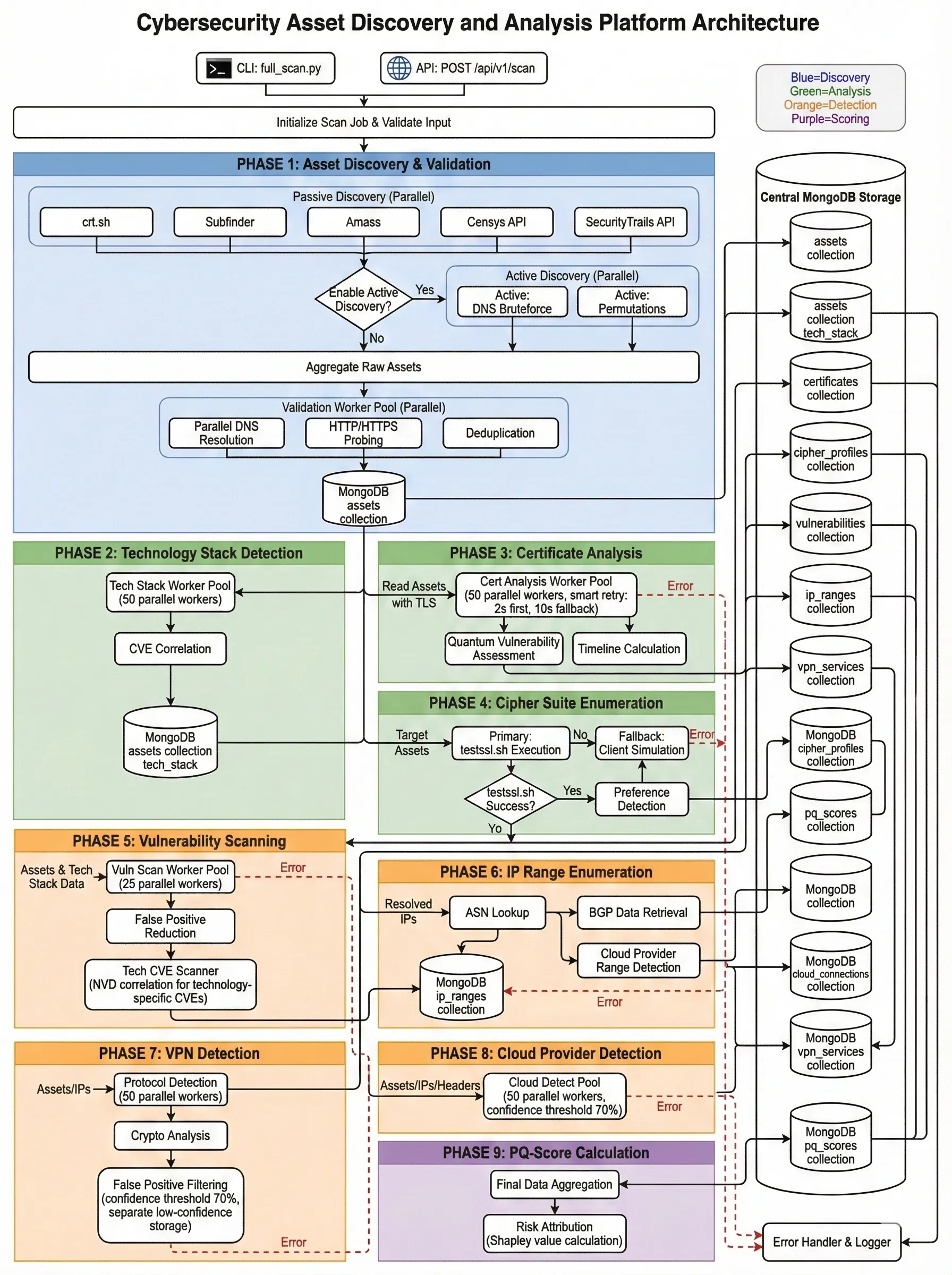
The emergence of large-scale quantum computing threatens widely deployed public-key cryptographic systems, creating an urgent need for enterprise-level methods to assess post-quantum (PQ) readiness. While PQ standards are under development, organizations lack scalable and quantitative frameworks for measuring cryptographic exposure and prioritizing migration across complex infrastructures. This paper presents a knowledge graph based framework that models enterprise cryptographic assets, dependencies, and vulnerabilities to compute a unified PQ readiness score. Infrastructure components, cryptographic primitives, certificates, and services are represented as a heterogeneous graph, enabling explicit modeling of dependency-driven risk propagation. PQ exposure is quantified using graph-theoretic risk functionals and attributed across cryptographic domains via Shapley value decomposition. To support scalability and data quality, the framework integrates large language models with human-in-the-loop validation for asset classification and risk attribution. The resulting approach produces explainable, normalized readiness metrics that support continuous monitoring, comparative analysis, and remediation prioritization.
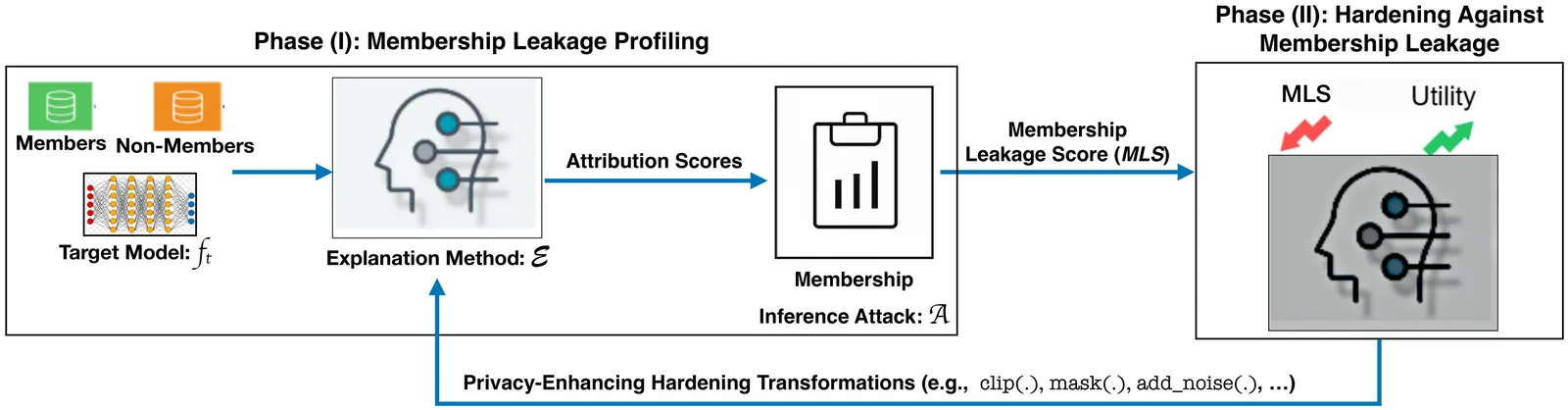
Machine learning (ML) explainability is central to algorithmic transparency in high-stakes settings such as predictive diagnostics and loan approval. However, these same domains require rigorous privacy guaranties, creating tension between interpretability and privacy. Although prior work has shown that explanation methods can leak membership information, practitioners still lack systematic guidance on selecting or deploying explanation techniques that balance transparency with privacy. We present DeepLeak, a system to audit and mitigate privacy risks in post-hoc explanation methods. DeepLeak advances the state-of-the-art in three ways: (1) comprehensive leakage profiling: we develop a stronger explanation-aware membership inference attack (MIA) to quantify how much representative explanation methods leak membership information under default configurations; (2) lightweight hardening strategies: we introduce practical, model-agnostic mitigations, including sensitivity-calibrated noise, attribution clipping, and masking, that substantially reduce membership leakage while preserving explanation utility; and (3) root-cause analysis: through controlled experiments, we pinpoint algorithmic properties (e.g., attribution sparsity and sensitivity) that drive leakage. Evaluating 15 explanation techniques across four families on image benchmarks, DeepLeak shows that default settings can leak up to 74.9% more membership information than previously reported. Our mitigations cut leakage by up to 95% (minimum 46.5%) with only <=3.3% utility loss on average. DeepLeak offers a systematic, reproducible path to safer explainability in privacy-sensitive ML.
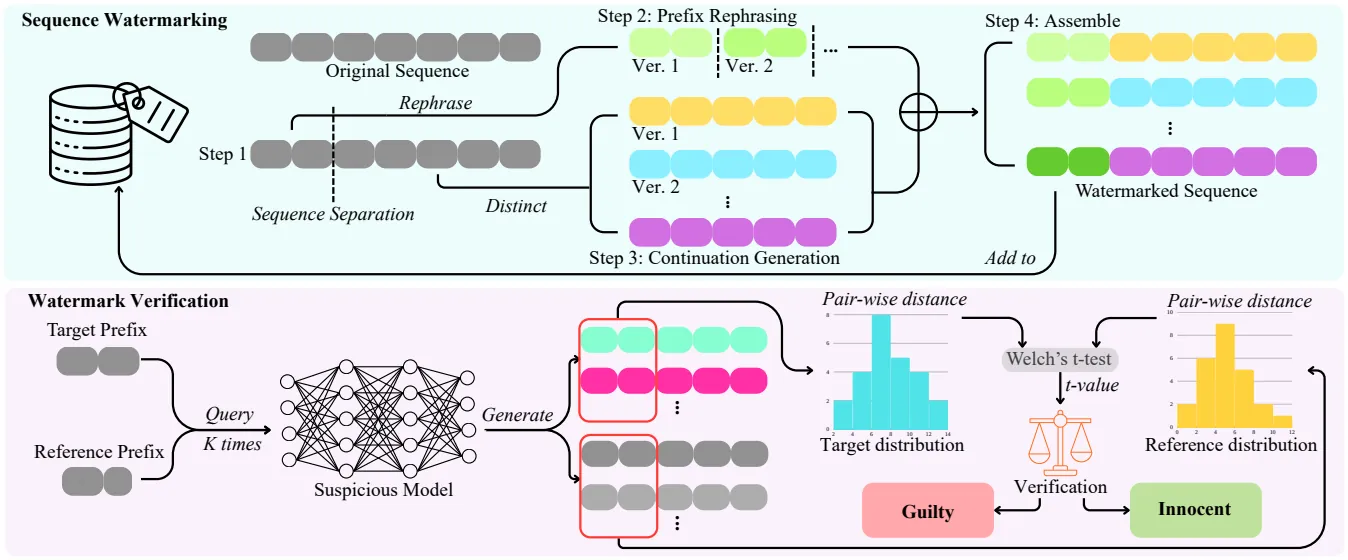
Training data is a critical and often proprietary asset in Large Language Model (LLM) development, motivating the use of data watermarking to embed model-transferable signals for usage verification. We identify low coverage as a vital yet largely overlooked requirement for practicality, as individual data owners typically contribute only a minute fraction of massive training corpora. Prior methods fail to maintain stealthiness, verification feasibility, or robustness when only one or a few sequences can be modified. To address these limitations, we introduce SLIM, a framework enabling per-user data provenance verification under strict black-box access. SLIM leverages intrinsic LLM properties to induce a Latent-Space Confusion Zone by training the model to map semantically similar prefixes to divergent continuations. This manifests as localized generation instability, which can be reliably detected via hypothesis testing. Experiments demonstrate that SLIM achieves ultra-low coverage capability, strong black-box verification performance, and great scalability while preserving both stealthiness and model utility, offering a robust solution for protecting training data in modern LLM pipelines.
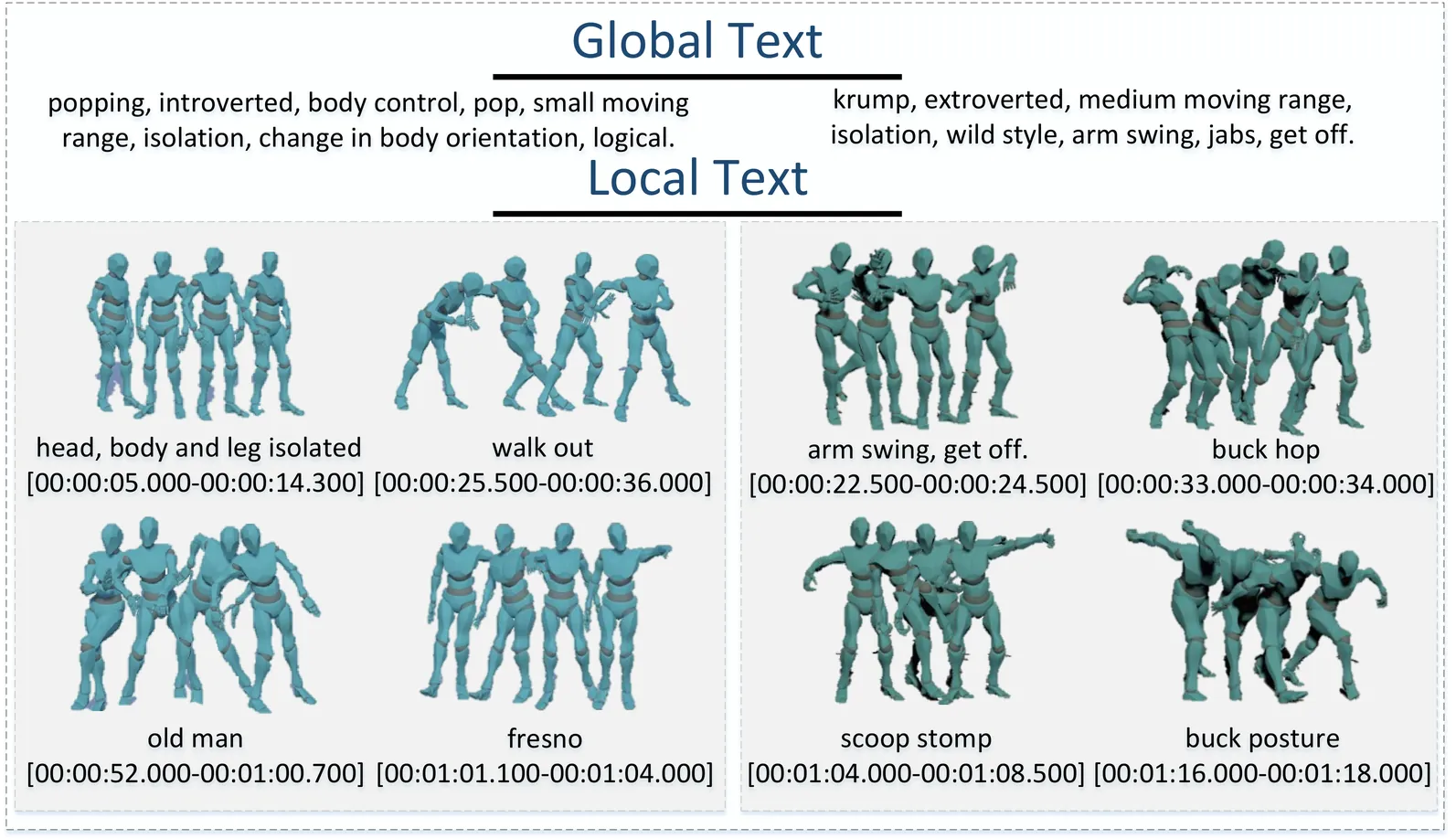
Advances in generative models and sequence learning have greatly promoted research in dance motion generation, yet current methods still suffer from coarse semantic control and poor coherence in long sequences. In this work, we present Listen to Rhythm, Choose Movements (LRCM), a multimodal-guided diffusion framework supporting both diverse input modalities and autoregressive dance motion generation. We explore a feature decoupling paradigm for dance datasets and generalize it to the Motorica Dance dataset, separating motion capture data, audio rhythm, and professionally annotated global and local text descriptions. Our diffusion architecture integrates an audio-latent Conformer and a text-latent Cross-Conformer, and incorporates a Motion Temporal Mamba Module (MTMM) to enable smooth, long-duration autoregressive synthesis. Experimental results indicate that LRCM delivers strong performance in both functional capability and quantitative metrics, demonstrating notable potential in multimodal input scenarios and extended sequence generation. We will release the full codebase, dataset, and pretrained models publicly upon acceptance.
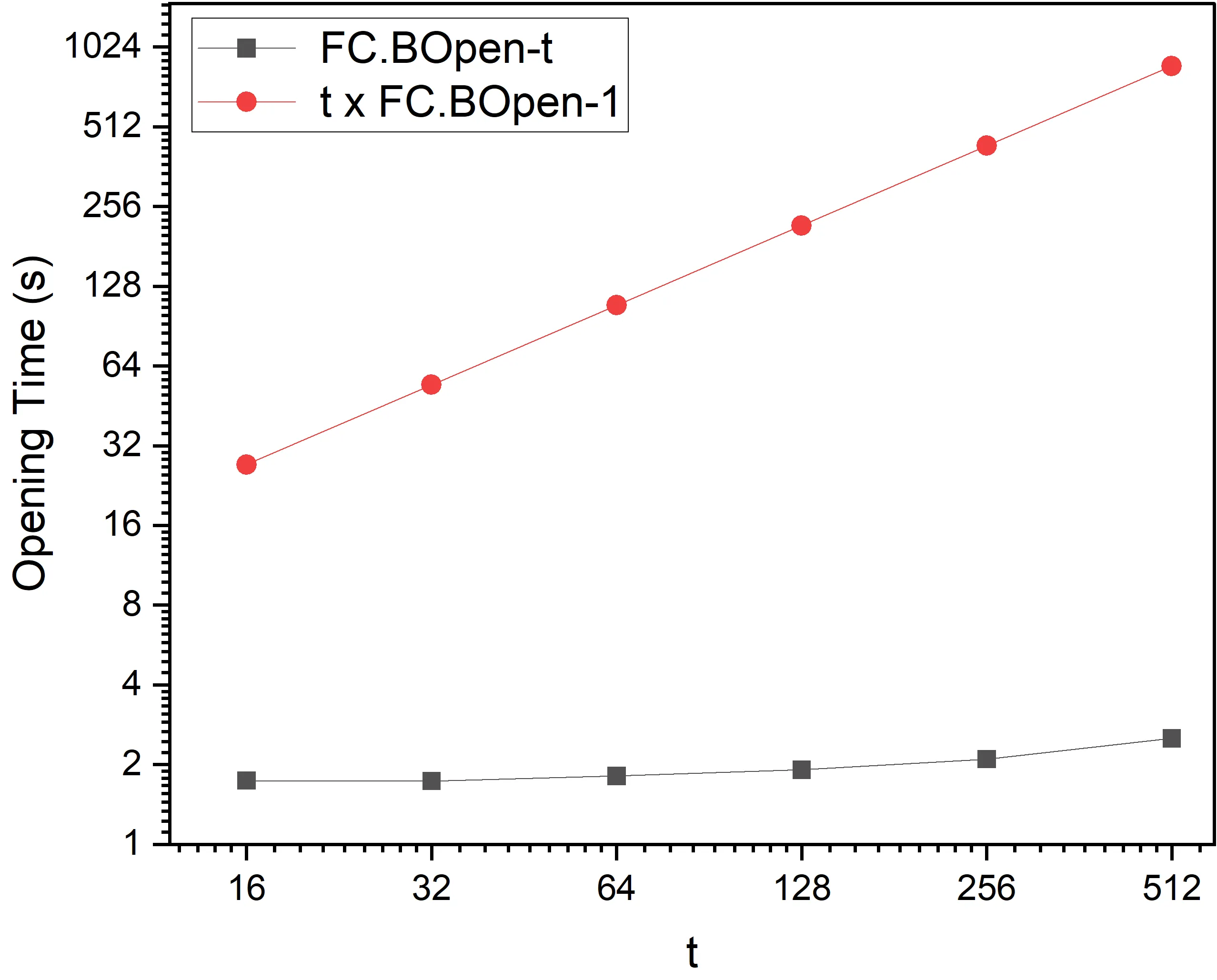
In this paper, we introduce FlexProofs, a new vector commitment (VC) scheme that achieves two key properties: (1) the prover can generate all individual opening proofs for a vector of size $N$ in optimal time ${\cal O}(N)$, and there is a flexible batch size parameter $b$ that can be increased to further reduce the time to generate all proofs; and (2) the scheme is directly compatible with a family of zkSNARKs that encode their input as a multi-linear polynomial. As a critical building block, we propose the first functional commitment (FC) scheme for multi-exponentiations with batch opening. Compared with HydraProofs, the only existing VC scheme that computes all proofs in optimal time ${\cal O}(N)$ and is directly compatible with zkSNARKs, FlexProofs may speed up the process of generating all proofs, if the parameter $b$ is properly chosen. Our experiments show that for $N=2^{16}$ and $b=\log^2 N$, FlexProofs can be $6\times$ faster than HydraProofs. Moreover, when combined with suitable zkSNARKs, FlexProofs enable practical applications such as verifiable secret sharing and verifiable robust aggregation.
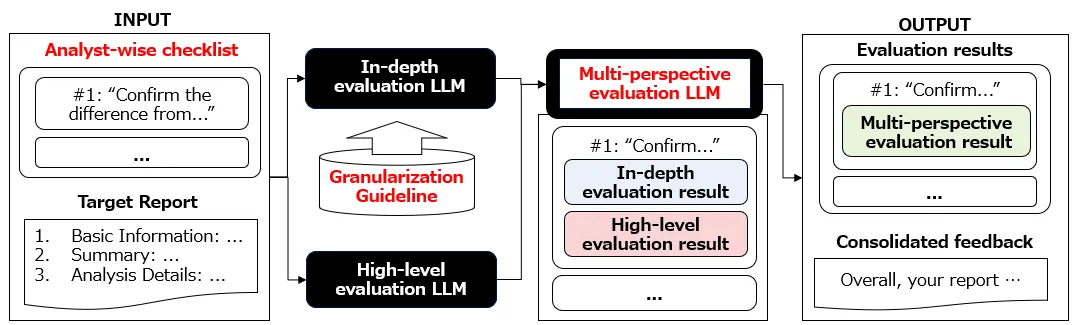
Security operation centers (SOCs) often produce analysis reports on security incidents, and large language models (LLMs) will likely be used for this task in the near future. We postulate that a better understanding of how veteran analysts evaluate reports, including their feedback, can help produce analysis reports in SOCs. In this paper, we aim to leverage LLMs for analysis reports. To this end, we first construct a Analyst-wise checklist to reflect SOC practitioners' opinions for analysis report evaluation through literature review and user study with SOC practitioners. Next, we design a novel LLM-based conceptual framework, named MESSALA, by further introducing two new techniques, granularization guideline and multi-perspective evaluation. MESSALA can maximize report evaluation and provide feedback on veteran SOC practitioners' perceptions. When we conduct extensive experiments with MESSALA, the evaluation results by MESSALA are the closest to those of veteran SOC practitioners compared with the existing LLM-based methods. We then show two key insights. We also conduct qualitative analysis with MESSALA, and then identify that MESSALA can provide actionable items that are necessary for improving analysis reports.
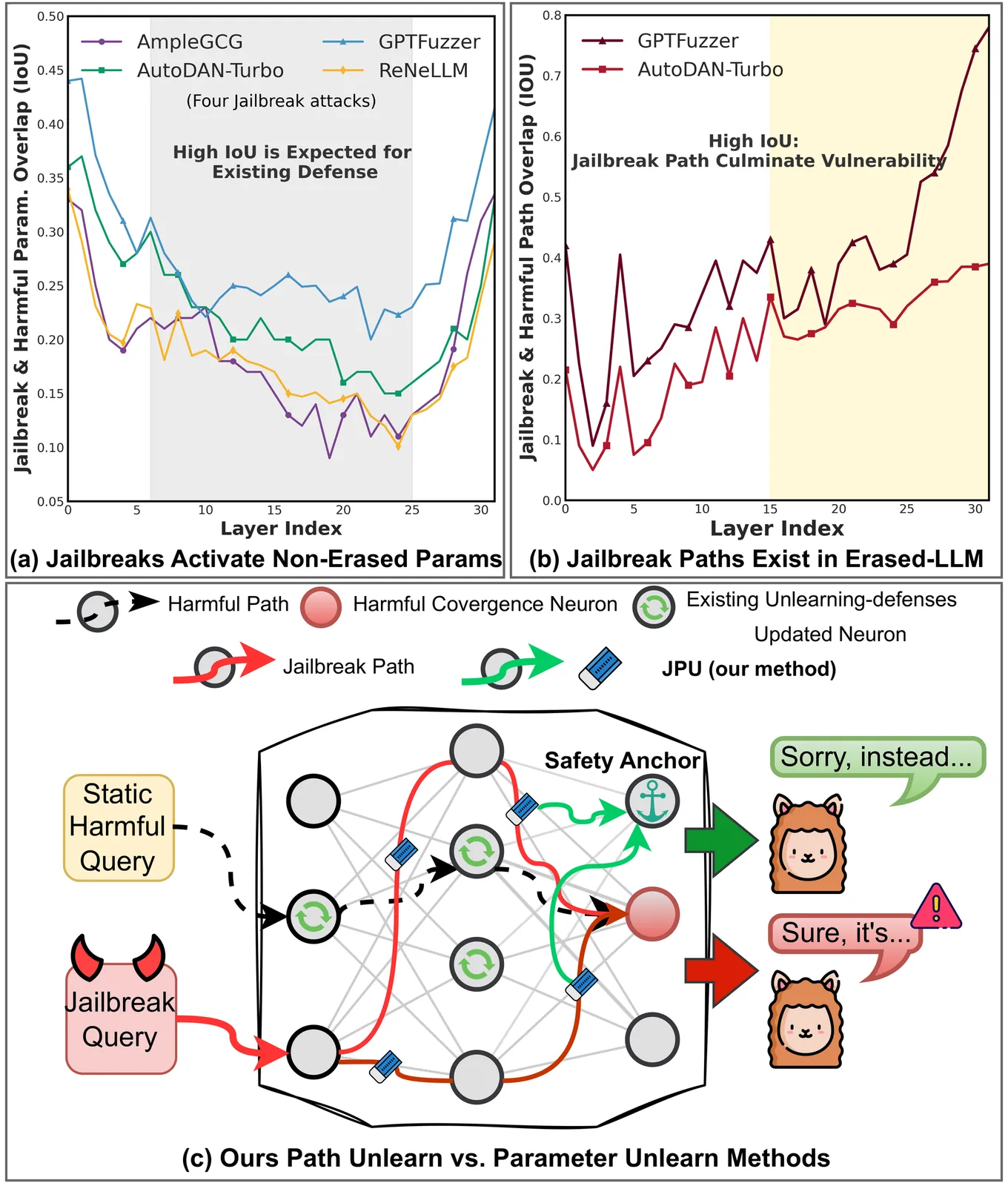
Despite extensive safety alignment, Large Language Models (LLMs) often fail against jailbreak attacks. While machine unlearning has emerged as a promising defense by erasing specific harmful parameters, current methods remain vulnerable to diverse jailbreaks. We first conduct an empirical study and discover that this failure mechanism is caused by jailbreaks primarily activating non-erased parameters in the intermediate layers. Further, by probing the underlying mechanism through which these circumvented parameters reassemble into the prohibited output, we verify the persistent existence of dynamic $\textbf{jailbreak paths}$ and show that the inability to rectify them constitutes the fundamental gap in existing unlearning defenses. To bridge this gap, we propose $\textbf{J}$ailbreak $\textbf{P}$ath $\textbf{U}$nlearning (JPU), which is the first to rectify dynamic jailbreak paths towards safety anchors by dynamically mining on-policy adversarial samples to expose vulnerabilities and identify jailbreak paths. Extensive experiments demonstrate that JPU significantly enhances jailbreak resistance against dynamic attacks while preserving the model's utility.