Trading & Market Microstructure
Algorithmic trading, market structure, and statistical arbitrage
Algorithmic trading, market structure, and statistical arbitrage
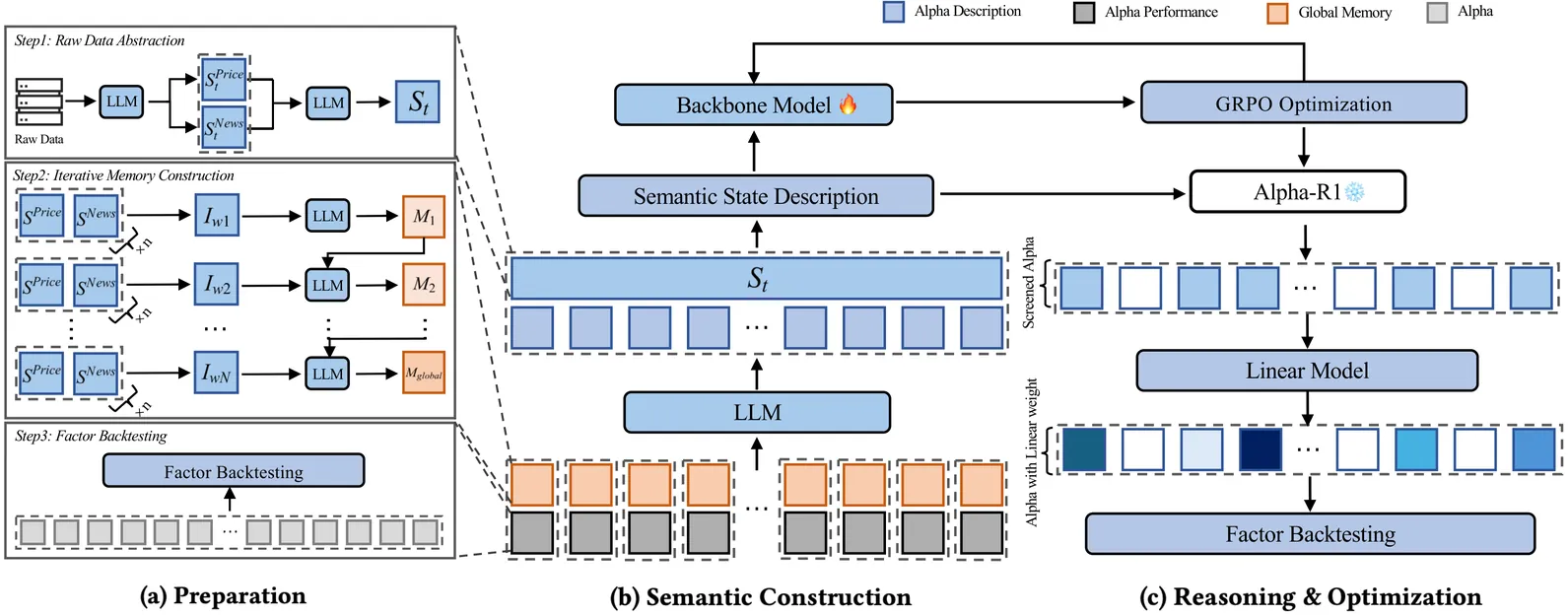
Signal decay and regime shifts pose recurring challenges for data-driven investment strategies in non-stationary markets. Conventional time-series and machine learning approaches, which rely primarily on historical correlations, often struggle to generalize when the economic environment changes. While large language models (LLMs) offer strong capabilities for processing unstructured information, their potential to support quantitative factor screening through explicit economic reasoning remains underexplored. Existing factor-based methods typically reduce alphas to numerical time series, overlooking the semantic rationale that determines when a factor is economically relevant. We propose Alpha-R1, an 8B-parameter reasoning model trained via reinforcement learning for context-aware alpha screening. Alpha-R1 reasons over factor logic and real-time news to evaluate alpha relevance under changing market conditions, selectively activating or deactivating factors based on contextual consistency. Empirical results across multiple asset pools show that Alpha-R1 consistently outperforms benchmark strategies and exhibits improved robustness to alpha decay. The full implementation and resources are available at https://github.com/FinStep-AI/Alpha-R1.
Signal decay and regime shifts pose recurring challenges for data-driven investment strategies in non-stationary markets. Conventional time-series and machine learning approaches, which rely primarily on historical correlations, often struggle to generalize when the economic environment changes. While large language models (LLMs) offer strong capabilities for processing unstructured information, their potential to support quantitative factor screening through explicit economic reasoning remains underexplored. Existing factor-based methods typically reduce alphas to numerical time series, overlooking the semantic rationale that determines when a factor is economically relevant. We propose Alpha-R1, an 8B-parameter reasoning model trained via reinforcement learning for context-aware alpha screening. Alpha-R1 reasons over factor logic and real-time news to evaluate alpha relevance under changing market conditions, selectively activating or deactivating factors based on contextual consistency. Empirical results across multiple asset pools show that Alpha-R1 consistently outperforms benchmark strategies and exhibits improved robustness to alpha decay. The full implementation and resources are available at https://github.com/FinStep-AI/Alpha-R1.

Synthetic financial data offers a practical way to address the privacy and accessibility challenges that limit research in quantitative finance. This paper examines the use of generative models, in particular TimeGAN and Variational Autoencoders (VAEs), for creating synthetic return series that support portfolio construction, trading analysis, and risk modeling. Using historical daily returns from the S and P 500 as a benchmark, we generate synthetic datasets under comparable market conditions and evaluate them using statistical similarity metrics, temporal structure tests, and downstream financial tasks. The study shows that TimeGAN produces synthetic data with distributional shapes, volatility patterns, and autocorrelation behaviour that are close to those observed in real returns. When applied to mean-variance portfolio optimization, the resulting synthetic datasets lead to portfolio weights, Sharpe ratios, and risk levels that remain close to those obtained from real data. The VAE provides more stable training but tends to smooth extreme market movements, which affects risk estimation. Finally, the analysis supports the use of synthetic datasets as substitutes for real financial data in portfolio analysis and risk simulation, particularly when models are able to capture temporal dynamics. Synthetic data therefore provides a privacy-preserving, cost-effective, and reproducible tool for financial experimentation and model development.
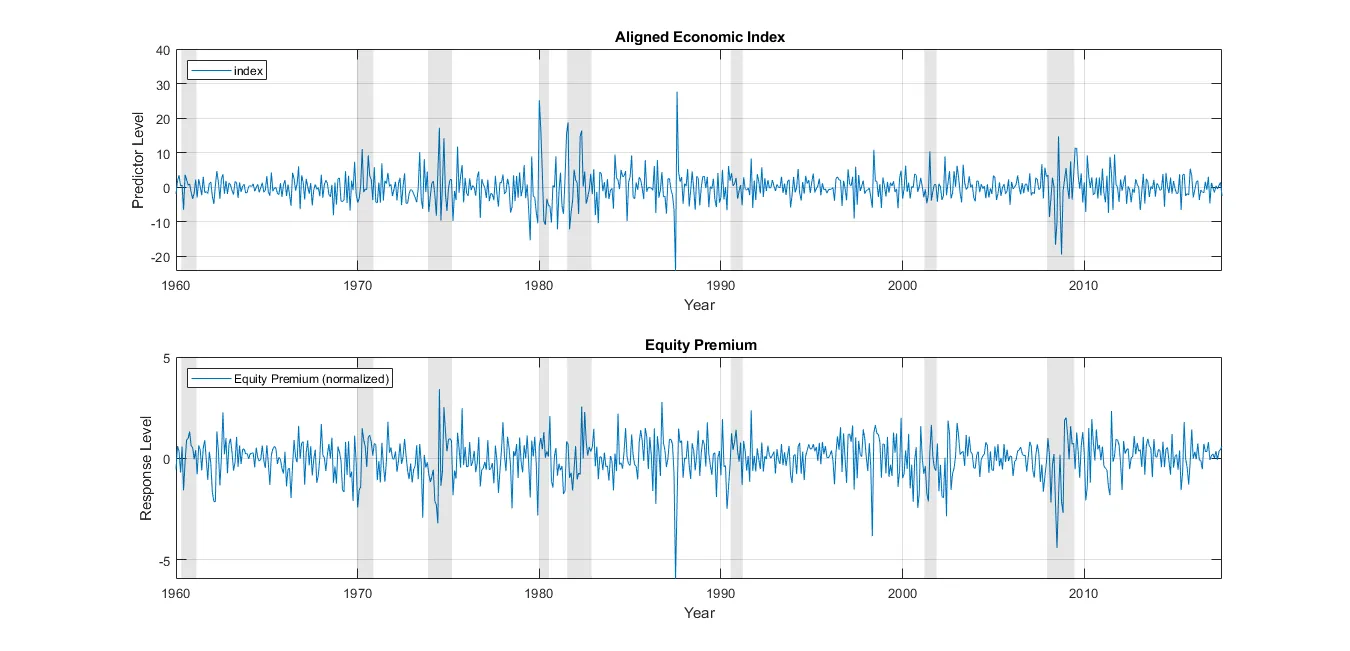
A growing empirical literature suggests that equity-premium predictability is state dependent, with much of the forecasting power concentrated around recessionary periods \parencite{Henkel2011,DanglHalling2012,Devpura2018}. I study U.S. stock return predictability across economic regimes and document strong evidence of time-varying expected returns across both expansionary and contractionary states. I contribute in two ways. First, I introduce a state-switching predictive regression in which the market state is defined in real time using the slope of the yield curve. Relative to the standard one-state predictive regression, the state-switching specification increases both in-sample and out-of-sample performance for the set of popular predictors considered by \textcite{WelchGoyal2008}, improving the out-of-sample performance of most predictors in economically meaningful ways. Second, I propose a new aggregate predictor, the Aligned Economic Index, constructed via partial least squares (PLS). Under the state-switching model, the Aligned Economic Index exhibits statistically and economically significant predictive power in sample and out of sample, and it outperforms widely used benchmark predictors and alternative predictor-combination methods.
We use a $φ^{4}$ quantum field theory with inhomogeneous couplings and explicit symmetry-breaking to model an ensemble of financial time series from the S$\&$P 500 index. The continuum nature of the $φ^4$ theory avoids the inaccuracies that occur in Ising-based models which require a discretization of the time series. We demonstrate this using the example of the 2008 global financial crisis. The $φ^{4}$ quantum field theory is expressive enough to reproduce the higher-order statistics such as the market kurtosis, which can serve as an indicator of possible market shocks. Accurate reproduction of high kurtosis is absent in binarized models. Therefore Ising models, despite being widely employed in econophysics, are incapable of fully representing empirical financial data, a limitation not present in the generalization of the $φ^{4}$ scalar field theory. We then investigate the scaling properties of the $φ^{4}$ machine learning algorithm and extract exponents which govern the behavior of the learned couplings (or weights and biases in ML language) in relation to the number of stocks in the model. Finally, we use our model to forecast the price changes of the AAPL, MSFT, and NVDA stocks. We conclude by discussing how the $φ^{4}$ scalar field theory could be used to build investment strategies and the possible intuitions that the QFT operations of dimensional compactification and renormalization can provide for financial modelling.

Accurate volatility forecasting is essential in banking, investment, and risk management, because expectations about future market movements directly influence current decisions. This study proposes a hybrid modelling framework that integrates a Stochastic Volatility model with a Long Short Term Memory neural network. The SV model improves statistical precision and captures latent volatility dynamics, especially in response to unforeseen events, while the LSTM network enhances the model's ability to detect complex nonlinear patterns in financial time series. The forecasting is conducted using daily data from the S and P 500 index, covering the period from January 1 1998 to December 31 2024. A rolling window approach is employed to train the model and generate one step ahead volatility forecasts. The performance of the hybrid SV-LSTM model is evaluated through both statistical testing and investment simulations. The results show that the hybrid approach outperforms both the standalone SV and LSTM models and contributes to the development of volatility modelling techniques, providing a foundation for improving risk assessment and strategic investment planning in the context of the S and P 500.
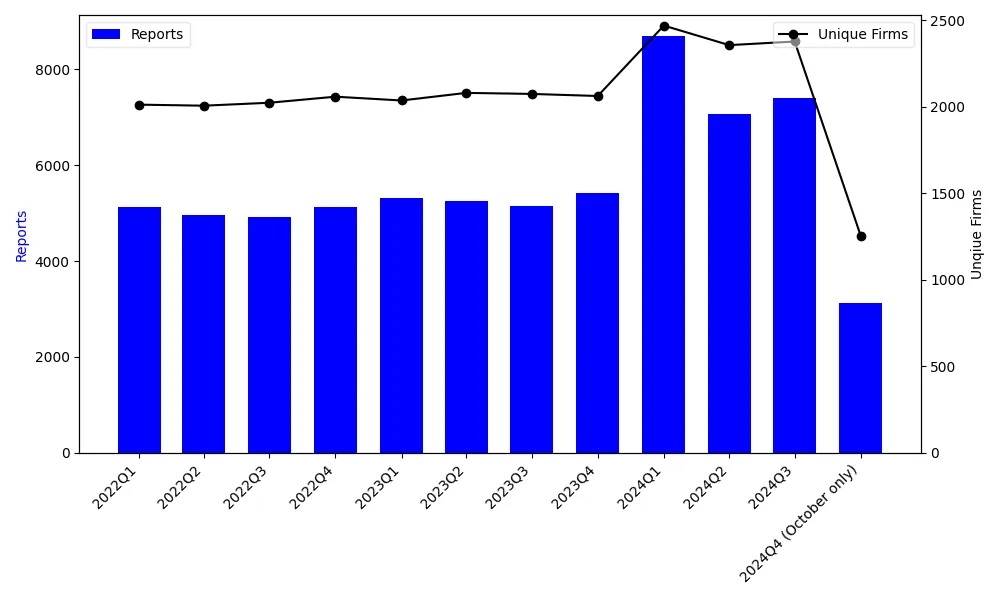
We study how generative artificial intelligence (AI) transforms the work of financial analysts. Using the 2023 launch of FactSet's AI platform as a natural experiment, we find that adoption produces markedly richer and more comprehensive reports -- featuring 40% more distinct information sources, 34% broader topical coverage, and 25% greater use of advanced analytical methods -- while also improving timeliness. However, forecast errors rise by 59% as AI-assisted reports convey a more balanced mix of positive and negative information that is harder to synthesize, particularly for analysts facing heavier cognitive demands. Placebo tests using other data vendors confirm that these effects are unique to FactSet's AI integration. Overall, our findings reveal both the productivity gains and cognitive limits of generative AI in financial information production.
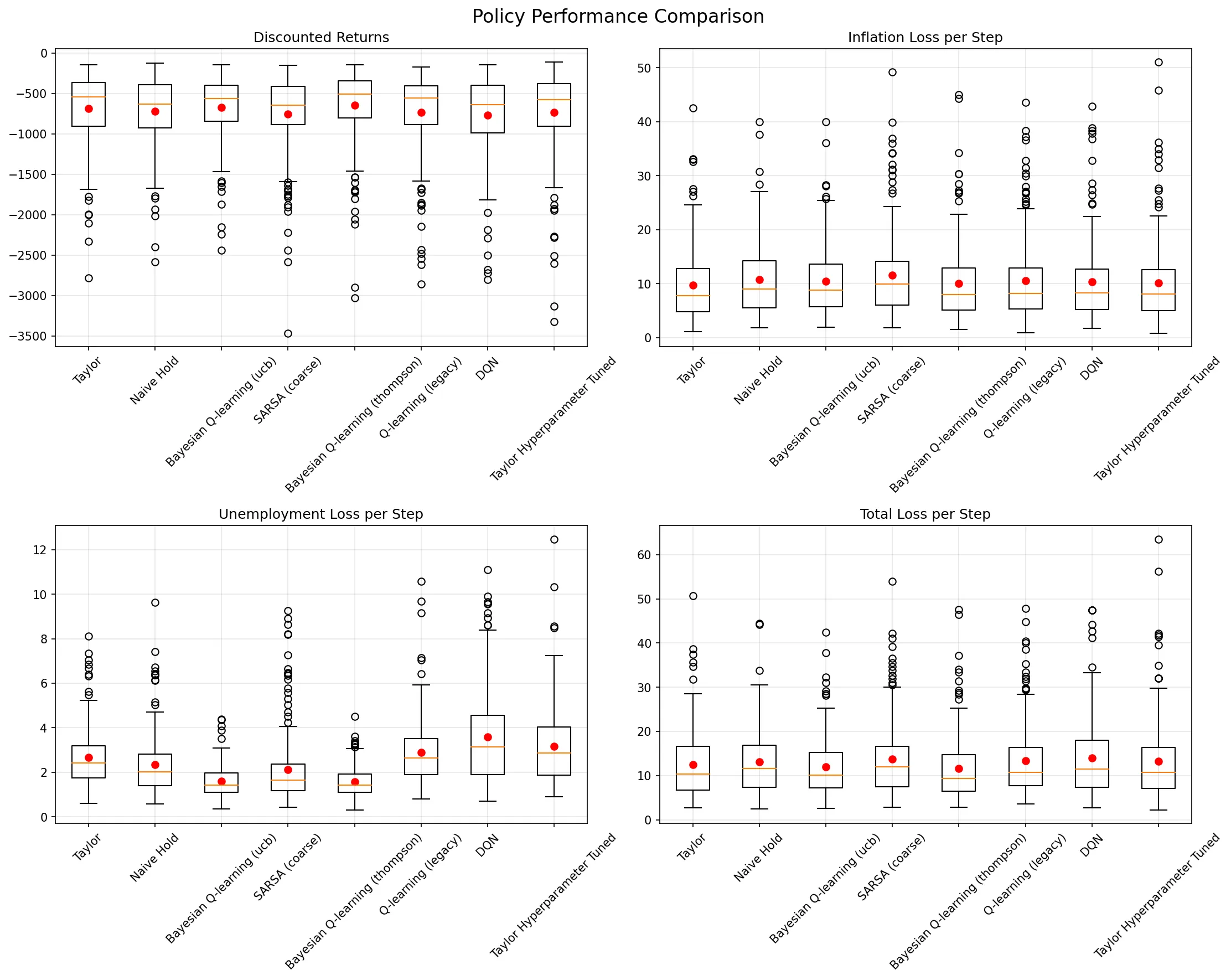
We study how a central bank should dynamically set short-term nominal interest rates to stabilize inflation and unemployment when macroeconomic relationships are uncertain and time-varying. We model monetary policy as a sequential decision-making problem where the central bank observes macroeconomic conditions quarterly and chooses interest rate adjustments. Using publically accessible historical Federal Reserve Economic Data (FRED), we construct a linear-Gaussian transition model and implement a discrete-action Markov Decision Process with a quadratic loss reward function. We chose to compare nine different reinforcement learning style approaches against Taylor Rule and naive baselines, including tabular Q-learning variants, SARSA, Actor-Critic, Deep Q-Networks, Bayesian Q-learning with uncertainty quantification, and POMDP formulations with partial observability. Surprisingly, standard tabular Q-learning achieved the best performance (-615.13 +- 309.58 mean return), outperforming both enhanced RL methods and traditional policy rules. Our results suggest that while sophisticated RL techniques show promise for monetary policy applications, simpler approaches may be more robust in this domain, highlighting important challenges in applying modern RL to macroeconomic policy.
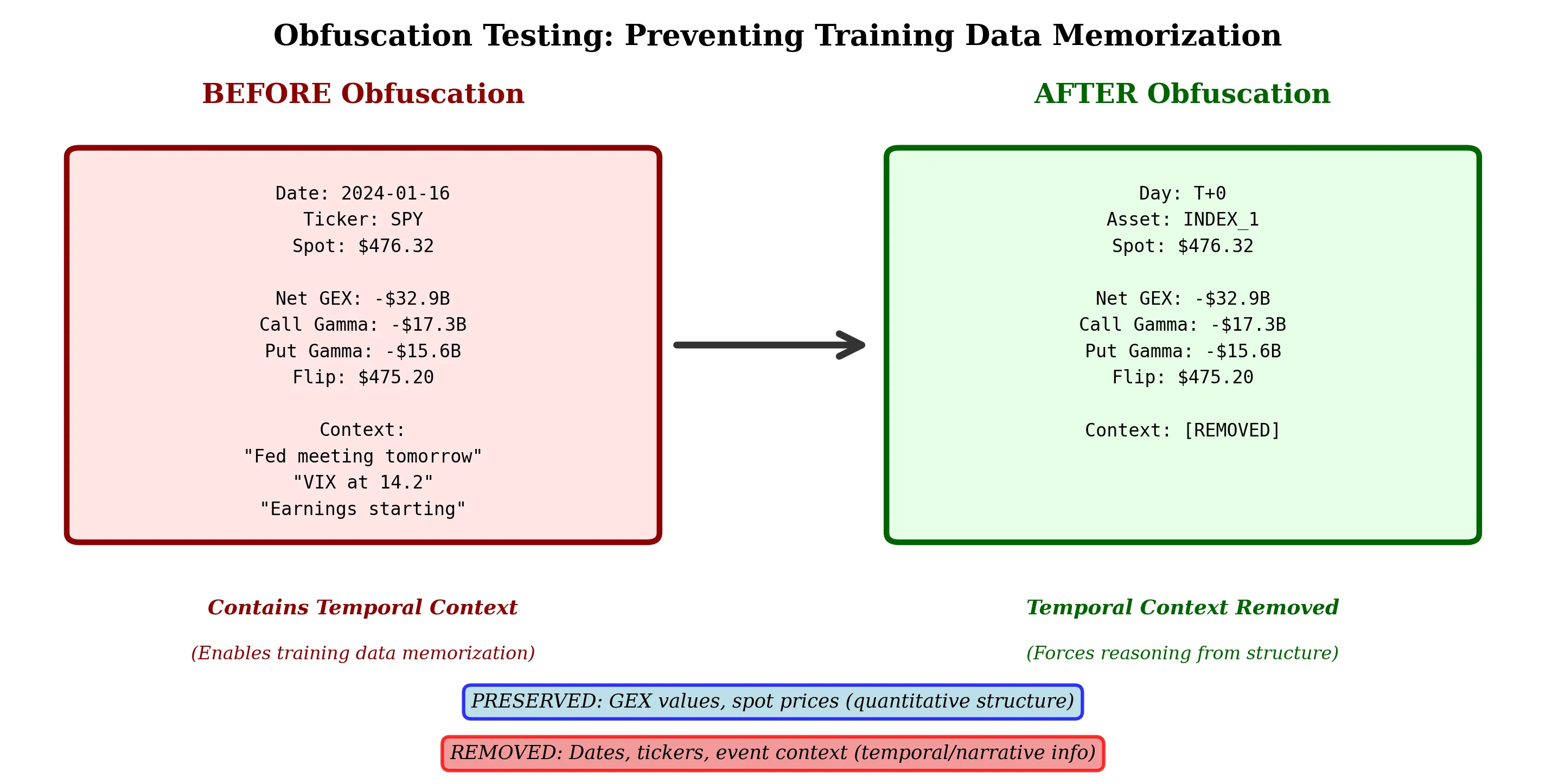
We introduce obfuscation testing, a novel methodology for validating whether large language models detect structural market patterns through causal reasoning rather than temporal association. Testing three dealer hedging constraint patterns (gamma positioning, stock pinning, 0DTE hedging) on 242 trading days (95.6% coverage) of S&P 500 options data, we find LLMs achieve 71.5% detection rate using unbiased prompts that provide only raw gamma exposure values without regime labels or temporal context. The WHO-WHOM-WHAT causal framework forces models to identify the economic actors (dealers), affected parties (directional traders), and structural mechanisms (forced hedging) underlying observed market dynamics. Critically, detection accuracy (91.2%) remains stable even as economic profitability varies quarterly, demonstrating that models identify structural constraints rather than profitable patterns. When prompted with regime labels, detection increases to 100%, but the 71.5% unbiased rate validates genuine pattern recognition. Our findings suggest LLMs possess emergent capabilities for detecting complex financial mechanisms through pure structural reasoning, with implications for systematic strategy development, risk management, and our understanding of how transformer architectures process financial market dynamics.
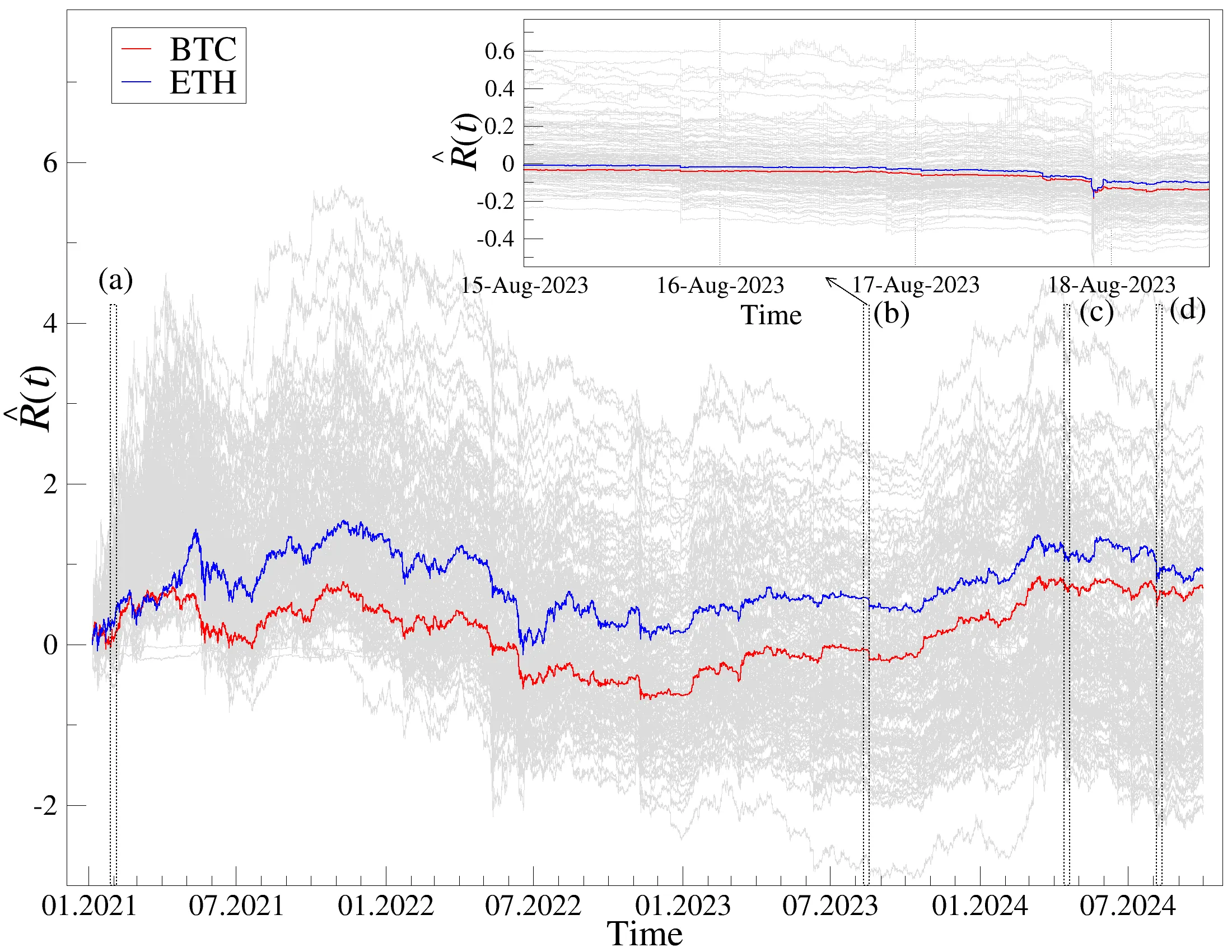
Correlations in complex systems are often obscured by nonstationarity, long-range memory, and heavy-tailed fluctuations, which limit the usefulness of traditional covariance-based analyses. To address these challenges, we construct scale and fluctuation-dependent correlation matrices using the multifractal detrended cross-correlation coefficient $ρ_r$ that selectively emphasizes fluctuations of different amplitudes. We examine the spectral properties of these detrended correlation matrices and compare them to the spectral properties of the matrices calculated in the same way from synthetic Gaussian and $q$Gaussian signals. Our results show that detrending, heavy tails, and the fluctuation-order parameter $r$ jointly produce spectra, which substantially depart from the random case even under absence of cross-correlations in time series. Applying this framework to one-minute returns of 140 major cryptocurrencies from 2021-2024 reveals robust collective modes, including a dominant market factor and several sectoral components whose strength depends on the analyzed scale and fluctuation order. After filtering out the market mode, the empirical eigenvalue bulk aligns closely with the limit of random detrended cross-correlations, enabling clear identification of structurally significant outliers. Overall, the study provides a refined spectral baseline for detrended cross-correlations and offers a promising tool for distinguishing genuine interdependencies from noise in complex, nonstationary, heavy-tailed systems.
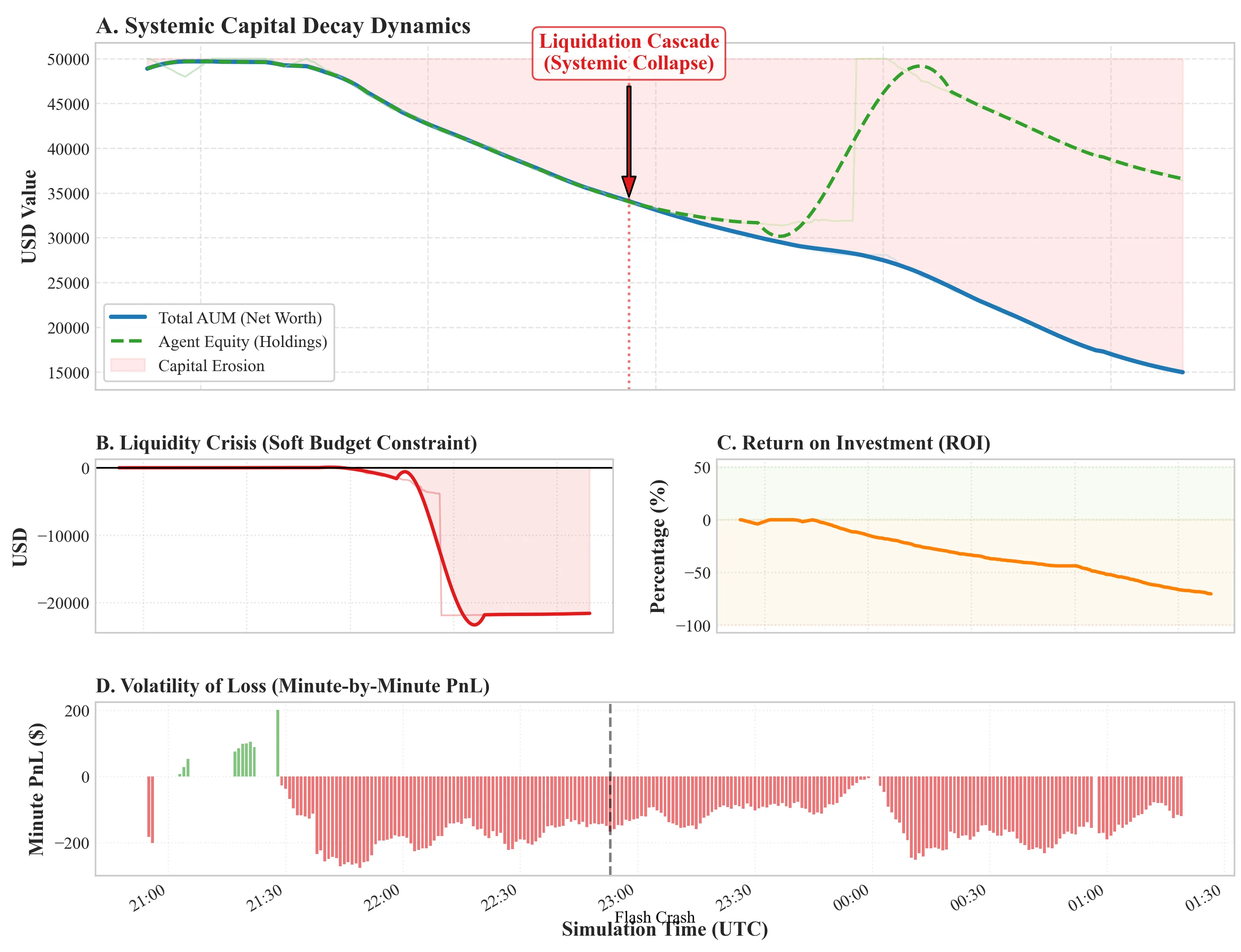
The integration of Deep Reinforcement Learning (DRL) and Evolutionary Computation (EC) is frequently hypothesized to be the "Holy Grail" of algorithmic trading, promising systems that adapt autonomously to non-stationary market regimes. This paper presents a rigorous post-mortem analysis of "Galaxy Empire," a hybrid framework coupling LSTM/Transformer-based perception with a genetic "Time-is-Life" survival mechanism. Deploying a population of 500 autonomous agents in a high-frequency cryptocurrency environment, we observed a catastrophic divergence between training metrics (Validation APY $>300\%$) and live performance (Capital Decay $>70\%$). We deconstruct this failure through a multi-disciplinary lens, identifying three critical failure modes: the overfitting of \textit{Aleatoric Uncertainty} in low-entropy time-series, the \textit{Survivor Bias} inherent in evolutionary selection under high variance, and the mathematical impossibility of overcoming microstructure friction without order-flow data. Our findings provide empirical evidence that increasing model complexity in the absence of information asymmetry exacerbates systemic fragility.

This paper investigates an optimal integration of deep learning with financial models for robust asset price forecasting. Specifically, we developed a hybrid framework combining a Long Short-Term Memory (LSTM) network with the Merton-Lévy jump-diffusion model. To optimise this framework, we employed the Grey Wolf Optimizer (GWO) for the LSTM hyperparameter tuning, and we explored three calibration methods for the Merton-Levy model parameters: Artificial Neural Networks (ANNs), the Marine Predators Algorithm (MPA), and the PyTorch-based TorchSDE library. To evaluate the predictive performance of our hybrid model, we compared it against several benchmark models, including a standard LSTM and an LSTM combined with the Fractional Heston model. This evaluation used three real-world financial datasets: Brent oil prices, the STOXX 600 index, and the IT40 index. Performance was assessed using standard metrics, including Mean Squared Error (MSE), Mean Absolute Error(MAE), Mean Squared Percentage Error (MSPE), and the coefficient of determination (R2). Our experimental results demonstrate that the hybrid model, combining a GWO-optimized LSTM network with the Levy-Merton Jump-Diffusion model calibrated using an ANN, outperformed the base LSTM model and all other models developed in this study.
Conventional models of matching markets assume that monetary transfers can clear markets by compensating for utility differentials. However, empirical patterns show that such transfers often fail to close structural preference gaps. This paper introduces a market microstructure framework that models matching decisions as a limit order book system with rigid bid ask spreads. Individual preferences are represented by a latent preference state matrix, where the spread between an agent's internal ask price (the unconditional maximum) and the market's best bid (the reachable maximum) creates a structural liquidity constraint. We establish a Threshold Impossibility Theorem showing that linear compensation cannot close these spreads unless it induces a categorical identity shift. A dynamic discrete choice execution model further demonstrates that matches occur only when the market to book ratio crosses a time decaying liquidity threshold, analogous to order execution under inventory pressure. Numerical experiments validate persistent slippage, regional invariance of preference orderings, and high tier zero spread executions. The model provides a unified microstructure explanation for matching failures, compensation inefficiency, and post match regret in illiquid order driven environments.

Forecasting cryptocurrency prices is hindered by extreme volatility and a methodological dilemma between information-scarce univariate models and noise-prone full-multivariate models. This paper investigates a partial-multivariate approach to balance this trade-off, hypothesizing that a strategic subset of features offers superior predictive power. We apply the Partial-Multivariate Transformer (PMformer) to forecast daily returns for BTCUSDT and ETHUSDT, benchmarking it against eleven classical and deep learning models. Our empirical results yield two primary contributions. First, we demonstrate that the partial-multivariate strategy achieves significant statistical accuracy, effectively balancing informative signals with noise. Second, we experiment and discuss an observable disconnect between this statistical performance and practical trading utility; lower prediction error did not consistently translate to higher financial returns in simulations. This finding challenges the reliance on traditional error metrics and highlights the need to develop evaluation criteria more aligned with real-world financial objectives.
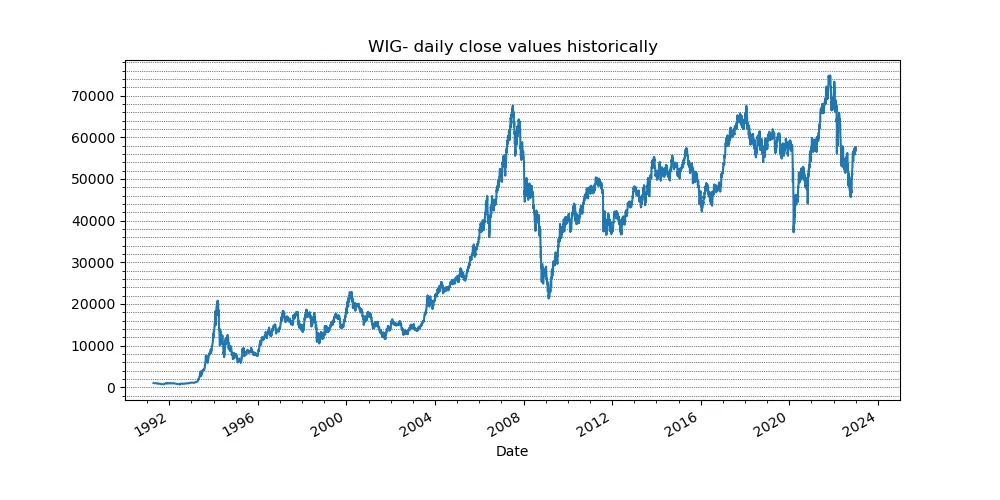
We study a systematic approach to a popular Statistical Arbitrage technique: Pairs Trading. Instead of relying on two highly correlated assets, we replace the second asset with a replication of the first using risk factor representations. These factors are obtained through Principal Components Analysis (PCA), exchange traded funds (ETFs), and, as our main contribution, Long Short Term Memory networks (LSTMs). Residuals between the main asset and its replication are examined for mean reversion properties, and trading signals are generated for sufficiently fast mean reverting portfolios. Beyond introducing a deep learning based replication method, we adapt the framework of Avellaneda and Lee (2008) to the Polish market. Accordingly, components of WIG20, mWIG40, and selected sector indices replace the original S&P500 universe, and market parameters such as the risk free rate and transaction costs are updated to reflect local conditions. We outline the full strategy pipeline: risk factor construction, residual modeling via the Ornstein Uhlenbeck process, and signal generation. Each replication technique is described together with its practical implementation. Strategy performance is evaluated over two periods: 2017-2019 and the recessive year 2020. All methods yield profits in 2017-2019, with PCA achieving roughly 20 percent cumulative return and an annualized Sharpe ratio of up to 2.63. Despite multiple adaptations, our conclusions remain consistent with those of the original paper. During the COVID-19 recession, only the ETF based approach remains profitable (about 5 percent annual return), while PCA and LSTM methods underperform. LSTM results, although negative, are promising and indicate potential for future optimization.
We investigate the use of Reinforcement Learning for the optimal execution of meta-orders, where the objective is to execute incrementally large orders while minimizing implementation shortfall and market impact over an extended period of time. Departing from traditional parametric approaches to price dynamics and impact modeling, we adopt a model-free, data-driven framework. Since policy optimization requires counterfactual feedback that historical data cannot provide, we employ the Queue-Reactive Model to generate realistic and tractable limit order book simulations that encompass transient price impact, and nonlinear and dynamic order flow responses. Methodologically, we train a Double Deep Q-Network agent on a state space comprising time, inventory, price, and depth variables, and evaluate its performance against established benchmarks. Numerical simulation results show that the agent learns a policy that is both strategic and tactical, adapting effectively to order book conditions and outperforming standard approaches across multiple training configurations. These findings provide strong evidence that model-free Reinforcement Learning can yield adaptive and robust solutions to the optimal execution problem.
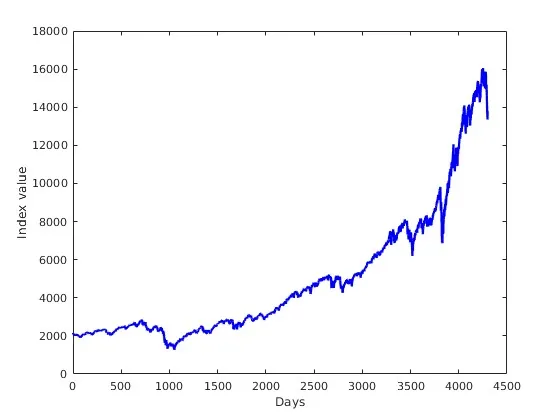
We investigate a number of Artificial Neural Network architectures (well-known and more ``exotic'') in application to the long-term financial time-series forecasts of indexes on different global markets. The particular area of interest of this research is to examine the correlation of these indexes' behaviour in terms of Machine Learning algorithms cross-training. Would training an algorithm on an index from one global market produce similar or even better accuracy when such a model is applied for predicting another index from a different market? The demonstrated predominately positive answer to this question is another argument in favour of the long-debated Efficient Market Hypothesis of Eugene Fama.
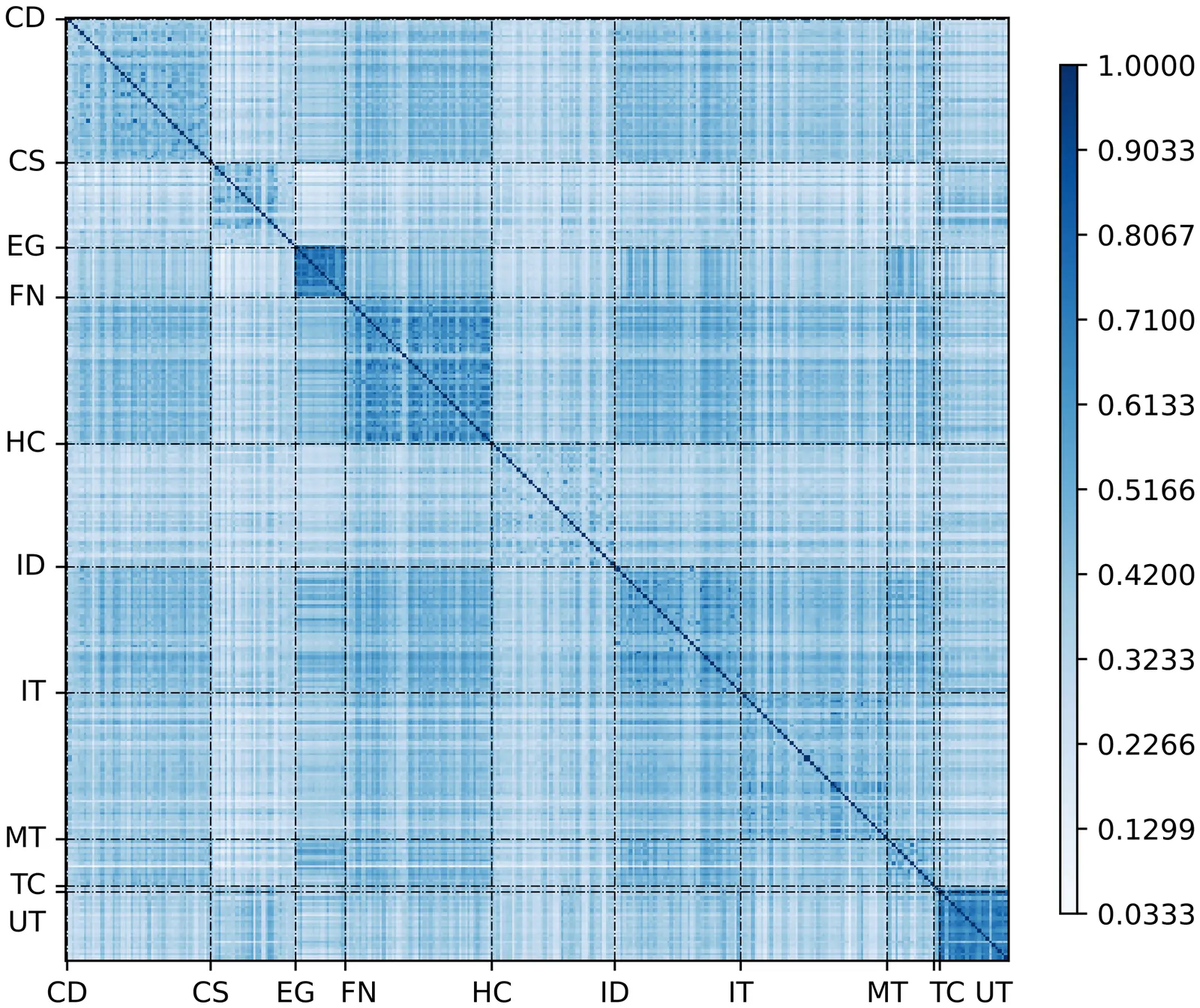
Starting from the Pearson Correlation Matrix of stock returns and from the desire to obtain a reduced number of parameters relevant for the dynamics of a financial market, we propose to take the idea of a sectorial matrix, which would have a large number of parameters, to the reduced picture of a real symmetric $2 \times 2$ matrix, extreme case, that still conserves the desirable feature that the average correlation can be one of the parameters. This is achieved by averaging the correlation matrix over blocks created by choosing two subsets of stocks for rows and columns and averaging over each of the resulting blocks. Averaging over these blocks, we retain the average of the correlation matrix. We shall use a random selection for two equal block sizes as well as two specific, hopefully relevant, ones that do not produce equal block sizes. The results show that one of the non-random choices has somewhat different properties, whose meaning will have to be analyzed from an economy point of view.
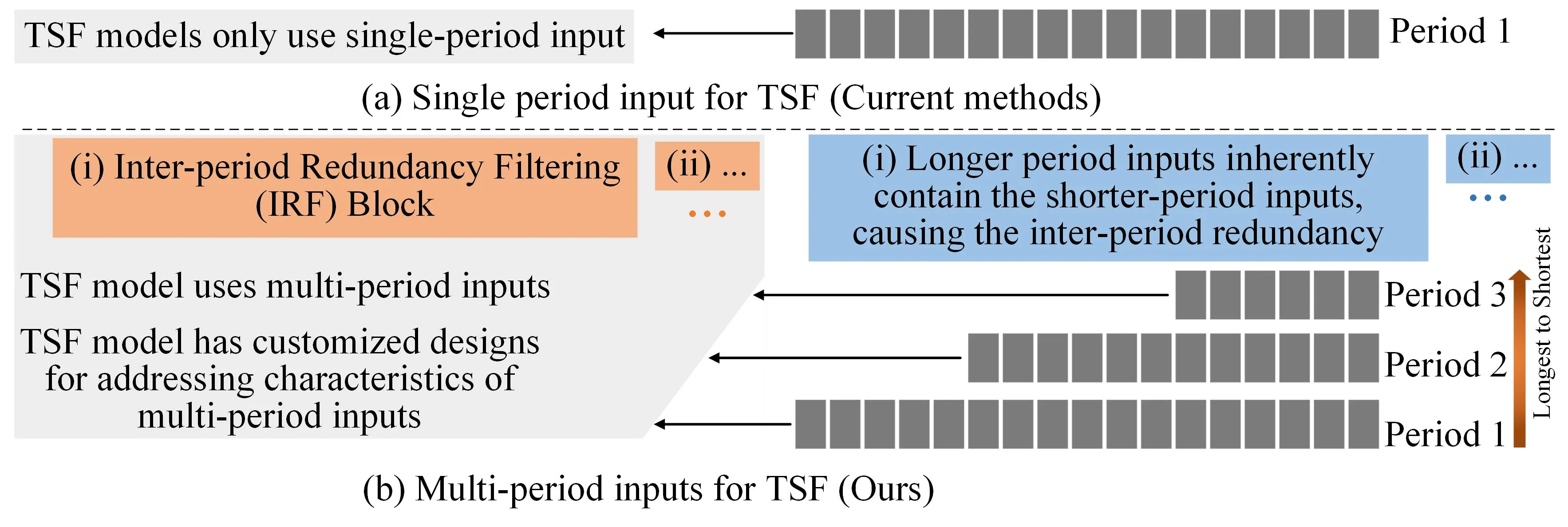
Time series forecasting is important in finance domain. Financial time series (TS) patterns are influenced by both short-term public opinions and medium-/long-term policy and market trends. Hence, processing multi-period inputs becomes crucial for accurate financial time series forecasting (TSF). However, current TSF models either use only single-period input, or lack customized designs for addressing multi-period characteristics. In this paper, we propose a Multi-period Learning Framework (MLF) to enhance financial TSF performance. MLF considers both TSF's accuracy and efficiency requirements. Specifically, we design three new modules to better integrate the multi-period inputs for improving accuracy: (i) Inter-period Redundancy Filtering (IRF), that removes the information redundancy between periods for accurate self-attention modeling, (ii) Learnable Weighted-average Integration (LWI), that effectively integrates multi-period forecasts, (iii) Multi-period self-Adaptive Patching (MAP), that mitigates the bias towards certain periods by setting the same number of patches across all periods. Furthermore, we propose a Patch Squeeze module to reduce the number of patches in self-attention modeling for maximized efficiency. MLF incorporates multiple inputs with varying lengths (periods) to achieve better accuracy and reduces the costs of selecting input lengths during training. The codes and datasets are available at https://github.com/Meteor-Stars/MLF.
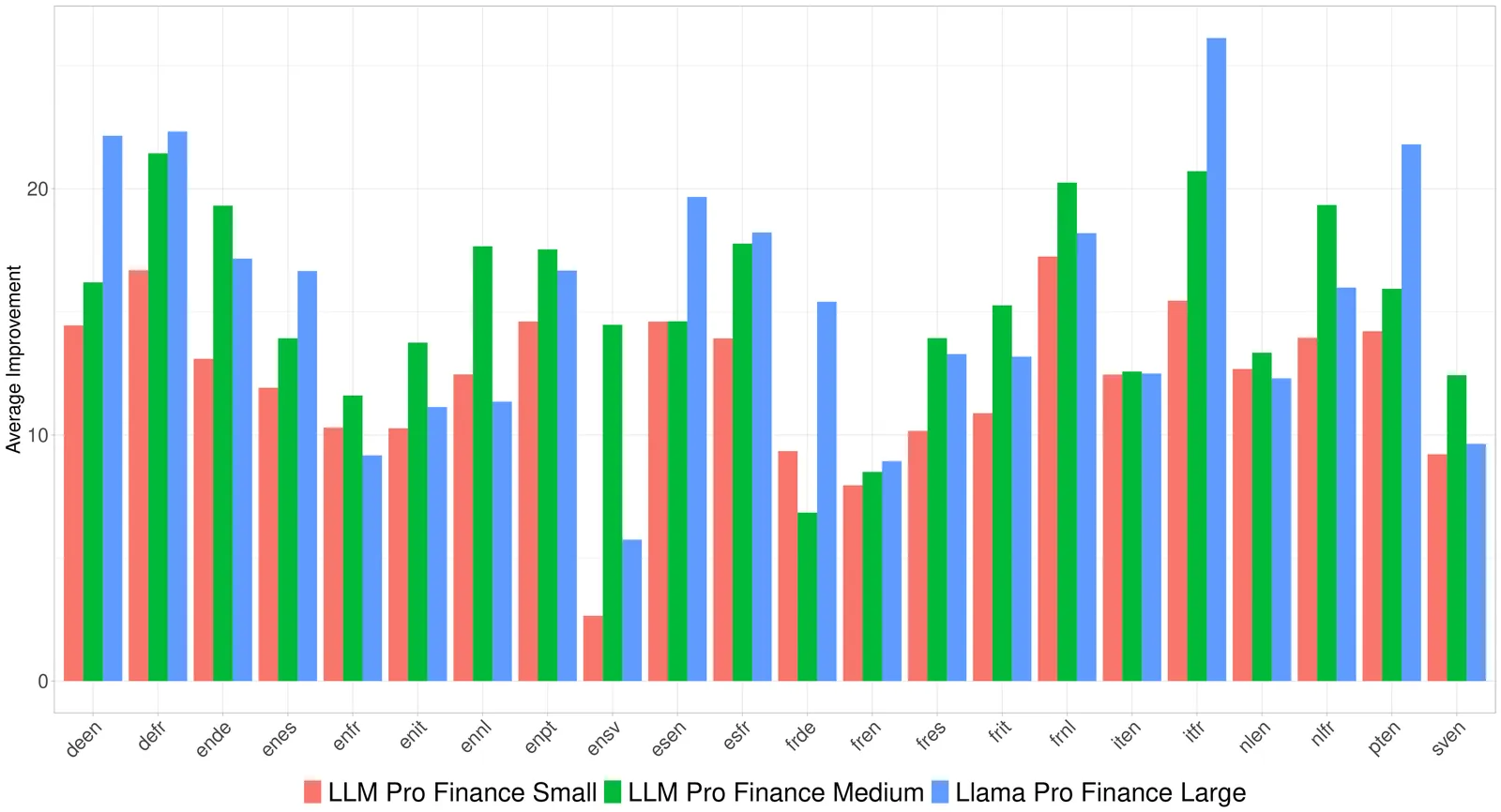
The financial industry's growing demand for advanced natural language processing (NLP) capabilities has highlighted the limitations of generalist large language models (LLMs) in handling domain-specific financial tasks. To address this gap, we introduce the LLM Pro Finance Suite, a collection of five instruction-tuned LLMs (ranging from 8B to 70B parameters) specifically designed for financial applications. Our approach focuses on enhancing generalist instruction-tuned models, leveraging their existing strengths in instruction following, reasoning, and toxicity control, while fine-tuning them on a curated, high-quality financial corpus comprising over 50% finance-related data in English, French, and German. We evaluate the LLM Pro Finance Suite on a comprehensive financial benchmark suite, demonstrating consistent improvement over state-of-the-art baselines in finance-oriented tasks and financial translation. Notably, our models maintain the strong general-domain capabilities of their base models, ensuring reliable performance across non-specialized tasks. This dual proficiency, enhanced financial expertise without compromise on general abilities, makes the LLM Pro Finance Suite an ideal drop-in replacement for existing LLMs in financial workflows, offering improved domain-specific performance while preserving overall versatility. We publicly release two 8B-parameters models to foster future research and development in financial NLP applications: https://huggingface.co/collections/DragonLLM/llm-open-finance.
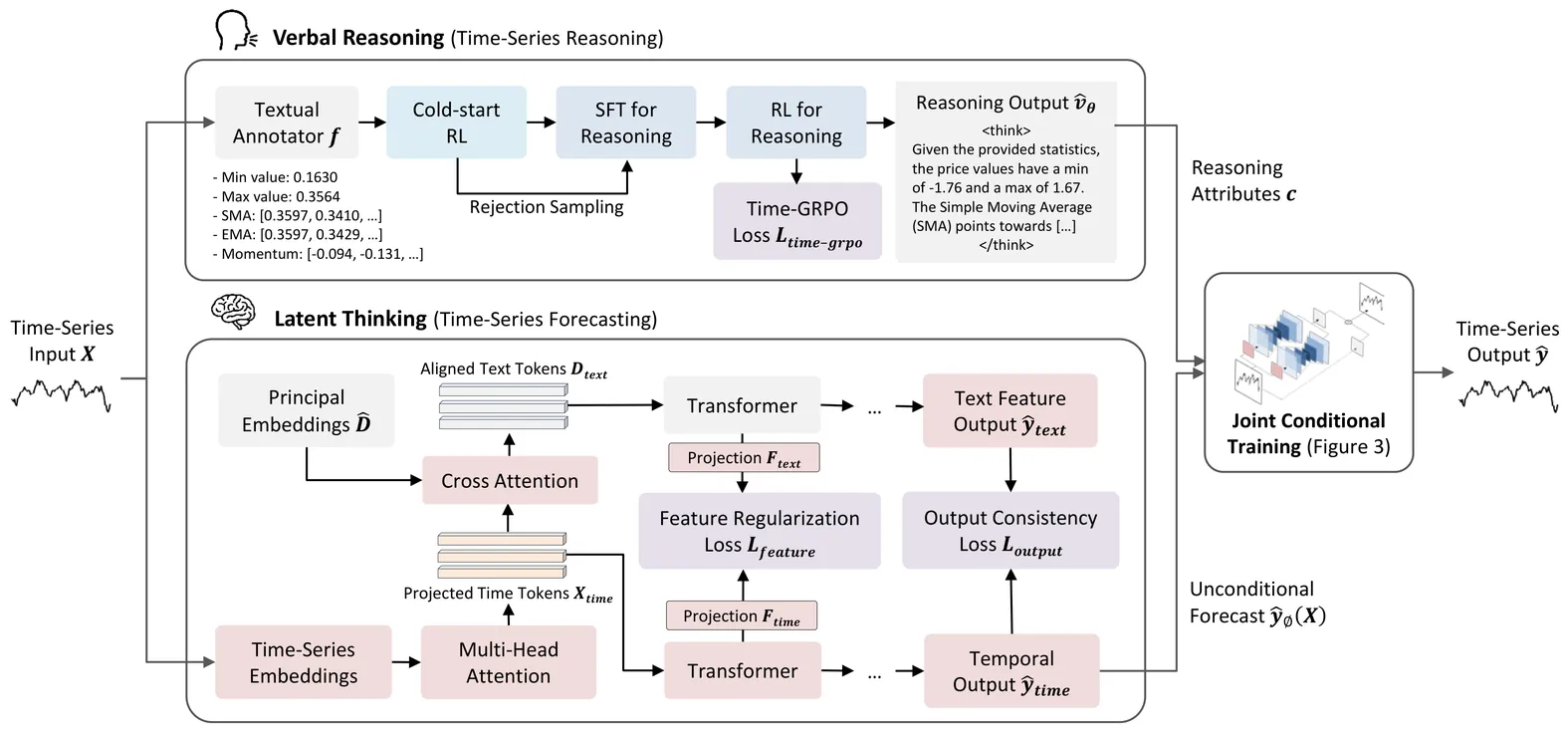
While Large Language Models have been used to produce interpretable stock forecasts, they mainly focus on analyzing textual reports but not historical price data, also known as Technical Analysis. This task is challenging as it switches between domains: the stock price inputs and outputs lie in the time-series domain, while the reasoning step should be in natural language. In this work, we introduce Verbal Technical Analysis (VTA), a novel framework that combine verbal and latent reasoning to produce stock time-series forecasts that are both accurate and interpretable. To reason over time-series, we convert stock price data into textual annotations and optimize the reasoning trace using an inverse Mean Squared Error (MSE) reward objective. To produce time-series outputs from textual reasoning, we condition the outputs of a time-series backbone model on the reasoning-based attributes. Experiments on stock datasets across U.S., Chinese, and European markets show that VTA achieves state-of-the-art forecasting accuracy, while the reasoning traces also perform well on evaluation by industry experts.