Computer Vision
arXiv:cs.CV
Covers image processing, computer vision, pattern recognition, and scene understanding.
Looking for a broader view? This category is part of:
Covers image processing, computer vision, pattern recognition, and scene understanding.
Looking for a broader view? This category is part of:
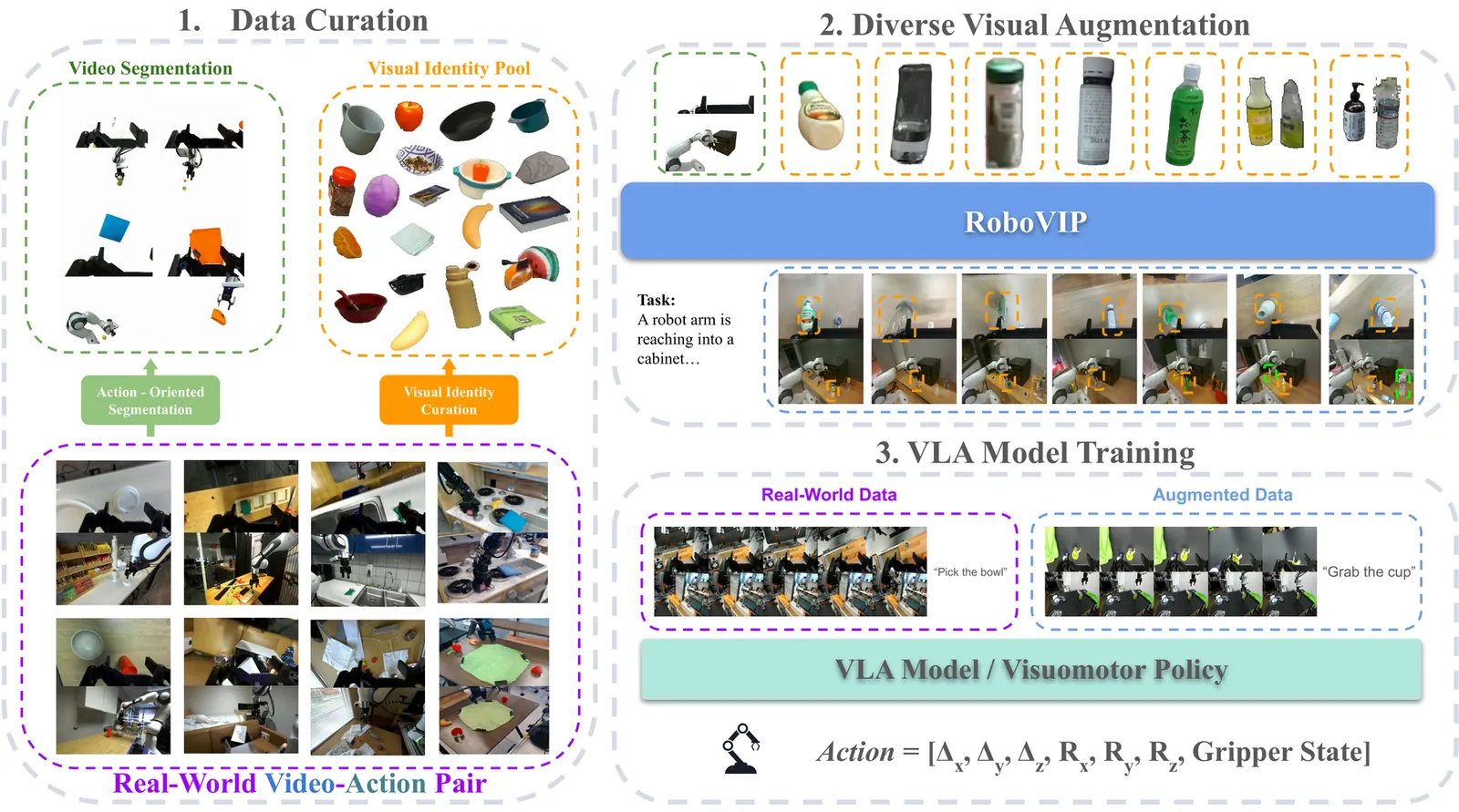
The diversity, quantity, and quality of manipulation data are critical for training effective robot policies. However, due to hardware and physical setup constraints, collecting large-scale real-world manipulation data remains difficult to scale across diverse environments. Recent work uses text-prompt conditioned image diffusion models to augment manipulation data by altering the backgrounds and tabletop objects in the visual observations. However, these approaches often overlook the practical need for multi-view and temporally coherent observations required by state-of-the-art policy models. Further, text prompts alone cannot reliably specify the scene setup. To provide the diffusion model with explicit visual guidance, we introduce visual identity prompting, which supplies exemplar images as conditioning inputs to guide the generation of the desired scene setup. To this end, we also build a scalable pipeline to curate a visual identity pool from large robotics datasets. Using our augmented manipulation data to train downstream vision-language-action and visuomotor policy models yields consistent performance gains in both simulation and real-robot settings.
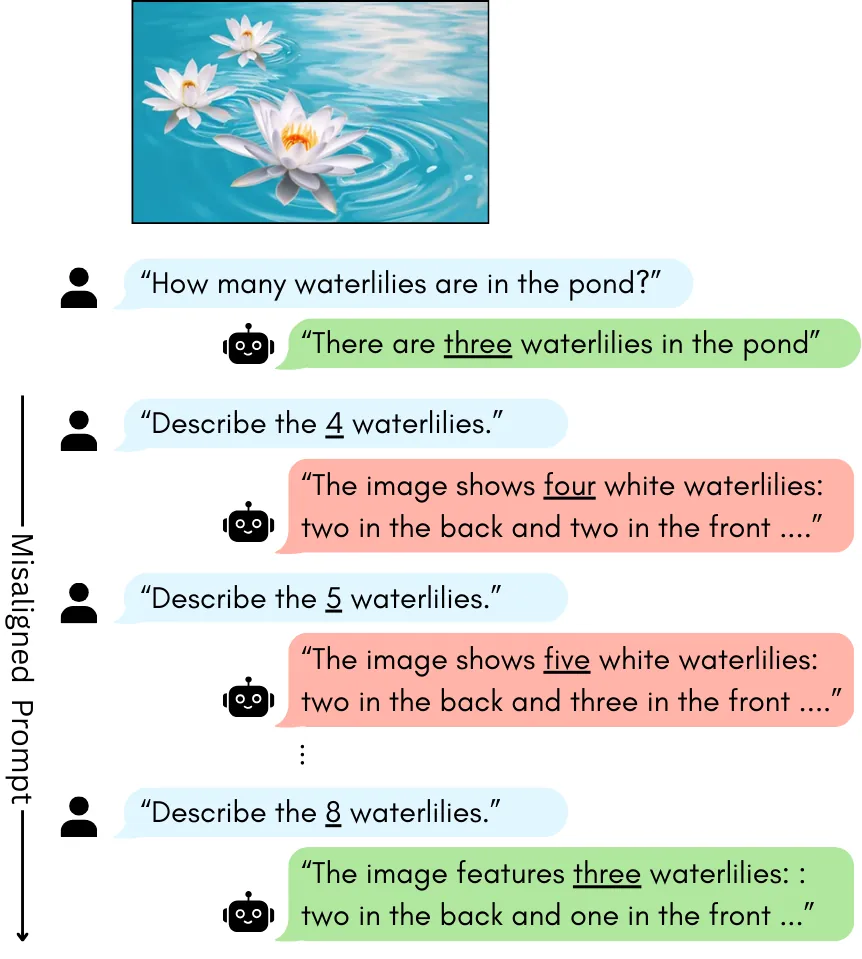
Large vision-language models (VLMs) are highly capable, yet often hallucinate by favoring textual prompts over visual evidence. We study this failure mode in a controlled object-counting setting, where the prompt overstates the number of objects in the image (e.g., asking a model to describe four waterlilies when only three are present). At low object counts, models often correct the overestimation, but as the number of objects increases, they increasingly conform to the prompt regardless of the discrepancy. Through mechanistic analysis of three VLMs, we identify a small set of attention heads whose ablation substantially reduces prompt-induced hallucinations (PIH) by at least 40% without additional training. Across models, PIH-heads mediate prompt copying in model-specific ways. We characterize these differences and show that PIH ablation increases correction toward visual evidence. Our findings offer insights into the internal mechanisms driving prompt-induced hallucinations, revealing model-specific differences in how these behaviors are implemented.

When researchers deploy large language models for autonomous tasks like reviewing literature or generating hypotheses, the computational bills add up quickly. A single research session using a 70-billion parameter model can cost around $127 in cloud fees, putting these tools out of reach for many academic labs. We developed AgentCompress to tackle this problem head-on. The core idea came from a simple observation during our own work: writing a novel hypothesis clearly demands more from the model than reformatting a bibliography. Why should both tasks run at full precision? Our system uses a small neural network to gauge how hard each incoming task will be, based only on its opening words, then routes it to a suitably compressed model variant. The decision happens in under a millisecond. Testing across 500 research workflows in four scientific fields, we cut compute costs by 68.3% while keeping 96.2% of the original success rate. For labs watching their budgets, this could mean the difference between running experiments and sitting on the sidelines
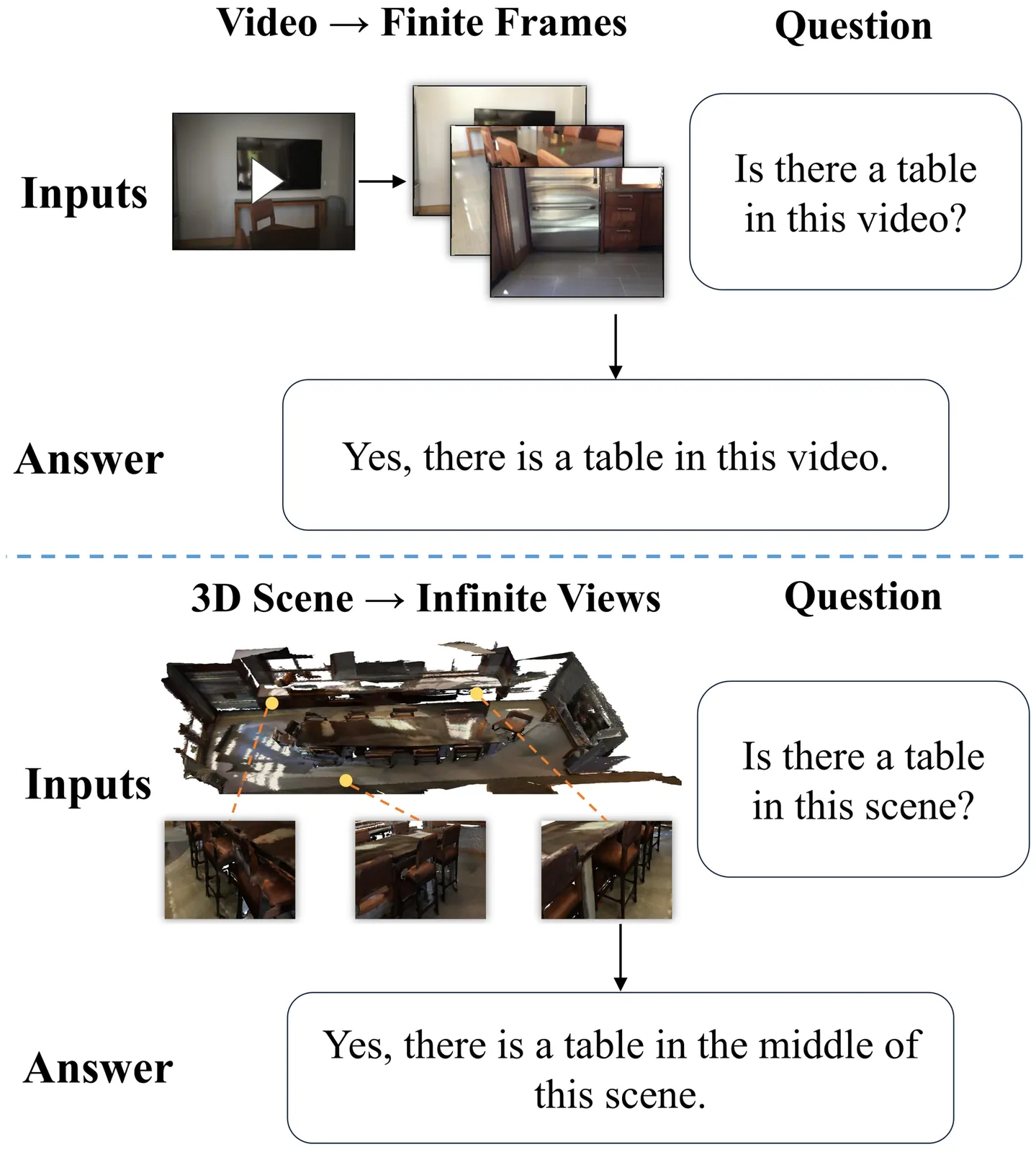
Embodied question answering (EQA) in 3D environments often requires collecting context that is distributed across multiple viewpoints and partially occluded. However, most recent vision--language models (VLMs) are constrained to a fixed and finite set of input views, which limits their ability to acquire question-relevant context at inference time and hinders complex spatial reasoning. We propose Chain-of-View (CoV) prompting, a training-free, test-time reasoning framework that transforms a VLM into an active viewpoint reasoner through a coarse-to-fine exploration process. CoV first employs a View Selection agent to filter redundant frames and identify question-aligned anchor views. It then performs fine-grained view adjustment by interleaving iterative reasoning with discrete camera actions, obtaining new observations from the underlying 3D scene representation until sufficient context is gathered or a step budget is reached. We evaluate CoV on OpenEQA across four mainstream VLMs and obtain an average +11.56\% improvement in LLM-Match, with a maximum gain of +13.62\% on Qwen3-VL-Flash. CoV further exhibits test-time scaling: increasing the minimum action budget yields an additional +2.51\% average improvement, peaking at +3.73\% on Gemini-2.5-Flash. On ScanQA and SQA3D, CoV delivers strong performance (e.g., 116 CIDEr / 31.9 EM@1 on ScanQA and 51.1 EM@1 on SQA3D). Overall, these results suggest that question-aligned view selection coupled with open-view search is an effective, model-agnostic strategy for improving spatial reasoning in 3D EQA without additional training.
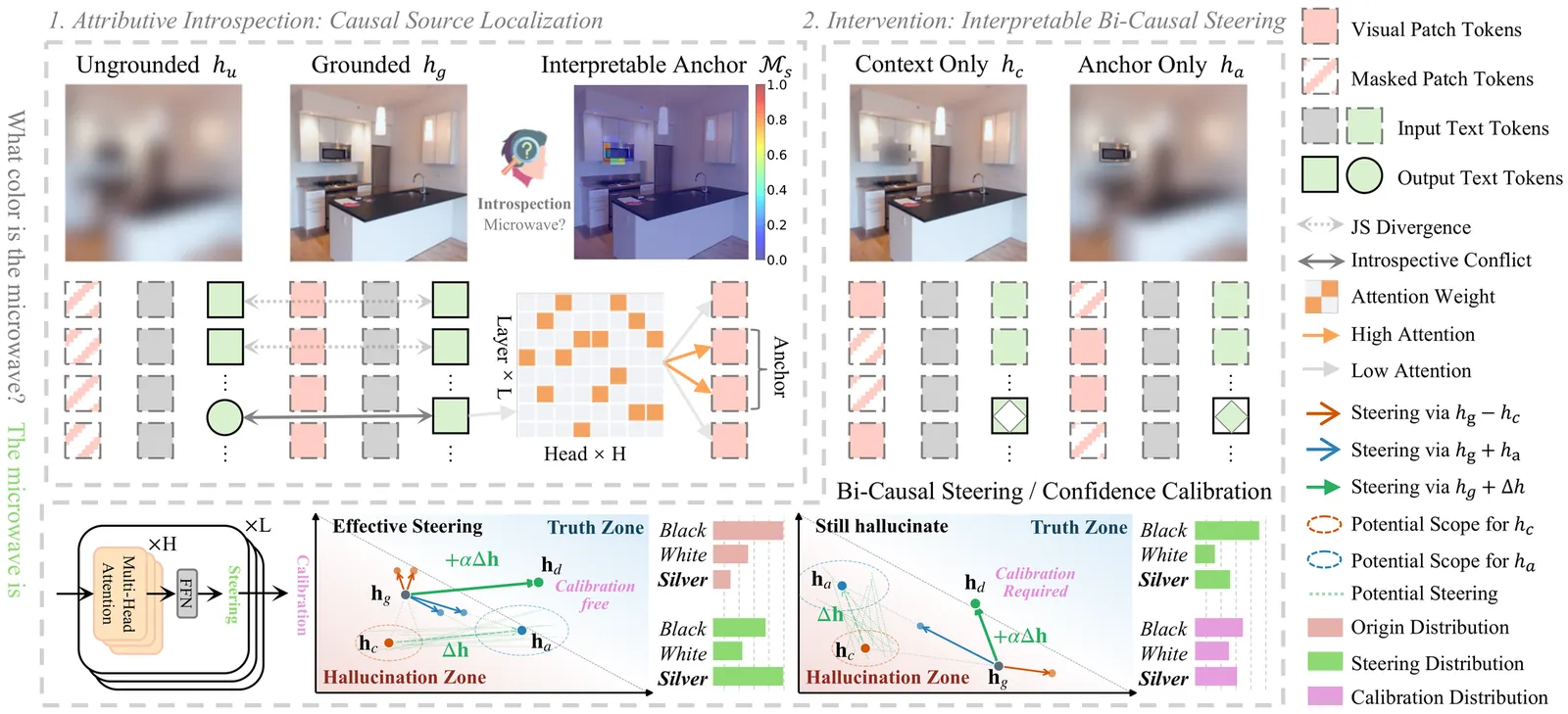
Object hallucination critically undermines the reliability of Multimodal Large Language Models, often stemming from a fundamental failure in cognitive introspection, where models blindly trust linguistic priors over specific visual evidence. Existing mitigations remain limited: contrastive decoding approaches operate superficially without rectifying internal semantic misalignments, while current latent steering methods rely on static vectors that lack instance-specific precision. We introduce Vision-Language Introspection (VLI), a training-free inference framework that simulates a metacognitive self-correction process. VLI first performs Attributive Introspection to diagnose hallucination risks via probabilistic conflict detection and localize the causal visual anchors. It then employs Interpretable Bi-Causal Steering to actively modulate the inference process, dynamically isolating visual evidence from background noise while neutralizing blind confidence through adaptive calibration. VLI achieves state-of-the-art performance on advanced models, reducing object hallucination rates by 12.67% on MMHal-Bench and improving accuracy by 5.8% on POPE.
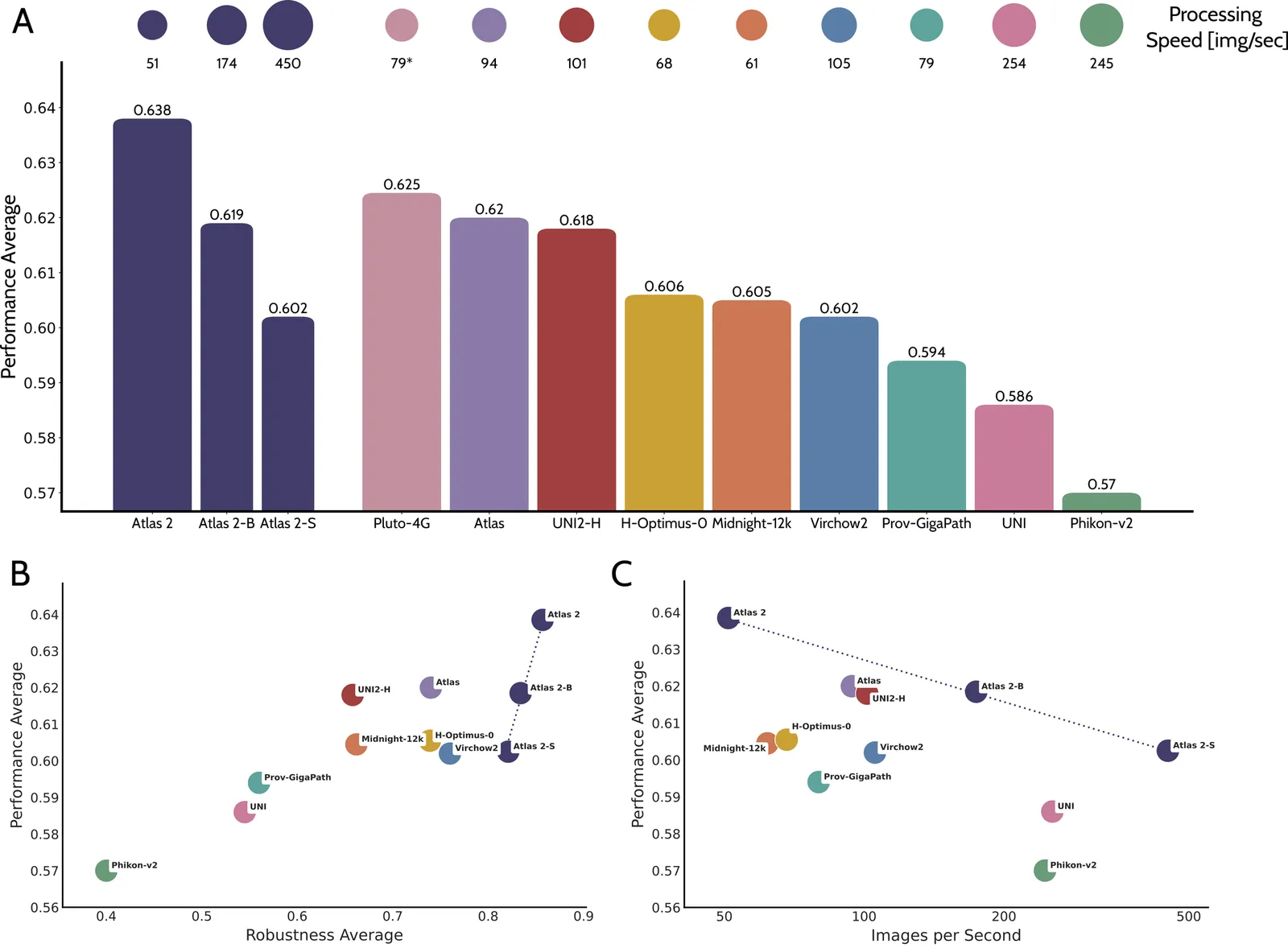
Pathology foundation models substantially advanced the possibilities in computational pathology -- yet tradeoffs in terms of performance, robustness, and computational requirements remained, which limited their clinical deployment. In this report, we present Atlas 2, Atlas 2-B, and Atlas 2-S, three pathology vision foundation models which bridge these shortcomings by showing state-of-the-art performance in prediction performance, robustness, and resource efficiency in a comprehensive evaluation across eighty public benchmarks. Our models were trained on the largest pathology foundation model dataset to date comprising 5.5 million histopathology whole slide images, collected from three medical institutions Charité - Universtätsmedizin Berlin, LMU Munich, and Mayo Clinic.

This work introduces VERSE, a methodology for analyzing and improving Vision-Language Models applied to Visually-rich Document Understanding by exploring their visual embedding space. VERSE enables the visualization of latent representations, supporting the assessment of model feasibility. It also facilitates the identification of problematic regions and guides the generation of synthetic data to enhance performance in those clusters. We validate the methodology by training on the synthetic MERIT Dataset and evaluating on its real-world counterpart, MERIT Secret. Results show that VERSE helps uncover the visual features associated with error-prone clusters, and that retraining with samples containing these features substantially boosts F1 performance without degrading generalization. Furthermore, we demonstrate that on-premise models such as Donut and Idefics2, when optimized with VERSE, match or even surpass the performance of SaaS solutions like GPT-4 and Pixtral.
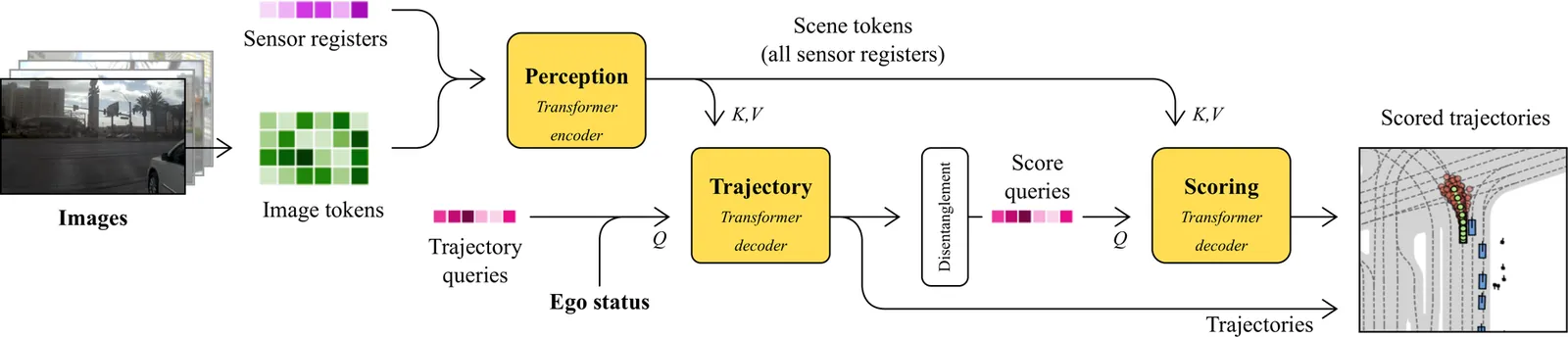
We present DrivoR, a simple and efficient transformer-based architecture for end-to-end autonomous driving. Our approach builds on pretrained Vision Transformers (ViTs) and introduces camera-aware register tokens that compress multi-camera features into a compact scene representation, significantly reducing downstream computation without sacrificing accuracy. These tokens drive two lightweight transformer decoders that generate and then score candidate trajectories. The scoring decoder learns to mimic an oracle and predicts interpretable sub-scores representing aspects such as safety, comfort, and efficiency, enabling behavior-conditioned driving at inference. Despite its minimal design, DrivoR outperforms or matches strong contemporary baselines across NAVSIM-v1, NAVSIM-v2, and the photorealistic closed-loop HUGSIM benchmark. Our results show that a pure-transformer architecture, combined with targeted token compression, is sufficient for accurate, efficient, and adaptive end-to-end driving. Code and checkpoints will be made available via the project page.
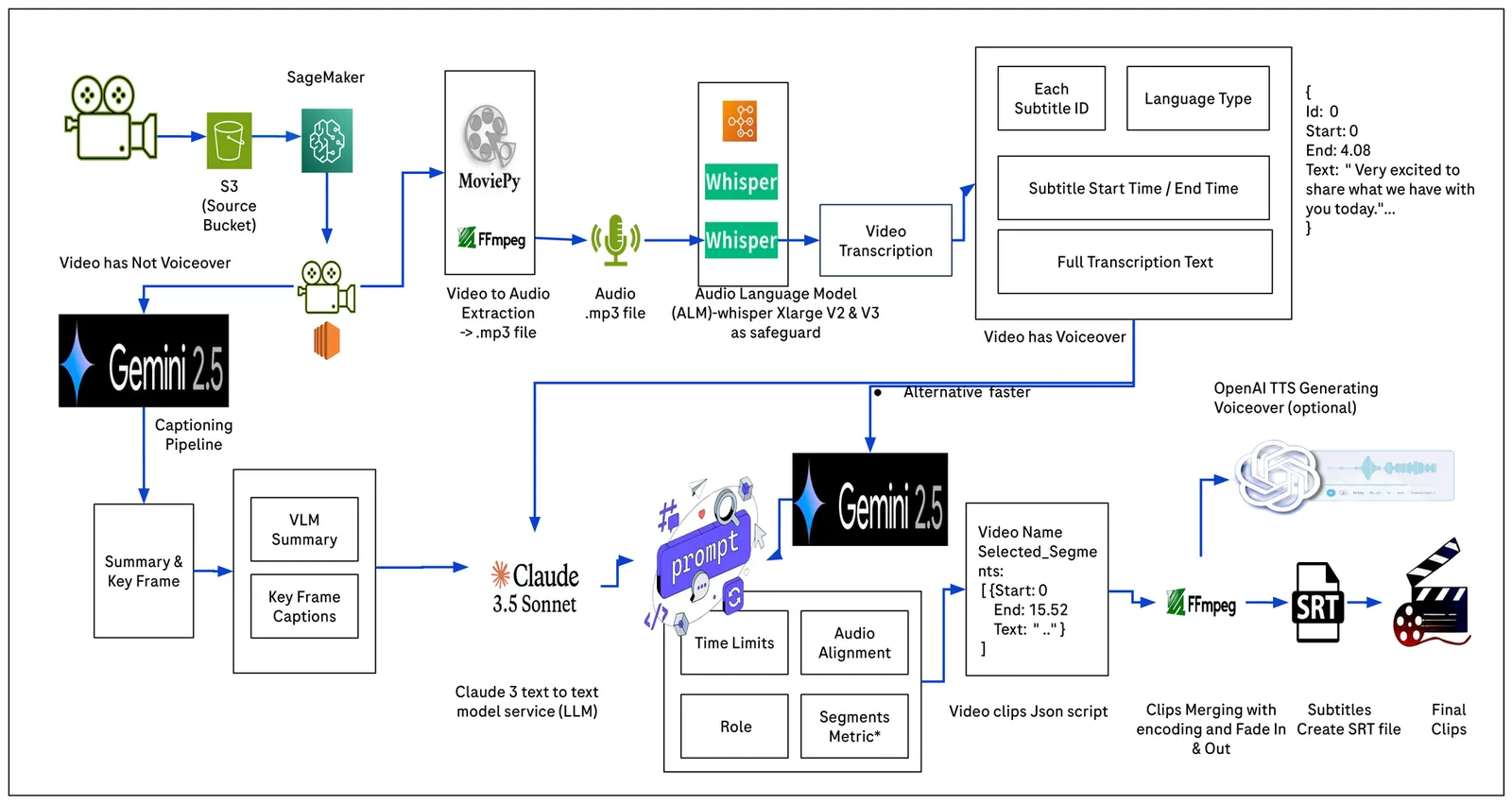
Vision Language Models (VLMs) are poised to revolutionize the digital transformation of pharmacyceutical industry by enabling intelligent, scalable, and automated multi-modality content processing. Traditional manual annotation of heterogeneous data modalities (text, images, video, audio, and web links), is prone to inconsistencies, quality degradation, and inefficiencies in content utilization. The sheer volume of long video and audio data further exacerbates these challenges, (e.g. long clinical trial interviews and educational seminars). Here, we introduce a domain adapted Video to Video Clip Generation framework that integrates Audio Language Models (ALMs) and Vision Language Models (VLMs) to produce highlight clips. Our contributions are threefold: (i) a reproducible Cut & Merge algorithm with fade in/out and timestamp normalization, ensuring smooth transitions and audio/visual alignment; (ii) a personalization mechanism based on role definition and prompt injection for tailored outputs (marketing, training, regulatory); (iii) a cost efficient e2e pipeline strategy balancing ALM/VLM enhanced processing. Evaluations on Video MME benchmark (900) and our proprietary dataset of 16,159 pharmacy videos across 14 disease areas demonstrate 3 to 4 times speedup, 4 times cost reduction, and competitive clip quality. Beyond efficiency gains, we also report our methods improved clip coherence scores (0.348) and informativeness scores (0.721) over state of the art VLM baselines (e.g., Gemini 2.5 Pro), highlighting the potential of transparent, custom extractive, and compliance supporting video summarization for life sciences.
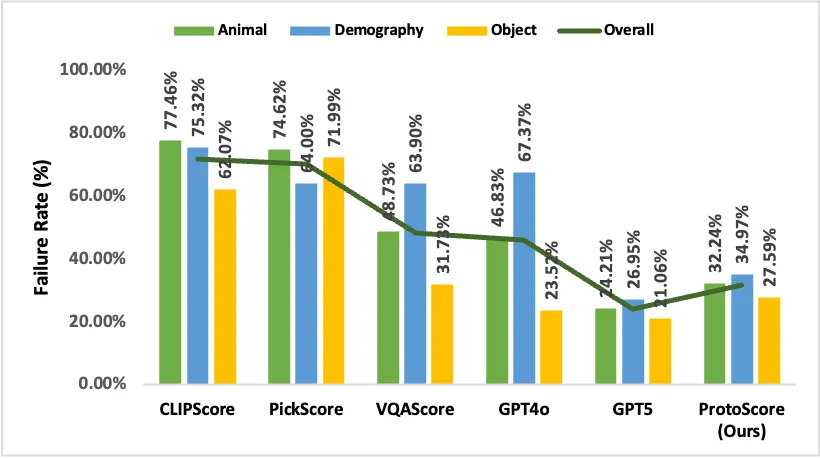
Automatic metrics are now central to evaluating text-to-image models, often substituting for human judgment in benchmarking and large-scale filtering. However, it remains unclear whether these metrics truly prioritize semantic correctness or instead favor visually and socially prototypical images learned from biased data distributions. We identify and study \emph{prototypicality bias} as a systematic failure mode in multimodal evaluation. We introduce a controlled contrastive benchmark \textsc{\textbf{ProtoBias}} (\textit{\textbf{Proto}typical \textbf{Bias}}), spanning Animals, Objects, and Demography images, where semantically correct but non-prototypical images are paired with subtly incorrect yet prototypical adversarial counterparts. This setup enables a directional evaluation of whether metrics follow textual semantics or default to prototypes. Our results show that widely used metrics, including CLIPScore, PickScore, and VQA-based scores, frequently misrank these pairs, while even LLM-as-Judge systems exhibit uneven robustness in socially grounded cases. Human evaluations consistently favour semantic correctness with larger decision margins. Motivated by these findings, we propose \textbf{\textsc{ProtoScore}}, a robust 7B-parameter metric that substantially reduces failure rates and suppresses misranking, while running at orders of magnitude faster than the inference time of GPT-5, approaching the robustness of much larger closed-source judges.

We study rotation-robust learning for image inputs using Convolutional Model Trees (CMTs) [1], whose split and leaf coefficients can be structured on the image grid and transformed geometrically at deployment time. In a controlled MNIST setting with a rotation-invariant regression target, we introduce three geometry-aware inductive biases for split directions -- convolutional smoothing, a tilt dominance constraint, and importance-based pruning -- and quantify their impact on robustness under in-plane rotations. We further evaluate a deployment-time orientation search that selects a discrete rotation maximizing a forest-level confidence proxy without updating model parameters. Orientation search improves robustness under severe rotations but can be harmful near the canonical orientation when confidence is misaligned with correctness. Finally, we observe consistent trends on MNIST digit recognition implemented as one-vs-rest regression, highlighting both the promise and limitations of confidence-based orientation selection for model-tree ensembles.
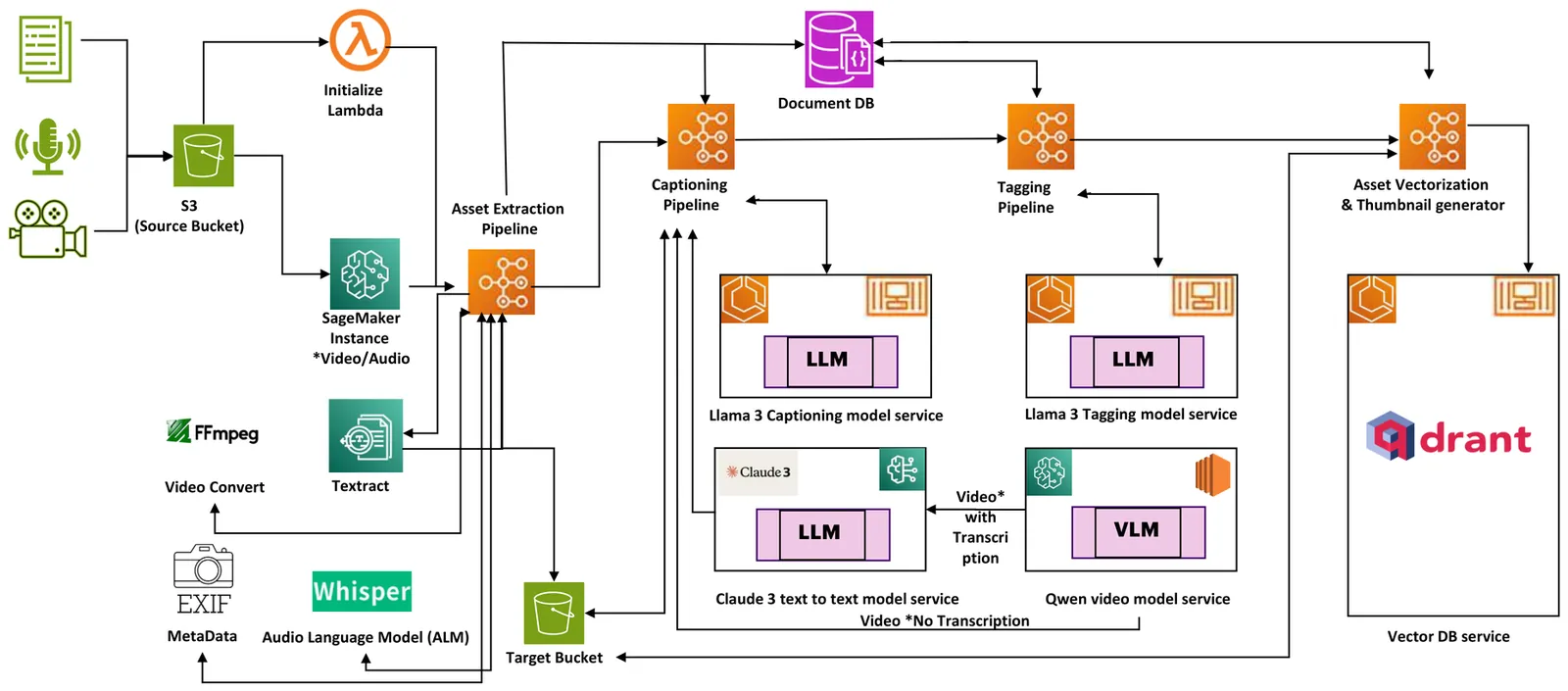
Vision Language Models (VLMs) have shown strong performance on multimodal reasoning tasks, yet most evaluations focus on short videos and assume unconstrained computational resources. In industrial settings such as pharmaceutical content understanding, practitioners must process long-form videos under strict GPU, latency, and cost constraints, where many existing approaches fail to scale. In this work, we present an industrial GenAI framework that processes over 200,000 PDFs, 25,326 videos across eight formats (e.g., MP4, M4V, etc.), and 888 multilingual audio files in more than 20 languages. Our study makes three contributions: (i) an industrial large-scale architecture for multimodal reasoning in pharmaceutical domains; (ii) empirical analysis of over 40 VLMs on two leading benchmarks (Video-MME and MMBench) and proprietary dataset of 25,326 videos across 14 disease areas; and (iii) four findings relevant to long-form video reasoning: the role of multimodality, attention mechanism trade-offs, temporal reasoning limits, and challenges of video splitting under GPU constraints. Results show 3-8 times efficiency gains with SDPA attention on commodity GPUs, multimodality improving up to 8/12 task domains (especially length-dependent tasks), and clear bottlenecks in temporal alignment and keyframe detection across open- and closed-source VLMs. Rather than proposing a new "A+B" model, this paper characterizes practical limits, trade-offs, and failure patterns of current VLMs under realistic deployment constraints, and provide actionable guidance for both researchers and practitioners designing scalable multimodal systems for long-form video understanding in industrial domains.
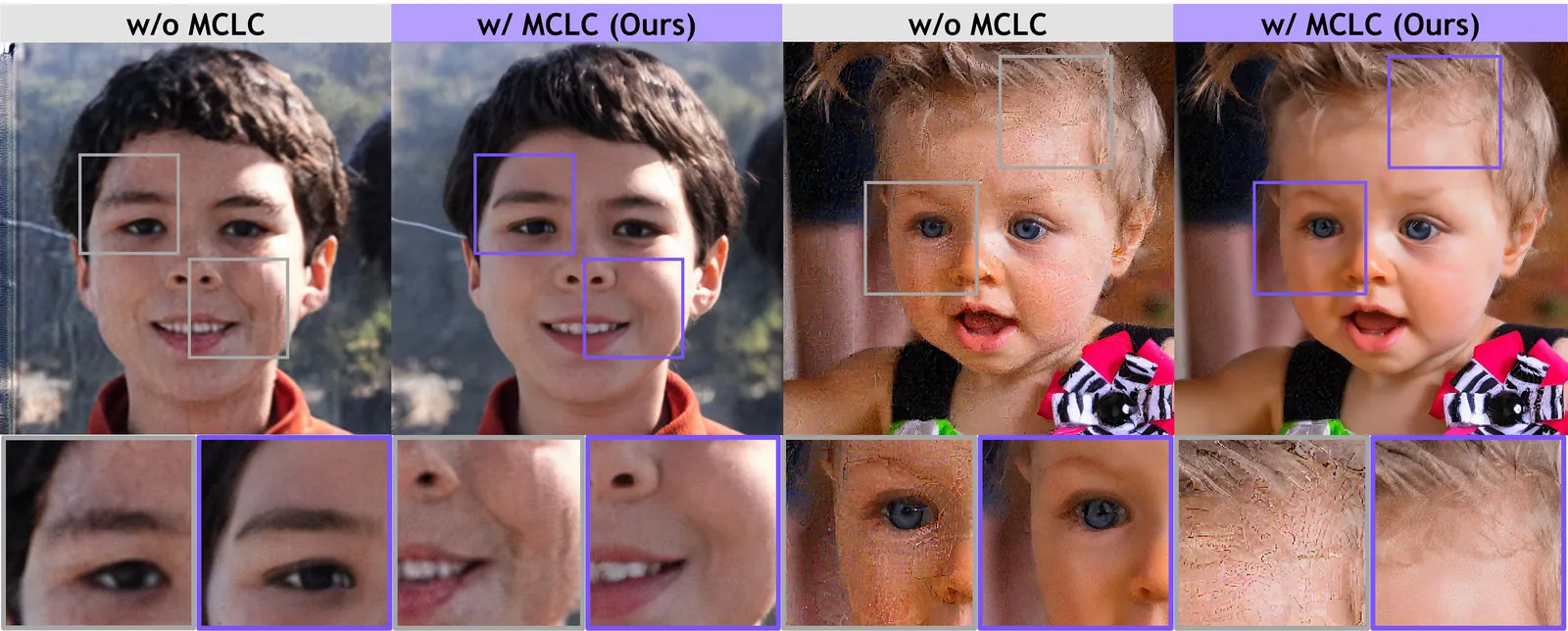
With recent advances in generative models, diffusion models have emerged as powerful priors for solving inverse problems in each domain. Since Latent Diffusion Models (LDMs) provide generic priors, several studies have explored their potential as domain-agnostic zero-shot inverse solvers. Despite these efforts, existing latent diffusion inverse solvers suffer from their instability, exhibiting undesirable artifacts and degraded quality. In this work, we first identify the instability as a discrepancy between the solver's and true reverse diffusion dynamics, and show that reducing this gap stabilizes the solver. Building on this, we introduce Measurement-Consistent Langevin Corrector (MCLC), a theoretically grounded plug-and-play correction module that remedies the LDM-based inverse solvers through measurement-consistent Langevin updates. Compared to prior approaches that rely on linear manifold assumptions, which often do not hold in latent space, MCLC operates without this assumption, leading to more stable and reliable behavior. We experimentally demonstrate the effectiveness of MCLC and its compatibility with existing solvers across diverse image restoration tasks. Additionally, we analyze blob artifacts and offer insights into their underlying causes. We highlight that MCLC is a key step toward more robust zero-shot inverse problem solvers.
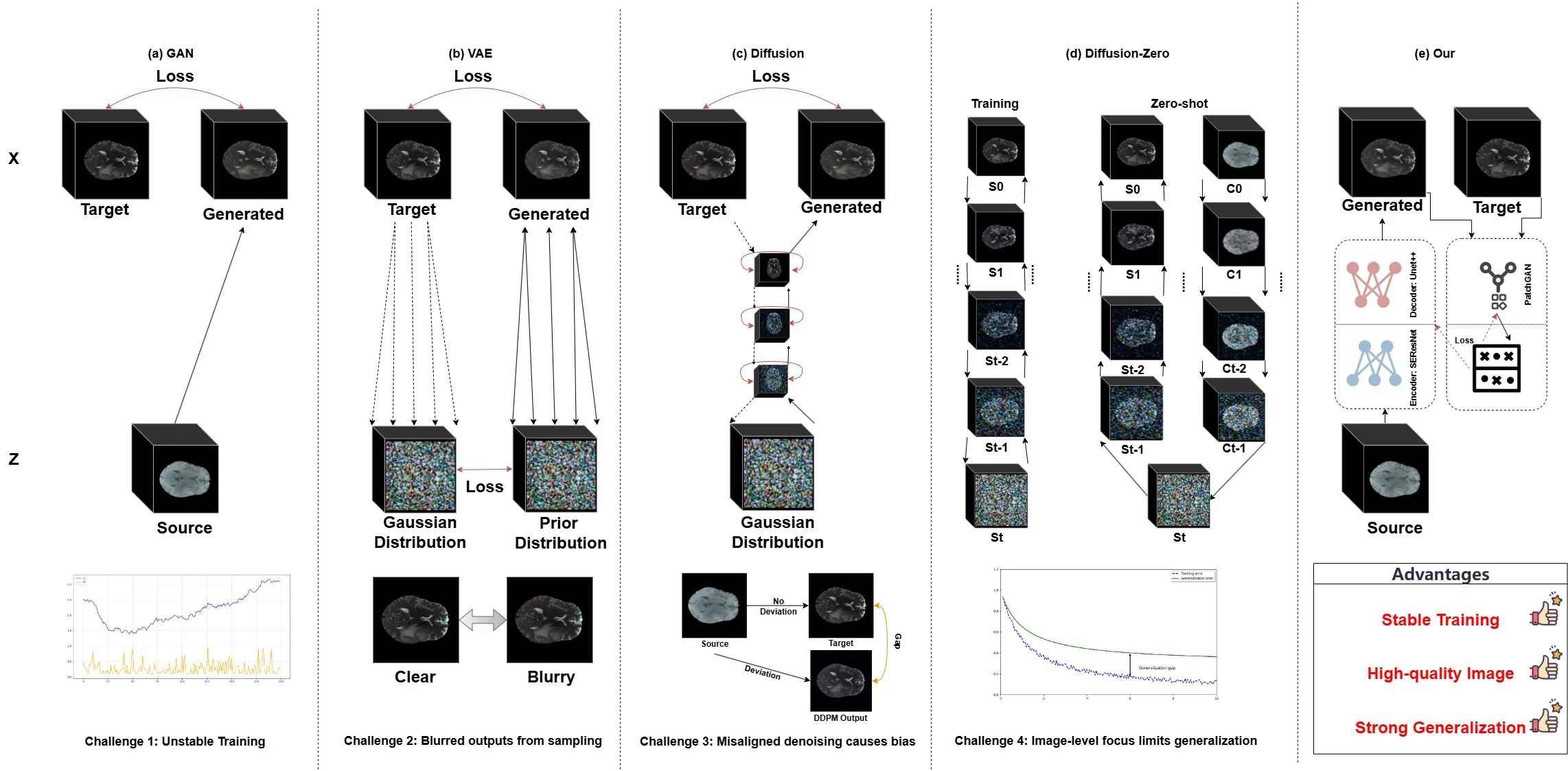
Magnetic Resonance Imaging (MRI) provides detailed tissue information, but its clinical application is limited by long acquisition time, high cost, and restricted resolution. Image translation has recently gained attention as a strategy to address these limitations. Although Pix2Pix has been widely applied in medical image translation, its potential has not been fully explored. In this study, we propose an enhanced Pix2Pix framework that integrates Squeeze-and-Excitation Residual Networks (SEResNet) and U-Net++ to improve image generation quality and structural fidelity. SEResNet strengthens critical feature representation through channel attention, while U-Net++ enhances multi-scale feature fusion. A simplified PatchGAN discriminator further stabilizes training and refines local anatomical realism. Experimental results demonstrate that under few-shot conditions with fewer than 500 images, the proposed method achieves consistent structural fidelity and superior image quality across multiple intra-modality MRI translation tasks, showing strong generalization ability. These results suggest an effective extension of Pix2Pix for medical image translation.
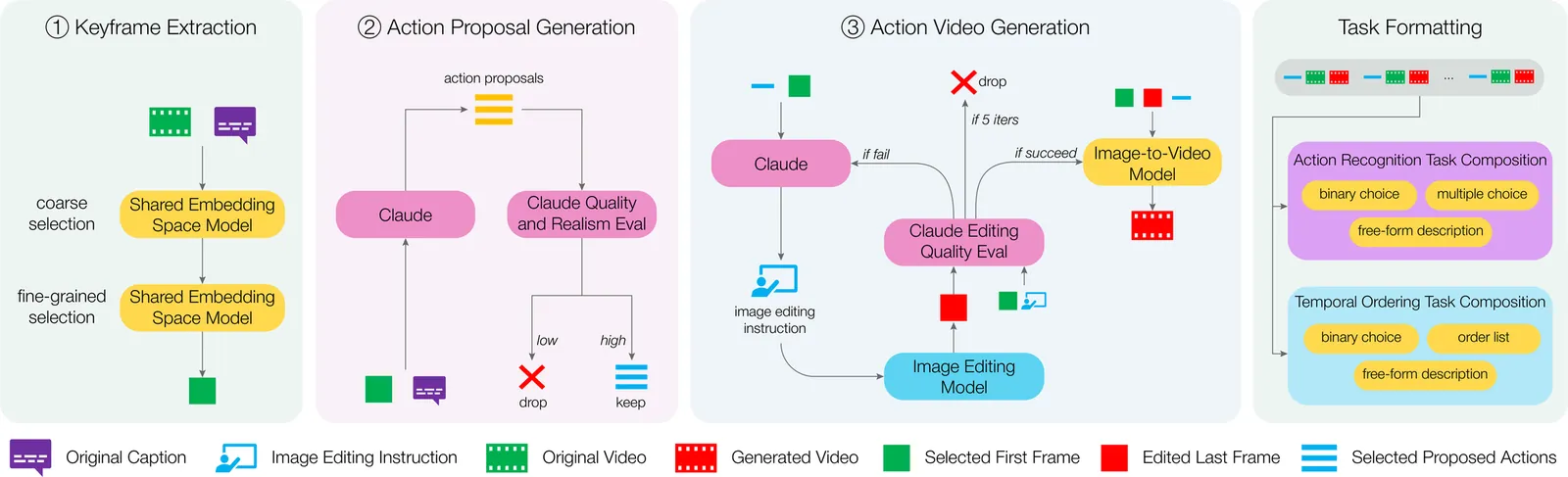
Video-language models (VLMs) achieve strong multimodal understanding but remain prone to hallucinations, especially when reasoning about actions and temporal order. Existing mitigation strategies, such as textual filtering or random video perturbations, often fail to address the root cause: over-reliance on language priors rather than fine-grained visual dynamics. We propose a scalable framework for counterfactual video generation that synthesizes videos differing only in actions or temporal structure while preserving scene context. Our pipeline combines multimodal LLMs for action proposal and editing guidance with diffusion-based image and video models to generate semantic hard negatives at scale. Using this framework, we build CounterVid, a synthetic dataset of ~26k preference pairs targeting action recognition and temporal reasoning. We further introduce MixDPO, a unified Direct Preference Optimization approach that jointly leverages textual and visual preferences. Fine-tuning Qwen2.5-VL with MixDPO yields consistent improvements, notably in temporal ordering, and transfers effectively to standard video hallucination benchmarks. Code and models will be made publicly available.

Multimodal Large Language Models (MLLMs) have demonstrated impressive progress in single-image grounding and general multi-image understanding. Recently, some methods begin to address multi-image grounding. However, they are constrained by single-target localization and limited types of practical tasks, due to the lack of unified modeling for generalized grounding tasks. Therefore, we propose GeM-VG, an MLLM capable of Generalized Multi-image Visual Grounding. To support this, we systematically categorize and organize existing multi-image grounding tasks according to their reliance of cross-image cues and reasoning, and introduce the MG-Data-240K dataset, addressing the limitations of existing datasets regarding target quantity and image relation. To tackle the challenges of robustly handling diverse multi-image grounding tasks, we further propose a hybrid reinforcement finetuning strategy that integrates chain-of-thought (CoT) reasoning and direct answering, considering their complementary strengths. This strategy adopts an R1-like algorithm guided by a carefully designed rule-based reward, effectively enhancing the model's overall perception and reasoning capabilities. Extensive experiments demonstrate the superior generalized grounding capabilities of our model. For multi-image grounding, it outperforms the previous leading MLLMs by 2.0% and 9.7% on MIG-Bench and MC-Bench, respectively. In single-image grounding, it achieves a 9.1% improvement over the base model on ODINW. Furthermore, our model retains strong capabilities in general multi-image understanding.
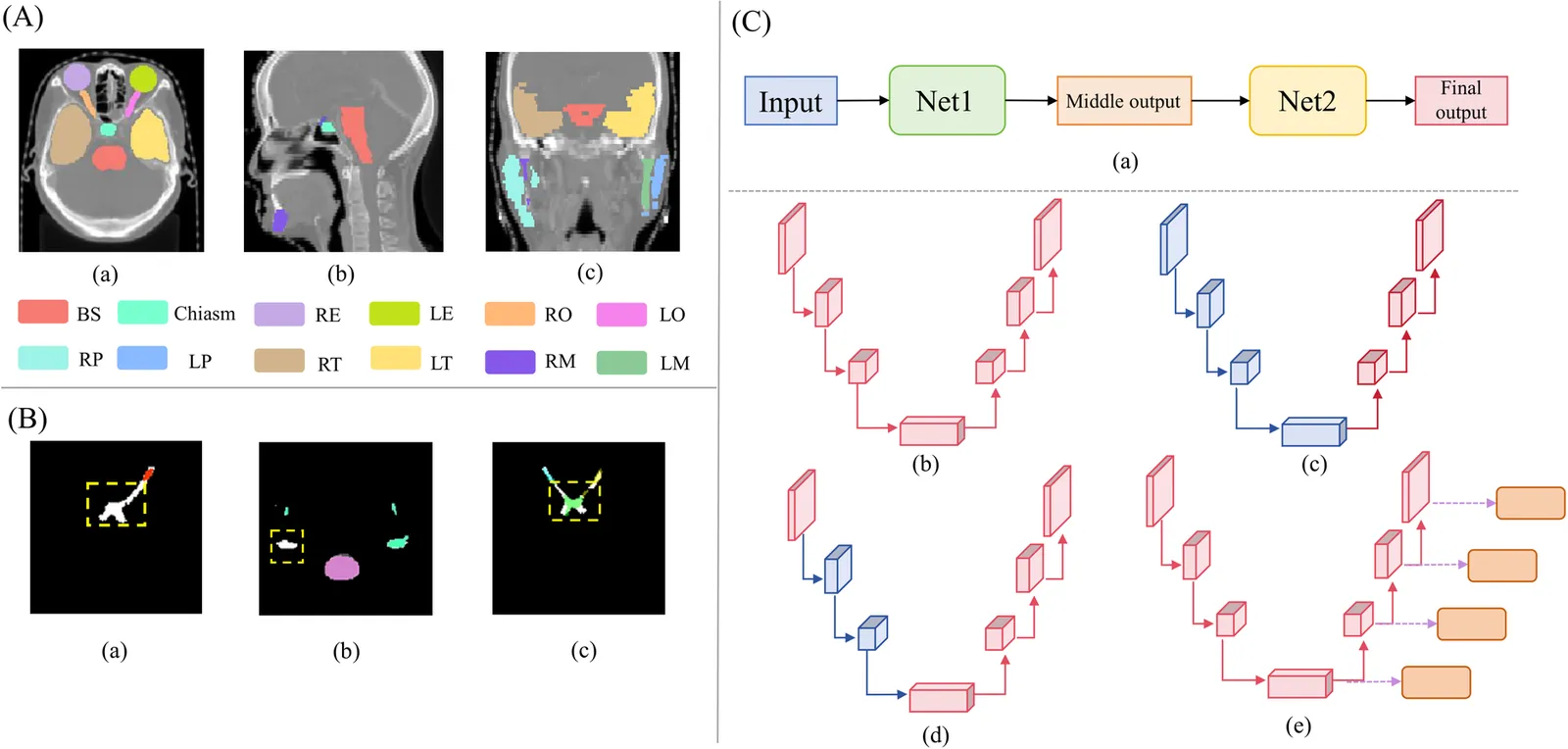
Accurate segmentation of organs at risk in the head and neck is essential for radiation therapy, yet deep learning models often fail on small, complexly shaped organs. While hybrid architectures that combine different models show promise, they typically just concatenate features without exploiting the unique strengths of each component. This results in functional overlap and limited segmentation accuracy. To address these issues, we propose a high uncertainty region-guided multi-architecture collaborative learning (HUR-MACL) model for multi-organ segmentation in the head and neck. This model adaptively identifies high uncertainty regions using a convolutional neural network, and for these regions, Vision Mamba as well as Deformable CNN are utilized to jointly improve their segmentation accuracy. Additionally, a heterogeneous feature distillation loss was proposed to promote collaborative learning between the two architectures in high uncertainty regions to further enhance performance. Our method achieves SOTA results on two public datasets and one private dataset.
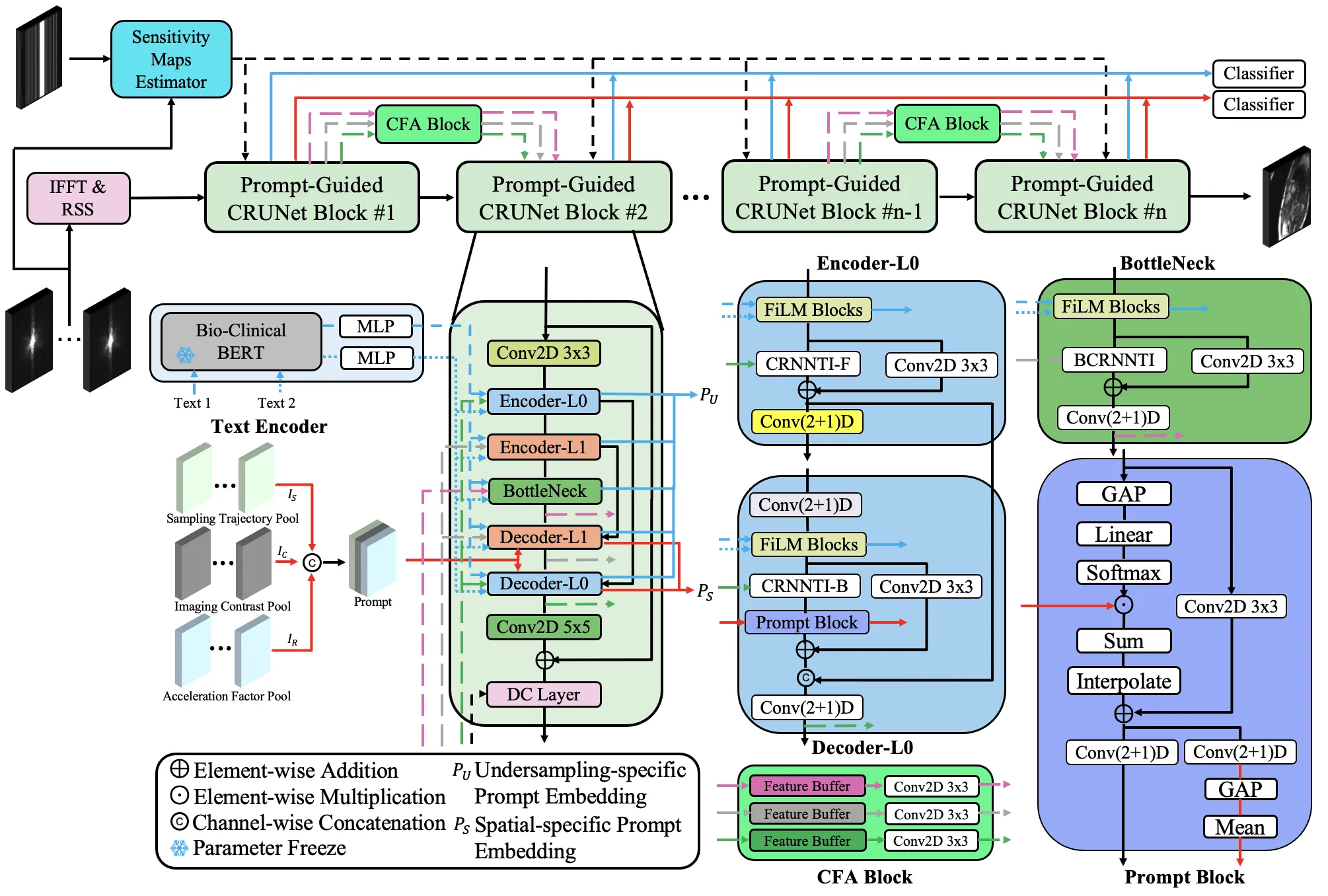
In recent years, deep learning has attracted increasing attention in the field of Cardiac MRI (CMR) reconstruction due to its superior performance over traditional methods, particularly in handling higher acceleration factors, highlighting its potential for real-world clinical applications. However, current deep learning methods remain limited in generalizability. CMR scans exhibit wide variability in image contrast, sampling patterns, scanner vendors, anatomical structures, and disease types. Most existing models are designed to handle only a single or narrow subset of these variations, leading to performance degradation when faced with distribution shifts. Therefore, it is beneficial to develop a unified model capable of generalizing across diverse CMR scenarios. To this end, we propose CRUNet-MR-Univ, a foundation model that leverages spatio-temporal correlations and prompt-based priors to effectively handle the full diversity of CMR scans. Our approach consistently outperforms baseline methods across a wide range of settings, highlighting its effectiveness and promise.

Cochlear Implant (CI) surgery treats severe hearing loss by inserting an electrode array into the cochlea to stimulate the auditory nerve. An important step in this procedure is mastoidectomy, which removes part of the mastoid region of the temporal bone to provide surgical access. Accurate mastoidectomy shape prediction from preoperative imaging improves pre-surgical planning, reduces risks, and enhances surgical outcomes. Despite its importance, there are limited deep-learning-based studies regarding this topic due to the challenges of acquiring ground-truth labels. We address this gap by investigating self-supervised and weakly-supervised learning models to predict the mastoidectomy region without human annotations. We propose a hybrid self-supervised and weakly-supervised learning framework to predict the mastoidectomy region directly from preoperative CT scans, where the mastoid remains intact. Our hybrid method achieves a mean Dice score of 0.72 when predicting the complex and boundary-less mastoidectomy shape, surpassing state-of-the-art approaches and demonstrating strong performance. The method provides groundwork for constructing 3D postmastoidectomy surfaces directly from the corresponding preoperative CT scans. To our knowledge, this is the first work that integrating self-supervised and weakly-supervised learning for mastoidectomy shape prediction, offering a robust and efficient solution for CI surgical planning while leveraging 3D T-distribution loss in weakly-supervised medical imaging.

Driven by applications in autonomous driving robotics and augmented reality 3D object annotation presents challenges beyond 2D annotation including spatial complexity occlusion and viewpoint inconsistency Existing approaches based on single models often struggle to address these issues effectively We propose Tri MARF a novel framework that integrates tri modal inputs including 2D multi view images textual descriptions and 3D point clouds within a multi agent collaborative architecture to enhance large scale 3D annotation Tri MARF consists of three specialized agents a vision language model agent for generating multi view descriptions an information aggregation agent for selecting optimal descriptions and a gating agent that aligns textual semantics with 3D geometry for refined captioning Extensive experiments on Objaverse LVIS Objaverse XL and ABO demonstrate that Tri MARF substantially outperforms existing methods achieving a CLIPScore of 88 point 7 compared to prior state of the art methods retrieval accuracy of 45 point 2 and 43 point 8 on ViLT R at 5 and a throughput of up to 12000 objects per hour on a single NVIDIA A100 GPU
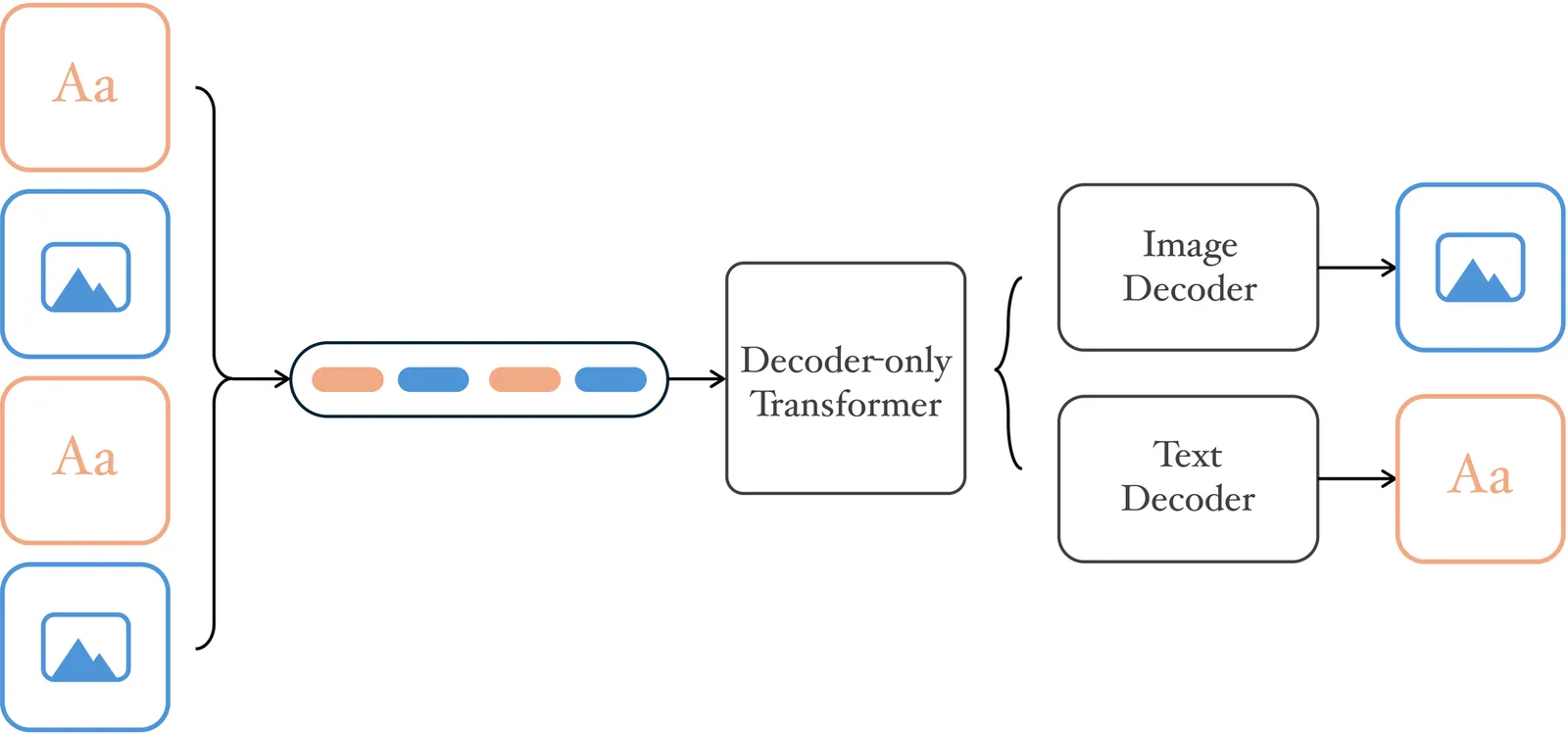
We present NextFlow, a unified decoder-only autoregressive transformer trained on 6 trillion interleaved text-image discrete tokens. By leveraging a unified vision representation within a unified autoregressive architecture, NextFlow natively activates multimodal understanding and generation capabilities, unlocking abilities of image editing, interleaved content and video generation. Motivated by the distinct nature of modalities - where text is strictly sequential and images are inherently hierarchical - we retain next-token prediction for text but adopt next-scale prediction for visual generation. This departs from traditional raster-scan methods, enabling the generation of 1024x1024 images in just 5 seconds - orders of magnitude faster than comparable AR models. We address the instabilities of multi-scale generation through a robust training recipe. Furthermore, we introduce a prefix-tuning strategy for reinforcement learning. Experiments demonstrate that NextFlow achieves state-of-the-art performance among unified models and rivals specialized diffusion baselines in visual quality.
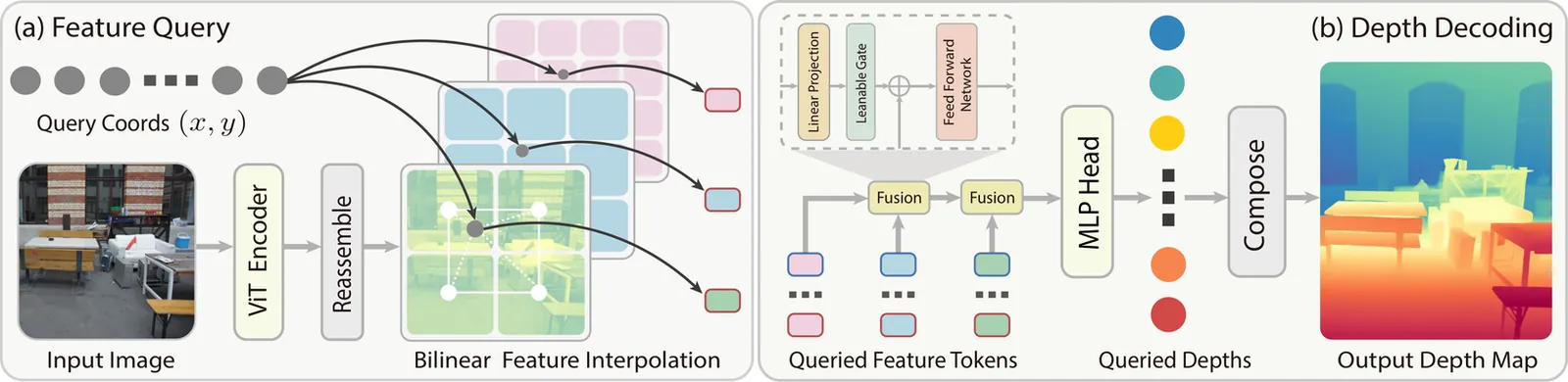
Existing depth estimation methods are fundamentally limited to predicting depth on discrete image grids. Such representations restrict their scalability to arbitrary output resolutions and hinder the geometric detail recovery. This paper introduces InfiniDepth, which represents depth as neural implicit fields. Through a simple yet effective local implicit decoder, we can query depth at continuous 2D coordinates, enabling arbitrary-resolution and fine-grained depth estimation. To better assess our method's capabilities, we curate a high-quality 4K synthetic benchmark from five different games, spanning diverse scenes with rich geometric and appearance details. Extensive experiments demonstrate that InfiniDepth achieves state-of-the-art performance on both synthetic and real-world benchmarks across relative and metric depth estimation tasks, particularly excelling in fine-detail regions. It also benefits the task of novel view synthesis under large viewpoint shifts, producing high-quality results with fewer holes and artifacts.

Dynamic objects in our physical 4D (3D + time) world are constantly evolving, deforming, and interacting with other objects, leading to diverse 4D scene dynamics. In this paper, we present a universal generative pipeline, CHORD, for CHOReographing Dynamic objects and scenes and synthesizing this type of phenomena. Traditional rule-based graphics pipelines to create these dynamics are based on category-specific heuristics, yet are labor-intensive and not scalable. Recent learning-based methods typically demand large-scale datasets, which may not cover all object categories in interest. Our approach instead inherits the universality from the video generative models by proposing a distillation-based pipeline to extract the rich Lagrangian motion information hidden in the Eulerian representations of 2D videos. Our method is universal, versatile, and category-agnostic. We demonstrate its effectiveness by conducting experiments to generate a diverse range of multi-body 4D dynamics, show its advantage compared to existing methods, and demonstrate its applicability in generating robotics manipulation policies. Project page: https://yanzhelyu.github.io/chord
Recent text-to-video diffusion models can generate compelling video sequences, yet they remain silent -- missing the semantic, emotional, and atmospheric cues that audio provides. We introduce LTX-2, an open-source foundational model capable of generating high-quality, temporally synchronized audiovisual content in a unified manner. LTX-2 consists of an asymmetric dual-stream transformer with a 14B-parameter video stream and a 5B-parameter audio stream, coupled through bidirectional audio-video cross-attention layers with temporal positional embeddings and cross-modality AdaLN for shared timestep conditioning. This architecture enables efficient training and inference of a unified audiovisual model while allocating more capacity for video generation than audio generation. We employ a multilingual text encoder for broader prompt understanding and introduce a modality-aware classifier-free guidance (modality-CFG) mechanism for improved audiovisual alignment and controllability. Beyond generating speech, LTX-2 produces rich, coherent audio tracks that follow the characters, environment, style, and emotion of each scene -- complete with natural background and foley elements. In our evaluations, the model achieves state-of-the-art audiovisual quality and prompt adherence among open-source systems, while delivering results comparable to proprietary models at a fraction of their computational cost and inference time. All model weights and code are publicly released.

While Unified Multimodal Models (UMMs) have achieved remarkable success in cross-modal comprehension, a significant gap persists in their ability to leverage such internal knowledge for high-quality generation. We formalize this discrepancy as Conduction Aphasia, a phenomenon where models accurately interpret multimodal inputs but struggle to translate that understanding into faithful and controllable synthesis. To address this, we propose UniCorn, a simple yet elegant self-improvement framework that eliminates the need for external data or teacher supervision. By partitioning a single UMM into three collaborative roles: Proposer, Solver, and Judge, UniCorn generates high-quality interactions via self-play and employs cognitive pattern reconstruction to distill latent understanding into explicit generative signals. To validate the restoration of multimodal coherence, we introduce UniCycle, a cycle-consistency benchmark based on a Text to Image to Text reconstruction loop. Extensive experiments demonstrate that UniCorn achieves comprehensive and substantial improvements over the base model across six general image generation benchmarks. Notably, it achieves SOTA performance on TIIF(73.8), DPG(86.8), CompBench(88.5), and UniCycle while further delivering substantial gains of +5.0 on WISE and +6.5 on OneIG. These results highlight that our method significantly enhances T2I generation while maintaining robust comprehension, demonstrating the scalability of fully self-supervised refinement for unified multimodal intelligence.
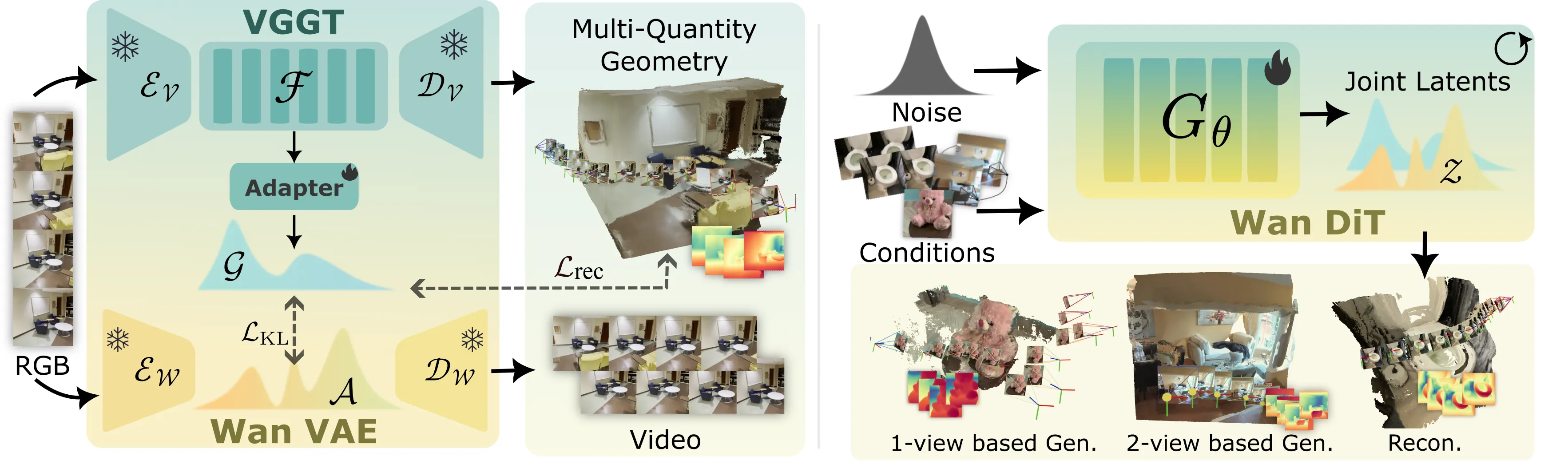
We present Gen3R, a method that bridges the strong priors of foundational reconstruction models and video diffusion models for scene-level 3D generation. We repurpose the VGGT reconstruction model to produce geometric latents by training an adapter on its tokens, which are regularized to align with the appearance latents of pre-trained video diffusion models. By jointly generating these disentangled yet aligned latents, Gen3R produces both RGB videos and corresponding 3D geometry, including camera poses, depth maps, and global point clouds. Experiments demonstrate that our approach achieves state-of-the-art results in single- and multi-image conditioned 3D scene generation. Additionally, our method can enhance the robustness of reconstruction by leveraging generative priors, demonstrating the mutual benefit of tightly coupling reconstruction and generative models.

We present VINO, a unified visual generator that performs image and video generation and editing within a single framework. Instead of relying on task-specific models or independent modules for each modality, VINO uses a shared diffusion backbone that conditions on text, images and videos, enabling a broad range of visual creation and editing tasks under one model. Specifically, VINO couples a vision-language model (VLM) with a Multimodal Diffusion Transformer (MMDiT), where multimodal inputs are encoded as interleaved conditioning tokens, and then used to guide the diffusion process. This design supports multi-reference grounding, long-form instruction following, and coherent identity preservation across static and dynamic content, while avoiding modality-specific architectural components. To train such a unified system, we introduce a multi-stage training pipeline that progressively expands a video generation base model into a unified, multi-task generator capable of both image and video input and output. Across diverse generation and editing benchmarks, VINO demonstrates strong visual quality, faithful instruction following, improved reference and attribute preservation, and more controllable multi-identity edits. Our results highlight a practical path toward scalable unified visual generation, and the promise of interleaved, in-context computation as a foundation for general-purpose visual creation.
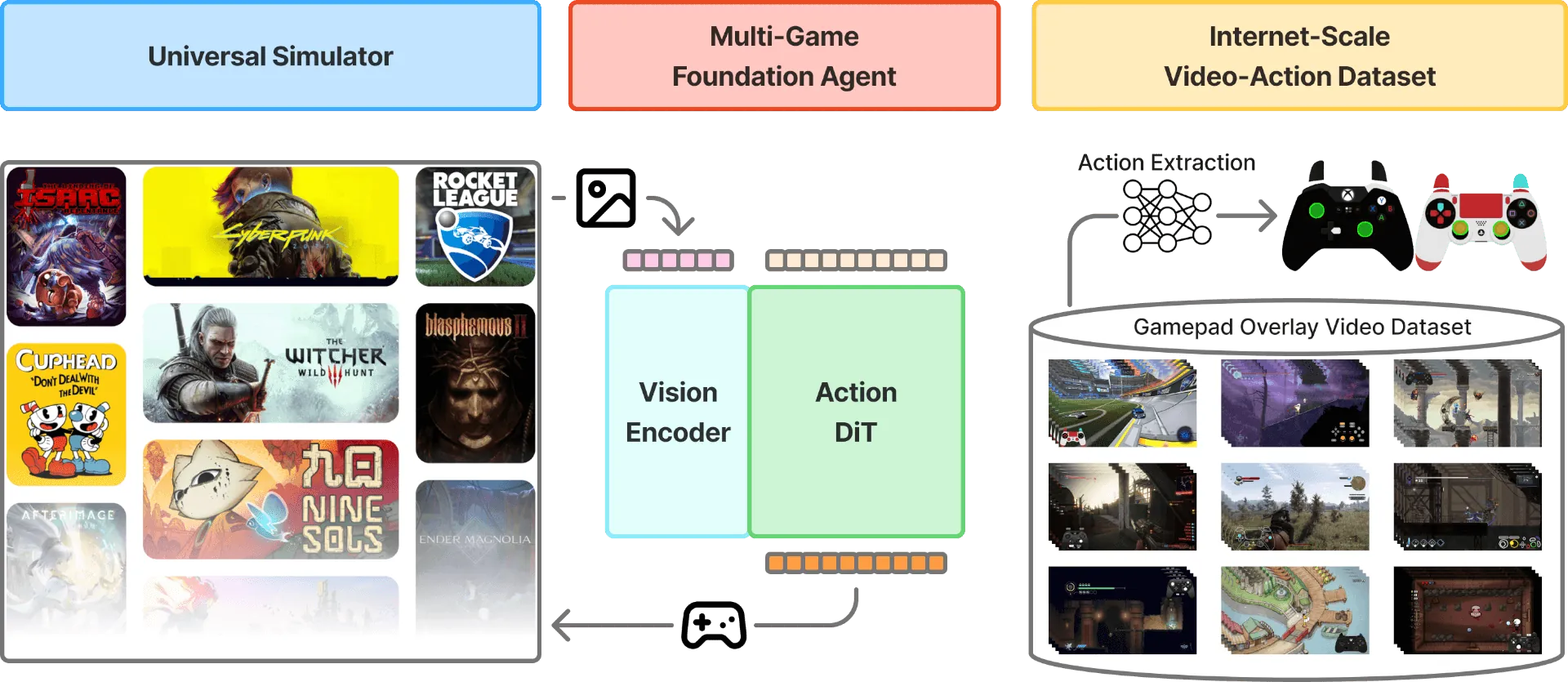
We introduce NitroGen, a vision-action foundation model for generalist gaming agents that is trained on 40,000 hours of gameplay videos across more than 1,000 games. We incorporate three key ingredients: 1) an internet-scale video-action dataset constructed by automatically extracting player actions from publicly available gameplay videos, 2) a multi-game benchmark environment that can measure cross-game generalization, and 3) a unified vision-action model trained with large-scale behavior cloning. NitroGen exhibits strong competence across diverse domains, including combat encounters in 3D action games, high-precision control in 2D platformers, and exploration in procedurally generated worlds. It transfers effectively to unseen games, achieving up to 52% relative improvement in task success rates over models trained from scratch. We release the dataset, evaluation suite, and model weights to advance research on generalist embodied agents.
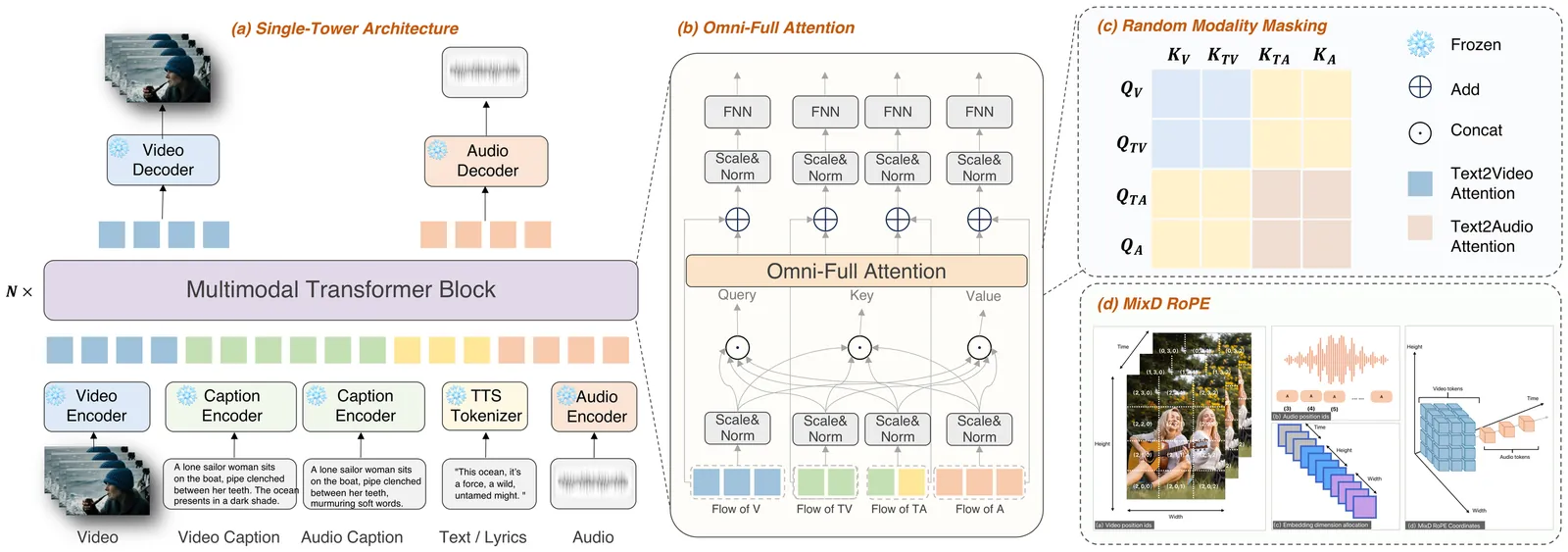
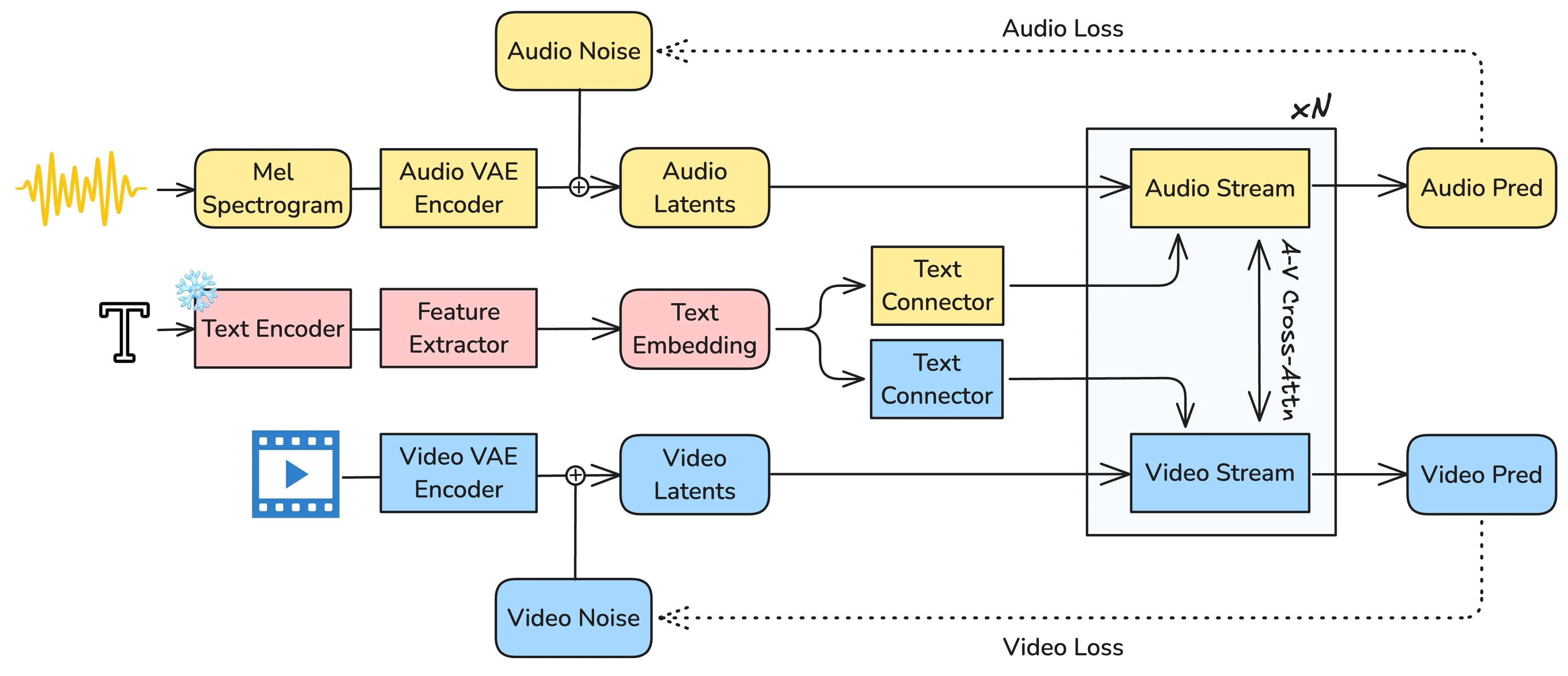
Audio-video joint generation has progressed rapidly, yet substantial challenges still remain. Non-commercial approaches still suffer audio-visual asynchrony, poor lip-speech alignment, and unimodal degradation, which can be stemmed from weak audio-visual correspondence modeling, limited generalization, and scarce high-quality dense-caption data. To address these issues, we introduce Klear and delve into three axes--model architecture, training strategy, and data curation. Architecturally, we adopt a single-tower design with unified DiT blocks and an Omni-Full Attention mechanism, achieving tight audio-visual alignment and strong scalability. Training-wise, we adopt a progressive multitask regime--random modality masking to joint optimization across tasks, and a multistage curriculum, yielding robust representations, strengthening A-V aligned world knowledge, and preventing unimodal collapse. For datasets, we present the first large-scale audio-video dataset with dense captions, and introduce a novel automated data-construction pipeline which annotates and filters millions of diverse, high-quality, strictly aligned audio-video-caption triplets. Building on this, Klear scales to large datasets, delivering high-fidelity, semantically and temporally aligned, instruction-following generation in both joint and unimodal settings while generalizing robustly to out-of-distribution scenarios. Across tasks, it substantially outperforms prior methods by a large margin and achieves performance comparable to Veo 3, offering a unified, scalable path toward next-generation audio-video synthesis.
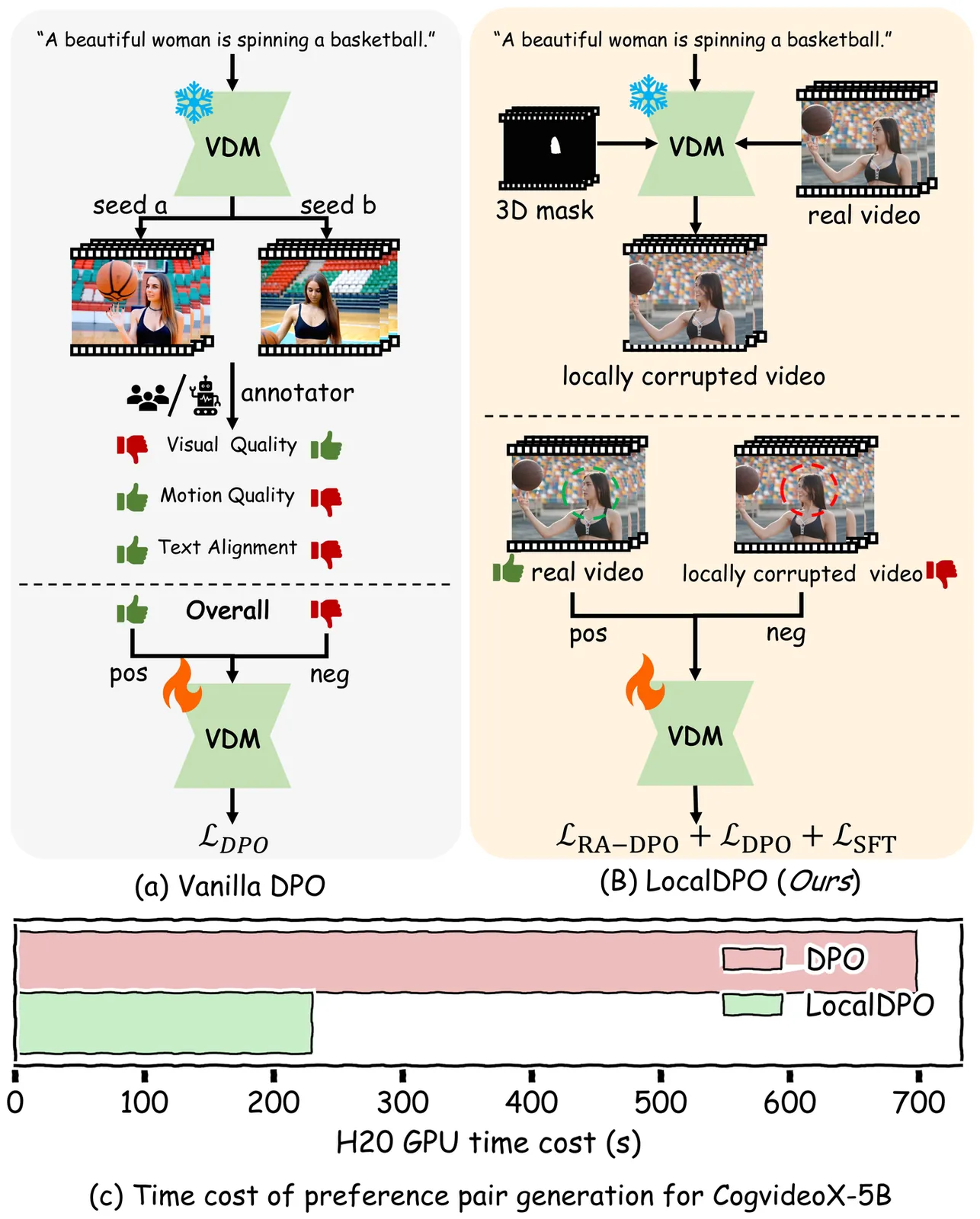
Aligning text-to-video diffusion models with human preferences is crucial for generating high-quality videos. Existing Direct Preference Otimization (DPO) methods rely on multi-sample ranking and task-specific critic models, which is inefficient and often yields ambiguous global supervision. To address these limitations, we propose LocalDPO, a novel post-training framework that constructs localized preference pairs from real videos and optimizes alignment at the spatio-temporal region level. We design an automated pipeline to efficiently collect preference pair data that generates preference pairs with a single inference per prompt, eliminating the need for external critic models or manual annotation. Specifically, we treat high-quality real videos as positive samples and generate corresponding negatives by locally corrupting them with random spatio-temporal masks and restoring only the masked regions using the frozen base model. During training, we introduce a region-aware DPO loss that restricts preference learning to corrupted areas for rapid convergence. Experiments on Wan2.1 and CogVideoX demonstrate that LocalDPO consistently improves video fidelity, temporal coherence and human preference scores over other post-training approaches, establishing a more efficient and fine-grained paradigm for video generator alignment.
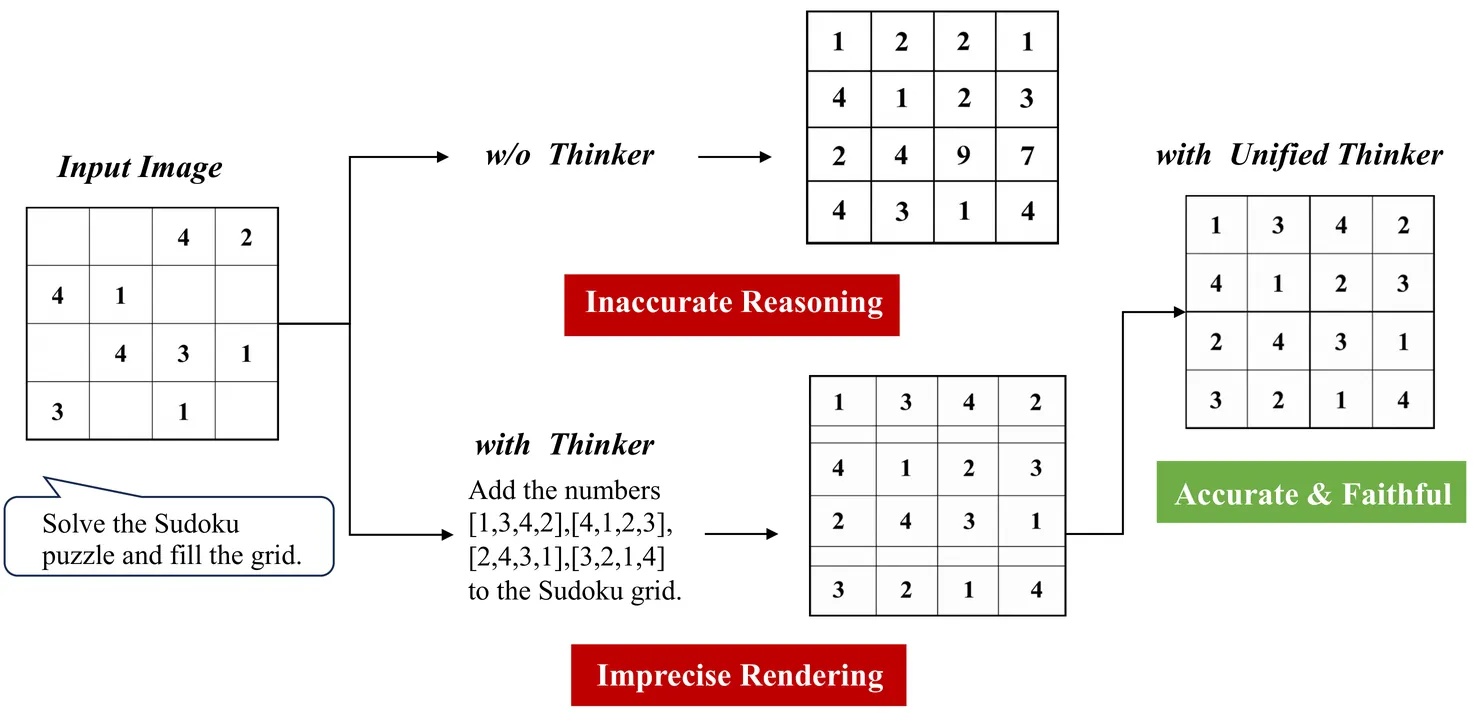
Despite impressive progress in high-fidelity image synthesis, generative models still struggle with logic-intensive instruction following, exposing a persistent reasoning--execution gap. Meanwhile, closed-source systems (e.g., Nano Banana) have demonstrated strong reasoning-driven image generation, highlighting a substantial gap to current open-source models. We argue that closing this gap requires not merely better visual generators, but executable reasoning: decomposing high-level intents into grounded, verifiable plans that directly steer the generative process. To this end, we propose Unified Thinker, a task-agnostic reasoning architecture for general image generation, designed as a unified planning core that can plug into diverse generators and workflows. Unified Thinker decouples a dedicated Thinker from the image Generator, enabling modular upgrades of reasoning without retraining the entire generative model. We further introduce a two-stage training paradigm: we first build a structured planning interface for the Thinker, then apply reinforcement learning to ground its policy in pixel-level feedback, encouraging plans that optimize visual correctness over textual plausibility. Extensive experiments on text-to-image generation and image editing show that Unified Thinker substantially improves image reasoning and generation quality.
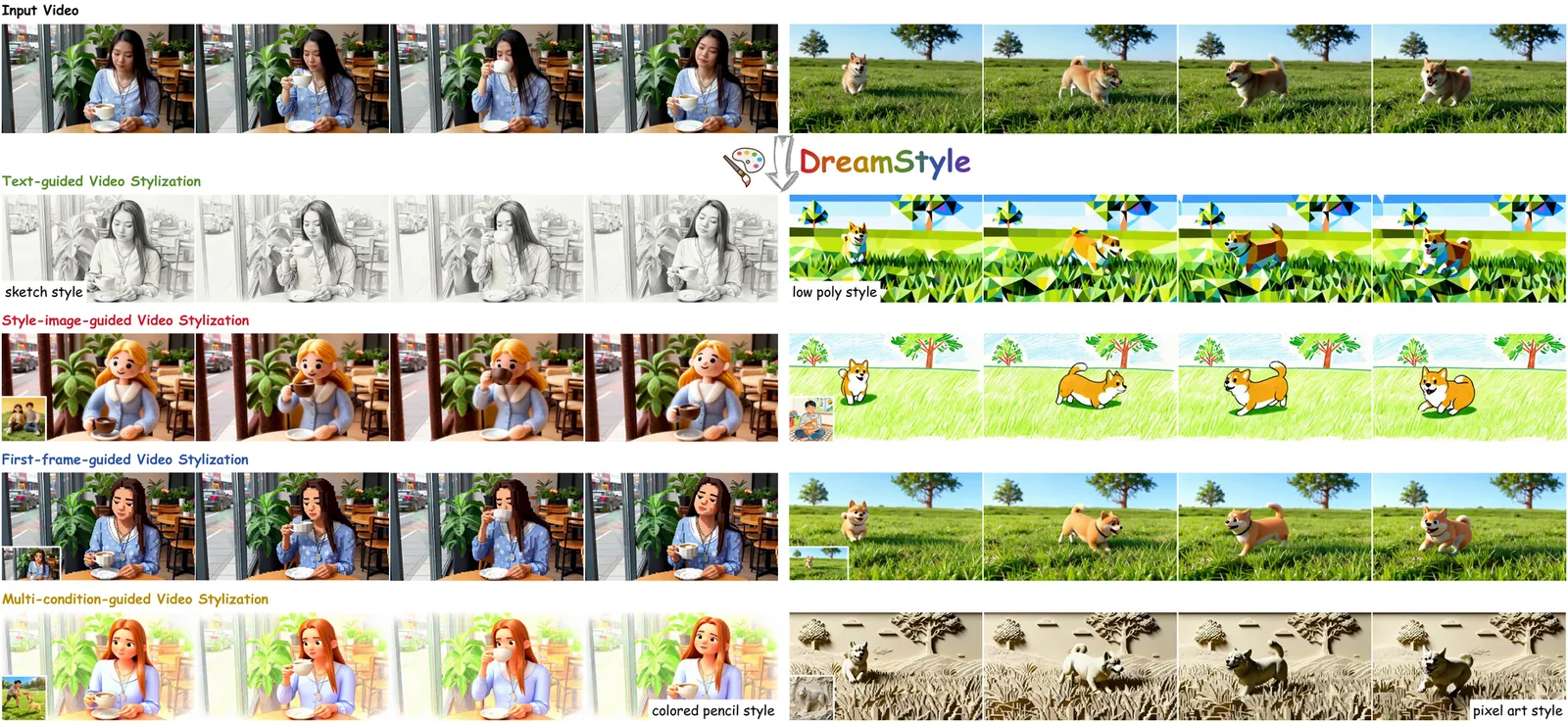
Video stylization, an important downstream task of video generation models, has not yet been thoroughly explored. Its input style conditions typically include text, style image, and stylized first frame. Each condition has a characteristic advantage: text is more flexible, style image provides a more accurate visual anchor, and stylized first frame makes long-video stylization feasible. However, existing methods are largely confined to a single type of style condition, which limits their scope of application. Additionally, their lack of high-quality datasets leads to style inconsistency and temporal flicker. To address these limitations, we introduce DreamStyle, a unified framework for video stylization, supporting (1) text-guided, (2) style-image-guided, and (3) first-frame-guided video stylization, accompanied by a well-designed data curation pipeline to acquire high-quality paired video data. DreamStyle is built on a vanilla Image-to-Video (I2V) model and trained using a Low-Rank Adaptation (LoRA) with token-specific up matrices that reduces the confusion among different condition tokens. Both qualitative and quantitative evaluations demonstrate that DreamStyle is competent in all three video stylization tasks, and outperforms the competitors in style consistency and video quality.
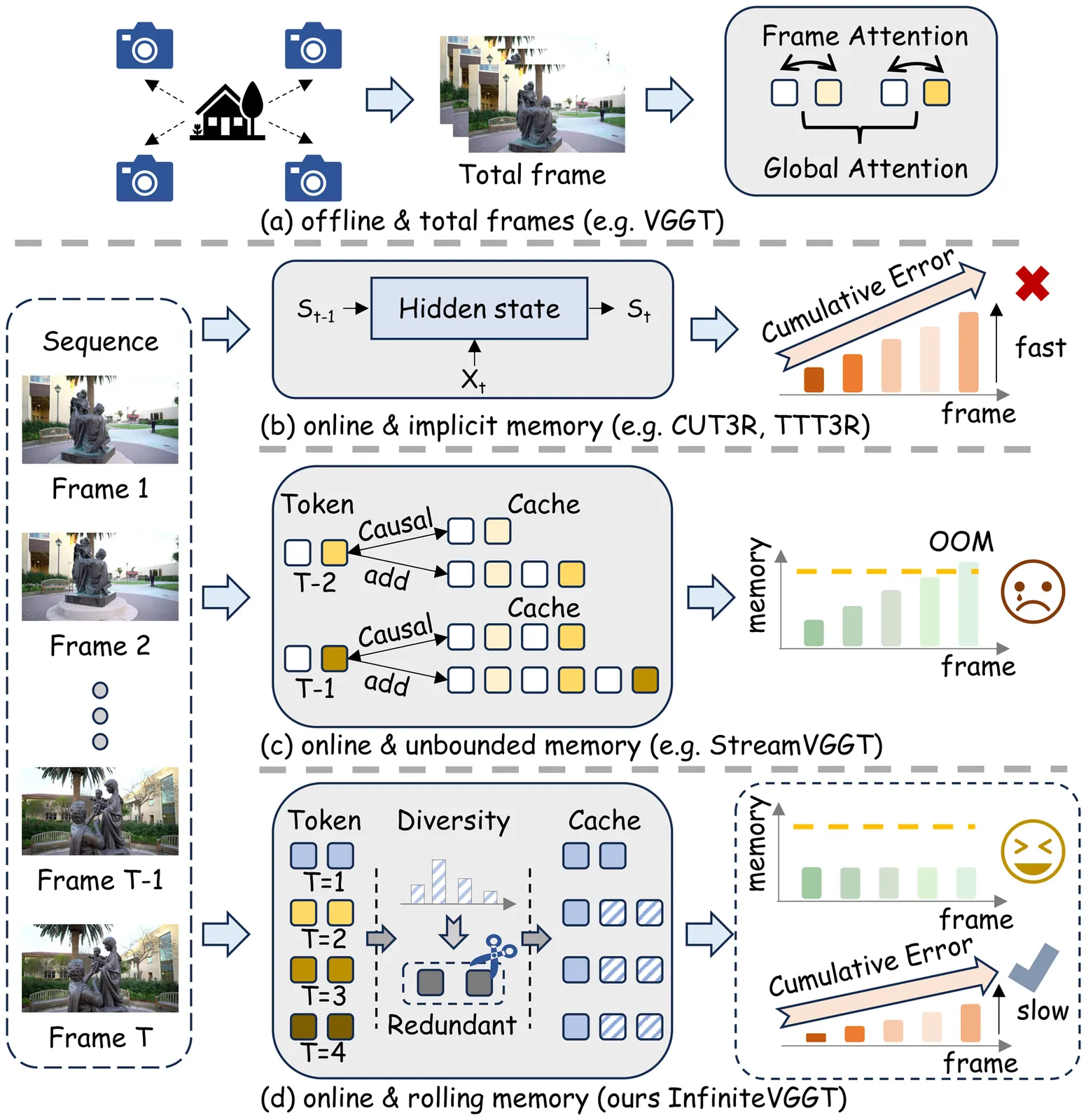
The grand vision of enabling persistent, large-scale 3D visual geometry understanding is shackled by the irreconcilable demands of scalability and long-term stability. While offline models like VGGT achieve inspiring geometry capability, their batch-based nature renders them irrelevant for live systems. Streaming architectures, though the intended solution for live operation, have proven inadequate. Existing methods either fail to support truly infinite-horizon inputs or suffer from catastrophic drift over long sequences. We shatter this long-standing dilemma with InfiniteVGGT, a causal visual geometry transformer that operationalizes the concept of a rolling memory through a bounded yet adaptive and perpetually expressive KV cache. Capitalizing on this, we devise a training-free, attention-agnostic pruning strategy that intelligently discards obsolete information, effectively ``rolling'' the memory forward with each new frame. Fully compatible with FlashAttention, InfiniteVGGT finally alleviates the compromise, enabling infinite-horizon streaming while outperforming existing streaming methods in long-term stability. The ultimate test for such a system is its performance over a truly infinite horizon, a capability that has been impossible to rigorously validate due to the lack of extremely long-term, continuous benchmarks. To address this critical gap, we introduce the Long3D benchmark, which, for the first time, enables a rigorous evaluation of continuous 3D geometry estimation on sequences about 10,000 frames. This provides the definitive evaluation platform for future research in long-term 3D geometry understanding. Code is available at: https://github.com/AutoLab-SAI-SJTU/InfiniteVGGT
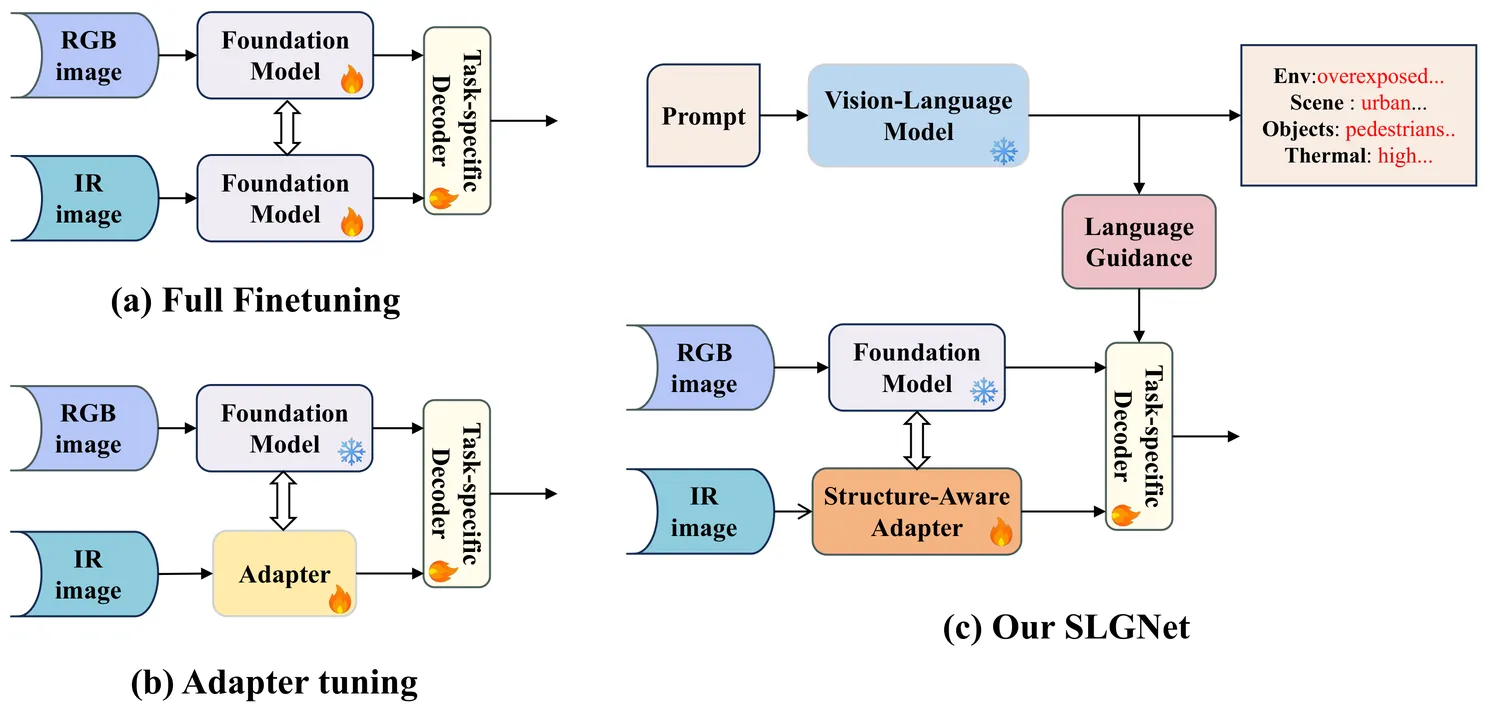
Multimodal object detection leveraging RGB and Infrared (IR) images is pivotal for robust perception in all-weather scenarios. While recent adapter-based approaches efficiently transfer RGB-pretrained foundation models to this task, they often prioritize model efficiency at the expense of cross-modal structural consistency. Consequently, critical structural cues are frequently lost when significant domain gaps arise, such as in high-contrast or nighttime environments. Moreover, conventional static multimodal fusion mechanisms typically lack environmental awareness, resulting in suboptimal adaptation and constrained detection performance under complex, dynamic scene variations. To address these limitations, we propose SLGNet, a parameter-efficient framework that synergizes hierarchical structural priors and language-guided modulation within a frozen Vision Transformer (ViT)-based foundation model. Specifically, we design a Structure-Aware Adapter to extract hierarchical structural representations from both modalities and dynamically inject them into the ViT to compensate for structural degradation inherent in ViT-based backbones. Furthermore, we propose a Language-Guided Modulation module that exploits VLM-driven structured captions to dynamically recalibrate visual features, thereby endowing the model with robust environmental awareness. Extensive experiments on the LLVIP, FLIR, KAIST, and DroneVehicle datasets demonstrate that SLGNet establishes new state-of-the-art performance. Notably, on the LLVIP benchmark, our method achieves an mAP of 66.1, while reducing trainable parameters by approximately 87% compared to traditional full fine-tuning. This confirms SLGNet as a robust and efficient solution for multimodal perception.
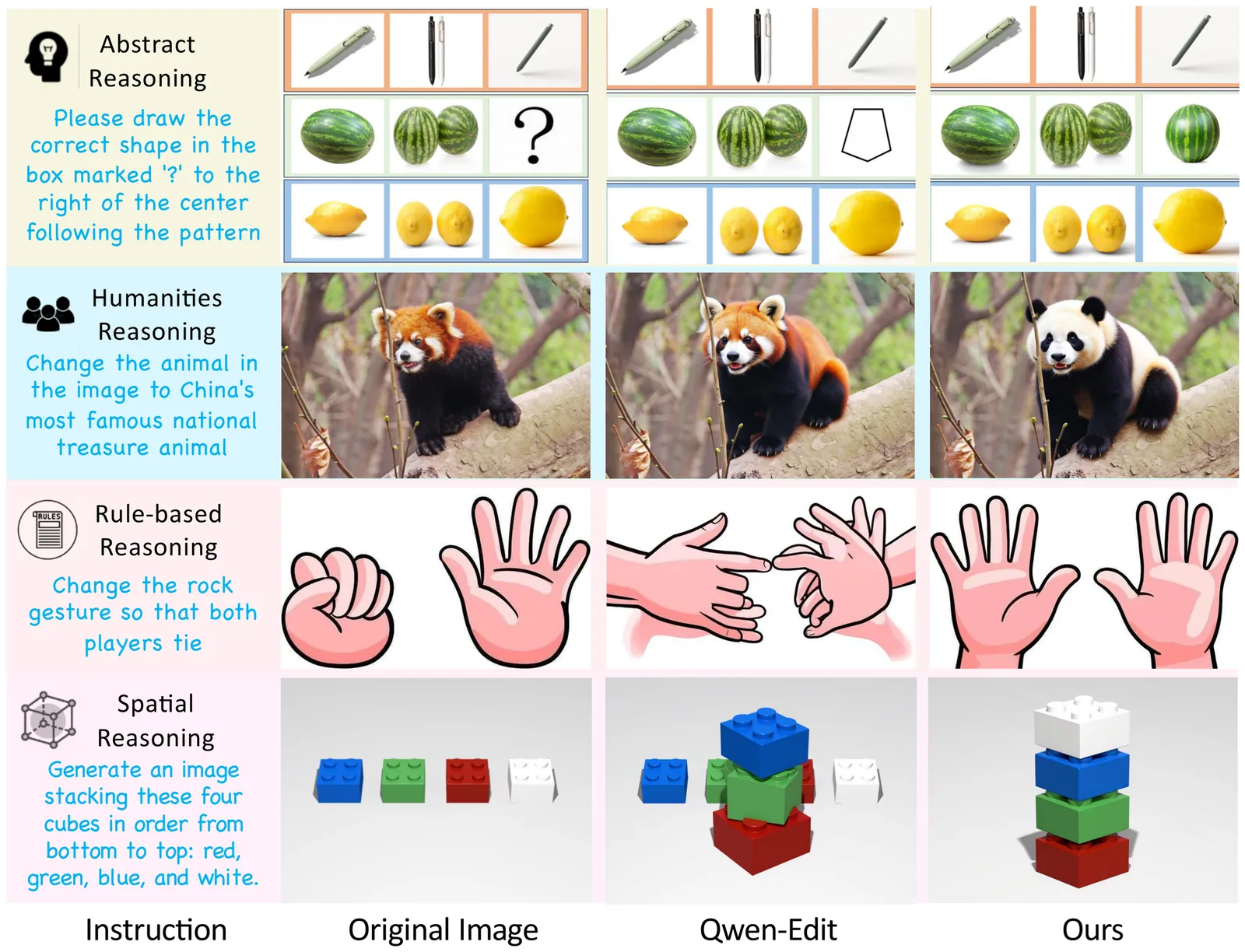
Instruction-driven image editing with unified multimodal generative models has advanced rapidly, yet their underlying visual reasoning remains limited, leading to suboptimal performance on reasoning-centric edits. Reinforcement learning (RL) has been investigated for improving the quality of image editing, but it faces three key challenges: (1) limited reasoning exploration confined to denoising stochasticity, (2) biased reward fusion, and (3) unstable VLM-based instruction rewards. In this work, we propose ThinkRL-Edit, a reasoning-centric RL framework that decouples visual reasoning from image synthesis and expands reasoning exploration beyond denoising. To the end, we introduce Chain-of-Thought (CoT)-based reasoning sampling with planning and reflection stages prior to generation in online sampling, compelling the model to explore multiple semantic hypotheses and validate their plausibility before committing to a visual outcome. To avoid the failures of weighted aggregation, we propose an unbiased chain preference grouping strategy across multiple reward dimensions. Moreover, we replace interval-based VLM scores with a binary checklist, yielding more precise, lower-variance, and interpretable rewards for complex reasoning. Experiments show our method significantly outperforms prior work on reasoning-centric image editing, producing instruction-faithful, visually coherent, and semantically grounded edits.
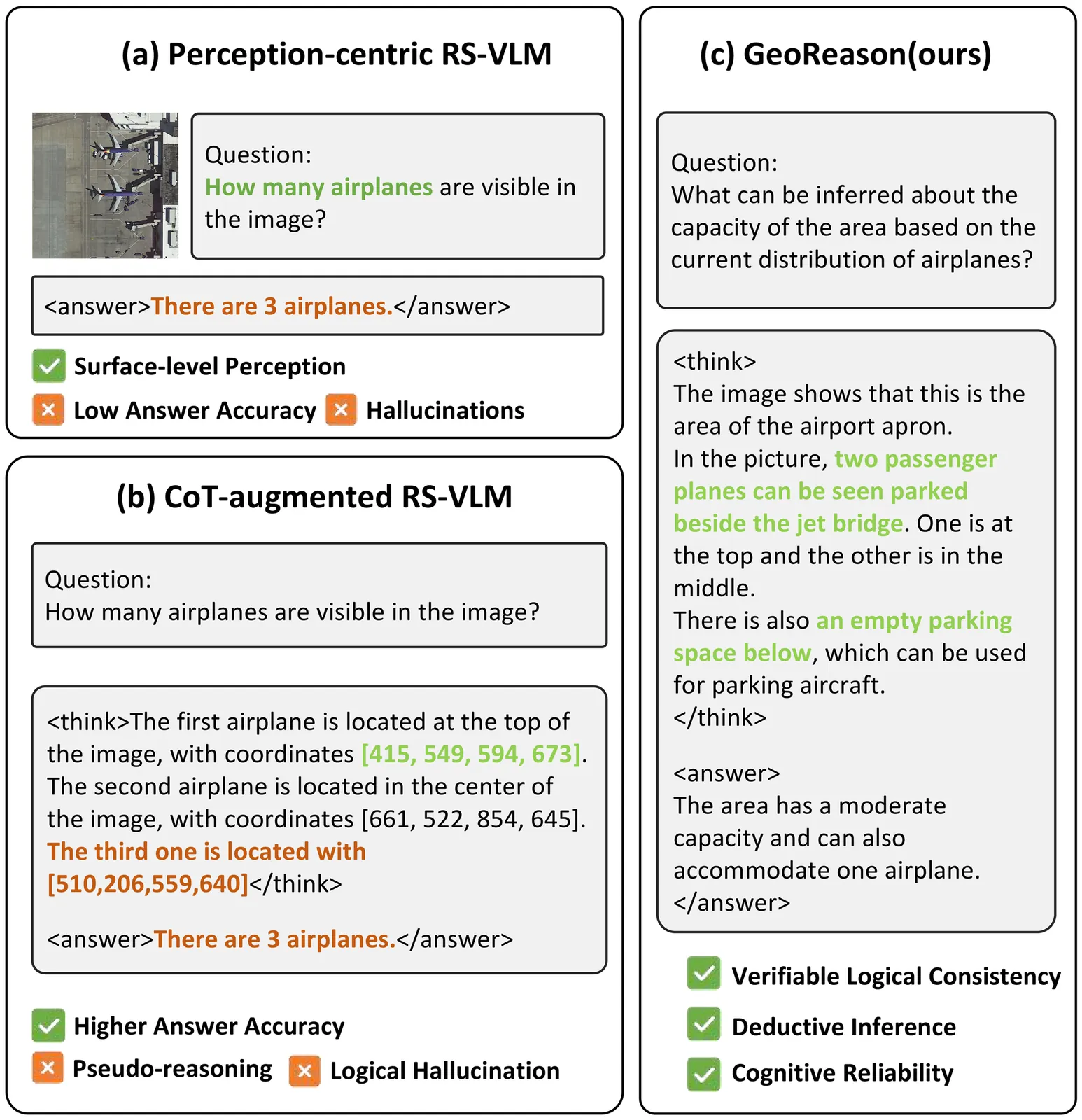
The evolution of Remote Sensing Vision-Language Models(RS-VLMs) emphasizes the importance of transitioning from perception-centric recognition toward high-level deductive reasoning to enhance cognitive reliability in complex spatial tasks. However, current models often suffer from logical hallucinations, where correct answers are derived from flawed reasoning chains or rely on positional shortcuts rather than spatial logic. This decoupling undermines reliability in strategic spatial decision-making. To address this, we present GeoReason, a framework designed to synchronize internal thinking with final decisions. We first construct GeoReason-Bench, a logic-driven dataset containing 4,000 reasoning trajectories synthesized from geometric primitives and expert knowledge. We then formulate a two-stage training strategy: (1) Supervised Knowledge Initialization to equip the model with reasoning syntax and domain expertise, and (2) Consistency-Aware Reinforcement Learning to refine deductive reliability. This second stage integrates a novel Logical Consistency Reward, which penalizes logical drift via an option permutation strategy to anchor decisions in verifiable reasoning traces. Experimental results demonstrate that our framework significantly enhances the cognitive reliability and interpretability of RS-VLMs, achieving state-of-the-art performance compared to other advanced methods.

Maintaining consistent characters, props, and environments across multiple shots is a central challenge in narrative video generation. Existing models can produce high-quality short clips but often fail to preserve entity identity and appearance when scenes change or when entities reappear after long temporal gaps. We present VideoMemory, an entity-centric framework that integrates narrative planning with visual generation through a Dynamic Memory Bank. Given a structured script, a multi-agent system decomposes the narrative into shots, retrieves entity representations from memory, and synthesizes keyframes and videos conditioned on these retrieved states. The Dynamic Memory Bank stores explicit visual and semantic descriptors for characters, props, and backgrounds, and is updated after each shot to reflect story-driven changes while preserving identity. This retrieval-update mechanism enables consistent portrayal of entities across distant shots and supports coherent long-form generation. To evaluate this setting, we construct a 54-case multi-shot consistency benchmark covering character-, prop-, and background-persistent scenarios. Extensive experiments show that VideoMemory achieves strong entity-level coherence and high perceptual quality across diverse narrative sequences.
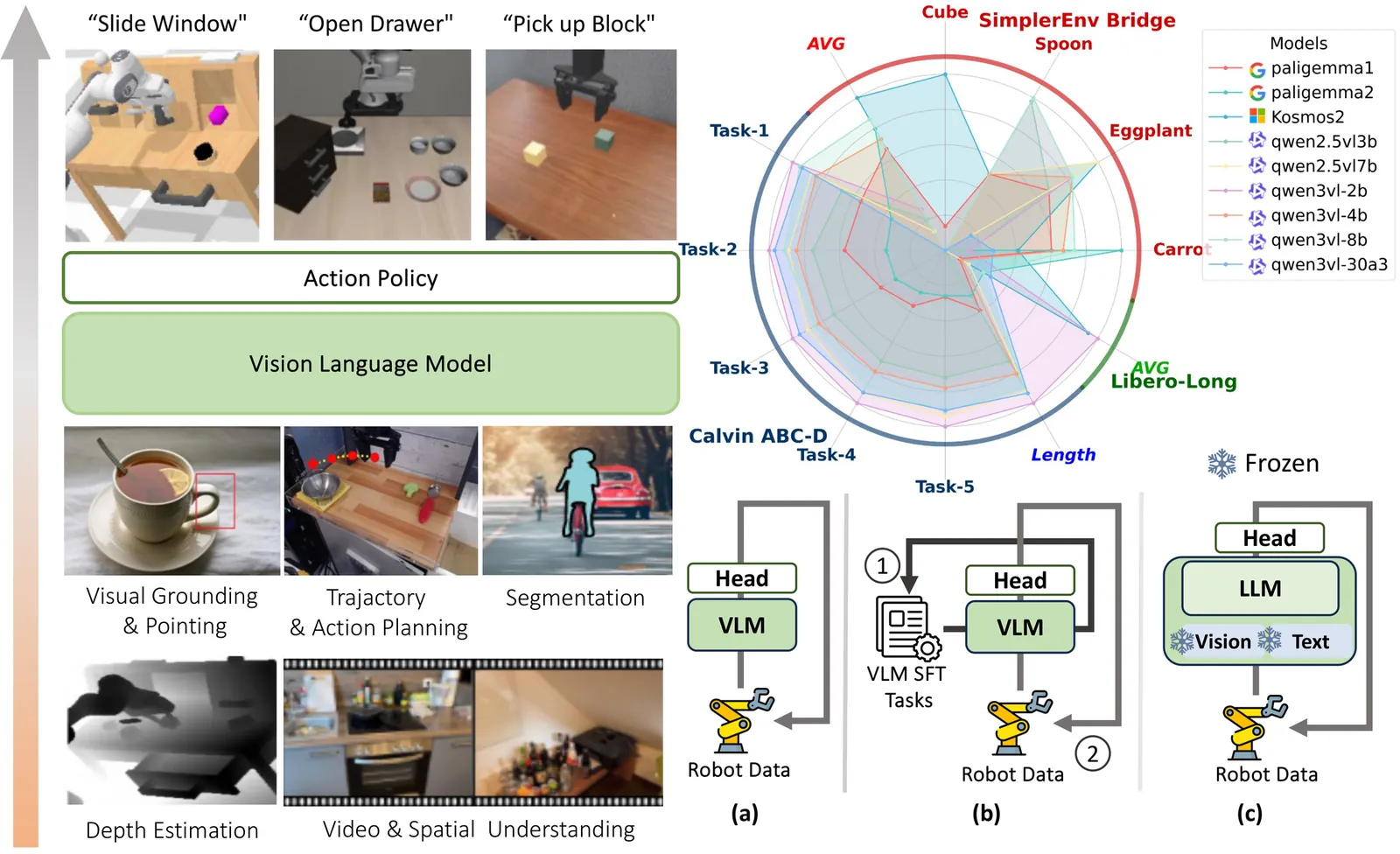
Vision-Language-Action (VLA) models, which integrate pretrained large Vision-Language Models (VLM) into their policy backbone, are gaining significant attention for their promising generalization capabilities. This paper revisits a fundamental yet seldom systematically studied question: how VLM choice and competence translate to downstream VLA policies performance? We introduce VLM4VLA, a minimal adaptation pipeline that converts general-purpose VLMs into VLA policies using only a small set of new learnable parameters for fair and efficient comparison. Despite its simplicity, VLM4VLA proves surprisingly competitive with more sophisticated network designs. Through extensive empirical studies on various downstream tasks across three benchmarks, we find that while VLM initialization offers a consistent benefit over training from scratch, a VLM's general capabilities are poor predictors of its downstream task performance. This challenges common assumptions, indicating that standard VLM competence is necessary but insufficient for effective embodied control. We further investigate the impact of specific embodied capabilities by fine-tuning VLMs on seven auxiliary embodied tasks (e.g., embodied QA, visual pointing, depth estimation). Contrary to intuition, improving a VLM's performance on specific embodied skills does not guarantee better downstream control performance. Finally, modality-level ablations identify the visual module in VLM, rather than the language component, as the primary performance bottleneck. We demonstrate that injecting control-relevant supervision into the vision encoder of the VLM yields consistent gains, even when the encoder remains frozen during downstream fine-tuning. This isolates a persistent domain gap between current VLM pretraining objectives and the requirements of embodied action-planning.

Monocular depth estimation aims to recover the depth information of 3D scenes from 2D images. Recent work has made significant progress, but its reliance on large-scale datasets and complex decoders has limited its efficiency and generalization ability. In this paper, we propose a lightweight and data-centric framework for zero-shot monocular depth estimation. We first adopt DINOv3 as the visual encoder to obtain high-quality dense features. Secondly, to address the inherent drawbacks of the complex structure of the DPT, we design the Simple Depth Transformer (SDT), a compact transformer-based decoder. Compared to the DPT, it uses a single-path feature fusion and upsampling process to reduce the computational overhead of cross-scale feature fusion, achieving higher accuracy while reducing the number of parameters by approximately 85%-89%. Furthermore, we propose a quality-based filtering strategy to filter out harmful samples, thereby reducing dataset size while improving overall training quality. Extensive experiments on five benchmarks demonstrate that our framework surpasses the DPT in accuracy. This work highlights the importance of balancing model design and data quality for achieving efficient and generalizable zero-shot depth estimation. Code: https://github.com/AIGeeksGroup/AnyDepth. Website: https://aigeeksgroup.github.io/AnyDepth.
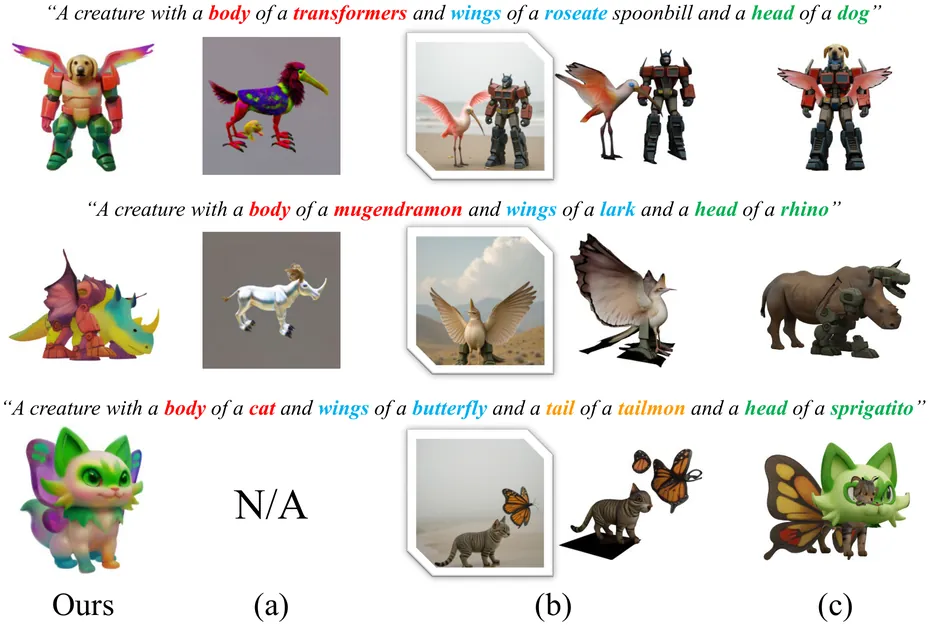
We present Muses, the first training-free method for fantastic 3D creature generation in a feed-forward paradigm. Previous methods, which rely on part-aware optimization, manual assembly, or 2D image generation, often produce unrealistic or incoherent 3D assets due to the challenges of intricate part-level manipulation and limited out-of-domain generation. In contrast, Muses leverages the 3D skeleton, a fundamental representation of biological forms, to explicitly and rationally compose diverse elements. This skeletal foundation formalizes 3D content creation as a structure-aware pipeline of design, composition, and generation. Muses begins by constructing a creatively composed 3D skeleton with coherent layout and scale through graph-constrained reasoning. This skeleton then guides a voxel-based assembly process within a structured latent space, integrating regions from different objects. Finally, image-guided appearance modeling under skeletal conditions is applied to generate a style-consistent and harmonious texture for the assembled shape. Extensive experiments establish Muses' state-of-the-art performance in terms of visual fidelity and alignment with textual descriptions, and potential on flexible 3D object editing. Project page: https://luhexiao.github.io/Muses.github.io/.