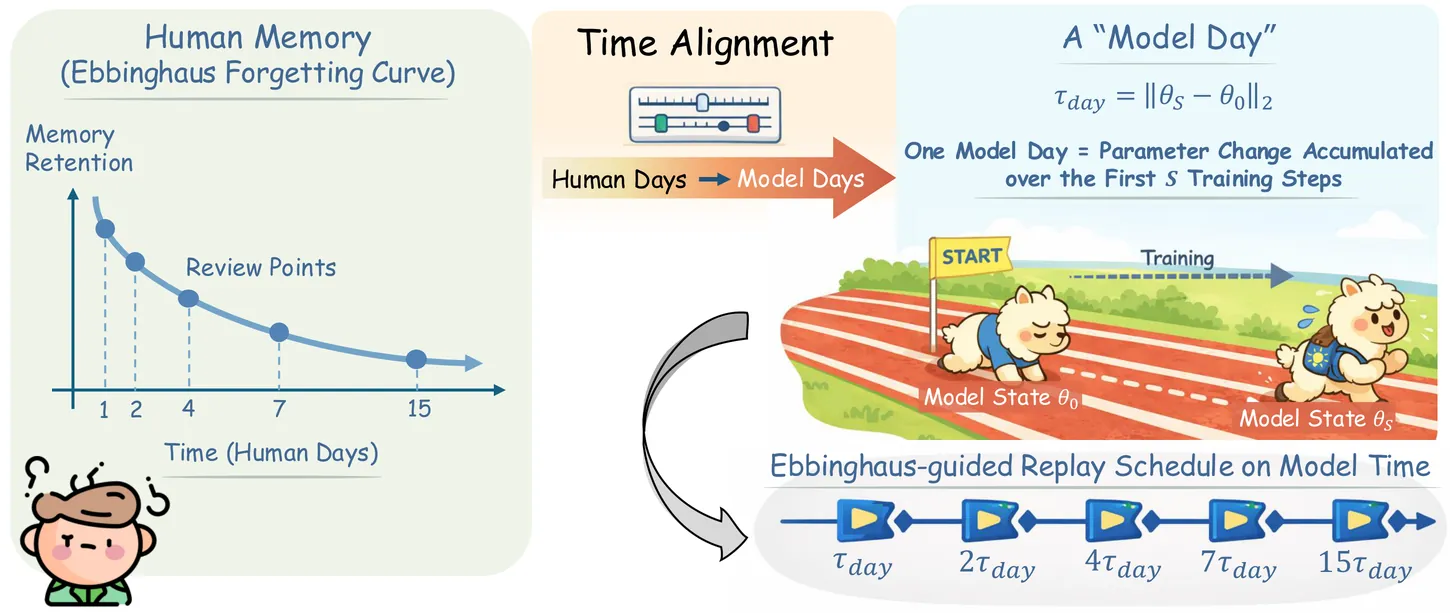
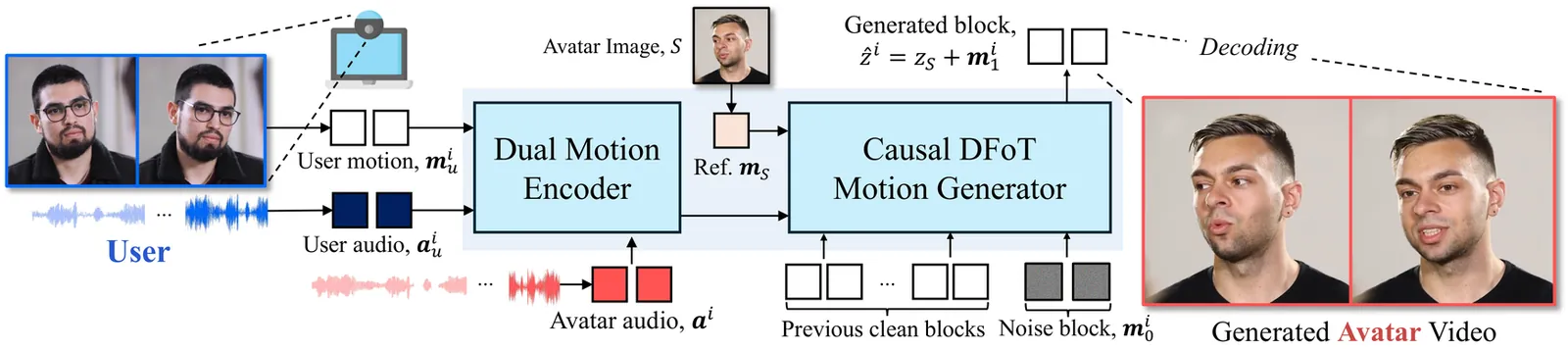
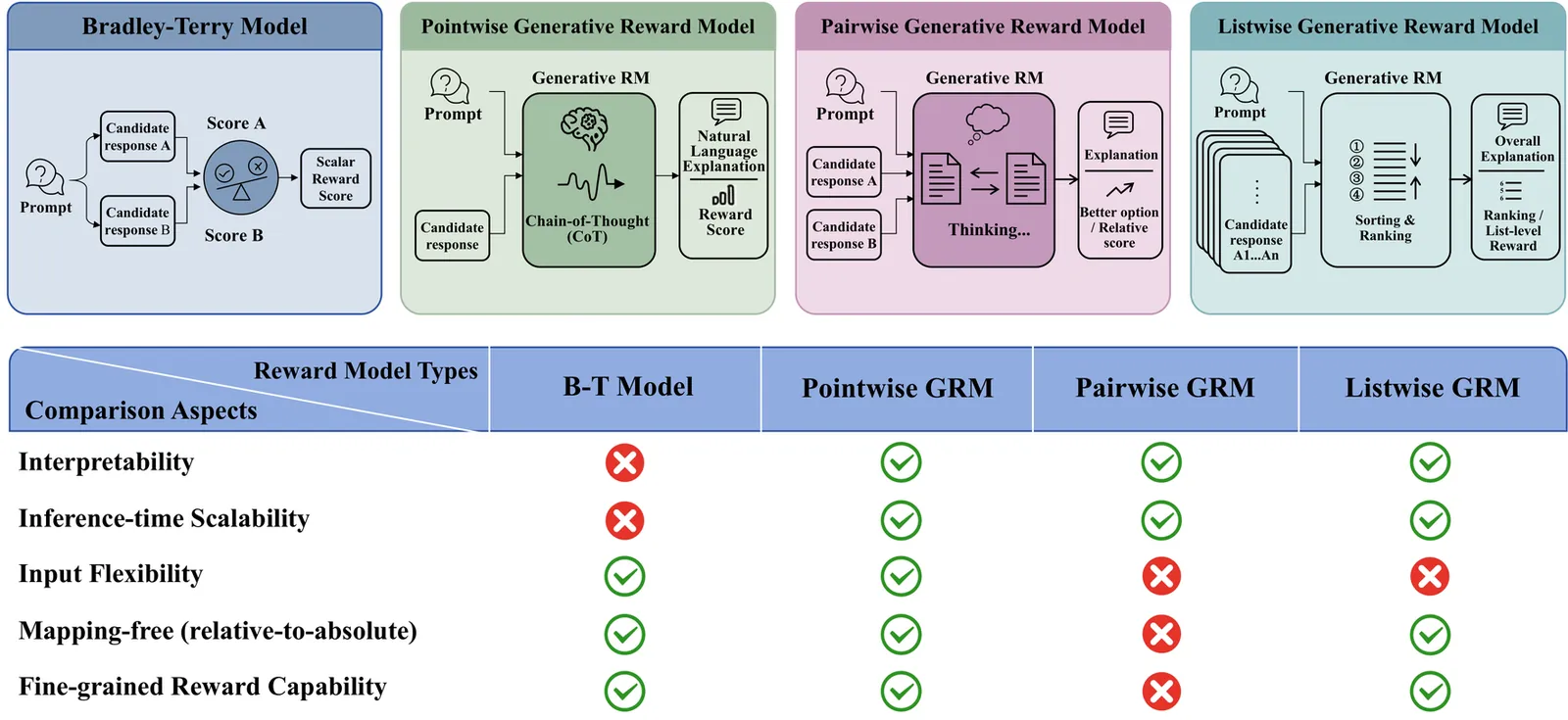
15,769 papers
Optimal Lower Bounds for Online Multicalibration
We prove tight lower bounds for online multicalibration, establishing an information-theoretic separation from marginal calibration. In the general setting where group functions can depend on both context and the learner's predictions, we prove an $Ω(T^{2/3})$ lower bound on expected multicalibration error using just three disjoint binary groups. This matches the upper bounds of Noarov et al. (2025) up to logarithmic factors and exceeds the $O(T^{2/3-\varepsilon})$ upper bound for marginal calibration (Dagan et al., 2025), thereby separating the two problems. We then turn to lower bounds for the more difficult case of group functions that may depend on context but not on the learner's predictions. In this case, we establish an $\widetildeΩ(T^{2/3})$ lower bound for online multicalibration via a $Θ(T)$-sized group family constructed using orthogonal function systems, again matching upper bounds up to logarithmic factors.
2601.05245Jan 2026
View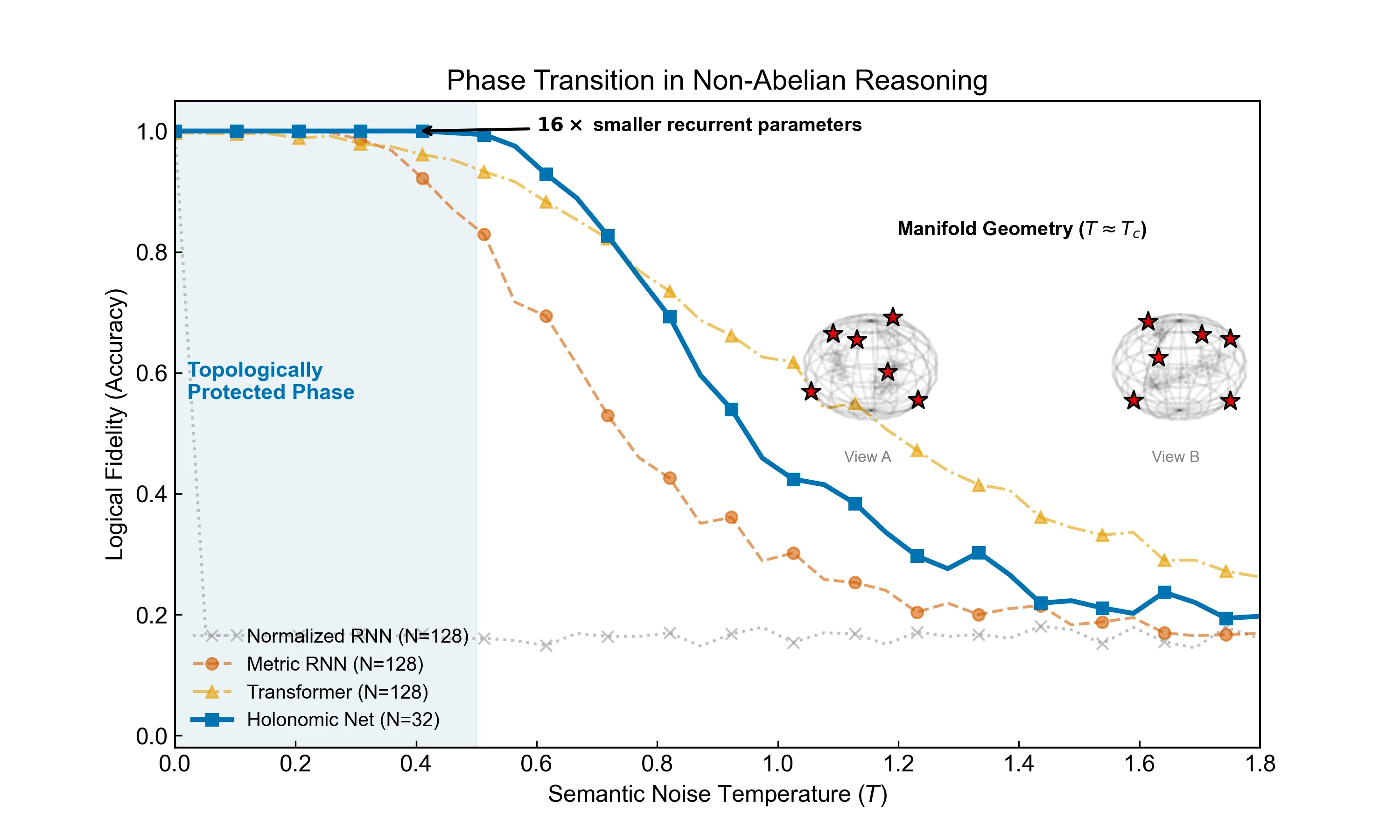
Robust Reasoning as a Symmetry-Protected Topological Phase
Large language models suffer from "hallucinations"-logical inconsistencies induced by semantic noise. We propose that current architectures operate in a "Metric Phase," where causal order is vulnerable to spontaneous symmetry breaking. Here, we identify robust inference as an effective Symmetry-Protected Topological phase, where logical operations are formally isomorphic to non-Abelian anyon braiding, replacing fragile geometric interpolation with robust topological invariants. Empirically, we demonstrate a sharp topological phase transition: while Transformers and RNNs exhibit gapless decay, our Holonomic Network reveals a macroscopic "mass gap," maintaining invariant fidelity below a critical noise threshold. Furthermore, in a variable-binding task on $S_{10}$ ($3.6 \times 10^6$ states) representing symbolic manipulation, we demonstrate holonomic generalization: the topological model maintains perfect fidelity extrapolating $100\times$ beyond training ($L=50 \to 5000$), consistent with a theoretically indefinite causal horizon, whereas Transformers lose logical coherence. Ablation studies indicate this protection emerges strictly from non-Abelian gauge symmetry. This provides strong evidence for a new universality class for logical reasoning, linking causal stability to the topology of the semantic manifold.
2601.05240Jan 2026
View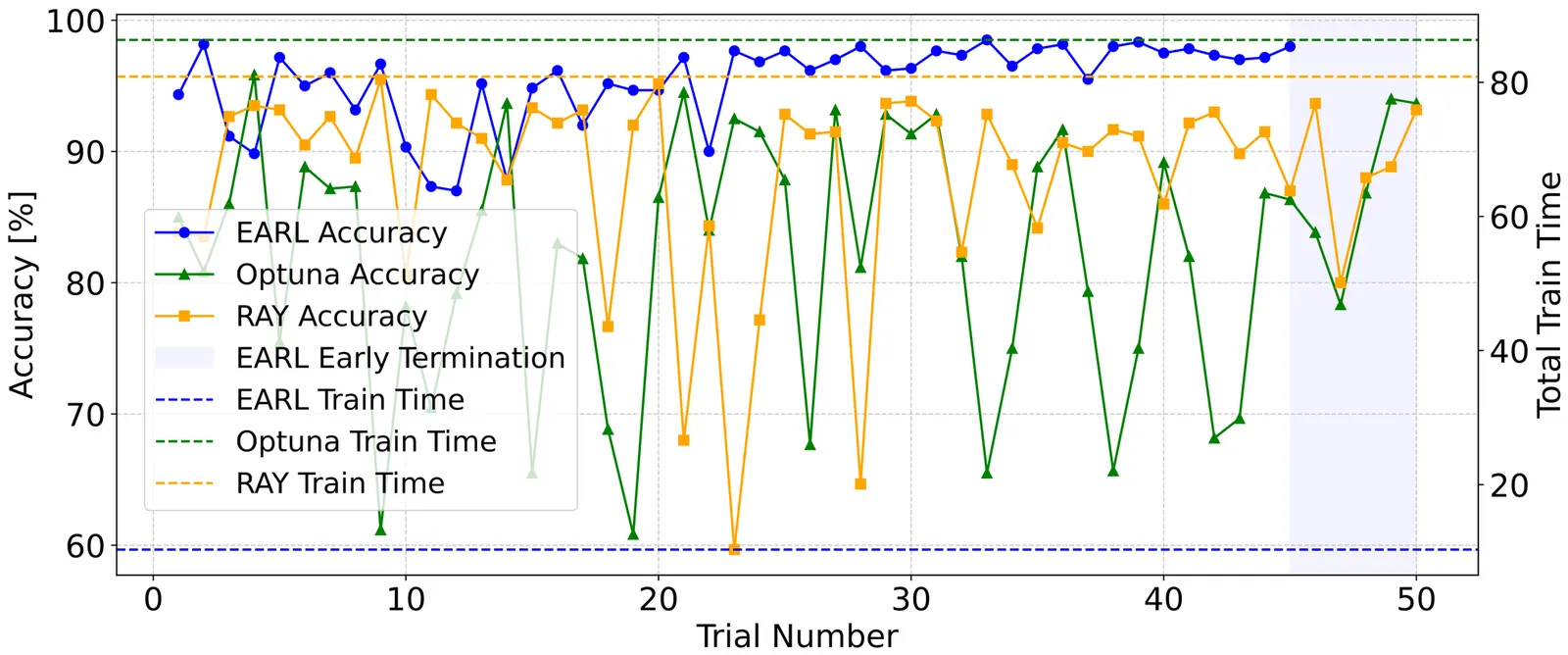
EARL: Energy-Aware Optimization of Liquid State Machines for Pervasive AI
Pervasive AI increasingly depends on on-device learning systems that deliver low-latency and energy-efficient computation under strict resource constraints. Liquid State Machines (LSMs) offer a promising approach for low-power temporal processing in pervasive and neuromorphic systems, but their deployment remains challenging due to high hyperparameter sensitivity and the computational cost of traditional optimization methods that ignore energy constraints. This work presents EARL, an energy-aware reinforcement learning framework that integrates Bayesian optimization with an adaptive reinforcement learning based selection policy to jointly optimize accuracy and energy consumption. EARL employs surrogate modeling for global exploration, reinforcement learning for dynamic candidate prioritization, and an early termination mechanism to eliminate redundant evaluations, substantially reducing computational overhead. Experiments on three benchmark datasets demonstrate that EARL achieves 6 to 15 percent higher accuracy, 60 to 80 percent lower energy consumption, and up to an order of magnitude reduction in optimization time compared to leading hyperparameter tuning frameworks. These results highlight the effectiveness of energy-aware adaptive search in improving the efficiency and scalability of LSMs for resource-constrained on-device AI applications.
2601.05205Jan 2026
View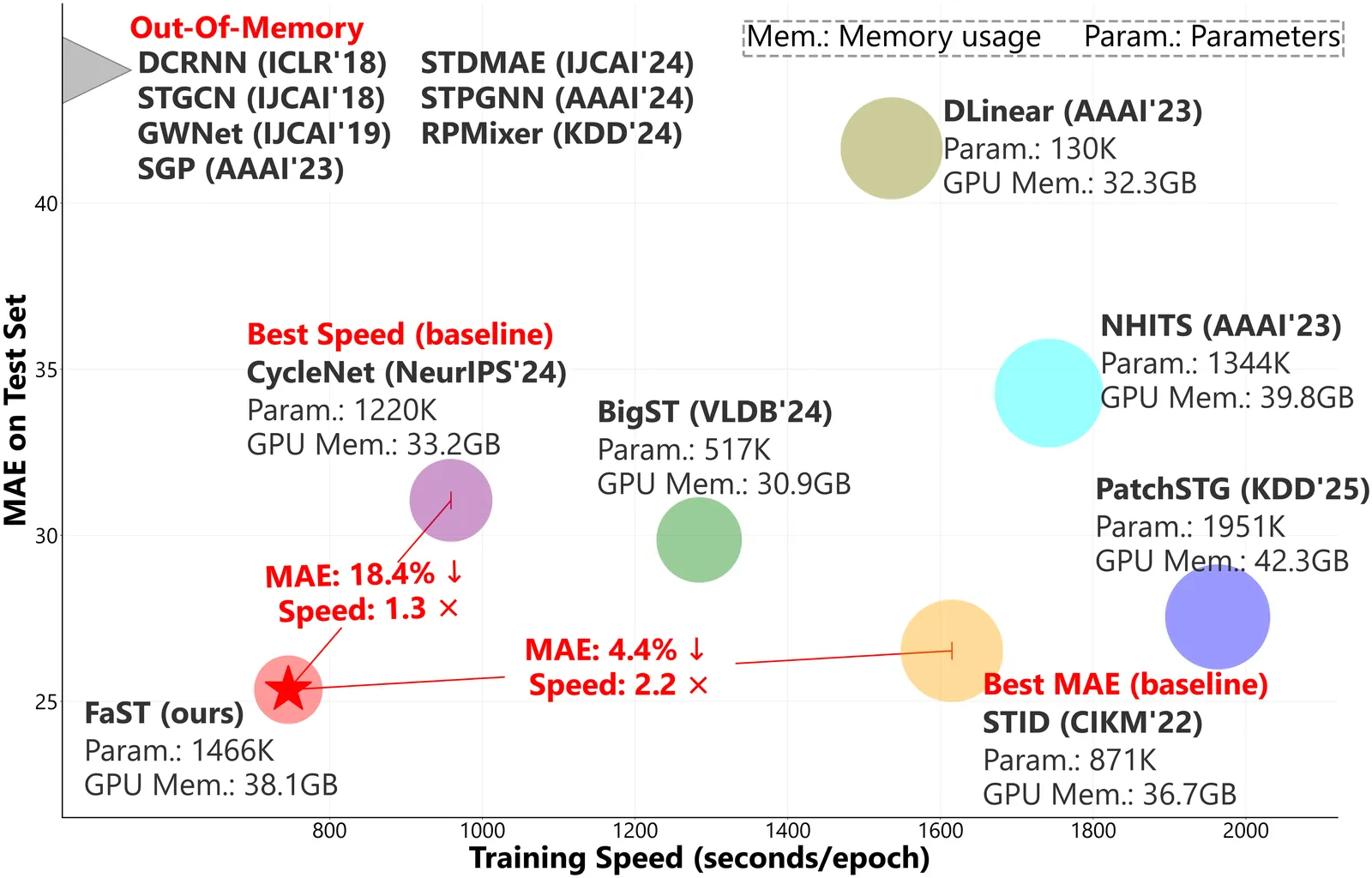
FaST: Efficient and Effective Long-Horizon Forecasting for Large-Scale Spatial-Temporal Graphs via Mixture-of-Experts
Spatial-Temporal Graph (STG) forecasting on large-scale networks has garnered significant attention. However, existing models predominantly focus on short-horizon predictions and suffer from notorious computational costs and memory consumption when scaling to long-horizon predictions and large graphs. Targeting the above challenges, we present FaST, an effective and efficient framework based on heterogeneity-aware Mixture-of-Experts (MoEs) for long-horizon and large-scale STG forecasting, which unlocks one-week-ahead (672 steps at a 15-minute granularity) prediction with thousands of nodes. FaST is underpinned by two key innovations. First, an adaptive graph agent attention mechanism is proposed to alleviate the computational burden inherent in conventional graph convolution and self-attention modules when applied to large-scale graphs. Second, we propose a new parallel MoE module that replaces traditional feed-forward networks with Gated Linear Units (GLUs), enabling an efficient and scalable parallel structure. Extensive experiments on real-world datasets demonstrate that FaST not only delivers superior long-horizon predictive accuracy but also achieves remarkable computational efficiency compared to state-of-the-art baselines. Our source code is available at: https://github.com/yijizhao/FaST.
2601.05174Jan 2026
ViewSafe Continual Reinforcement Learning Methods for Nonstationary Environments. Towards a Survey of the State of the Art
This work provides a state-of-the-art survey of continual safe online reinforcement learning (COSRL) methods. We discuss theoretical aspects, challenges, and open questions in building continual online safe reinforcement learning algorithms. We provide the taxonomy and the details of continual online safe reinforcement learning methods based on the type of safe learning mechanism that takes adaptation to nonstationarity into account. We categorize safety constraints formulation for online reinforcement learning algorithms, and finally, we discuss prospects for creating reliable, safe online learning algorithms. Keywords: safe RL in nonstationary environments, safe continual reinforcement learning under nonstationarity, HM-MDP, NSMDP, POMDP, safe POMDP, constraints for continual learning, safe continual reinforcement learning review, safe continual reinforcement learning survey, safe continual reinforcement learning, safe online learning under distribution shift, safe continual online adaptation, safe reinforcement learning, safe exploration, safe adaptation, constrained Markov decision processes, safe reinforcement learning, partially observable Markov decision process, safe reinforcement learning and hidden Markov decision processes, Safe Online Reinforcement Learning, safe online reinforcement learning, safe online reinforcement learning, safe meta-learning, safe meta-reinforcement learning, safe context-based reinforcement learning, formulating safety constraints for continual learning
2601.05152Jan 2026
View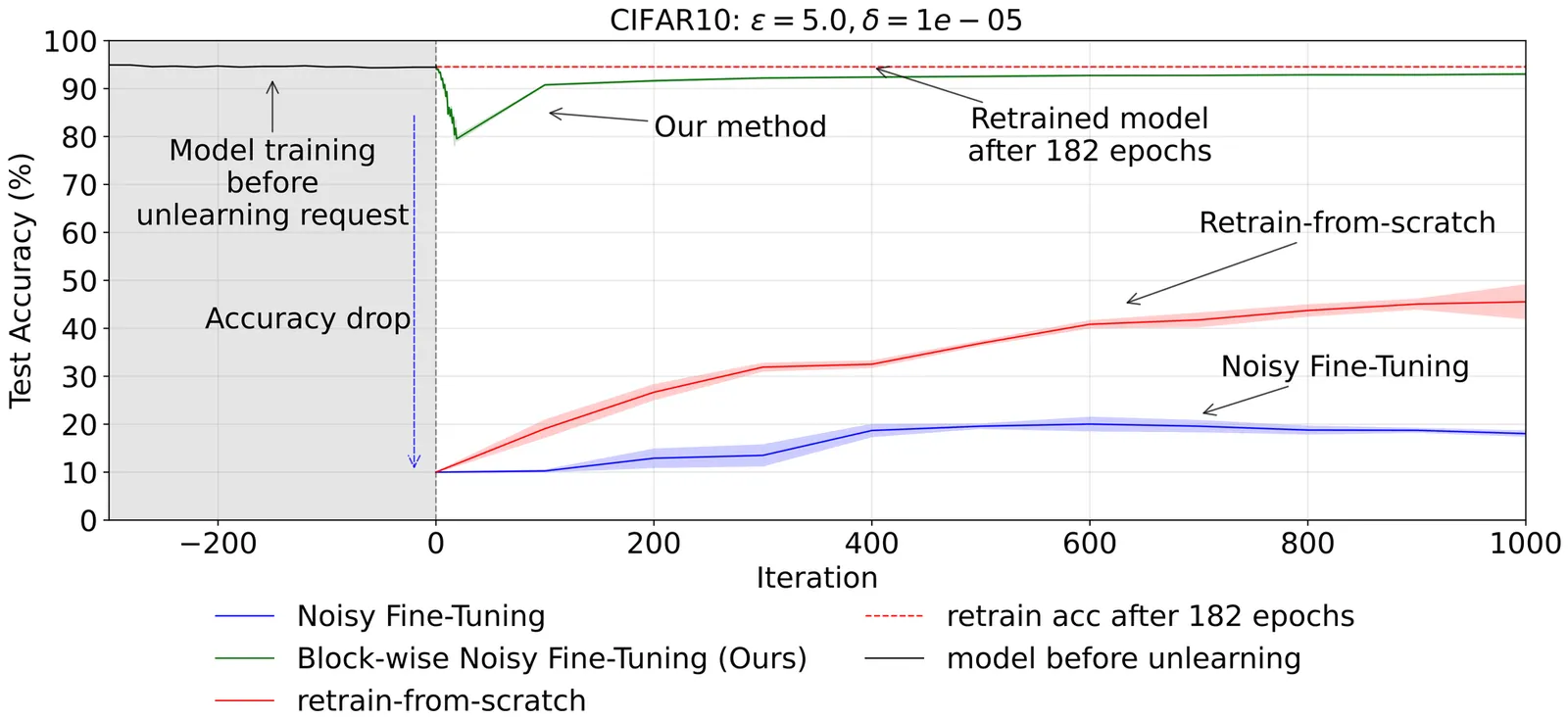
Sequential Subspace Noise Injection Prevents Accuracy Collapse in Certified Unlearning
Certified unlearning based on differential privacy offers strong guarantees but remains largely impractical: the noisy fine-tuning approaches proposed so far achieve these guarantees but severely reduce model accuracy. We propose sequential noise scheduling, which distributes the noise budget across orthogonal subspaces of the parameter space, rather than injecting it all at once. This simple modification mitigates the destructive effect of noise while preserving the original certification guarantees. We extend the analysis of noisy fine-tuning to the subspace setting, proving that the same $(\varepsilon,δ)$ privacy budget is retained. Empirical results on image classification benchmarks show that our approach substantially improves accuracy after unlearning while remaining robust to membership inference attacks. These results show that certified unlearning can achieve both rigorous guarantees and practical utility.
2601.05134Jan 2026
View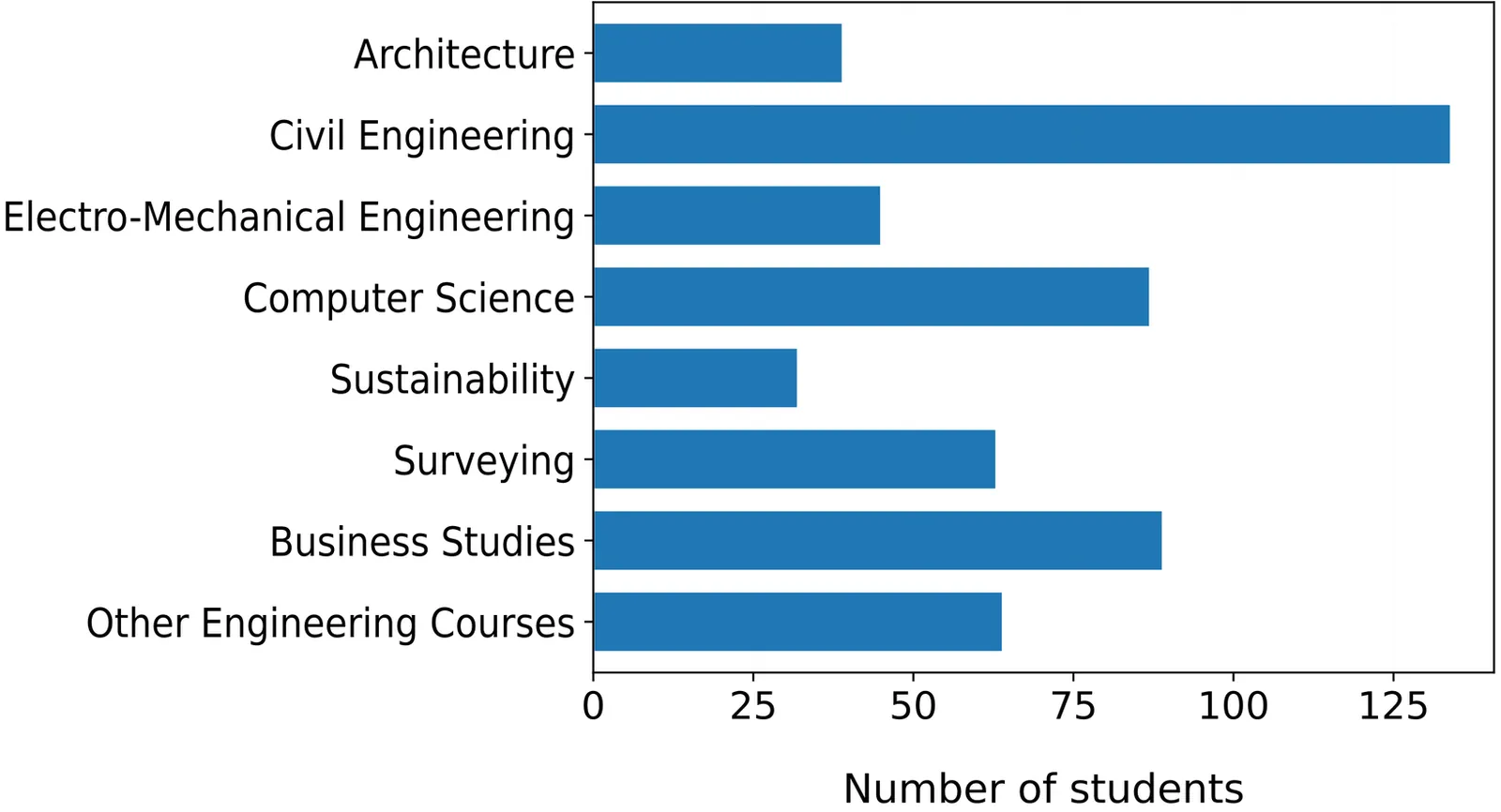
Exploring Student Expectations and Confidence in Learning Analytics
Learning Analytics (LA) is nowadays ubiquitous in many educational systems, providing the ability to collect and analyze student data in order to understand and optimize learning and the environments in which it occurs. On the other hand, the collection of data requires to comply with the growing demand regarding privacy legislation. In this paper, we use the Student Expectation of Learning Analytics Questionnaire (SELAQ) to analyze the expectations and confidence of students from different faculties regarding the processing of their data for Learning Analytics purposes. This allows us to identify four clusters of students through clustering algorithms: Enthusiasts, Realists, Cautious and Indifferents. This structured analysis provides valuable insights into the acceptance and criticism of Learning Analytics among students.
2601.05082Jan 2026
View
Milestones over Outcome: Unlocking Geometric Reasoning with Sub-Goal Verifiable Reward
Multimodal Large Language Models (MLLMs) struggle with complex geometric reasoning, largely because "black box" outcome-based supervision fails to distinguish between lucky guesses and rigorous deduction. To address this, we introduce a paradigm shift towards subgoal-level evaluation and learning. We first construct GeoGoal, a benchmark synthesized via a rigorous formal verification data engine, which converts abstract proofs into verifiable numeric subgoals. This structure reveals a critical divergence between reasoning quality and outcome accuracy. Leveraging this, we propose the Sub-Goal Verifiable Reward (SGVR) framework, which replaces sparse signals with dense rewards based on the Skeleton Rate. Experiments demonstrate that SGVR not only enhances geometric performance (+9.7%) but also exhibits strong generalization, transferring gains to general math (+8.0%) and other general reasoning tasks (+2.8%), demonstrating broad applicability across diverse domains.
2601.05073Jan 2026
View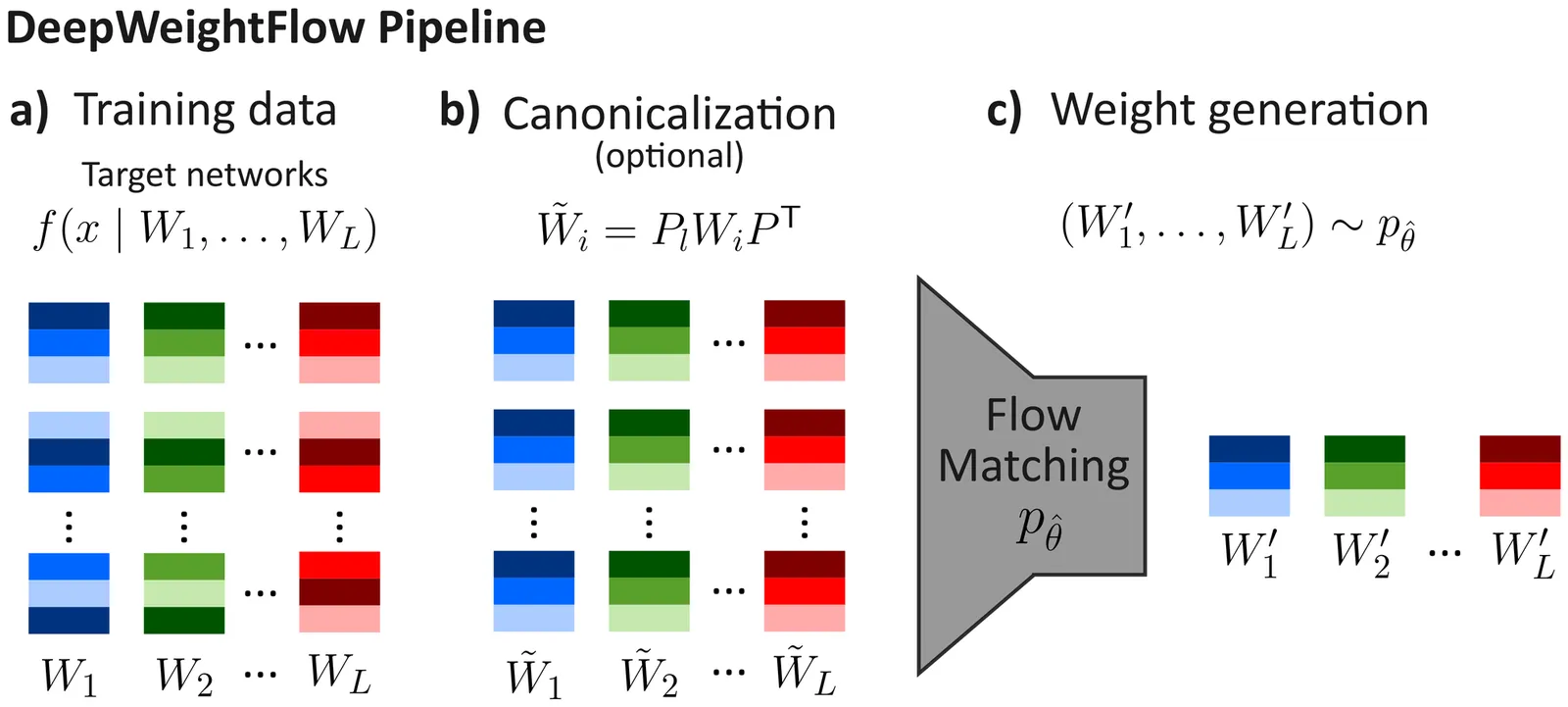
DeepWeightFlow: Re-Basined Flow Matching for Generating Neural Network Weights
Building efficient and effective generative models for neural network weights has been a research focus of significant interest that faces challenges posed by the high-dimensional weight spaces of modern neural networks and their symmetries. Several prior generative models are limited to generating partial neural network weights, particularly for larger models, such as ResNet and ViT. Those that do generate complete weights struggle with generation speed or require finetuning of the generated models. In this work, we present DeepWeightFlow, a Flow Matching model that operates directly in weight space to generate diverse and high-accuracy neural network weights for a variety of architectures, neural network sizes, and data modalities. The neural networks generated by DeepWeightFlow do not require fine-tuning to perform well and can scale to large networks. We apply Git Re-Basin and TransFusion for neural network canonicalization in the context of generative weight models to account for the impact of neural network permutation symmetries and to improve generation efficiency for larger model sizes. The generated networks excel at transfer learning, and ensembles of hundreds of neural networks can be generated in minutes, far exceeding the efficiency of diffusion-based methods. DeepWeightFlow models pave the way for more efficient and scalable generation of diverse sets of neural networks.
2601.05052Jan 2026
View
Approximate equivariance via projection-based regularisation
Equivariance is a powerful inductive bias in neural networks, improving generalisation and physical consistency. Recently, however, non-equivariant models have regained attention, due to their better runtime performance and imperfect symmetries that might arise in real-world applications. This has motivated the development of approximately equivariant models that strike a middle ground between respecting symmetries and fitting the data distribution. Existing approaches in this field usually apply sample-based regularisers which depend on data augmentation at training time, incurring a high sample complexity, in particular for continuous groups such as $SO(3)$. This work instead approaches approximate equivariance via a projection-based regulariser which leverages the orthogonal decomposition of linear layers into equivariant and non-equivariant components. In contrast to existing methods, this penalises non-equivariance at an operator level across the full group orbit, rather than point-wise. We present a mathematical framework for computing the non-equivariance penalty exactly and efficiently in both the spatial and spectral domain. In our experiments, our method consistently outperforms prior approximate equivariance approaches in both model performance and efficiency, achieving substantial runtime gains over sample-based regularisers.
2601.05028Jan 2026
View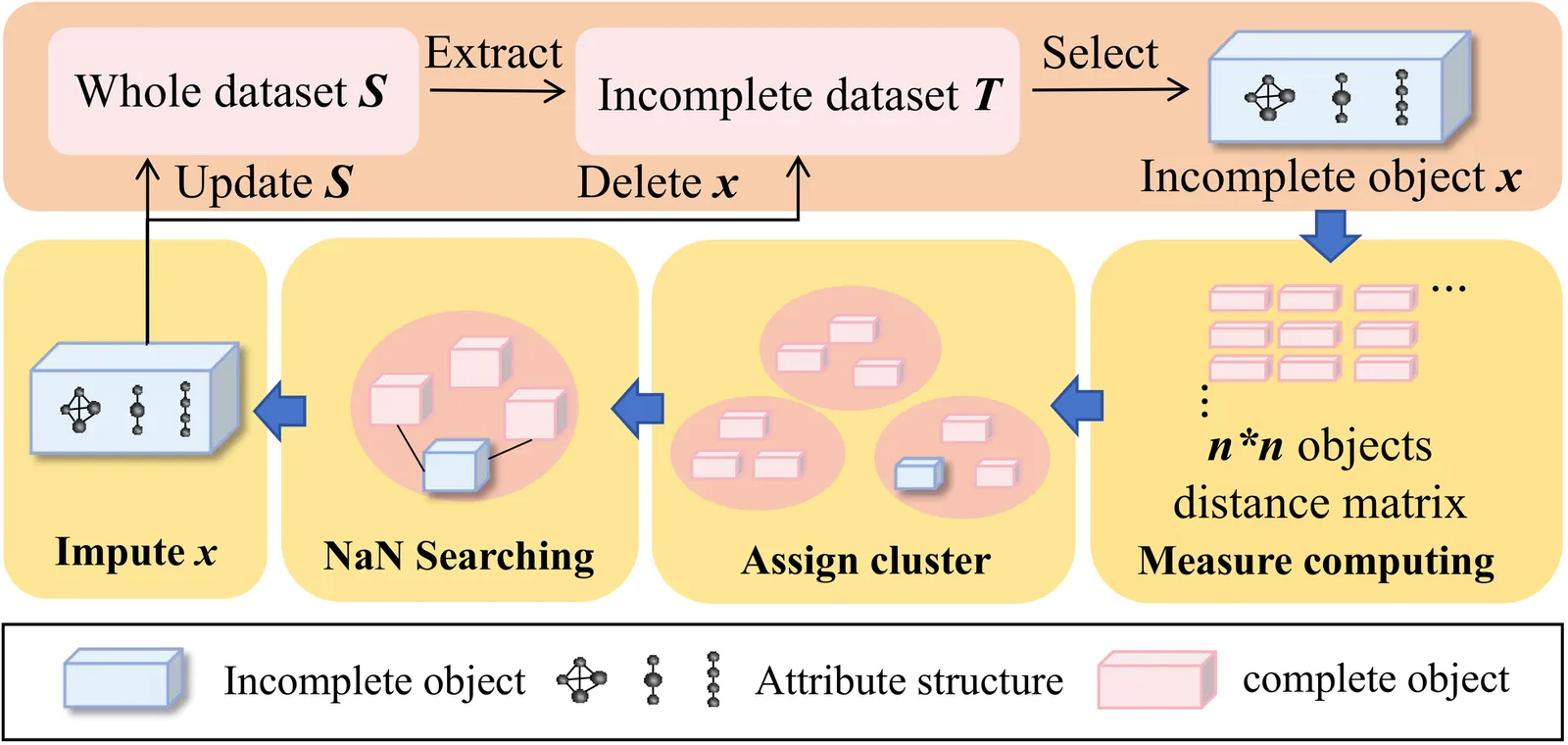
HMVI: Unifying Heterogeneous Attributes with Natural Neighbors for Missing Value Inference
Missing value imputation is a fundamental challenge in machine intelligence, heavily dependent on data completeness. Current imputation methods often handle numerical and categorical attributes independently, overlooking critical interdependencies among heterogeneous features. To address these limitations, we propose a novel imputation approach that explicitly models cross-type feature dependencies within a unified framework. Our method leverages both complete and incomplete instances to ensure accurate and consistent imputation in tabular data. Extensive experimental results demonstrate that the proposed approach achieves superior performance over existing techniques and significantly enhances downstream machine learning tasks, providing a robust solution for real-world systems with missing data.
2601.05017Jan 2026
ViewOn the Hidden Objective Biases of Group-based Reinforcement Learning
Group-based reinforcement learning methods, like Group Relative Policy Optimization (GRPO), are widely used nowadays to post-train large language models. Despite their empirical success, they exhibit structural mismatches between reward optimization and the underlying training objective. In this paper, we present a theoretical analysis of GRPO style methods by studying them within a unified surrogate formulation. This perspective reveals recurring properties that affect all the methods under analysis: (i) non-uniform group weighting induces systematic gradient biases on shared prefix tokens; (ii) interactions with the AdamW optimizer make training dynamics largely insensitive to reward scaling; and (iii) optimizer momentum can push policy updates beyond the intended clipping region under repeated optimization steps. We believe that these findings highlight fundamental limitations of current approaches and provide principled guidance for the design of future formulations.
2601.05002Jan 2026
View
On the Definition and Detection of Cherry-Picking in Counterfactual Explanations
Counterfactual explanations are widely used to communicate how inputs must change for a model to alter its prediction. For a single instance, many valid counterfactuals can exist, which leaves open the possibility for an explanation provider to cherry-pick explanations that better suit a narrative of their choice, highlighting favourable behaviour and withholding examples that reveal problematic behaviour. We formally define cherry-picking for counterfactual explanations in terms of an admissible explanation space, specified by the generation procedure, and a utility function. We then study to what extent an external auditor can detect such manipulation. Considering three levels of access to the explanation process: full procedural access, partial procedural access, and explanation-only access, we show that detection is extremely limited in practice. Even with full procedural access, cherry-picked explanations can remain difficult to distinguish from non cherry-picked explanations, because the multiplicity of valid counterfactuals and flexibility in the explanation specification provide sufficient degrees of freedom to mask deliberate selection. Empirically, we demonstrate that this variability often exceeds the effect of cherry-picking on standard counterfactual quality metrics such as proximity, plausibility, and sparsity, making cherry-picked explanations statistically indistinguishable from baseline explanations. We argue that safeguards should therefore prioritise reproducibility, standardisation, and procedural constraints over post-hoc detection, and we provide recommendations for algorithm developers, explanation providers, and auditors.
2601.04977Jan 2026
View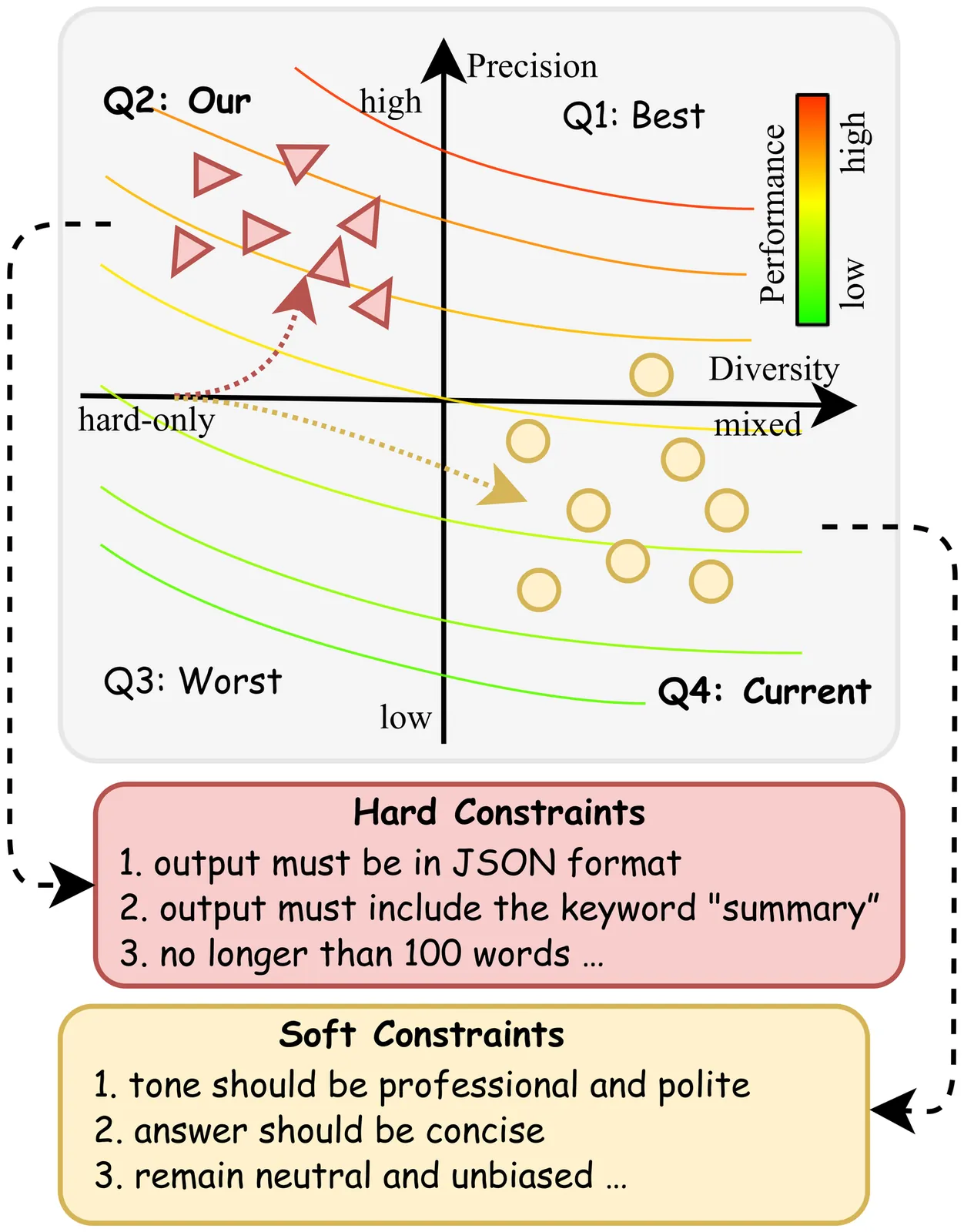
Precision over Diversity: High-Precision Reward Generalizes to Robust Instruction Following
A central belief in scaling reinforcement learning with verifiable rewards for instruction following (IF) tasks is that, a diverse mixture of verifiable hard and unverifiable soft constraints is essential for generalizing to unseen instructions. In this work, we challenge this prevailing consensus through a systematic empirical investigation. Counter-intuitively, we find that models trained on hard-only constraints consistently outperform those trained on mixed datasets. Extensive experiments reveal that reward precision, rather than constraint diversity, is the primary driver of effective alignment. The LLM judge suffers from a low recall rate in detecting false response, which leads to severe reward hacking, thereby undermining the benefits of diversity. Furthermore, analysis of the attention mechanism reveals that high-precision rewards develop a transferable meta-skill for IF. Motivated by these insights, we propose a simple yet effective data-centric refinement strategy that prioritizes reward precision. Evaluated on five benchmarks, our approach outperforms competitive baselines by 13.4\% in performance while achieving a 58\% reduction in training time, maintaining strong generalization beyond instruction following. Our findings advocate for a paradigm shift: moving away from the indiscriminate pursuit of data diversity toward high-precision rewards.
2601.04954Jan 2026
View
Cardinality augmented loss functions
Class imbalance is a common and pernicious issue for the training of neural networks. Often, an imbalanced majority class can dominate training to skew classifier performance towards the majority outcome. To address this problem we introduce cardinality augmented loss functions, derived from cardinality-like invariants in modern mathematics literature such as magnitude and the spread. These invariants enrich the concept of cardinality by evaluating the `effective diversity' of a metric space, and as such represent a natural solution to overly homogeneous training data. In this work, we establish a methodology for applying cardinality augmented loss functions in the training of neural networks and report results on both artificially imbalanced datasets as well as a real-world imbalanced material science dataset. We observe significant performance improvement among minority classes, as well as improvement in overall performance metrics.
2601.04941Jan 2026
View
Distributed Online Convex Optimization with Efficient Communication: Improved Algorithm and Lower bounds
We investigate distributed online convex optimization with compressed communication, where $n$ learners connected by a network collaboratively minimize a sequence of global loss functions using only local information and compressed data from neighbors. Prior work has established regret bounds of $O(\max\{ω^{-2}ρ^{-4}n^{1/2},ω^{-4}ρ^{-8}\}n\sqrt{T})$ and $O(\max\{ω^{-2}ρ^{-4}n^{1/2},ω^{-4}ρ^{-8}\}n\ln{T})$ for convex and strongly convex functions, respectively, where $ω\in(0,1]$ is the compression quality factor ($ω=1$ means no compression) and $ρ<1$ is the spectral gap of the communication matrix. However, these regret bounds suffer from a \emph{quadratic} or even \emph{quartic} dependence on $ω^{-1}$. Moreover, the \emph{super-linear} dependence on $n$ is also undesirable. To overcome these limitations, we propose a novel algorithm that achieves improved regret bounds of $\tilde{O}(ω^{-1/2}ρ^{-1}n\sqrt{T})$ and $\tilde{O}(ω^{-1}ρ^{-2}n\ln{T})$ for convex and strongly convex functions, respectively. The primary idea is to design a \emph{two-level blocking update framework} incorporating two novel ingredients: an online gossip strategy and an error compensation scheme, which collaborate to \emph{achieve a better consensus} among learners. Furthermore, we establish the first lower bounds for this problem, justifying the optimality of our results with respect to both $ω$ and $T$. Additionally, we consider the bandit feedback scenario, and extend our method with the classic gradient estimators to enhance existing regret bounds.
2601.04907Jan 2026
View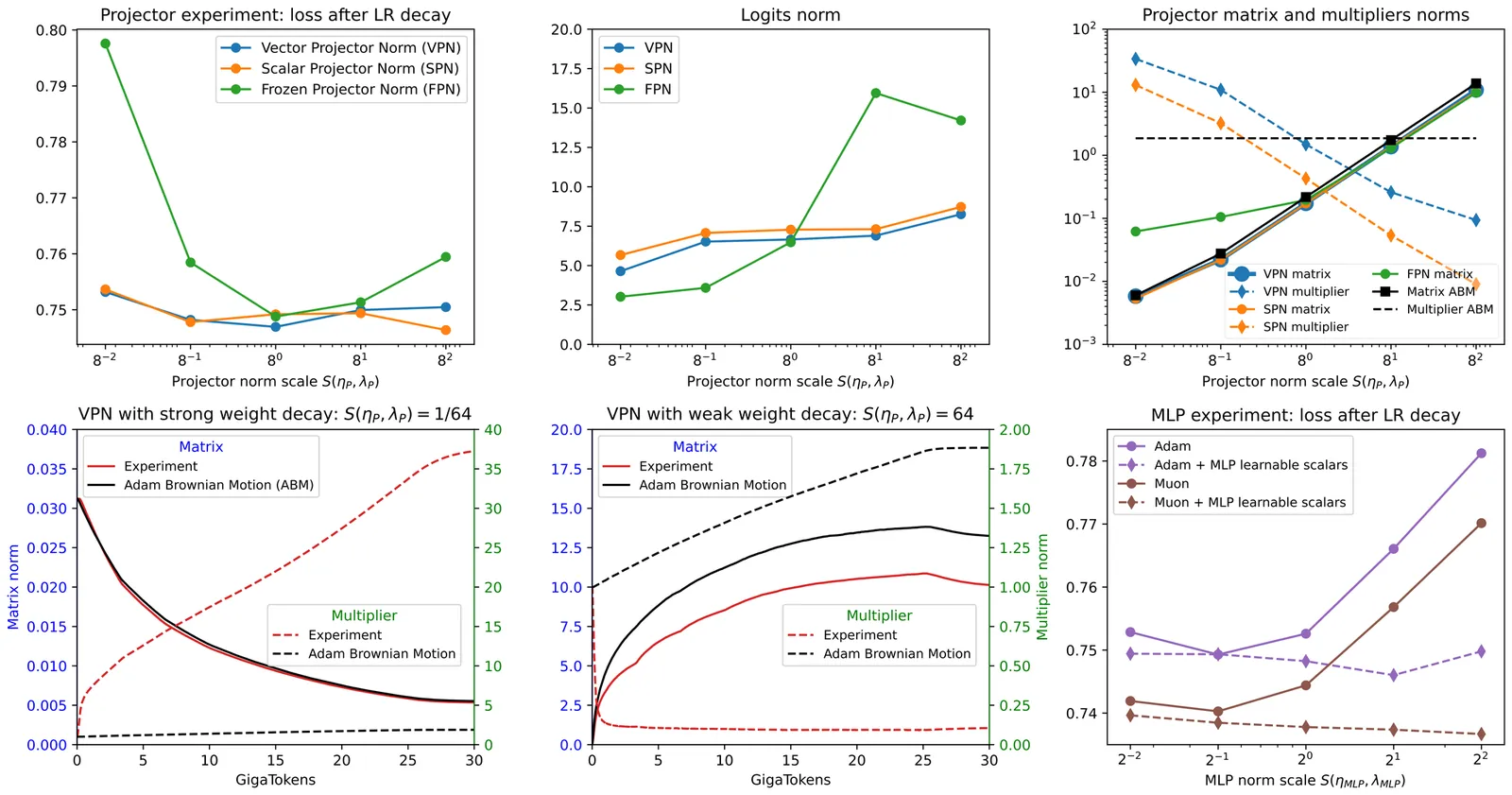
Learnable Multipliers: Freeing the Scale of Language Model Matrix Layers
Applying weight decay (WD) to matrix layers is standard practice in large-language-model pretraining. Prior work suggests that stochastic gradient noise induces a Brownian-like expansion of the weight matrices W, whose growth is counteracted by WD, leading to a WD-noise equilibrium with a certain weight norm ||W||. In this work, we view the equilibrium norm as a harmful artifact of the training procedure, and address it by introducing learnable multipliers to learn the optimal scale. First, we attach a learnable scalar multiplier to W and confirm that the WD-noise equilibrium norm is suboptimal: the learned scale adapts to data and improves performance. We then argue that individual row and column norms are similarly constrained, and free their scale by introducing learnable per-row and per-column multipliers. Our method can be viewed as a learnable, more expressive generalization of muP multipliers. It outperforms a well-tuned muP baseline, reduces the computational overhead of multiplier tuning, and surfaces practical questions such as forward-pass symmetries and the width-scaling of the learned multipliers. Finally, we validate learnable multipliers with both Adam and Muon optimizers, where it shows improvement in downstream evaluations matching the improvement of the switching from Adam to Muon.
2601.04890Jan 2026
View
Rethinking GNNs and Missing Features: Challenges, Evaluation and a Robust Solution
Handling missing node features is a key challenge for deploying Graph Neural Networks (GNNs) in real-world domains such as healthcare and sensor networks. Existing studies mostly address relatively benign scenarios, namely benchmark datasets with (a) high-dimensional but sparse node features and (b) incomplete data generated under Missing Completely At Random (MCAR) mechanisms. For (a), we theoretically prove that high sparsity substantially limits the information loss caused by missingness, making all models appear robust and preventing a meaningful comparison of their performance. To overcome this limitation, we introduce one synthetic and three real-world datasets with dense, semantically meaningful features. For (b), we move beyond MCAR and design evaluation protocols with more realistic missingness mechanisms. Moreover, we provide a theoretical background to state explicit assumptions on the missingness process and analyze their implications for different methods. Building on this analysis, we propose GNNmim, a simple yet effective baseline for node classification with incomplete feature data. Experiments show that GNNmim is competitive with respect to specialized architectures across diverse datasets and missingness regimes.
2601.04855Jan 2026
View
Parallelizing Node-Level Explainability in Graph Neural Networks
Graph Neural Networks (GNNs) have demonstrated remarkable performance in a wide range of tasks, such as node classification, link prediction, and graph classification, by exploiting the structural information in graph-structured data. However, in node classification, computing node-level explainability becomes extremely time-consuming as the size of the graph increases, while batching strategies often degrade explanation quality. This paper introduces a novel approach to parallelizing node-level explainability in GNNs through graph partitioning. By decomposing the graph into disjoint subgraphs, we enable parallel computation of explainability for node neighbors, significantly improving the scalability and efficiency without affecting the correctness of the results, provided sufficient memory is available. For scenarios where memory is limited, we further propose a dropout-based reconstruction mechanism that offers a controllable trade-off between memory usage and explanation fidelity. Experimental results on real-world datasets demonstrate substantial speedups, enabling scalable and transparent explainability for large-scale GNN models.
2601.04807Jan 2026
View
Neural-Symbolic Integration with Evolvable Policies
Neural-Symbolic (NeSy) Artificial Intelligence has emerged as a promising approach for combining the learning capabilities of neural networks with the interpretable reasoning of symbolic systems. However, existing NeSy frameworks typically require either predefined symbolic policies or policies that are differentiable, limiting their applicability when domain expertise is unavailable or when policies are inherently non-differentiable. We propose a framework that addresses this limitation by enabling the concurrent learning of both non-differentiable symbolic policies and neural network weights through an evolutionary process. Our approach casts NeSy systems as organisms in a population that evolve through mutations (both symbolic rule additions and neural weight changes), with fitness-based selection guiding convergence toward hidden target policies. The framework extends the NEUROLOG architecture to make symbolic policies trainable, adapts Valiant's Evolvability framework to the NeSy context, and employs Machine Coaching semantics for mutable symbolic representations. Neural networks are trained through abductive reasoning from the symbolic component, eliminating differentiability requirements. Through extensive experimentation, we demonstrate that NeSy systems starting with empty policies and random neural weights can successfully approximate hidden non-differentiable target policies, achieving median correct performance approaching 100%. This work represents a step toward enabling NeSy research in domains where the acquisition of symbolic knowledge from experts is challenging or infeasible.
2601.04799Jan 2026
ViewPage 1 of 789