Machine Learning
Neural networks, deep learning, statistical learning, and optimization methods
Neural networks, deep learning, statistical learning, and optimization methods
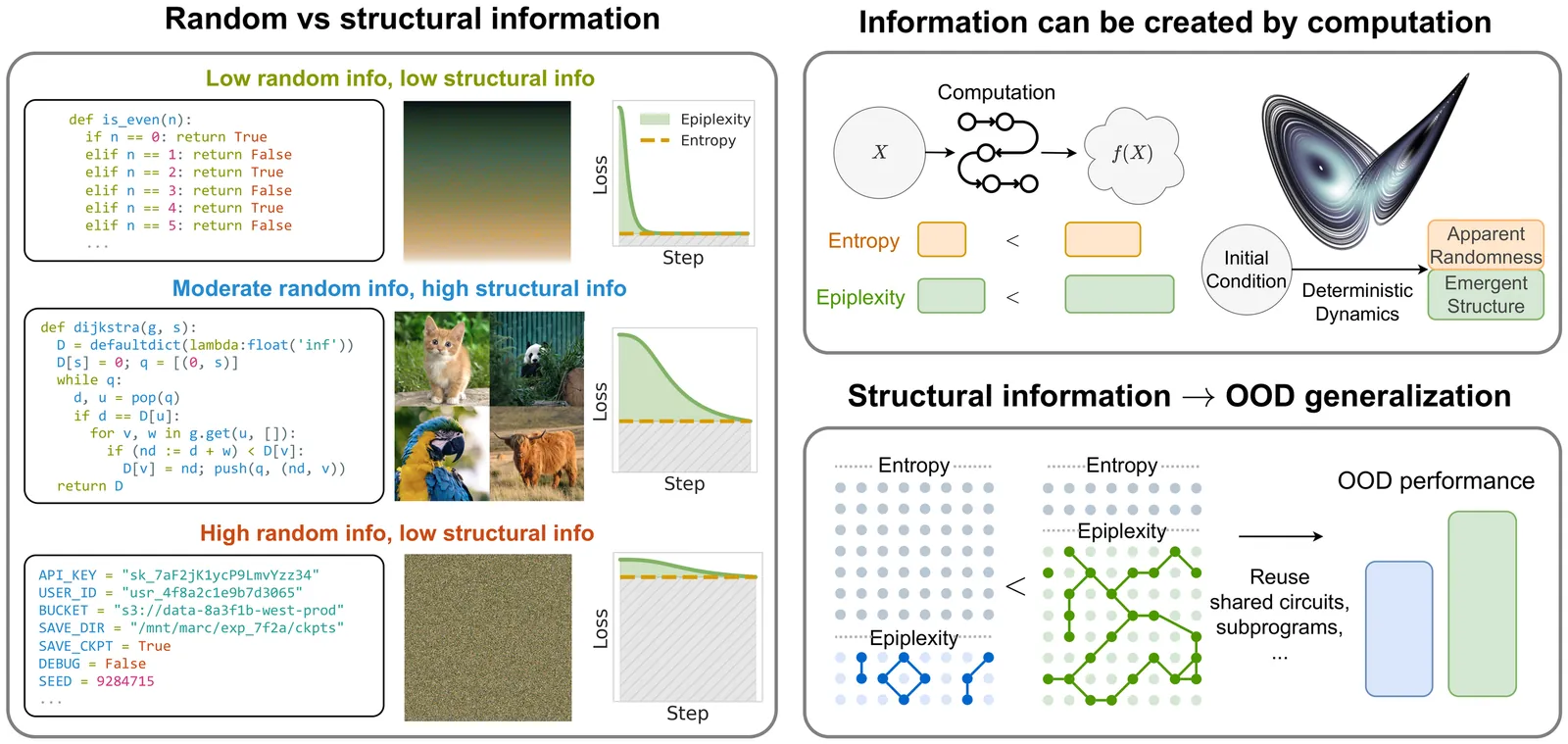
Can we learn more from data than existed in the generating process itself? Can new and useful information be constructed from merely applying deterministic transformations to existing data? Can the learnable content in data be evaluated without considering a downstream task? On these questions, Shannon information and Kolmogorov complexity come up nearly empty-handed, in part because they assume observers with unlimited computational capacity and fail to target the useful information content. In this work, we identify and exemplify three seeming paradoxes in information theory: (1) information cannot be increased by deterministic transformations; (2) information is independent of the order of data; (3) likelihood modeling is merely distribution matching. To shed light on the tension between these results and modern practice, and to quantify the value of data, we introduce epiplexity, a formalization of information capturing what computationally bounded observers can learn from data. Epiplexity captures the structural content in data while excluding time-bounded entropy, the random unpredictable content exemplified by pseudorandom number generators and chaotic dynamical systems. With these concepts, we demonstrate how information can be created with computation, how it depends on the ordering of the data, and how likelihood modeling can produce more complex programs than present in the data generating process itself. We also present practical procedures to estimate epiplexity which we show capture differences across data sources, track with downstream performance, and highlight dataset interventions that improve out-of-distribution generalization. In contrast to principles of model selection, epiplexity provides a theoretical foundation for data selection, guiding how to select, generate, or transform data for learning systems.
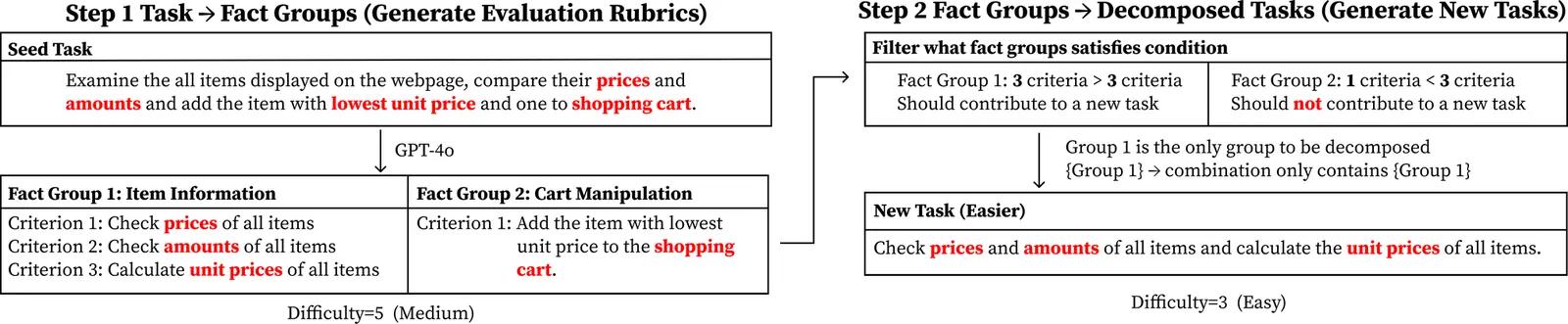
We present WebGym, the largest-to-date open-source environment for training realistic visual web agents. Real websites are non-stationary and diverse, making artificial or small-scale task sets insufficient for robust policy learning. WebGym contains nearly 300,000 tasks with rubric-based evaluations across diverse, real-world websites and difficulty levels. We train agents with a simple reinforcement learning (RL) recipe, which trains on the agent's own interaction traces (rollouts), using task rewards as feedback to guide learning. To enable scaling RL, we speed up sampling of trajectories in WebGym by developing a high-throughput asynchronous rollout system, designed specifically for web agents. Our system achieves a 4-5x rollout speedup compared to naive implementations. Second, we scale the task set breadth, depth, and size, which results in continued performance improvement. Fine-tuning a strong base vision-language model, Qwen-3-VL-8B-Instruct, on WebGym results in an improvement in success rate on an out-of-distribution test set from 26.2% to 42.9%, significantly outperforming agents based on proprietary models such as GPT-4o and GPT-5-Thinking that achieve 27.1% and 29.8%, respectively. This improvement is substantial because our test set consists only of tasks on websites never seen during training, unlike many other prior works on training visual web agents.
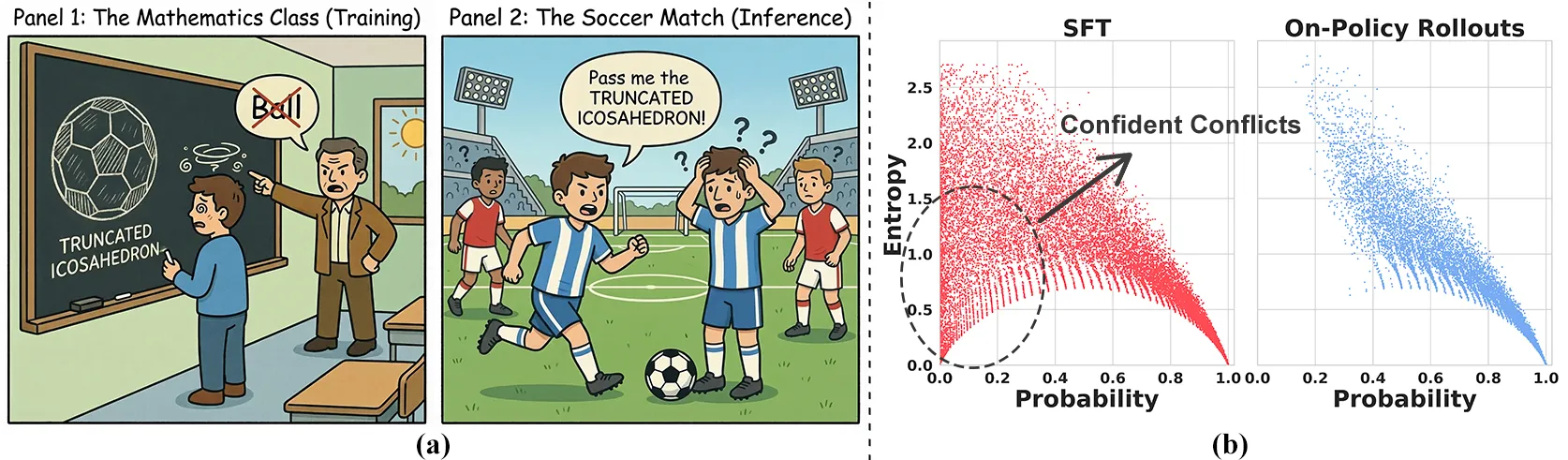
Supervised Fine-Tuning (SFT) is the standard paradigm for domain adaptation, yet it frequently incurs the cost of catastrophic forgetting. In sharp contrast, on-policy Reinforcement Learning (RL) effectively preserves general capabilities. We investigate this discrepancy and identify a fundamental distributional gap: while RL aligns with the model's internal belief, SFT forces the model to fit external supervision. This mismatch often manifests as "Confident Conflicts" tokens characterized by low probability but low entropy. In these instances, the model is highly confident in its own prediction but is forced to learn a divergent ground truth, triggering destructive gradient updates. To address this, we propose Entropy-Adaptive Fine-Tuning (EAFT). Unlike methods relying solely on prediction probability, EAFT utilizes token-level entropy as a gating mechanism to distinguish between epistemic uncertainty and knowledge conflict. This allows the model to learn from uncertain samples while suppressing gradients on conflicting data. Extensive experiments on Qwen and GLM series (ranging from 4B to 32B parameters) across mathematical, medical, and agentic domains confirm our hypothesis. EAFT consistently matches the downstream performance of standard SFT while significantly mitigating the degradation of general capabilities.
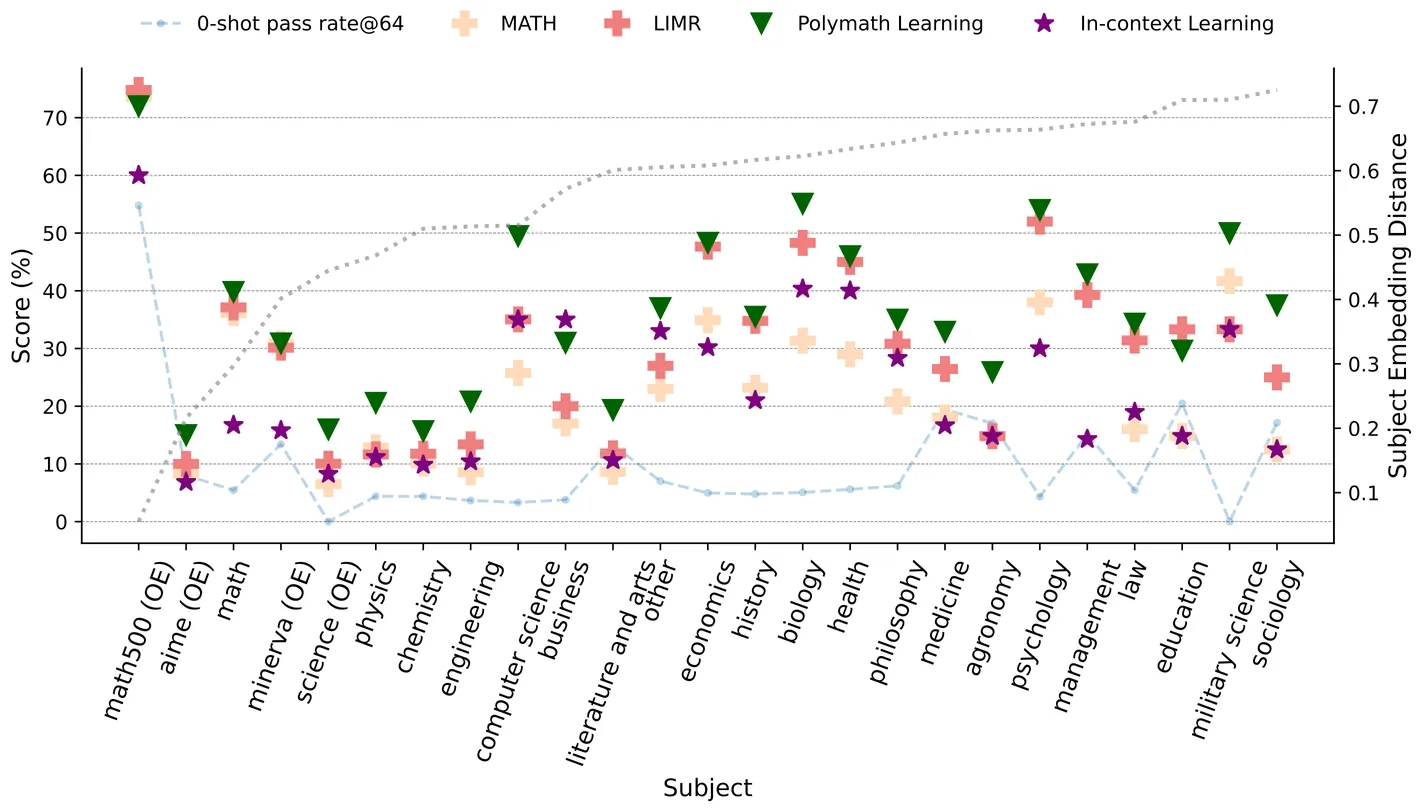
The reasoning ability of large language models (LLMs) can be unleashed with reinforcement learning (RL) (OpenAI, 2024; DeepSeek-AI et al., 2025a; Zeng et al., 2025). The success of existing RL attempts in LLMs usually relies on high-quality samples of thousands or beyond. In this paper, we challenge fundamental assumptions about data requirements in RL for LLMs by demonstrating the remarkable effectiveness of one-shot learning. Specifically, we introduce polymath learning, a framework for designing one training sample that elicits multidisciplinary impact. We present three key findings: (1) A single, strategically selected math reasoning sample can produce significant performance improvements across multiple domains, including physics, chemistry, and biology with RL; (2) The math skills salient to reasoning suggest the characteristics of the optimal polymath sample; and (3) An engineered synthetic sample that integrates multidiscipline elements outperforms training with individual samples that naturally occur. Our approach achieves superior performance to training with larger datasets across various reasoning benchmarks, demonstrating that sample quality and design, rather than quantity, may be the key to unlock enhanced reasoning capabilities in language models. Our results suggest a shift, dubbed as sample engineering, toward precision engineering of training samples rather than simply increasing data volume.
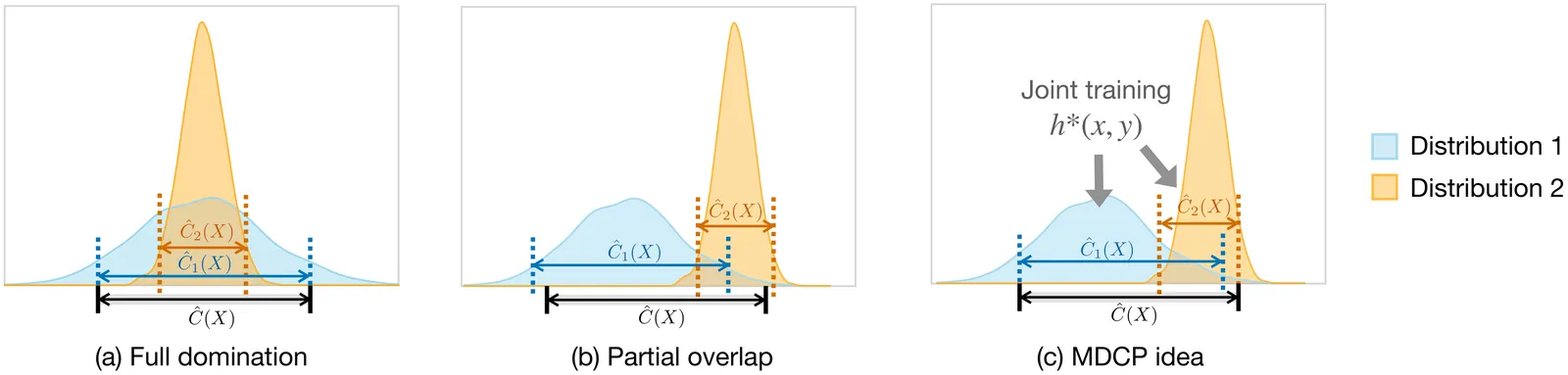
In many fairness and distribution robustness problems, one has access to labeled data from multiple source distributions yet the test data may come from an arbitrary member or a mixture of them. We study the problem of constructing a conformal prediction set that is uniformly valid across multiple, heterogeneous distributions, in the sense that no matter which distribution the test point is from, the coverage of the prediction set is guaranteed to exceed a pre-specified level. We first propose a max-p aggregation scheme that delivers finite-sample, multi-distribution coverage given any conformity scores associated with each distribution. Upon studying several efficiency optimization programs subject to uniform coverage, we prove the optimality and tightness of our aggregation scheme, and propose a general algorithm to learn conformity scores that lead to efficient prediction sets after the aggregation under standard conditions. We discuss how our framework relates to group-wise distributionally robust optimization, sub-population shift, fairness, and multi-source learning. In synthetic and real-data experiments, our method delivers valid worst-case coverage across multiple distributions while greatly reducing the set size compared with naively applying max-p aggregation to single-source conformity scores, and can be comparable in size to single-source prediction sets with popular, standard conformity scores.
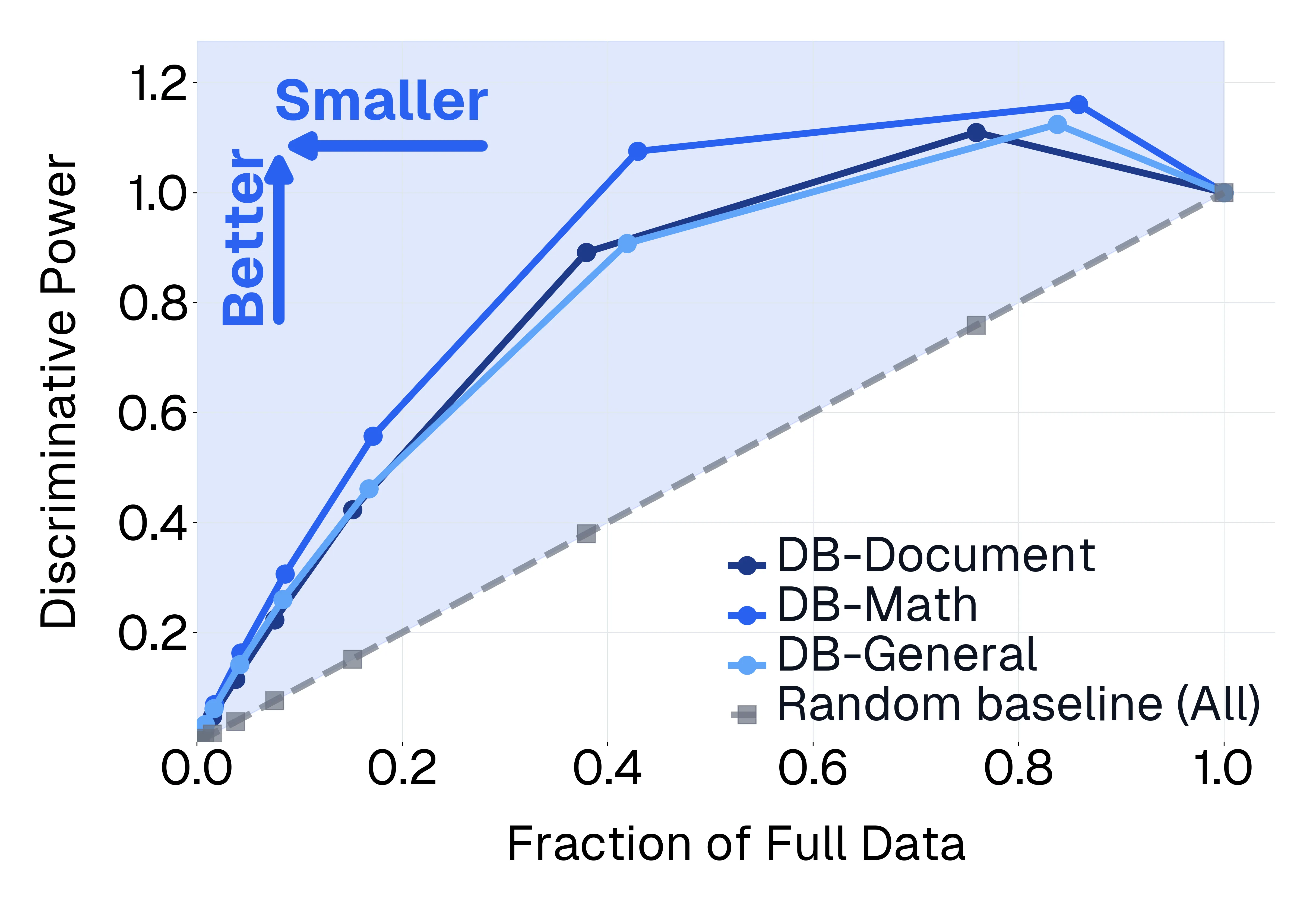
Empirical evaluation serves as the primary compass guiding research progress in foundation models. Despite a large body of work focused on training frontier vision-language models (VLMs), approaches to their evaluation remain nascent. To guide their maturation, we propose three desiderata that evaluations should satisfy: (1) faithfulness to the modality and application, (2) discriminability between models of varying quality, and (3) efficiency in compute. Through this lens, we identify critical failure modes that violate faithfulness and discriminability, misrepresenting model capabilities: (i) multiple-choice formats reward guessing, poorly reflect downstream use cases, and saturate early as models improve; (ii) blindly solvable questions, which can be answered without images, constitute up to 70% of some evaluations; and (iii) mislabeled or ambiguous samples compromise up to 42% of examples in certain datasets. Regarding efficiency, the computational burden of evaluating frontier models has become prohibitive: by some accounts, nearly 20% of development compute is devoted to evaluation alone. Rather than discarding existing benchmarks, we curate them via transformation and filtering to maximize fidelity and discriminability. We find that converting multiple-choice questions to generative tasks reveals sharp capability drops of up to 35%. In addition, filtering blindly solvable and mislabeled samples improves discriminative power while simultaneously reducing computational cost. We release DatBench-Full, a cleaned evaluation suite of 33 datasets spanning nine VLM capabilities, and DatBench, a discriminative subset that achieves 13x average speedup (up to 50x) while closely matching the discriminative power of the original datasets. Our work outlines a path toward evaluation practices that are both rigorous and sustainable as VLMs continue to scale.
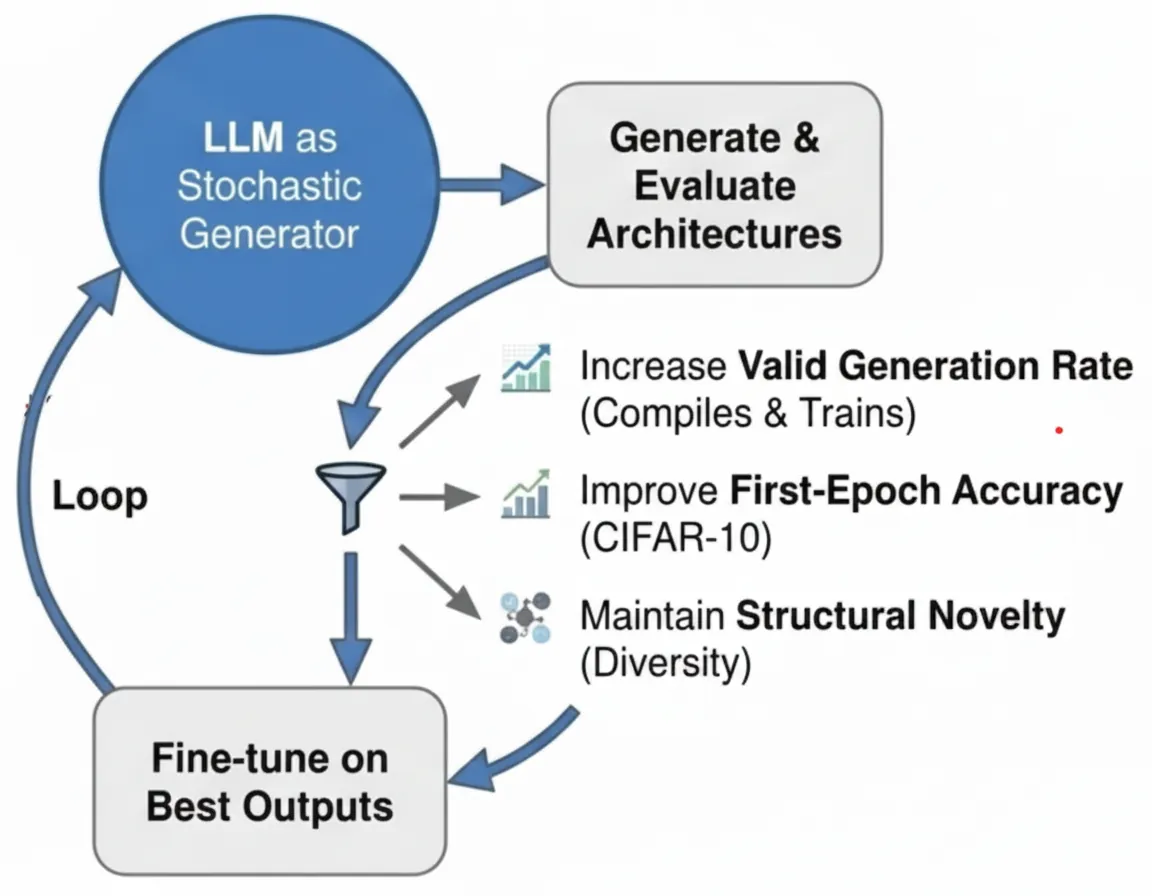
Large language models (LLMs) excel in program synthesis, yet their ability to autonomously navigate neural architecture design--balancing syntactic reliability, performance, and structural novelty--remains underexplored. We address this by placing a code-oriented LLM within a closed-loop synthesis framework, analyzing its evolution over 22 supervised fine-tuning cycles. The model synthesizes PyTorch convolutional networks which are validated, evaluated via low-fidelity performance signals (single-epoch accuracy), and filtered using a MinHash-Jaccard criterion to prevent structural redundancy. High-performing, novel architectures are converted into prompt-code pairs for iterative fine-tuning via parameter-efficient LoRA adaptation, initialized from the LEMUR dataset. Across cycles, the LLM internalizes empirical architectural priors, becoming a robust generator. The valid generation rate stabilizes at 50.6 percent (peaking at 74.5 percent), while mean first-epoch accuracy rises from 28.06 percent to 50.99 percent, and the fraction of candidates exceeding 40 percent accuracy grows from 2.04 percent to 96.81 percent. Analyses confirm the model moves beyond replicating existing motifs, synthesizing 455 high-performing architectures absent from the original corpus. By grounding code synthesis in execution feedback, this work provides a scalable blueprint for transforming stochastic generators into autonomous, performance-driven neural designers, establishing that LLMs can internalize empirical, non-textual rewards to transcend their training data.
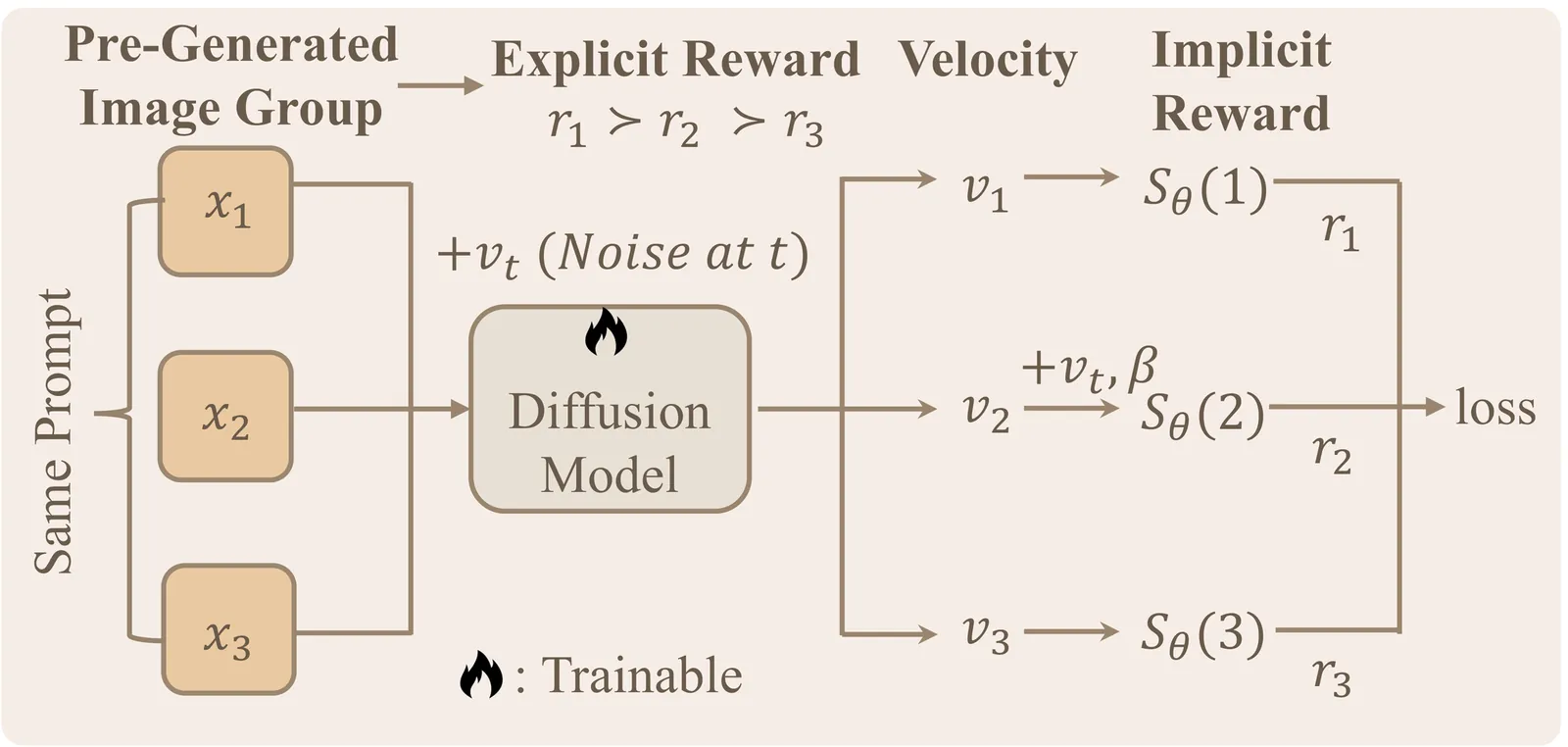
Recent advancements adopt online reinforcement learning (RL) from LLMs to text-to-image rectified flow diffusion models for reward alignment. The use of group-level rewards successfully aligns the model with the targeted reward. However, it faces challenges including low efficiency, dependency on stochastic samplers, and reward hacking. The problem is that rectified flow models are fundamentally different from LLMs: 1) For efficiency, online image sampling takes much more time and dominates the time of training. 2) For stochasticity, rectified flow is deterministic once the initial noise is fixed. Aiming at these problems and inspired by the effects of group-level rewards from LLMs, we design Group-level Direct Reward Optimization (GDRO). GDRO is a new post-training paradigm for group-level reward alignment that combines the characteristics of rectified flow models. Through rigorous theoretical analysis, we point out that GDRO supports full offline training that saves the large time cost for image rollout sampling. Also, it is diffusion-sampler-independent, which eliminates the need for the ODE-to-SDE approximation to obtain stochasticity. We also empirically study the reward hacking trap that may mislead the evaluation, and involve this factor in the evaluation using a corrected score that not only considers the original evaluation reward but also the trend of reward hacking. Extensive experiments demonstrate that GDRO effectively and efficiently improves the reward score of the diffusion model through group-wise offline optimization across the OCR and GenEval tasks, while demonstrating strong stability and robustness in mitigating reward hacking.
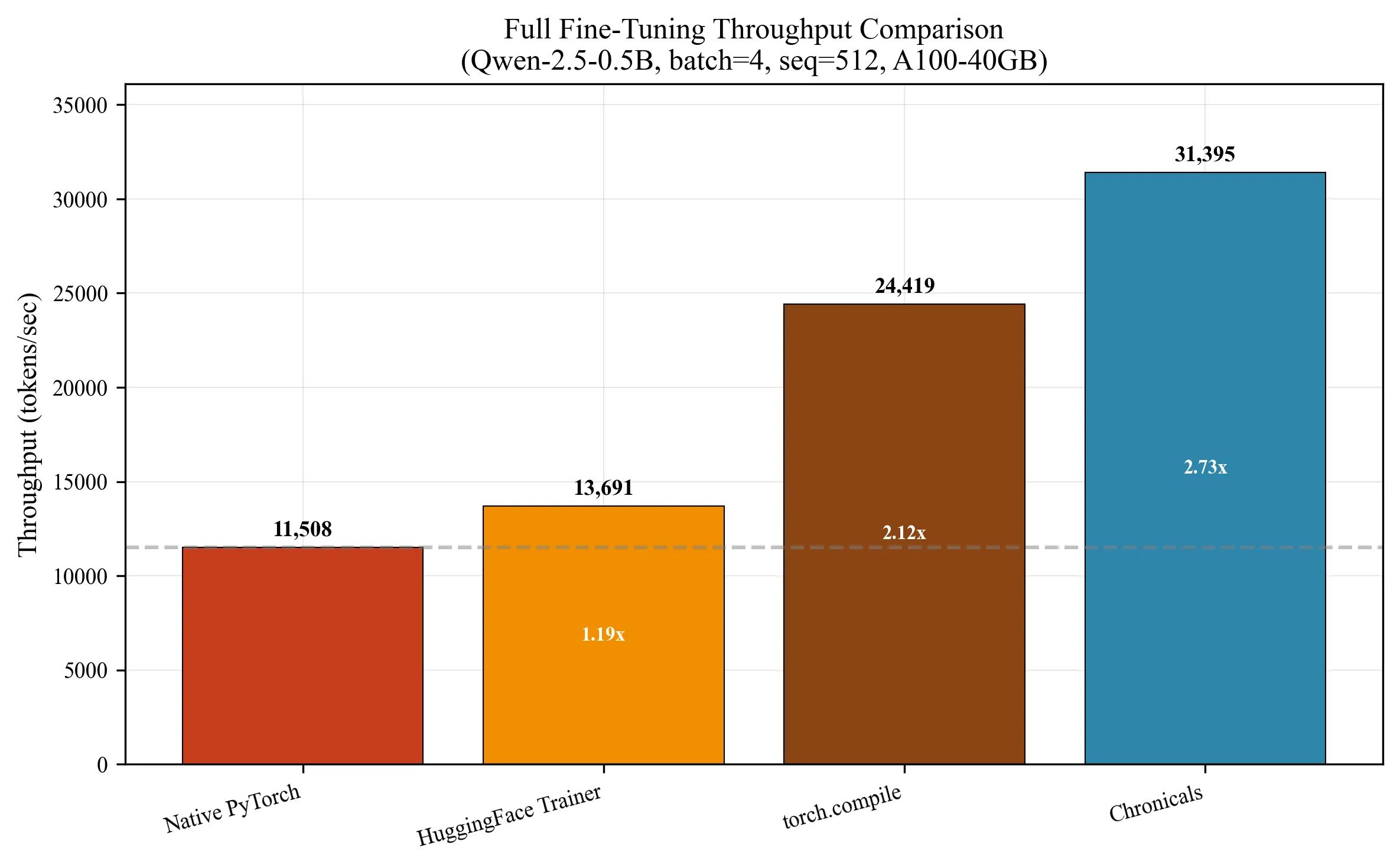
Large language model fine-tuning is bottlenecked by memory: a 7B parameter model requires 84GB--14GB for weights, 14GB for gradients, and 56GB for FP32 optimizer states--exceeding even A100-40GB capacity. We present Chronicals, an open-source training framework achieving 3.51x speedup over Unsloth through four synergistic optimizations: (1) fused Triton kernels eliminating 75% of memory traffic via RMSNorm (7x), SwiGLU (5x), and QK-RoPE (2.3x) fusion; (2) Cut Cross-Entropy reducing logit memory from 5GB to 135MB through online softmax computation; (3) LoRA+ with theoretically-derived 16x differential learning rates between adapter matrices; and (4) Best-Fit Decreasing sequence packing recovering 60-75% of compute wasted on padding. On Qwen2.5-0.5B with A100-40GB, Chronicals achieves 41,184 tokens/second for full fine-tuning versus Unsloth's 11,736 tokens/second (3.51x). For LoRA at rank 32, we reach 11,699 tokens/second versus Unsloth MAX's 2,857 tokens/second (4.10x). Critically, we discovered that Unsloth's reported 46,000 tokens/second benchmark exhibited zero gradient norms--the model was not training. We provide complete mathematical foundations: online softmax correctness proofs, FlashAttention IO complexity bounds O(N^2 d^2 M^{-1}), LoRA+ learning rate derivations from gradient magnitude analysis, and bin-packing approximation guarantees. All implementations, benchmarks, and proofs are available at https://github.com/Ajwebdevs/Chronicals with pip installation via https://pypi.org/project/chronicals/.
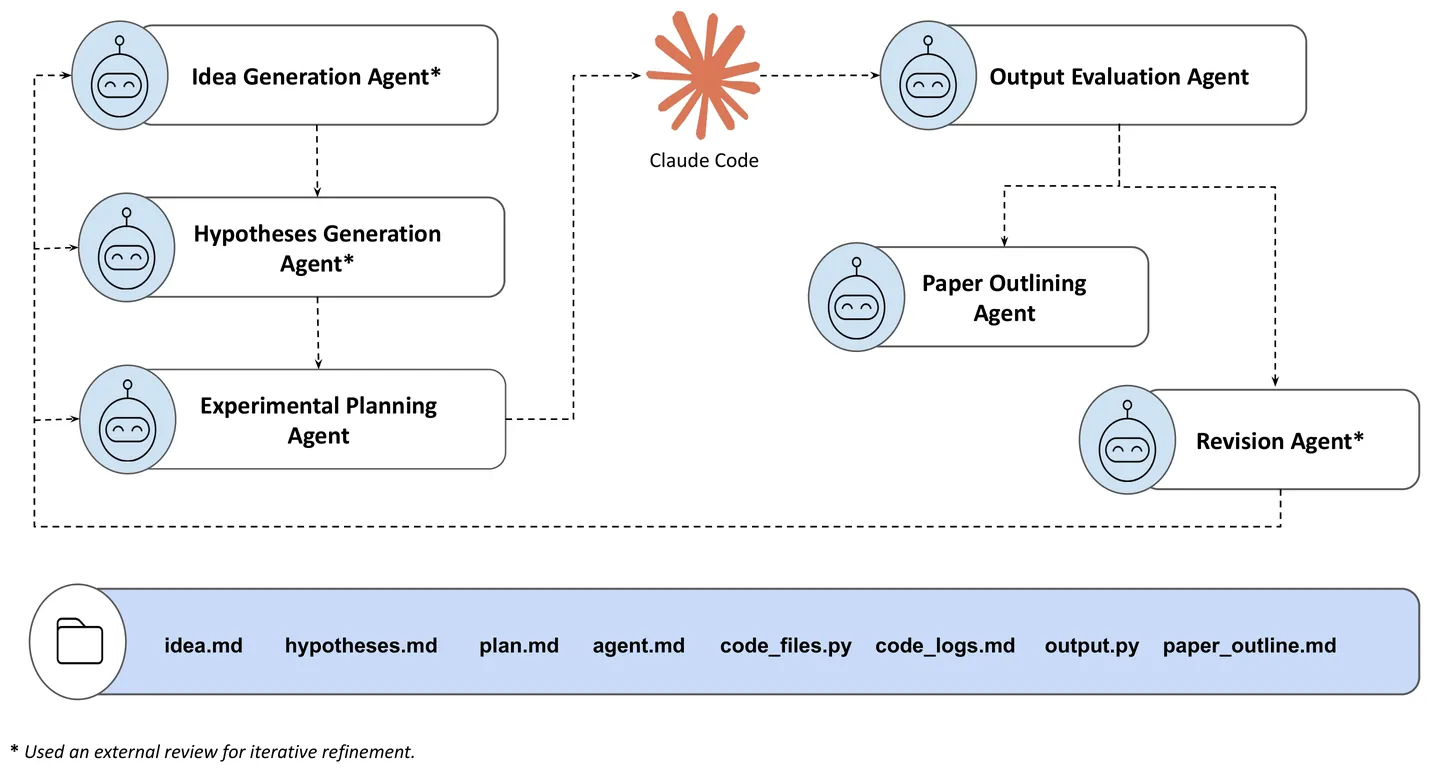
We report a case study of four end-to-end attempts to autonomously generate ML research papers using a pipeline of six LLM agents mapped to stages of the scientific workflow. Of these four, three attempts failed during implementation or evaluation. One completed the pipeline and was accepted to Agents4Science 2025, an experimental inaugural venue that required AI systems as first authors, passing both human and multi-AI review. From these attempts, we document six recurring failure modes: bias toward training data defaults, implementation drift under execution pressure, memory and context degradation across long-horizon tasks, overexcitement that declares success despite obvious failures, insufficient domain intelligence, and weak scientific taste in experimental design. We conclude by discussing four design principles for more robust AI-scientist systems, implications for autonomous scientific discovery, and we release all prompts, artifacts, and outputs at https://github.com/Lossfunk/ai-scientist-artefacts-v1
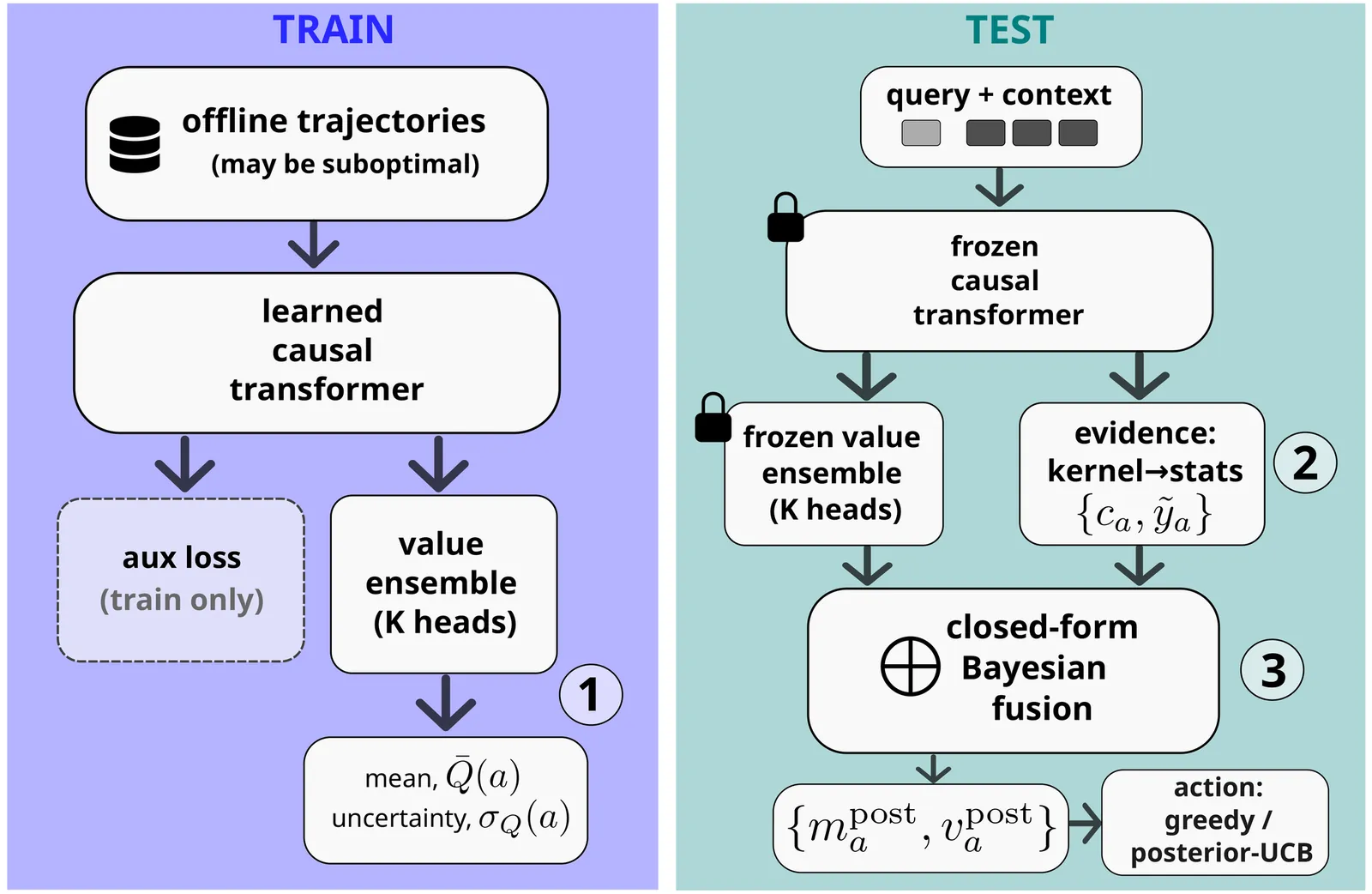
In-context reinforcement learning (ICRL) promises fast adaptation to unseen environments without parameter updates, but current methods either cannot improve beyond the training distribution or require near-optimal data, limiting practical adoption. We introduce SPICE, a Bayesian ICRL method that learns a prior over Q-values via deep ensemble and updates this prior at test-time using in-context information through Bayesian updates. To recover from poor priors resulting from training on sub-optimal data, our online inference follows an Upper-Confidence Bound rule that favours exploration and adaptation. We prove that SPICE achieves regret-optimal behaviour in both stochastic bandits and finite-horizon MDPs, even when pretrained only on suboptimal trajectories. We validate these findings empirically across bandit and control benchmarks. SPICE achieves near-optimal decisions on unseen tasks, substantially reduces regret compared to prior ICRL and meta-RL approaches while rapidly adapting to unseen tasks and remaining robust under distribution shift.

Verification is critical for improving agents: it provides the reward signal for Reinforcement Learning and enables inference-time gains through Test-Time Scaling (TTS). Despite its importance, verification in software engineering (SWE) agent settings often relies on code execution, which can be difficult to scale due to environment setup overhead. Scalable alternatives such as patch classifiers and heuristic methods exist, but they are less grounded in codebase context and harder to interpret. To this end, we explore Agentic Rubrics: an expert agent interacts with the repository to create a context-grounded rubric checklist, and candidate patches are then scored against it without requiring test execution. On SWE-Bench Verified under parallel TTS evaluation, Agentic Rubrics achieve a score of 54.2% on Qwen3-Coder-30B-A3B and 40.6% on Qwen3-32B, with at least a +3.5 percentage-point gain over the strongest baseline in our comparison set. We further analyze rubric behavior, showing that rubric scores are consistent with ground-truth tests while also flagging issues that tests do not capture. Our ablations show that agentic context gathering is essential for producing codebase-specific, unambiguous criteria. Together, these results suggest that Agentic Rubrics provide an efficient, scalable, and granular verification signal for SWE agents.
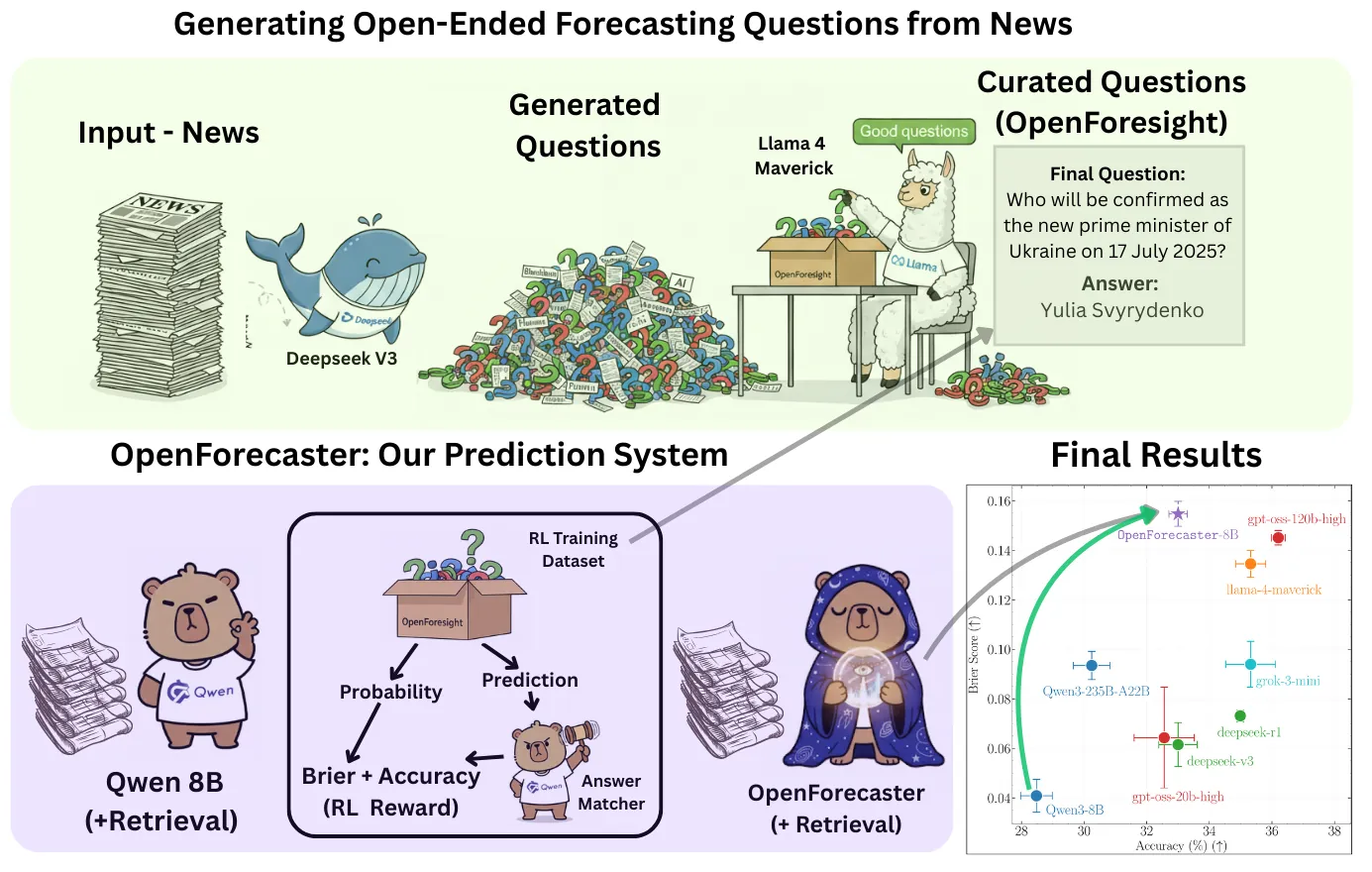
High-stakes decision making involves reasoning under uncertainty about the future. In this work, we train language models to make predictions on open-ended forecasting questions. To scale up training data, we synthesize novel forecasting questions from global events reported in daily news, using a fully automated, careful curation recipe. We train the Qwen3 thinking models on our dataset, OpenForesight. To prevent leakage of future information during training and evaluation, we use an offline news corpus, both for data generation and retrieval in our forecasting system. Guided by a small validation set, we show the benefits of retrieval, and an improved reward function for reinforcement learning (RL). Once we obtain our final forecasting system, we perform held-out testing between May to August 2025. Our specialized model, OpenForecaster 8B, matches much larger proprietary models, with our training improving the accuracy, calibration, and consistency of predictions. We find calibration improvements from forecasting training generalize across popular benchmarks. We open-source all our models, code, and data to make research on language model forecasting broadly accessible.

The efficacy of deep residual networks is fundamentally predicated on the identity shortcut connection. While this mechanism effectively mitigates the vanishing gradient problem, it imposes a strictly additive inductive bias on feature transformations, thereby limiting the network's capacity to model complex state transitions. In this paper, we introduce Deep Delta Learning (DDL), a novel architecture that generalizes the standard residual connection by modulating the identity shortcut with a learnable, data-dependent geometric transformation. This transformation, termed the Delta Operator, constitutes a rank-1 perturbation of the identity matrix, parameterized by a reflection direction vector $\mathbf{k}(\mathbf{X})$ and a gating scalar $β(\mathbf{X})$. We provide a spectral analysis of this operator, demonstrating that the gate $β(\mathbf{X})$ enables dynamic interpolation between identity mapping, orthogonal projection, and geometric reflection. Furthermore, we restructure the residual update as a synchronous rank-1 injection, where the gate acts as a dynamic step size governing both the erasure of old information and the writing of new features. This unification empowers the network to explicitly control the spectrum of its layer-wise transition operator, enabling the modeling of complex, non-monotonic dynamics while preserving the stable training characteristics of gated residual architectures.
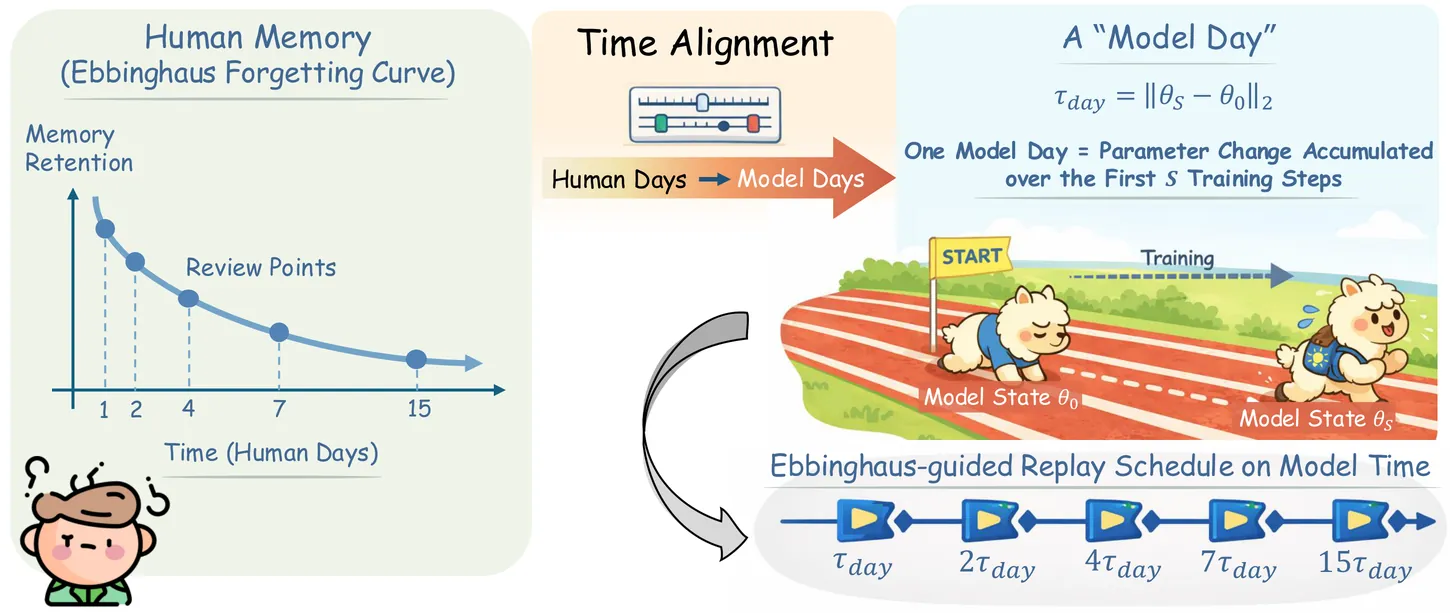
Continual learning (CL) for large language models (LLMs) aims to enable sequential knowledge acquisition without catastrophic forgetting. Memory replay methods are widely used for their practicality and effectiveness, but most rely on fixed, step-based heuristics that often misalign with the model's actual learning progress, since identical training steps can result in varying degrees of parameter change. Motivated by recent findings that LLM forgetting mirrors the Ebbinghaus human forgetting curve, we propose FOREVER (FORgEtting curVe-inspired mEmory Replay), a novel CL framework that aligns replay schedules with a model-centric notion of time. FOREVER defines model time using the magnitude of optimizer updates, allowing forgetting curve-inspired replay intervals to align with the model's internal evolution rather than raw training steps. Building on this approach, FOREVER incorporates a forgetting curve-based replay scheduler to determine when to replay and an intensity-aware regularization mechanism to adaptively control how to replay. Extensive experiments on three CL benchmarks and models ranging from 0.6B to 13B parameters demonstrate that FOREVER consistently mitigates catastrophic forgetting.

Despite the recent progresses, particularly in developing Language Models, there are fundamental challenges and unanswered questions about how such models can continually learn/memorize, self-improve, and find effective solutions. In this paper, we present a new learning paradigm, called Nested Learning (NL), that coherently represents a machine learning model with a set of nested, multi-level, and/or parallel optimization problems, each of which with its own context flow. Through the lenses of NL, existing deep learning methods learns from data through compressing their own context flow, and in-context learning naturally emerges in large models. NL suggests a philosophy to design more expressive learning algorithms with more levels, resulting in higher-order in-context learning and potentially unlocking effective continual learning capabilities. We advocate for NL by presenting three core contributions: (1) Expressive Optimizers: We show that known gradient-based optimizers, such as Adam, SGD with Momentum, etc., are in fact associative memory modules that aim to compress the gradients' information (by gradient descent). Building on this insight, we present other more expressive optimizers with deep memory and/or more powerful learning rules; (2) Self-Modifying Learning Module: Taking advantage of NL's insights on learning algorithms, we present a sequence model that learns how to modify itself by learning its own update algorithm; and (3) Continuum Memory System: We present a new formulation for memory system that generalizes the traditional viewpoint of long/short-term memory. Combining our self-modifying sequence model with the continuum memory system, we present a continual learning module, called Hope, showing promising results in language modeling, knowledge incorporation, and few-shot generalization tasks, continual learning, and long-context reasoning tasks.

Large Language Models (LLMs) apply uniform computation to all tokens, despite language exhibiting highly non-uniform information density. This token-uniform regime wastes capacity on locally predictable spans while under-allocating computation to semantically critical transitions. We propose $\textbf{Dynamic Large Concept Models (DLCM)}$, a hierarchical language modeling framework that learns semantic boundaries from latent representations and shifts computation from tokens to a compressed concept space where reasoning is more efficient. DLCM discovers variable-length concepts end-to-end without relying on predefined linguistic units. Hierarchical compression fundamentally changes scaling behavior. We introduce the first $\textbf{compression-aware scaling law}$, which disentangles token-level capacity, concept-level reasoning capacity, and compression ratio, enabling principled compute allocation under fixed FLOPs. To stably train this heterogeneous architecture, we further develop a $\textbf{decoupled $μ$P parametrization}$ that supports zero-shot hyperparameter transfer across widths and compression regimes. At a practical setting ($R=4$, corresponding to an average of four tokens per concept), DLCM reallocates roughly one-third of inference compute into a higher-capacity reasoning backbone, achieving a $\textbf{+2.69$\%$ average improvement}$ across 12 zero-shot benchmarks under matched inference FLOPs.
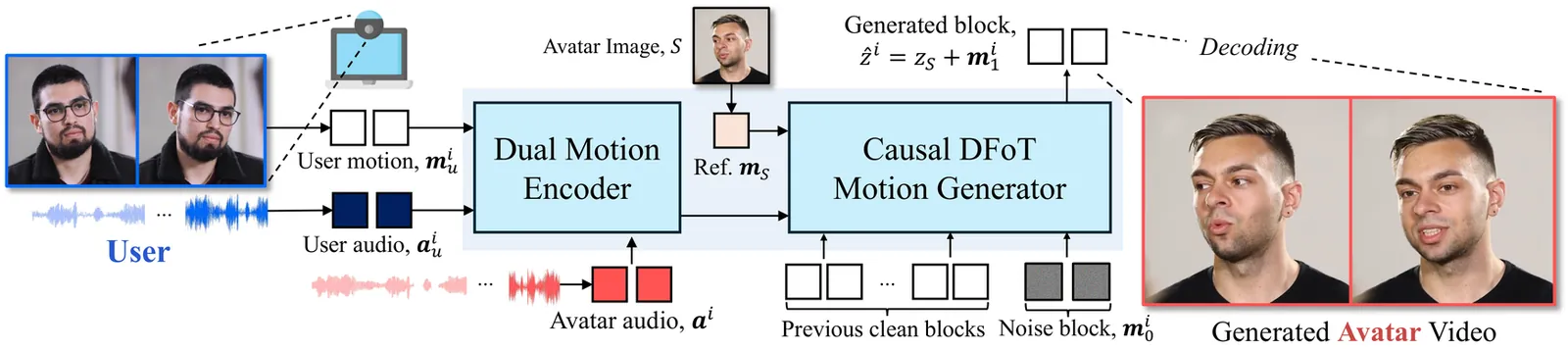
Talking head generation creates lifelike avatars from static portraits for virtual communication and content creation. However, current models do not yet convey the feeling of truly interactive communication, often generating one-way responses that lack emotional engagement. We identify two key challenges toward truly interactive avatars: generating motion in real-time under causal constraints and learning expressive, vibrant reactions without additional labeled data. To address these challenges, we propose Avatar Forcing, a new framework for interactive head avatar generation that models real-time user-avatar interactions through diffusion forcing. This design allows the avatar to process real-time multimodal inputs, including the user's audio and motion, with low latency for instant reactions to both verbal and non-verbal cues such as speech, nods, and laughter. Furthermore, we introduce a direct preference optimization method that leverages synthetic losing samples constructed by dropping user conditions, enabling label-free learning of expressive interaction. Experimental results demonstrate that our framework enables real-time interaction with low latency (approximately 500ms), achieving 6.8X speedup compared to the baseline, and produces reactive and expressive avatar motion, which is preferred over 80% against the baseline.
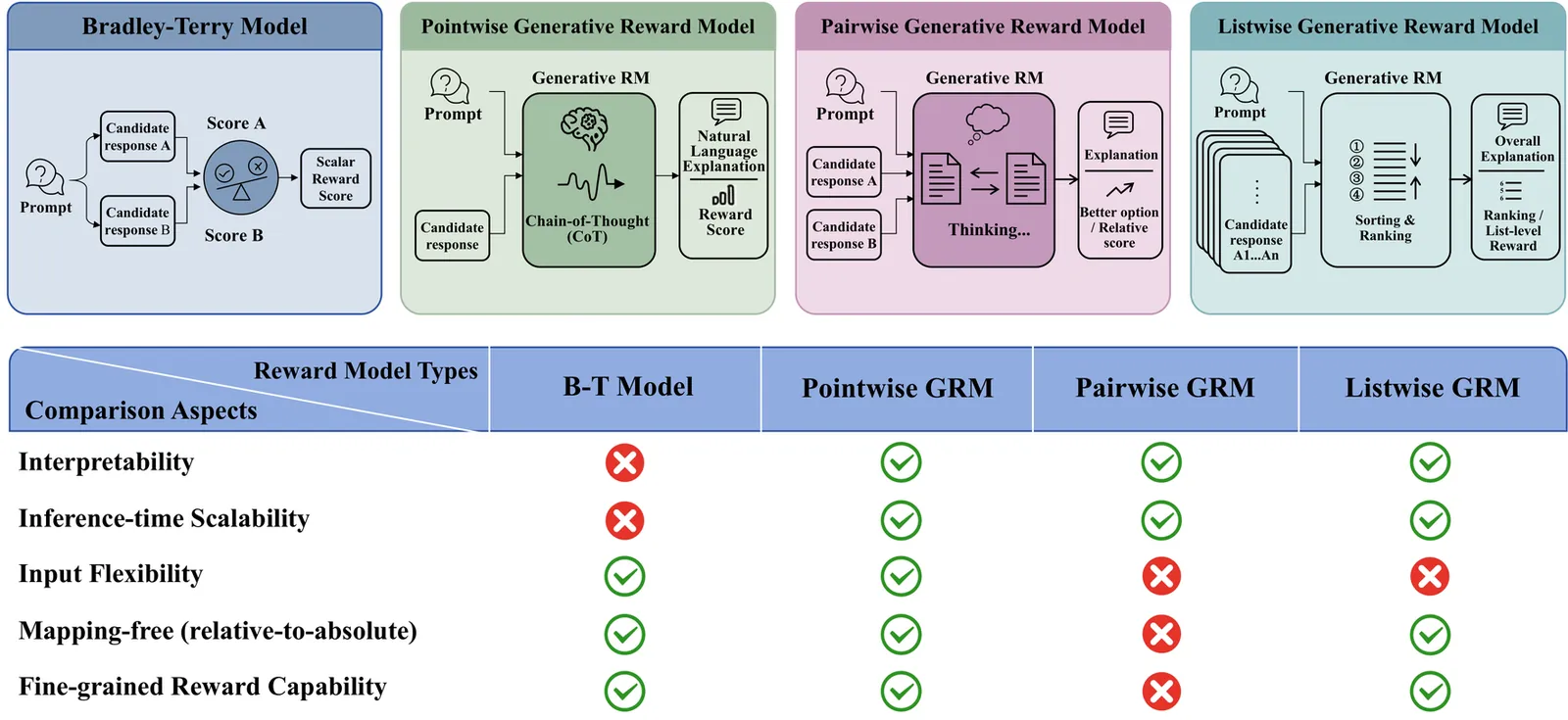
Generative Reward Models (GRMs) have attracted considerable research interest in reward modeling due to their interpretability, inference-time scalability, and potential for refinement through reinforcement learning (RL). However, widely used pairwise GRMs create a computational bottleneck when integrated with RL algorithms such as Group Relative Policy Optimization (GRPO). This bottleneck arises from two factors: (i) the O(n^2) time complexity of pairwise comparisons required to obtain relative scores, and (ii) the computational overhead of repeated sampling or additional chain-of-thought (CoT) reasoning to improve performance. To address the first factor, we propose Intergroup Relative Preference Optimization (IRPO), a novel RL framework that incorporates the well-established Bradley-Terry model into GRPO. By generating a pointwise score for each response, IRPO enables efficient evaluation of arbitrarily many candidates during RL training while preserving interpretability and fine-grained reward signals. Experimental results demonstrate that IRPO achieves state-of-the-art (SOTA) performance among pointwise GRMs across multiple benchmarks, with performance comparable to that of current leading pairwise GRMs. Furthermore, we show that IRPO significantly outperforms pairwise GRMs in post-training evaluations.
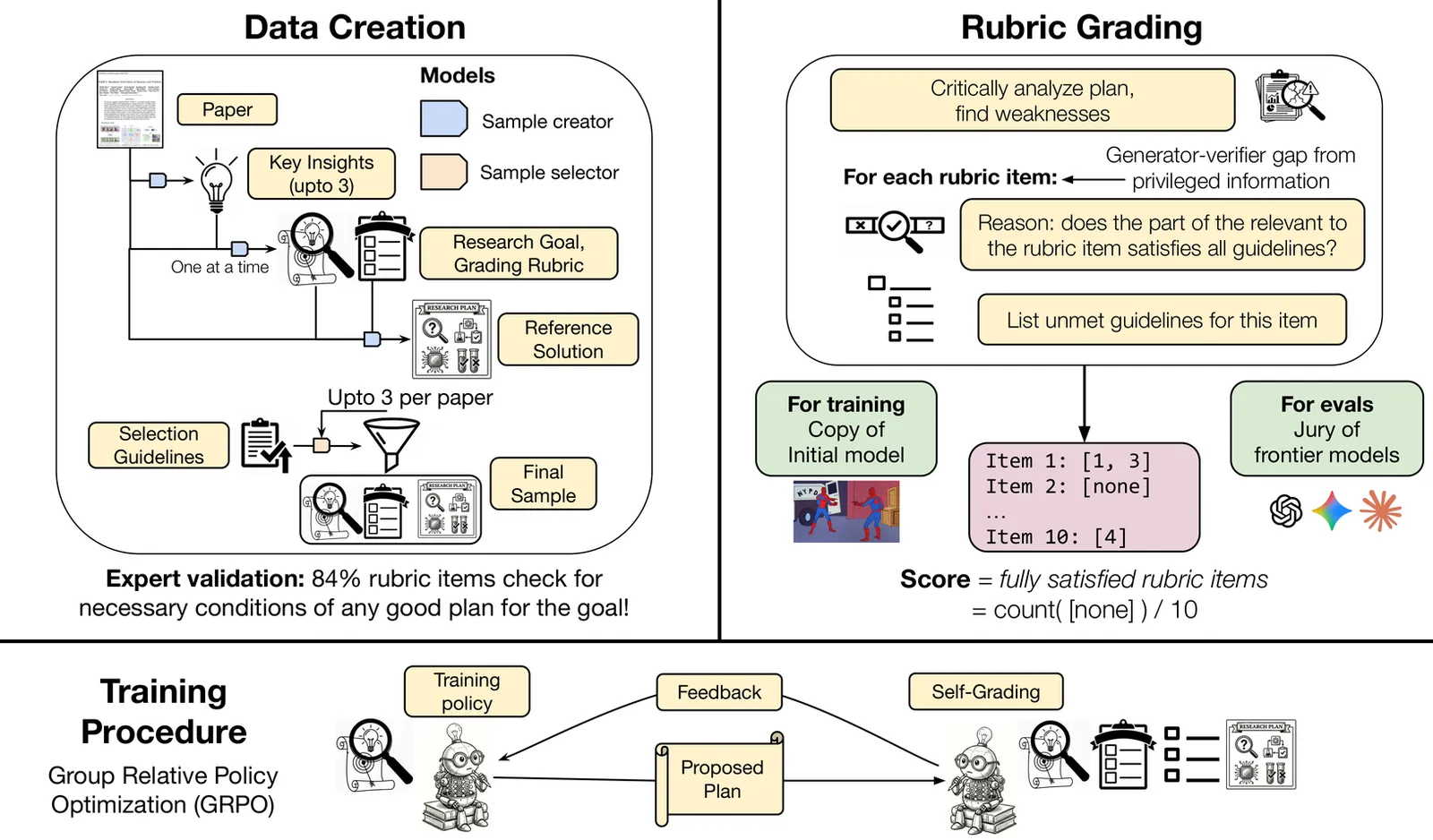
AI co-scientists are emerging as a tool to assist human researchers in achieving their research goals. A crucial feature of these AI co-scientists is the ability to generate a research plan given a set of aims and constraints. The plan may be used by researchers for brainstorming, or may even be implemented after further refinement. However, language models currently struggle to generate research plans that follow all constraints and implicit requirements. In this work, we study how to leverage the vast corpus of existing research papers to train language models that generate better research plans. We build a scalable, diverse training corpus by automatically extracting research goals and goal-specific grading rubrics from papers across several domains. We then train models for research plan generation via reinforcement learning with self-grading. A frozen copy of the initial policy acts as the grader during training, with the rubrics creating a generator-verifier gap that enables improvements without external human supervision. To validate this approach, we conduct a study with human experts for machine learning research goals, spanning 225 hours. The experts prefer plans generated by our finetuned Qwen3-30B-A3B model over the initial model for 70% of research goals, and approve 84% of the automatically extracted goal-specific grading rubrics. To assess generality, we also extend our approach to research goals from medical papers, and new arXiv preprints, evaluating with a jury of frontier models. Our finetuning yields 12-22% relative improvements and significant cross-domain generalization, proving effective even in problem settings like medical research where execution feedback is infeasible. Together, these findings demonstrate the potential of a scalable, automated training recipe as a step towards improving general AI co-scientists.
We prove tight lower bounds for online multicalibration, establishing an information-theoretic separation from marginal calibration. In the general setting where group functions can depend on both context and the learner's predictions, we prove an $Ω(T^{2/3})$ lower bound on expected multicalibration error using just three disjoint binary groups. This matches the upper bounds of Noarov et al. (2025) up to logarithmic factors and exceeds the $O(T^{2/3-\varepsilon})$ upper bound for marginal calibration (Dagan et al., 2025), thereby separating the two problems. We then turn to lower bounds for the more difficult case of group functions that may depend on context but not on the learner's predictions. In this case, we establish an $\widetildeΩ(T^{2/3})$ lower bound for online multicalibration via a $Θ(T)$-sized group family constructed using orthogonal function systems, again matching upper bounds up to logarithmic factors.
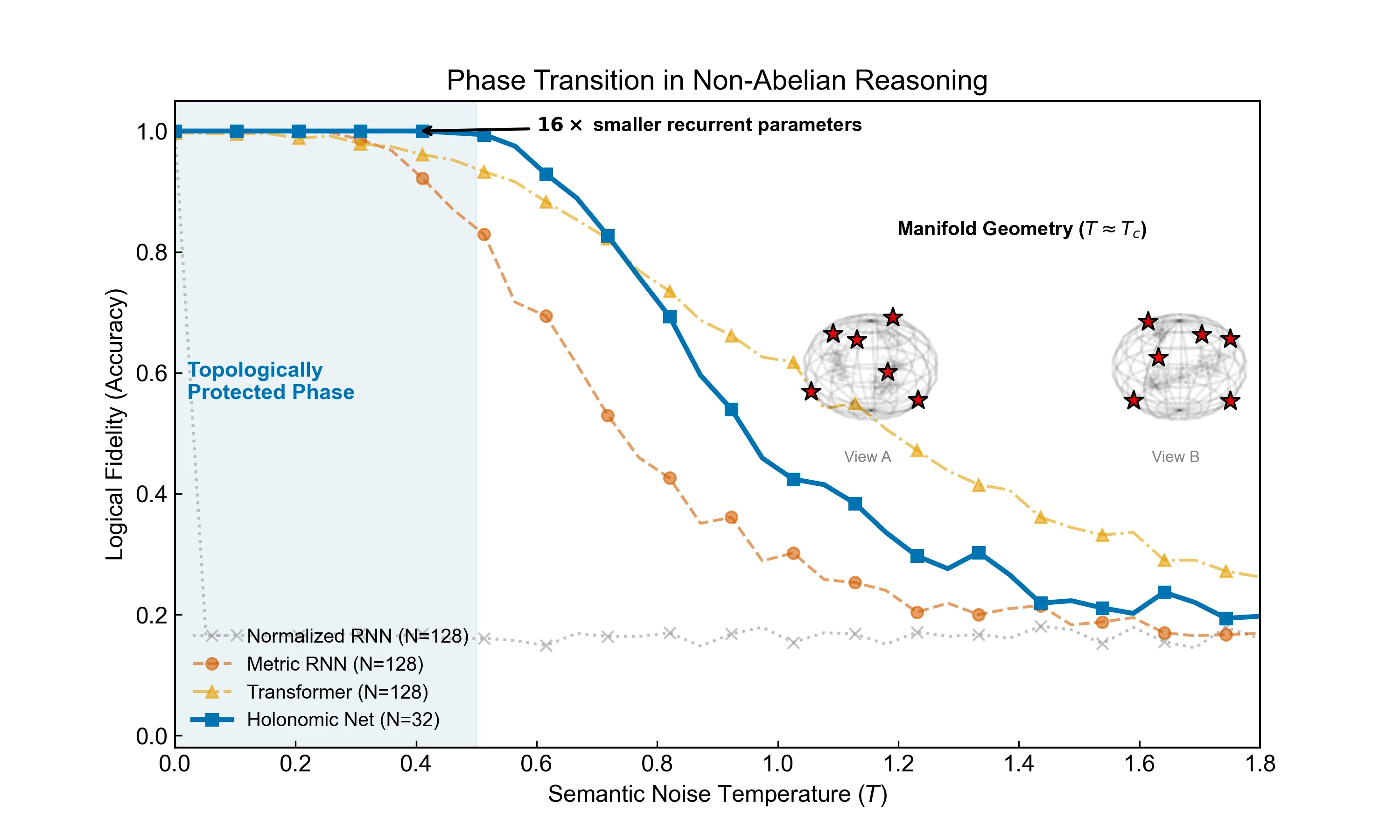
Large language models suffer from "hallucinations"-logical inconsistencies induced by semantic noise. We propose that current architectures operate in a "Metric Phase," where causal order is vulnerable to spontaneous symmetry breaking. Here, we identify robust inference as an effective Symmetry-Protected Topological phase, where logical operations are formally isomorphic to non-Abelian anyon braiding, replacing fragile geometric interpolation with robust topological invariants. Empirically, we demonstrate a sharp topological phase transition: while Transformers and RNNs exhibit gapless decay, our Holonomic Network reveals a macroscopic "mass gap," maintaining invariant fidelity below a critical noise threshold. Furthermore, in a variable-binding task on $S_{10}$ ($3.6 \times 10^6$ states) representing symbolic manipulation, we demonstrate holonomic generalization: the topological model maintains perfect fidelity extrapolating $100\times$ beyond training ($L=50 \to 5000$), consistent with a theoretically indefinite causal horizon, whereas Transformers lose logical coherence. Ablation studies indicate this protection emerges strictly from non-Abelian gauge symmetry. This provides strong evidence for a new universality class for logical reasoning, linking causal stability to the topology of the semantic manifold.
I propose a novel framework that integrates stochastic differential equations (SDEs) with deep generative models to improve uncertainty quantification in machine learning applications involving structured and temporal data. This approach, termed Stochastic Latent Differential Inference (SLDI), embeds an Itô SDE in the latent space of a variational autoencoder, allowing for flexible, continuous-time modeling of uncertainty while preserving a principled mathematical foundation. The drift and diffusion terms of the SDE are parameterized by neural networks, enabling data-driven inference and generalizing classical time series models to handle irregular sampling and complex dynamic structure. A central theoretical contribution is the co-parameterization of the adjoint state with a dedicated neural network, forming a coupled forward-backward system that captures not only latent evolution but also gradient dynamics. I introduce a pathwise-regularized adjoint loss and analyze variance-reduced gradient flows through the lens of stochastic calculus, offering new tools for improving training stability in deep latent SDEs. My paper unifies and extends variational inference, continuous-time generative modeling, and control-theoretic optimization, providing a rigorous foundation for future developments in stochastic probabilistic machine learning.

One-shot prediction enables rapid adaptation of pretrained foundation models to new tasks using only one labeled example, but lacks principled uncertainty quantification. While conformal prediction provides finite-sample coverage guarantees, standard split conformal methods are inefficient in the one-shot setting due to data splitting and reliance on a single predictor. We propose Conformal Aggregation of One-Shot Predictors (CAOS), a conformal framework that adaptively aggregates multiple one-shot predictors and uses a leave-one-out calibration scheme to fully exploit scarce labeled data. Despite violating classical exchangeability assumptions, we prove that CAOS achieves valid marginal coverage using a monotonicity-based argument. Experiments on one-shot facial landmarking and RAFT text classification tasks show that CAOS produces substantially smaller prediction sets than split conformal baselines while maintaining reliable coverage.
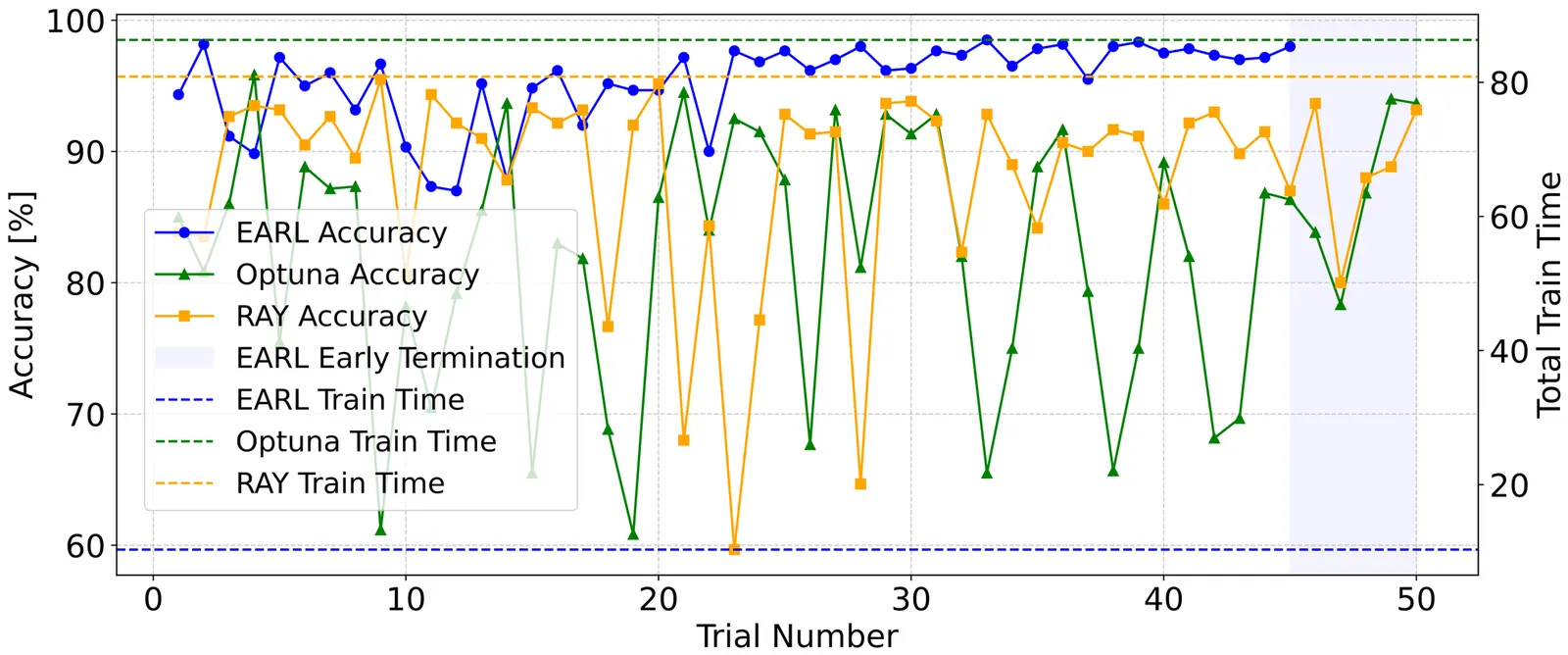
Pervasive AI increasingly depends on on-device learning systems that deliver low-latency and energy-efficient computation under strict resource constraints. Liquid State Machines (LSMs) offer a promising approach for low-power temporal processing in pervasive and neuromorphic systems, but their deployment remains challenging due to high hyperparameter sensitivity and the computational cost of traditional optimization methods that ignore energy constraints. This work presents EARL, an energy-aware reinforcement learning framework that integrates Bayesian optimization with an adaptive reinforcement learning based selection policy to jointly optimize accuracy and energy consumption. EARL employs surrogate modeling for global exploration, reinforcement learning for dynamic candidate prioritization, and an early termination mechanism to eliminate redundant evaluations, substantially reducing computational overhead. Experiments on three benchmark datasets demonstrate that EARL achieves 6 to 15 percent higher accuracy, 60 to 80 percent lower energy consumption, and up to an order of magnitude reduction in optimization time compared to leading hyperparameter tuning frameworks. These results highlight the effectiveness of energy-aware adaptive search in improving the efficiency and scalability of LSMs for resource-constrained on-device AI applications.
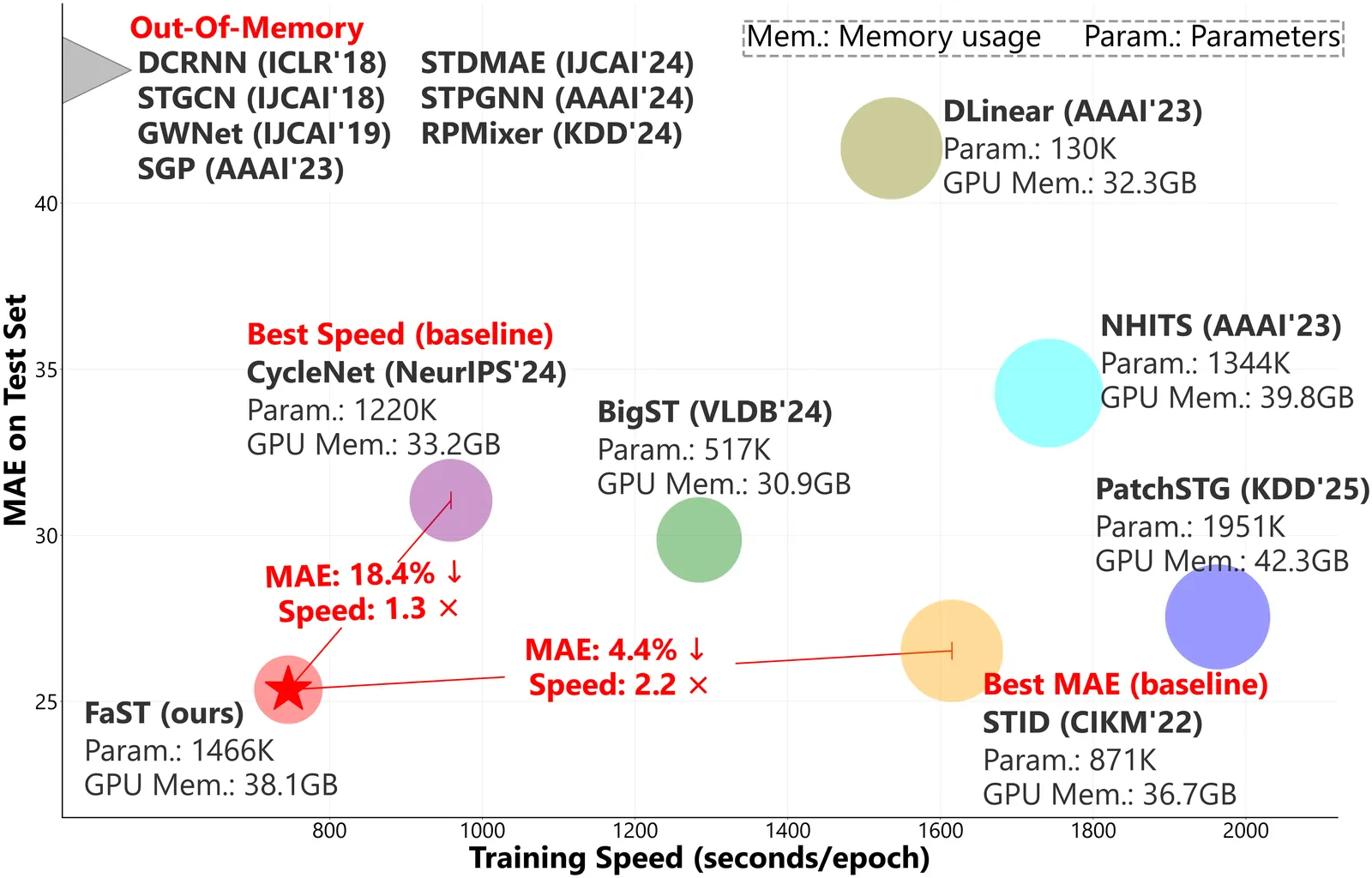
Spatial-Temporal Graph (STG) forecasting on large-scale networks has garnered significant attention. However, existing models predominantly focus on short-horizon predictions and suffer from notorious computational costs and memory consumption when scaling to long-horizon predictions and large graphs. Targeting the above challenges, we present FaST, an effective and efficient framework based on heterogeneity-aware Mixture-of-Experts (MoEs) for long-horizon and large-scale STG forecasting, which unlocks one-week-ahead (672 steps at a 15-minute granularity) prediction with thousands of nodes. FaST is underpinned by two key innovations. First, an adaptive graph agent attention mechanism is proposed to alleviate the computational burden inherent in conventional graph convolution and self-attention modules when applied to large-scale graphs. Second, we propose a new parallel MoE module that replaces traditional feed-forward networks with Gated Linear Units (GLUs), enabling an efficient and scalable parallel structure. Extensive experiments on real-world datasets demonstrate that FaST not only delivers superior long-horizon predictive accuracy but also achieves remarkable computational efficiency compared to state-of-the-art baselines. Our source code is available at: https://github.com/yijizhao/FaST.
This work provides a state-of-the-art survey of continual safe online reinforcement learning (COSRL) methods. We discuss theoretical aspects, challenges, and open questions in building continual online safe reinforcement learning algorithms. We provide the taxonomy and the details of continual online safe reinforcement learning methods based on the type of safe learning mechanism that takes adaptation to nonstationarity into account. We categorize safety constraints formulation for online reinforcement learning algorithms, and finally, we discuss prospects for creating reliable, safe online learning algorithms. Keywords: safe RL in nonstationary environments, safe continual reinforcement learning under nonstationarity, HM-MDP, NSMDP, POMDP, safe POMDP, constraints for continual learning, safe continual reinforcement learning review, safe continual reinforcement learning survey, safe continual reinforcement learning, safe online learning under distribution shift, safe continual online adaptation, safe reinforcement learning, safe exploration, safe adaptation, constrained Markov decision processes, safe reinforcement learning, partially observable Markov decision process, safe reinforcement learning and hidden Markov decision processes, Safe Online Reinforcement Learning, safe online reinforcement learning, safe online reinforcement learning, safe meta-learning, safe meta-reinforcement learning, safe context-based reinforcement learning, formulating safety constraints for continual learning
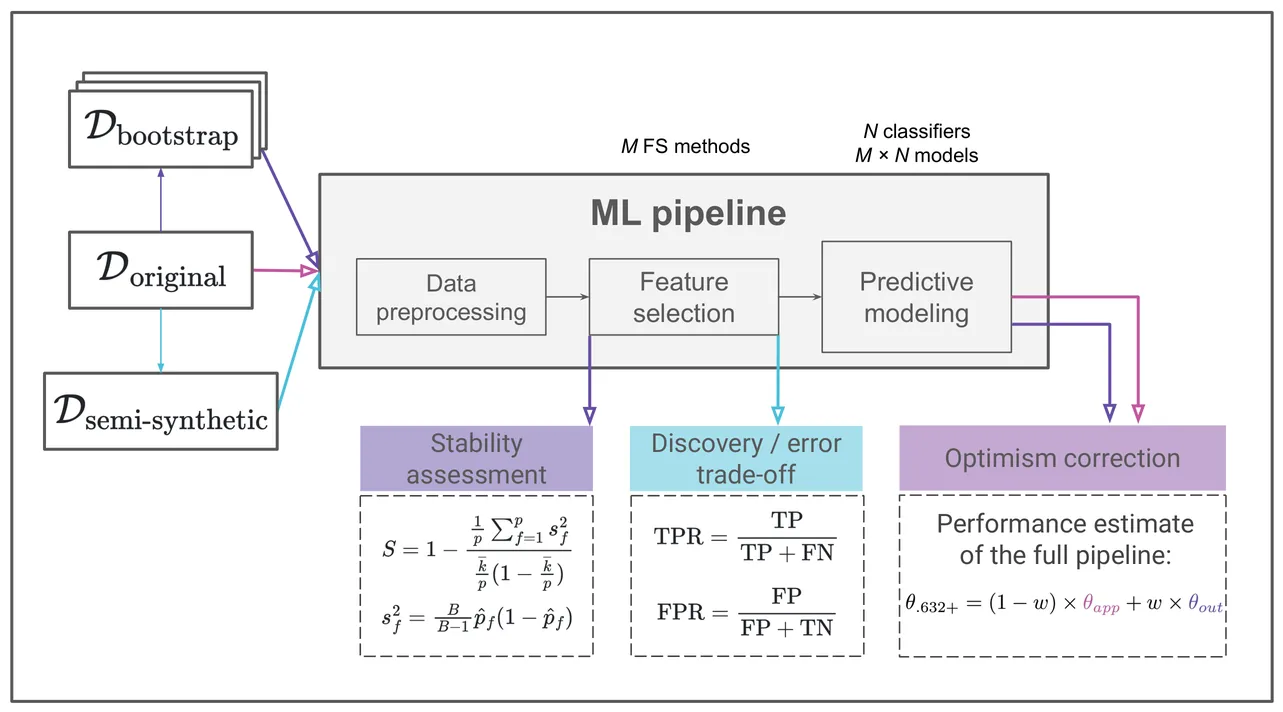
Feature selection (FS) is essential for biomarker discovery and in the analysis of biomedical datasets. However, challenges such as high-dimensional feature space, low sample size, multicollinearity, and missing values make FS non-trivial. Moreover, FS performances vary across datasets and predictive tasks. We propose roofs, a Python package available at https://gitlab.inria.fr/compo/roofs, designed to help researchers in the choice of FS method adapted to their problem. Roofs benchmarks multiple FS methods on the user's data and generates reports that summarize a comprehensive set of evaluation metrics, including downstream predictive performance estimated using optimism correction, stability, reliability of individual features, and true positive and false positive rates assessed on semi-synthetic data with a simulated outcome. We demonstrate the utility of roofs on data from the PIONeeR clinical trial, aimed at identifying predictors of resistance to anti-PD-(L)1 immunotherapy in lung cancer. The PIONeeR dataset contained 374 multi-source blood and tumor biomarkers from 435 patients. A reduced subset of 214 features was obtained through iterative variance inflation factor pre-filtering. Of the 34 FS methods gathered in roofs, we evaluated 23 in combination with 11 classifiers (253 models in total) and identified a filter based on the union of Benjamini-Hochberg false discovery rate-adjusted p-values from t-test and logistic regression as the optimal approach, outperforming other methods including the widely used LASSO. We conclude that comprehensive benchmarking with roofs has the potential to improve the robustness and reproducibility of FS discoveries and increase the translational value of clinical models.
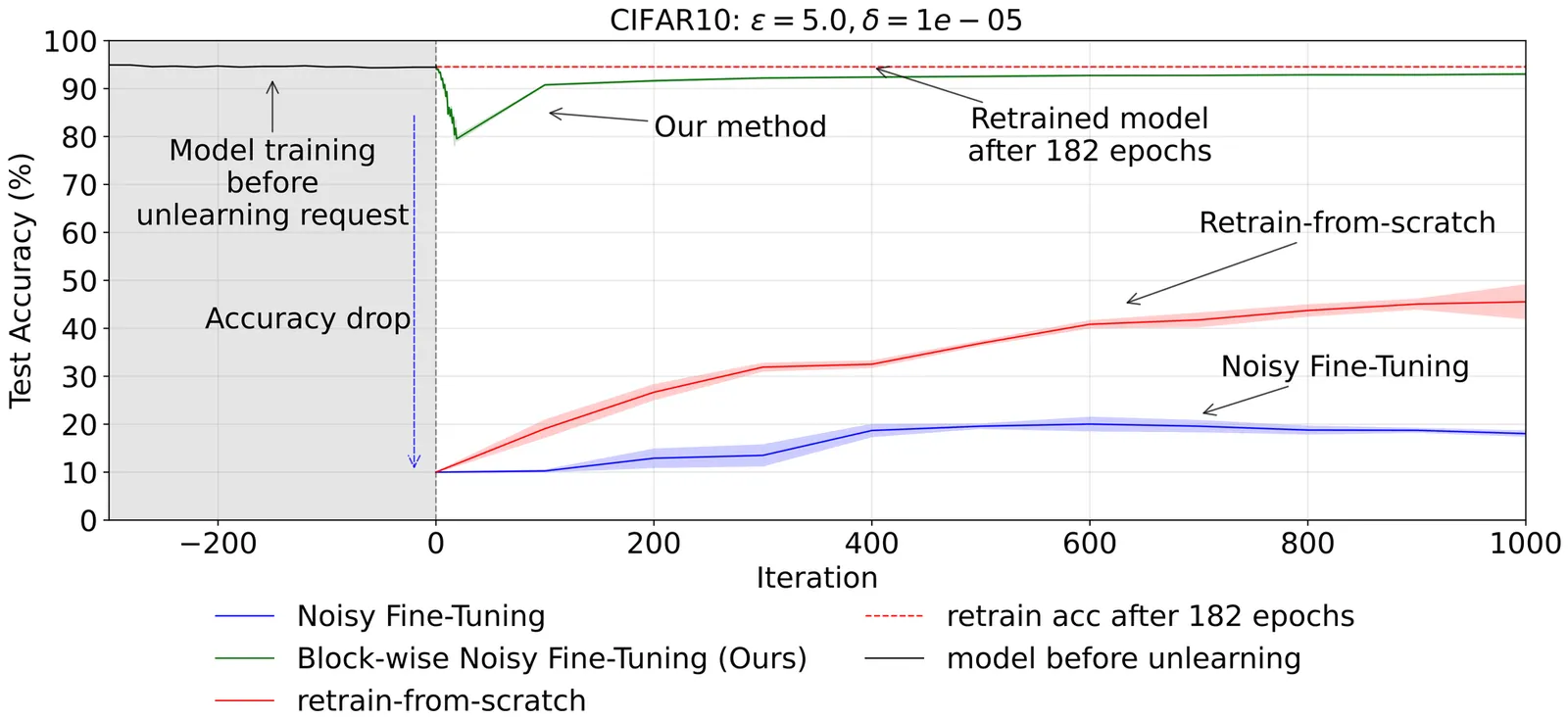
Certified unlearning based on differential privacy offers strong guarantees but remains largely impractical: the noisy fine-tuning approaches proposed so far achieve these guarantees but severely reduce model accuracy. We propose sequential noise scheduling, which distributes the noise budget across orthogonal subspaces of the parameter space, rather than injecting it all at once. This simple modification mitigates the destructive effect of noise while preserving the original certification guarantees. We extend the analysis of noisy fine-tuning to the subspace setting, proving that the same $(\varepsilon,δ)$ privacy budget is retained. Empirical results on image classification benchmarks show that our approach substantially improves accuracy after unlearning while remaining robust to membership inference attacks. These results show that certified unlearning can achieve both rigorous guarantees and practical utility.
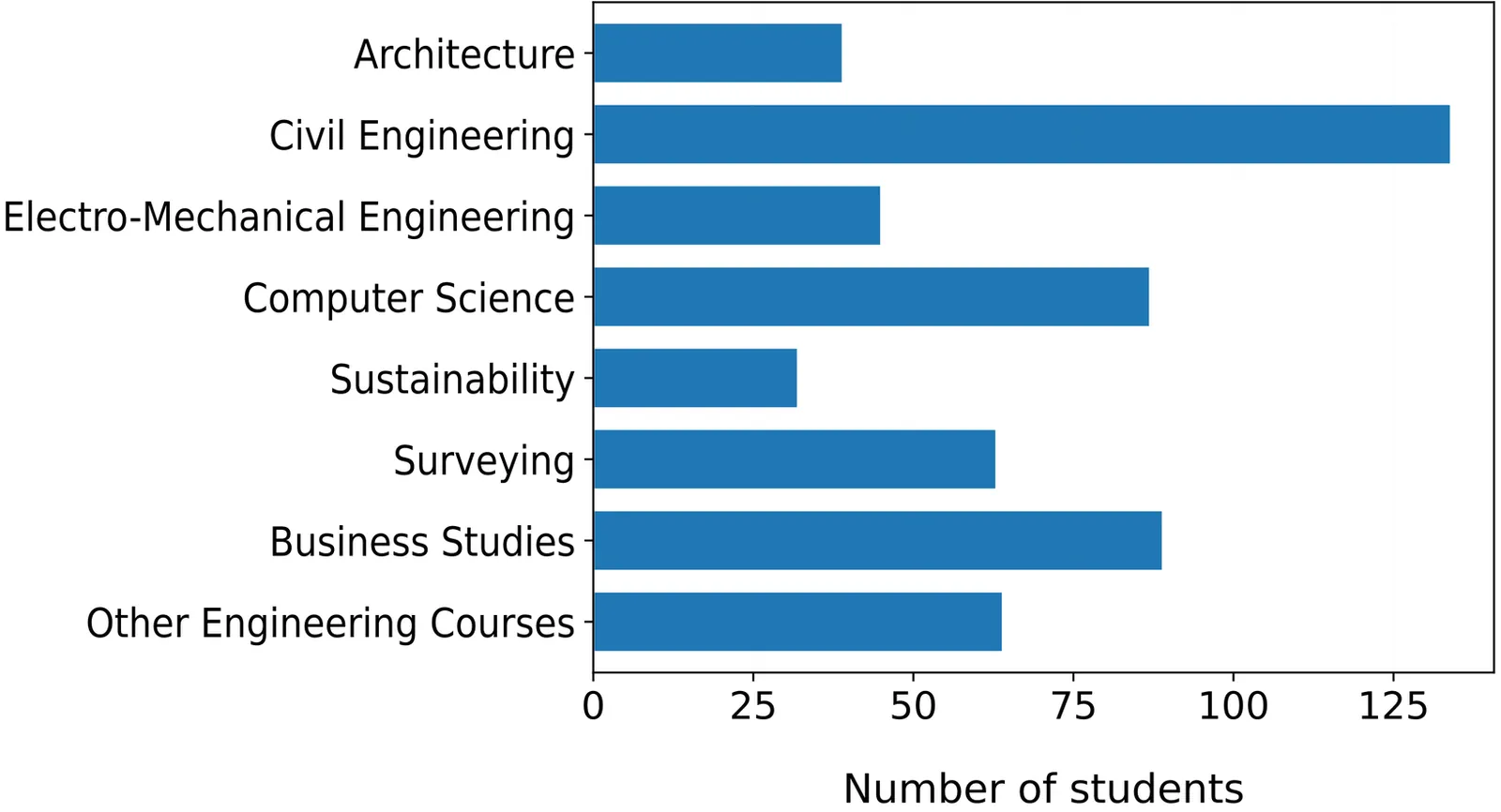
Learning Analytics (LA) is nowadays ubiquitous in many educational systems, providing the ability to collect and analyze student data in order to understand and optimize learning and the environments in which it occurs. On the other hand, the collection of data requires to comply with the growing demand regarding privacy legislation. In this paper, we use the Student Expectation of Learning Analytics Questionnaire (SELAQ) to analyze the expectations and confidence of students from different faculties regarding the processing of their data for Learning Analytics purposes. This allows us to identify four clusters of students through clustering algorithms: Enthusiasts, Realists, Cautious and Indifferents. This structured analysis provides valuable insights into the acceptance and criticism of Learning Analytics among students.
Multimodal Large Language Models (MLLMs) struggle with complex geometric reasoning, largely because "black box" outcome-based supervision fails to distinguish between lucky guesses and rigorous deduction. To address this, we introduce a paradigm shift towards subgoal-level evaluation and learning. We first construct GeoGoal, a benchmark synthesized via a rigorous formal verification data engine, which converts abstract proofs into verifiable numeric subgoals. This structure reveals a critical divergence between reasoning quality and outcome accuracy. Leveraging this, we propose the Sub-Goal Verifiable Reward (SGVR) framework, which replaces sparse signals with dense rewards based on the Skeleton Rate. Experiments demonstrate that SGVR not only enhances geometric performance (+9.7%) but also exhibits strong generalization, transferring gains to general math (+8.0%) and other general reasoning tasks (+2.8%), demonstrating broad applicability across diverse domains.
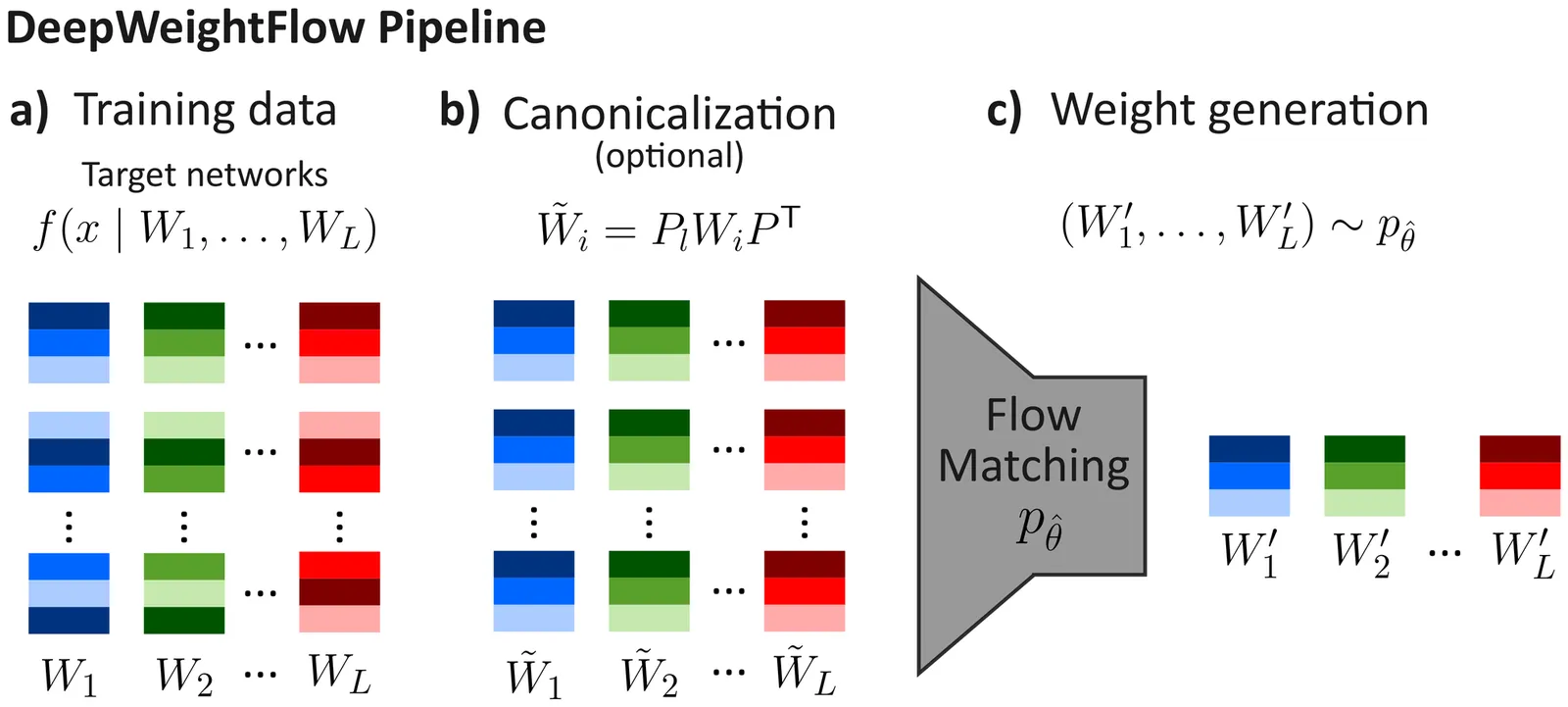
Building efficient and effective generative models for neural network weights has been a research focus of significant interest that faces challenges posed by the high-dimensional weight spaces of modern neural networks and their symmetries. Several prior generative models are limited to generating partial neural network weights, particularly for larger models, such as ResNet and ViT. Those that do generate complete weights struggle with generation speed or require finetuning of the generated models. In this work, we present DeepWeightFlow, a Flow Matching model that operates directly in weight space to generate diverse and high-accuracy neural network weights for a variety of architectures, neural network sizes, and data modalities. The neural networks generated by DeepWeightFlow do not require fine-tuning to perform well and can scale to large networks. We apply Git Re-Basin and TransFusion for neural network canonicalization in the context of generative weight models to account for the impact of neural network permutation symmetries and to improve generation efficiency for larger model sizes. The generated networks excel at transfer learning, and ensembles of hundreds of neural networks can be generated in minutes, far exceeding the efficiency of diffusion-based methods. DeepWeightFlow models pave the way for more efficient and scalable generation of diverse sets of neural networks.

Equivariance is a powerful inductive bias in neural networks, improving generalisation and physical consistency. Recently, however, non-equivariant models have regained attention, due to their better runtime performance and imperfect symmetries that might arise in real-world applications. This has motivated the development of approximately equivariant models that strike a middle ground between respecting symmetries and fitting the data distribution. Existing approaches in this field usually apply sample-based regularisers which depend on data augmentation at training time, incurring a high sample complexity, in particular for continuous groups such as $SO(3)$. This work instead approaches approximate equivariance via a projection-based regulariser which leverages the orthogonal decomposition of linear layers into equivariant and non-equivariant components. In contrast to existing methods, this penalises non-equivariance at an operator level across the full group orbit, rather than point-wise. We present a mathematical framework for computing the non-equivariance penalty exactly and efficiently in both the spatial and spectral domain. In our experiments, our method consistently outperforms prior approximate equivariance approaches in both model performance and efficiency, achieving substantial runtime gains over sample-based regularisers.
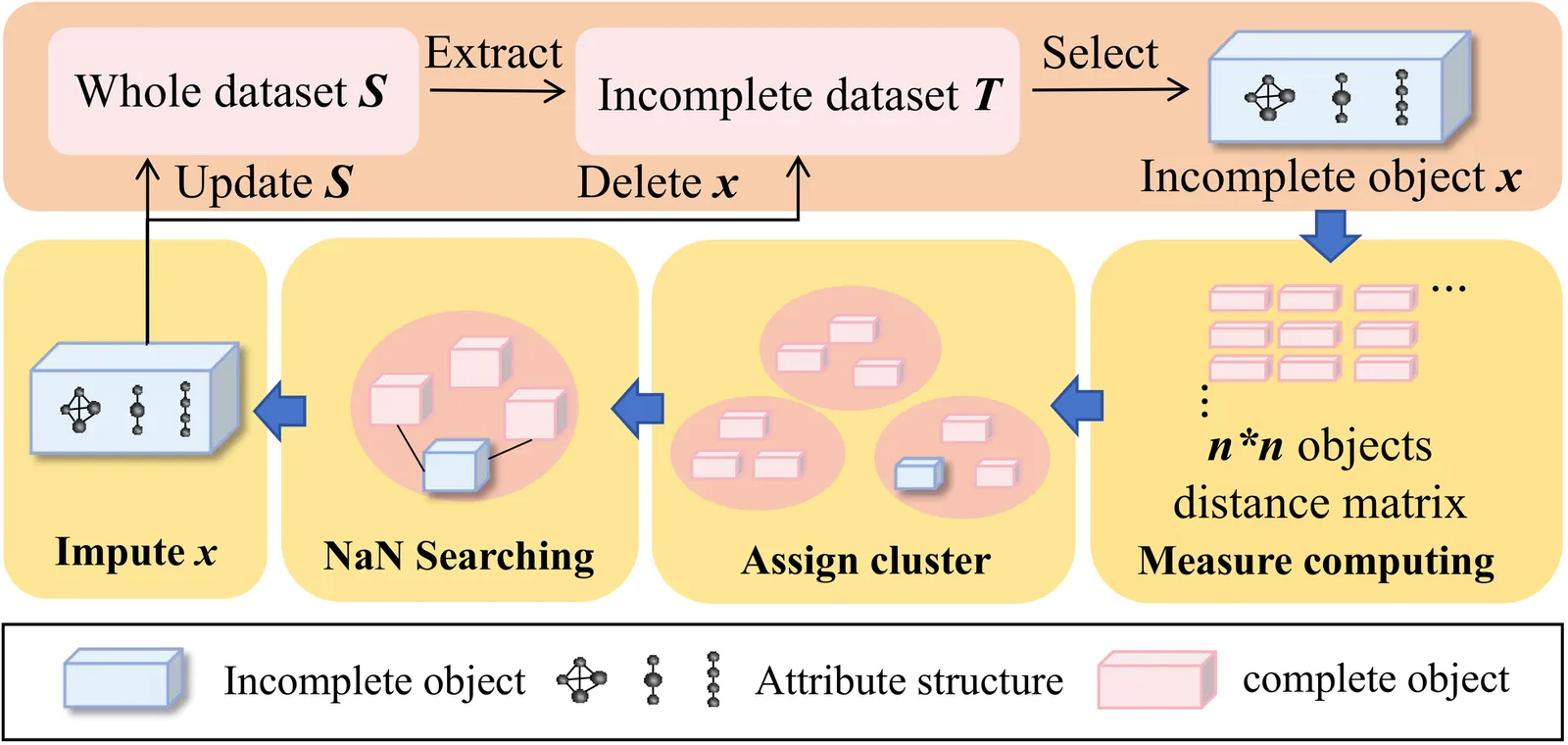
Missing value imputation is a fundamental challenge in machine intelligence, heavily dependent on data completeness. Current imputation methods often handle numerical and categorical attributes independently, overlooking critical interdependencies among heterogeneous features. To address these limitations, we propose a novel imputation approach that explicitly models cross-type feature dependencies within a unified framework. Our method leverages both complete and incomplete instances to ensure accurate and consistent imputation in tabular data. Extensive experimental results demonstrate that the proposed approach achieves superior performance over existing techniques and significantly enhances downstream machine learning tasks, providing a robust solution for real-world systems with missing data.
Group-based reinforcement learning methods, like Group Relative Policy Optimization (GRPO), are widely used nowadays to post-train large language models. Despite their empirical success, they exhibit structural mismatches between reward optimization and the underlying training objective. In this paper, we present a theoretical analysis of GRPO style methods by studying them within a unified surrogate formulation. This perspective reveals recurring properties that affect all the methods under analysis: (i) non-uniform group weighting induces systematic gradient biases on shared prefix tokens; (ii) interactions with the AdamW optimizer make training dynamics largely insensitive to reward scaling; and (iii) optimizer momentum can push policy updates beyond the intended clipping region under repeated optimization steps. We believe that these findings highlight fundamental limitations of current approaches and provide principled guidance for the design of future formulations.
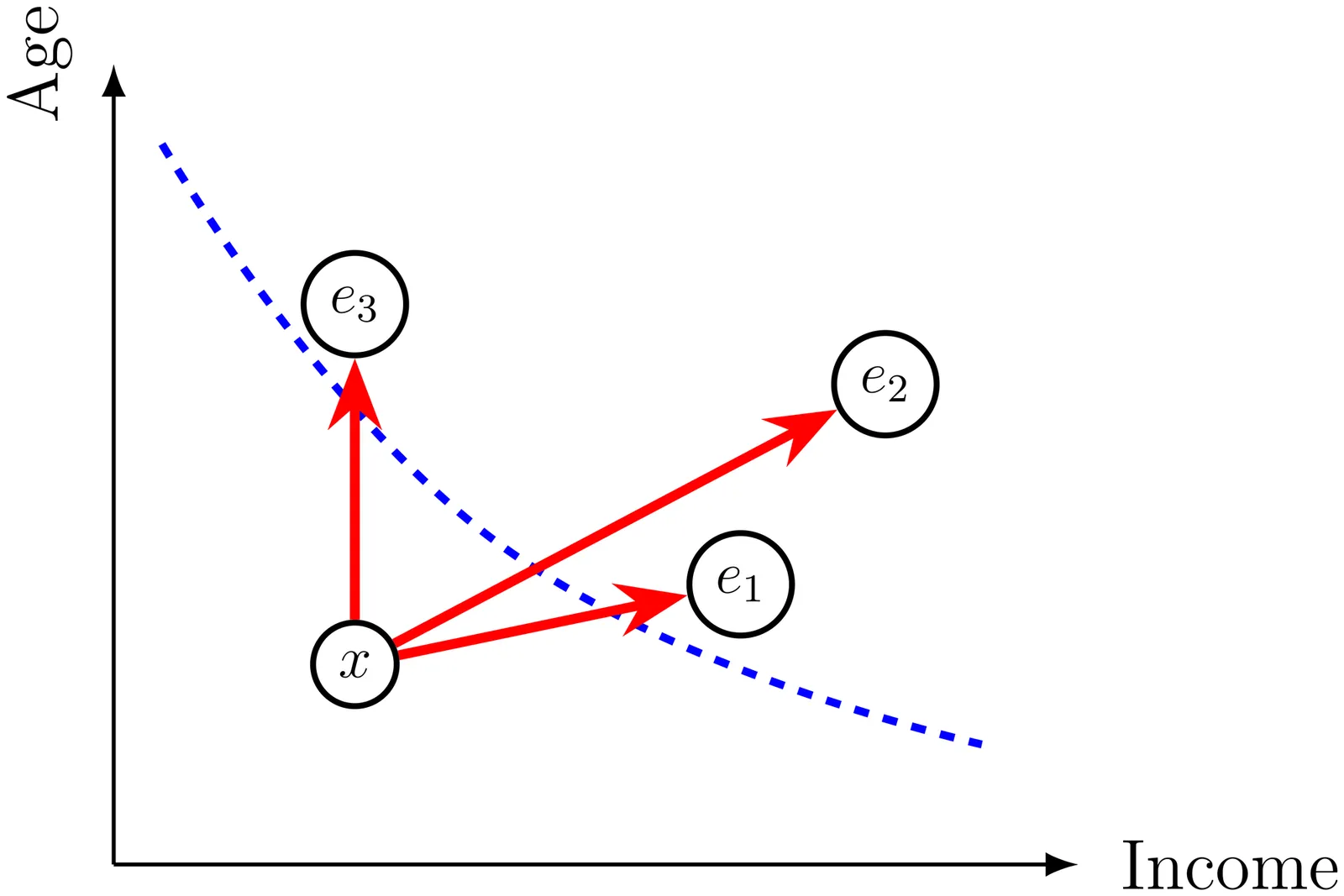
Counterfactual explanations are widely used to communicate how inputs must change for a model to alter its prediction. For a single instance, many valid counterfactuals can exist, which leaves open the possibility for an explanation provider to cherry-pick explanations that better suit a narrative of their choice, highlighting favourable behaviour and withholding examples that reveal problematic behaviour. We formally define cherry-picking for counterfactual explanations in terms of an admissible explanation space, specified by the generation procedure, and a utility function. We then study to what extent an external auditor can detect such manipulation. Considering three levels of access to the explanation process: full procedural access, partial procedural access, and explanation-only access, we show that detection is extremely limited in practice. Even with full procedural access, cherry-picked explanations can remain difficult to distinguish from non cherry-picked explanations, because the multiplicity of valid counterfactuals and flexibility in the explanation specification provide sufficient degrees of freedom to mask deliberate selection. Empirically, we demonstrate that this variability often exceeds the effect of cherry-picking on standard counterfactual quality metrics such as proximity, plausibility, and sparsity, making cherry-picked explanations statistically indistinguishable from baseline explanations. We argue that safeguards should therefore prioritise reproducibility, standardisation, and procedural constraints over post-hoc detection, and we provide recommendations for algorithm developers, explanation providers, and auditors.
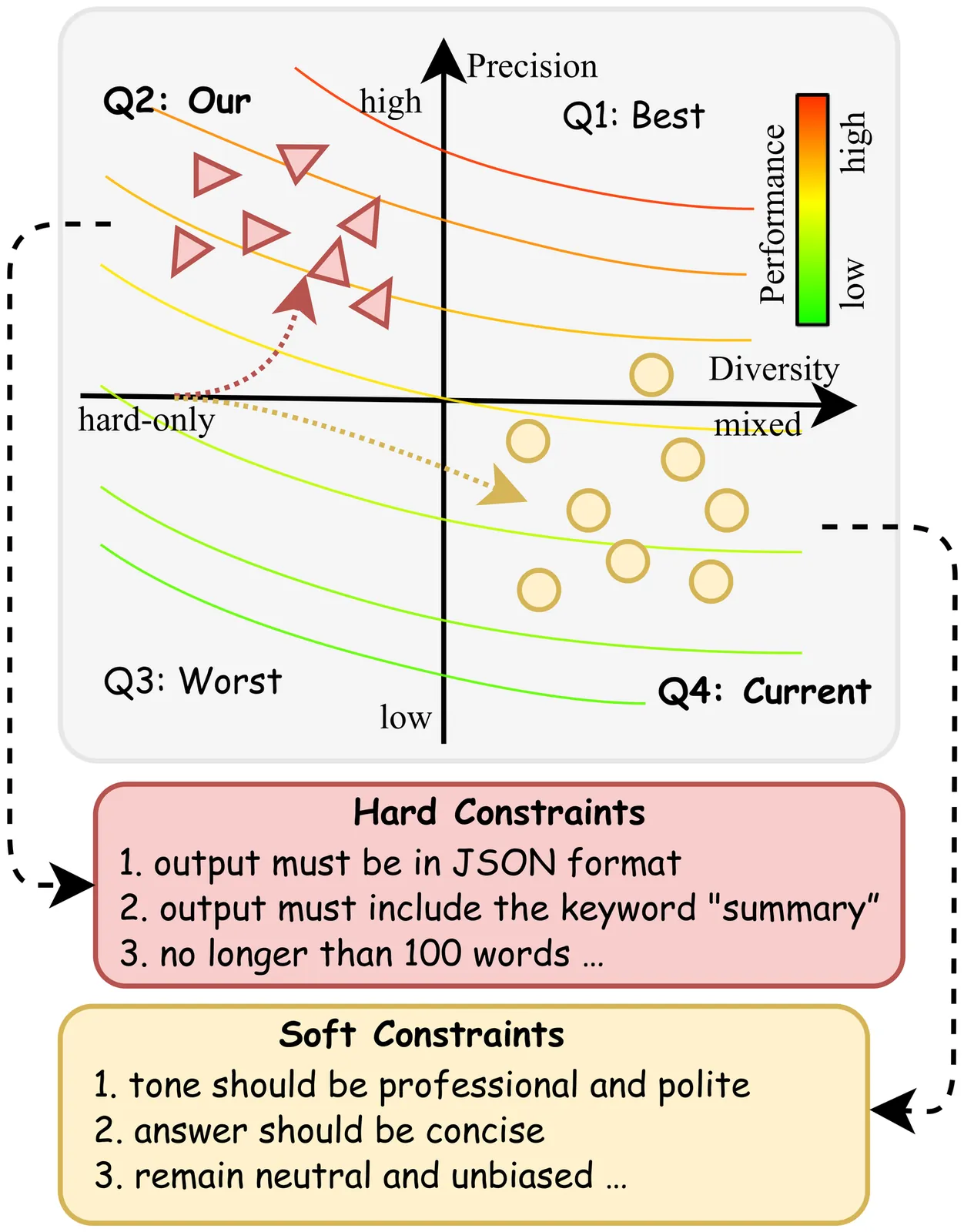
A central belief in scaling reinforcement learning with verifiable rewards for instruction following (IF) tasks is that, a diverse mixture of verifiable hard and unverifiable soft constraints is essential for generalizing to unseen instructions. In this work, we challenge this prevailing consensus through a systematic empirical investigation. Counter-intuitively, we find that models trained on hard-only constraints consistently outperform those trained on mixed datasets. Extensive experiments reveal that reward precision, rather than constraint diversity, is the primary driver of effective alignment. The LLM judge suffers from a low recall rate in detecting false response, which leads to severe reward hacking, thereby undermining the benefits of diversity. Furthermore, analysis of the attention mechanism reveals that high-precision rewards develop a transferable meta-skill for IF. Motivated by these insights, we propose a simple yet effective data-centric refinement strategy that prioritizes reward precision. Evaluated on five benchmarks, our approach outperforms competitive baselines by 13.4\% in performance while achieving a 58\% reduction in training time, maintaining strong generalization beyond instruction following. Our findings advocate for a paradigm shift: moving away from the indiscriminate pursuit of data diversity toward high-precision rewards.
Class imbalance is a common and pernicious issue for the training of neural networks. Often, an imbalanced majority class can dominate training to skew classifier performance towards the majority outcome. To address this problem we introduce cardinality augmented loss functions, derived from cardinality-like invariants in modern mathematics literature such as magnitude and the spread. These invariants enrich the concept of cardinality by evaluating the `effective diversity' of a metric space, and as such represent a natural solution to overly homogeneous training data. In this work, we establish a methodology for applying cardinality augmented loss functions in the training of neural networks and report results on both artificially imbalanced datasets as well as a real-world imbalanced material science dataset. We observe significant performance improvement among minority classes, as well as improvement in overall performance metrics.
We investigate distributed online convex optimization with compressed communication, where $n$ learners connected by a network collaboratively minimize a sequence of global loss functions using only local information and compressed data from neighbors. Prior work has established regret bounds of $O(\max\{ω^{-2}ρ^{-4}n^{1/2},ω^{-4}ρ^{-8}\}n\sqrt{T})$ and $O(\max\{ω^{-2}ρ^{-4}n^{1/2},ω^{-4}ρ^{-8}\}n\ln{T})$ for convex and strongly convex functions, respectively, where $ω\in(0,1]$ is the compression quality factor ($ω=1$ means no compression) and $ρ<1$ is the spectral gap of the communication matrix. However, these regret bounds suffer from a \emph{quadratic} or even \emph{quartic} dependence on $ω^{-1}$. Moreover, the \emph{super-linear} dependence on $n$ is also undesirable. To overcome these limitations, we propose a novel algorithm that achieves improved regret bounds of $\tilde{O}(ω^{-1/2}ρ^{-1}n\sqrt{T})$ and $\tilde{O}(ω^{-1}ρ^{-2}n\ln{T})$ for convex and strongly convex functions, respectively. The primary idea is to design a \emph{two-level blocking update framework} incorporating two novel ingredients: an online gossip strategy and an error compensation scheme, which collaborate to \emph{achieve a better consensus} among learners. Furthermore, we establish the first lower bounds for this problem, justifying the optimality of our results with respect to both $ω$ and $T$. Additionally, we consider the bandit feedback scenario, and extend our method with the classic gradient estimators to enhance existing regret bounds.
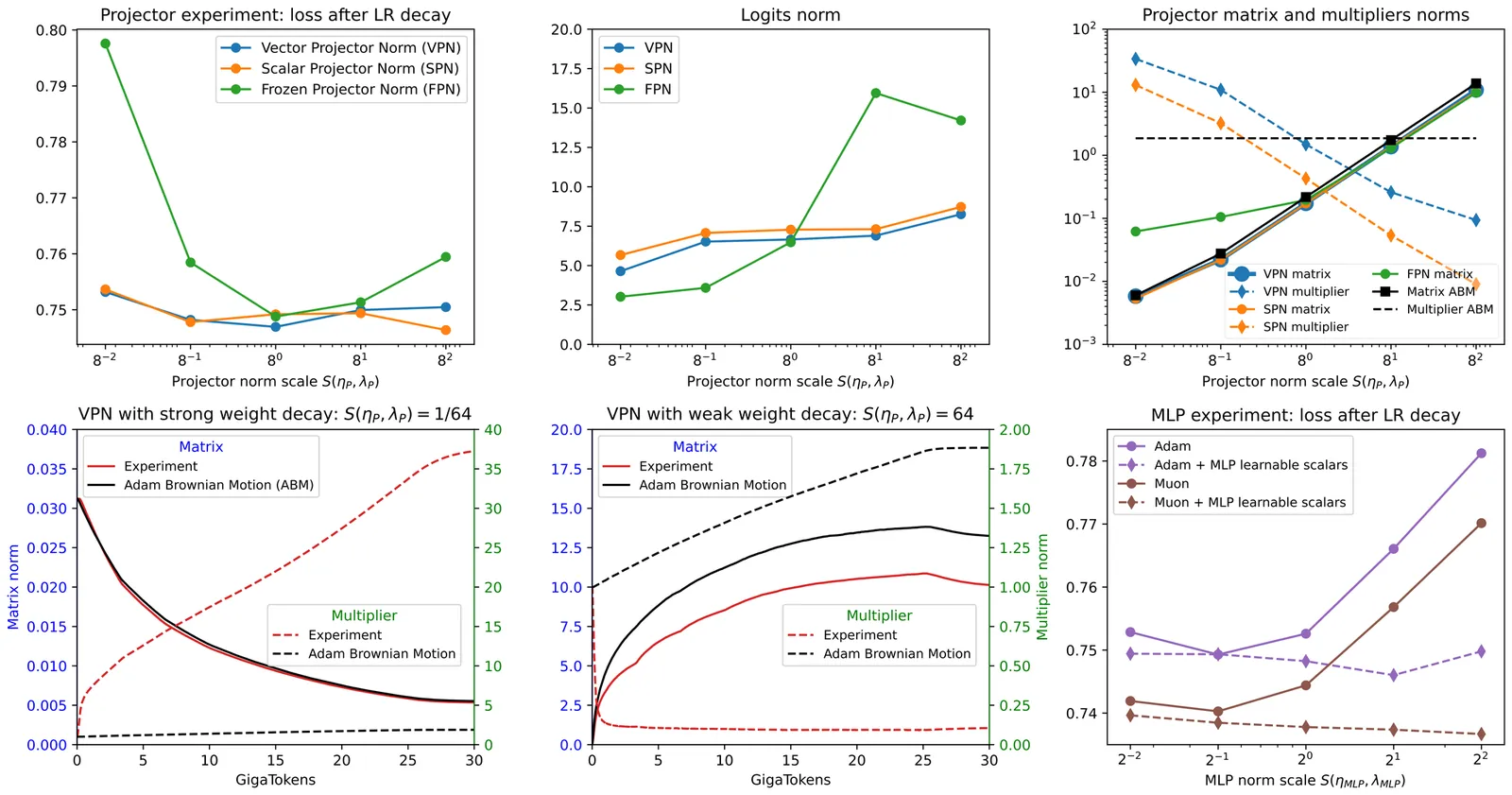
Applying weight decay (WD) to matrix layers is standard practice in large-language-model pretraining. Prior work suggests that stochastic gradient noise induces a Brownian-like expansion of the weight matrices W, whose growth is counteracted by WD, leading to a WD-noise equilibrium with a certain weight norm ||W||. In this work, we view the equilibrium norm as a harmful artifact of the training procedure, and address it by introducing learnable multipliers to learn the optimal scale. First, we attach a learnable scalar multiplier to W and confirm that the WD-noise equilibrium norm is suboptimal: the learned scale adapts to data and improves performance. We then argue that individual row and column norms are similarly constrained, and free their scale by introducing learnable per-row and per-column multipliers. Our method can be viewed as a learnable, more expressive generalization of muP multipliers. It outperforms a well-tuned muP baseline, reduces the computational overhead of multiplier tuning, and surfaces practical questions such as forward-pass symmetries and the width-scaling of the learned multipliers. Finally, we validate learnable multipliers with both Adam and Muon optimizers, where it shows improvement in downstream evaluations matching the improvement of the switching from Adam to Muon.