Distributed, Parallel, and Cluster Computing
arXiv:cs.DC
Covers fault-tolerance, distributed algorithms, stabilility, parallel computation, and cluster computing.
Looking for a broader view? This category is part of:
Covers fault-tolerance, distributed algorithms, stabilility, parallel computation, and cluster computing.
Looking for a broader view? This category is part of:
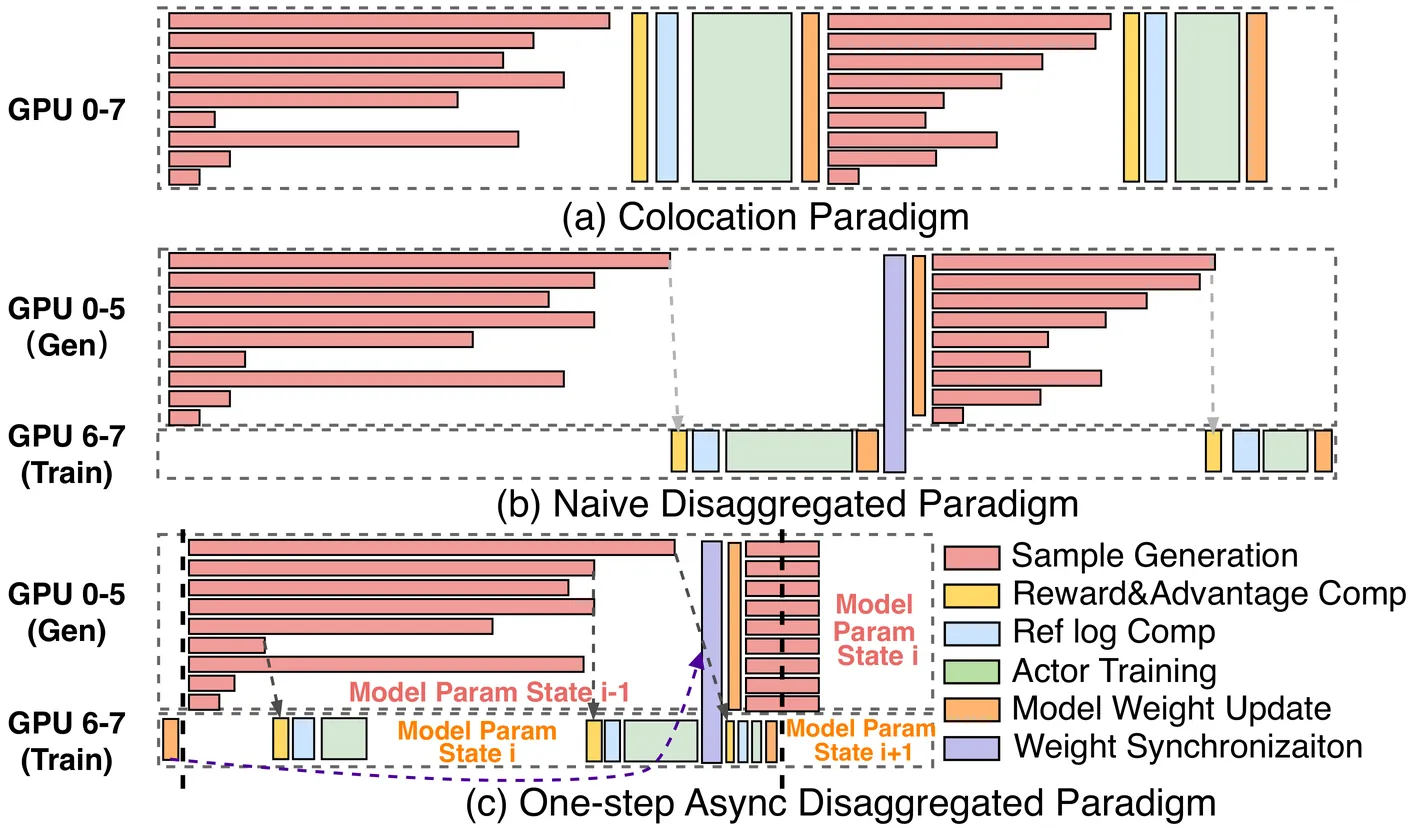
Post-training with reinforcement learning (RL) has greatly enhanced the capabilities of large language models. Disaggregating the generation and training stages in RL into a parallel, asynchronous pipeline offers the potential for flexible scaling and improved throughput. However, it still faces two critical challenges. First, the generation stage often becomes a bottleneck due to dynamic workload shifts and severe execution imbalances. Second, the decoupled stages result in diverse and dynamic network traffic patterns that overwhelm conventional network fabrics. This paper introduces OrchestrRL, an orchestration framework that dynamically manages compute and network rhythms in disaggregated RL. To improve generation efficiency, OrchestrRL employs an adaptive compute scheduler that dynamically adjusts parallelism to match workload characteristics within and across generation steps. This accelerates execution while continuously rebalancing requests to mitigate stragglers. To address the dynamic network demands inherent in disaggregated RL -- further intensified by parallelism switching -- we co-design RFabric, a reconfigurable hybrid optical-electrical fabric. RFabric leverages optical circuit switches at selected network tiers to reconfigure the topology in real time, enabling workload-aware circuits for (i) layer-wise collective communication during training iterations, (ii) generation under different parallelism configurations, and (iii) periodic inter-cluster weight synchronization. We evaluate OrchestrRL on a physical testbed with 48 H800 GPUs, demonstrating up to a 1.40x throughput improvement. Furthermore, we develop RLSim, a high-fidelity simulator, to evaluate RFabric at scale. Our results show that RFabric achieves superior performance-cost efficiency compared to static Fat-Tree networks, establishing it as a highly effective solution for large-scale RL workloads.
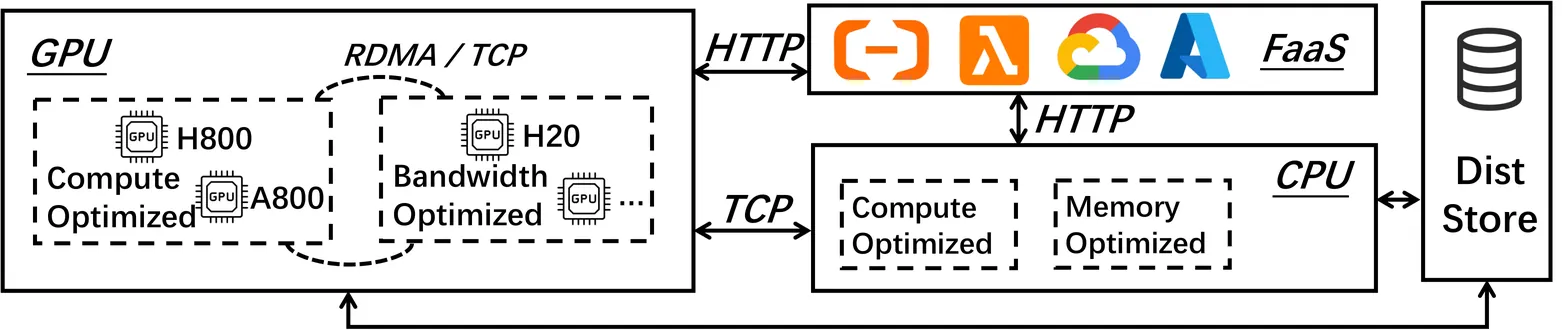
Agentic Reinforcement Learning (RL) enables Large Language Models (LLMs) to perform autonomous decision-making and long-term planning. Unlike standard LLM post-training, agentic RL workloads are highly heterogeneous, combining compute-intensive prefill phases, bandwidth-bound decoding, and stateful, CPU-heavy environment simulations. We argue that efficient agentic RL training requires disaggregated infrastructure to leverage specialized, best-fit hardware. However, naive disaggregation introduces substantial synchronization overhead and resource underutilization due to the complex dependencies between stages. We present RollArc, a distributed system designed to maximize throughput for multi-task agentic RL on disaggregated infrastructure. RollArc is built on three core principles: (1) hardware-affinity workload mapping, which routes compute-bound and bandwidth-bound tasks to bestfit GPU devices, (2) fine-grained asynchrony, which manages execution at the trajectory level to mitigate resource bubbles, and (3) statefulness-aware computation, which offloads stateless components (e.g., reward models) to serverless infrastructure for elastic scaling. Our results demonstrate that RollArc effectively improves training throughput and achieves 1.35-2.05\(\times\) end-to-end training time reduction compared to monolithic and synchronous baselines. We also evaluate RollArc by training a hundreds-of-billions-parameter MoE model for Qoder product on an Alibaba cluster with more than 3,000 GPUs, further demonstrating RollArc scalability and robustness. The code is available at https://github.com/alibaba/ROLL.

Recent advances in video analytics address real-time data drift by continuously retraining specialized, lightweight DNN models for individual cameras. However, the current practice of retraining a separate model for each camera suffers from high compute and communication costs, making it unscalable. We present ECCO, a new video analytics framework designed for resource-efficient continuous learning. The key insight is that the data drift, which necessitates model retraining, often shows temporal and spatial correlations across nearby cameras. By identifying cameras that experience similar drift and retraining a shared model for them, ECCO can substantially reduce the associated compute and communication costs. Specifically, ECCO introduces: (i) a lightweight grouping algorithm that dynamically forms and updates camera groups; (ii) a GPU allocator that dynamically assigns GPU resources across different groups to improve retraining accuracy and ensure fairness; and (iii) a transmission controller at each camera that configures frame sampling and coordinates bandwidth sharing with other cameras based on its assigned GPU resources. We conducted extensive evaluations on three distinctive datasets for two vision tasks. Compared to leading baselines, ECCO improves retraining accuracy by 6.7%-18.1% using the same compute and communication resources, or supports 3.3 times more concurrent cameras at the same accuracy.
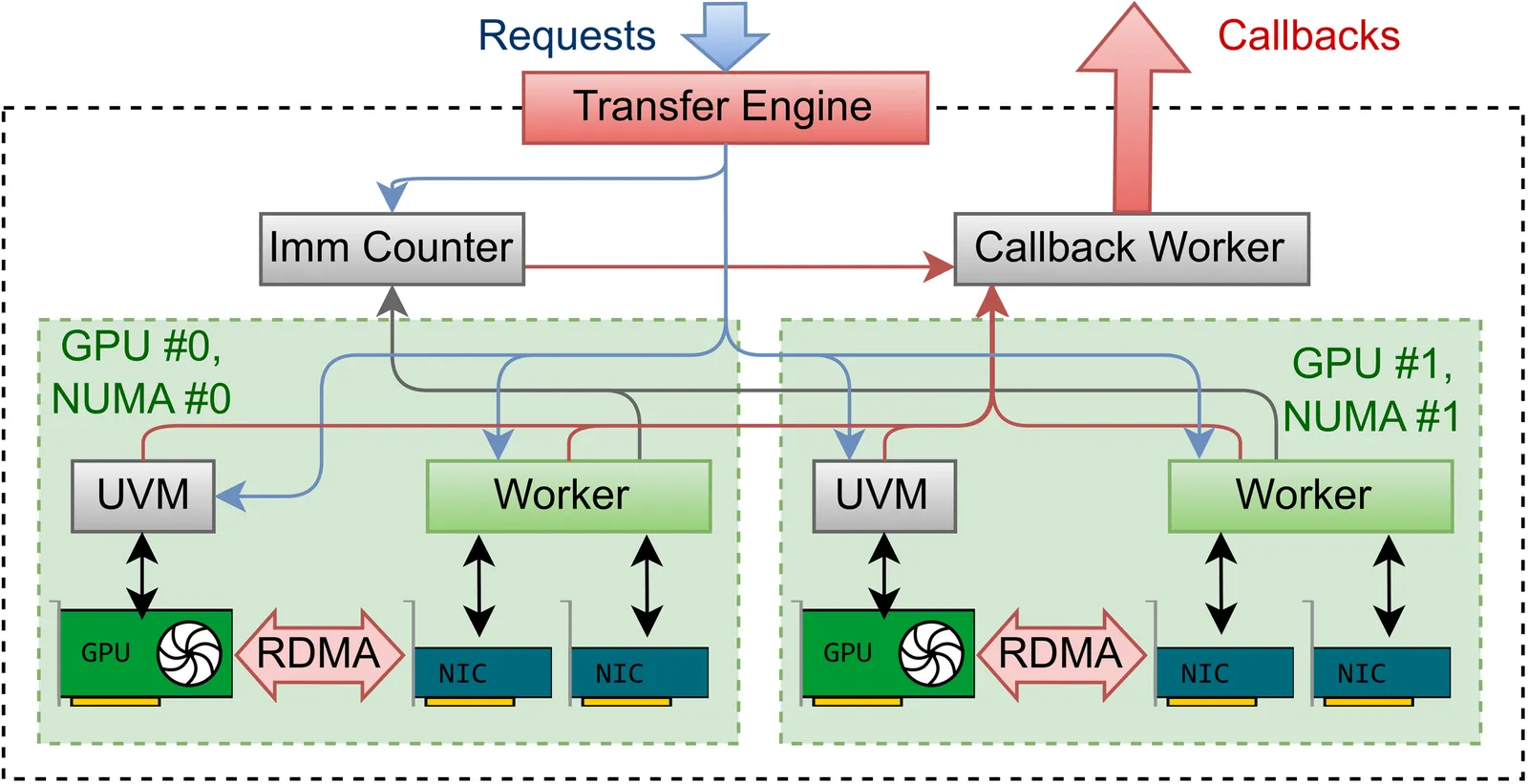
Emerging Large Language Model (LLM) system patterns, such as disaggregated inference, Mixture-of-Experts (MoE) routing, and asynchronous reinforcement fine-tuning, require flexible point-to-point communication beyond simple collectives. Existing implementations are locked to specific Network Interface Controllers (NICs), hindering integration into inference engines and portability across hardware providers. We present TransferEngine, which bridges the functionality of common NICs to expose a uniform interface. TransferEngine exposes one-sided WriteImm operations with a ImmCounter primitive for completion notification, without ordering assumptions of network transport, transparently managing multiple NICs per GPU. We demonstrate peak throughput of 400 Gbps on both NVIDIA ConnectX-7 and AWS Elastic Fabric Adapter (EFA). We showcase TransferEngine through three production systems: (1) KvCache transfer for disaggregated inference with dynamic scaling, (2) RL weight updates achieving 1.3 seconds for trillion-parameter models, and (3) MoE dispatch/combine implementation exceeding DeepEP decode latency on ConnectX-7, with the first viable latencies on EFA. We demonstrate that our portable point-to-point communication complements collectives while avoiding lock-in.
LLM-driven agentic applications increasingly automate complex, multi-step tasks, but serving them efficiently remains challenging due to heterogeneous components, dynamic and model-driven control flow, long-running state, and unpredictable latencies. Nalar is a ground-up agent-serving framework that cleanly separates workflow specification from execution while providing the runtime visibility and control needed for robust performance. Nalar preserves full Python expressiveness, using lightweight auto-generated stubs that turn agent and tool invocations into futures carrying dependency and context metadata. A managed state layer decouples logical state from physical placement, enabling safe reuse, migration, and consistent retry behavior. A two-level control architecture combines global policy computation with local event-driven enforcement to support adaptive routing, scheduling, and resource management across evolving workflows. Together, these mechanisms allow Nalar to deliver scalable, efficient, and policy-driven serving of heterogeneous agentic applications without burdening developers with orchestration logic. Across three agentic workloads, Nalar cuts tail latency by 34--74\%, achieves up to $2.9\times$ speedups, sustains 80 RPS where baselines fail, and scales to 130K futures with sub-500 ms control overhead.

Privacy-preserving federated averaging is a central approach for protecting client privacy in federated learning. In this paper, we study this problem in an asynchronous communications setting with malicious aggregators. We propose a new solution to provide federated averaging in this model while protecting the client's data privacy through secure aggregation and differential privacy. Our solution maintains the same performance as the state of the art across all metrics. The main contributions of this paper are threefold. First, unlike existing single- or multi-server solutions, we consider malicious aggregation servers that may manipulate the model to leak clients' data or halt computation. To tolerate this threat, we replicate the aggregators, allowing a fraction of them to be corrupted. Second, we propose a new privacy preservation protocol for protocols in asynchronous communication models with Byzantine aggregators. In this protocol, clients mask their values and add Gaussian noise to their models. In contrast with previous works, we use the replicated servers to unmask the models, while ensuring the liveness of training even if aggregators misbehave. Third, the asynchronous communication model introduces new challenges not present in existing approaches. In such a setting, faster clients may contribute more frequently, potentially reducing their privacy and biasing the training. To address this, we introduce an inclusion mechanism that ensures uniform client participation and balanced privacy budgets. Interestingly, the solution presented in this paper does not rely on agreement between aggregators. Thus, we circumvent the known impossibility of consensus in asynchronous settings where processes might crash. Additionally, this feature increases availability, as a consensus-based algorithm only progresses in periods of low latency.
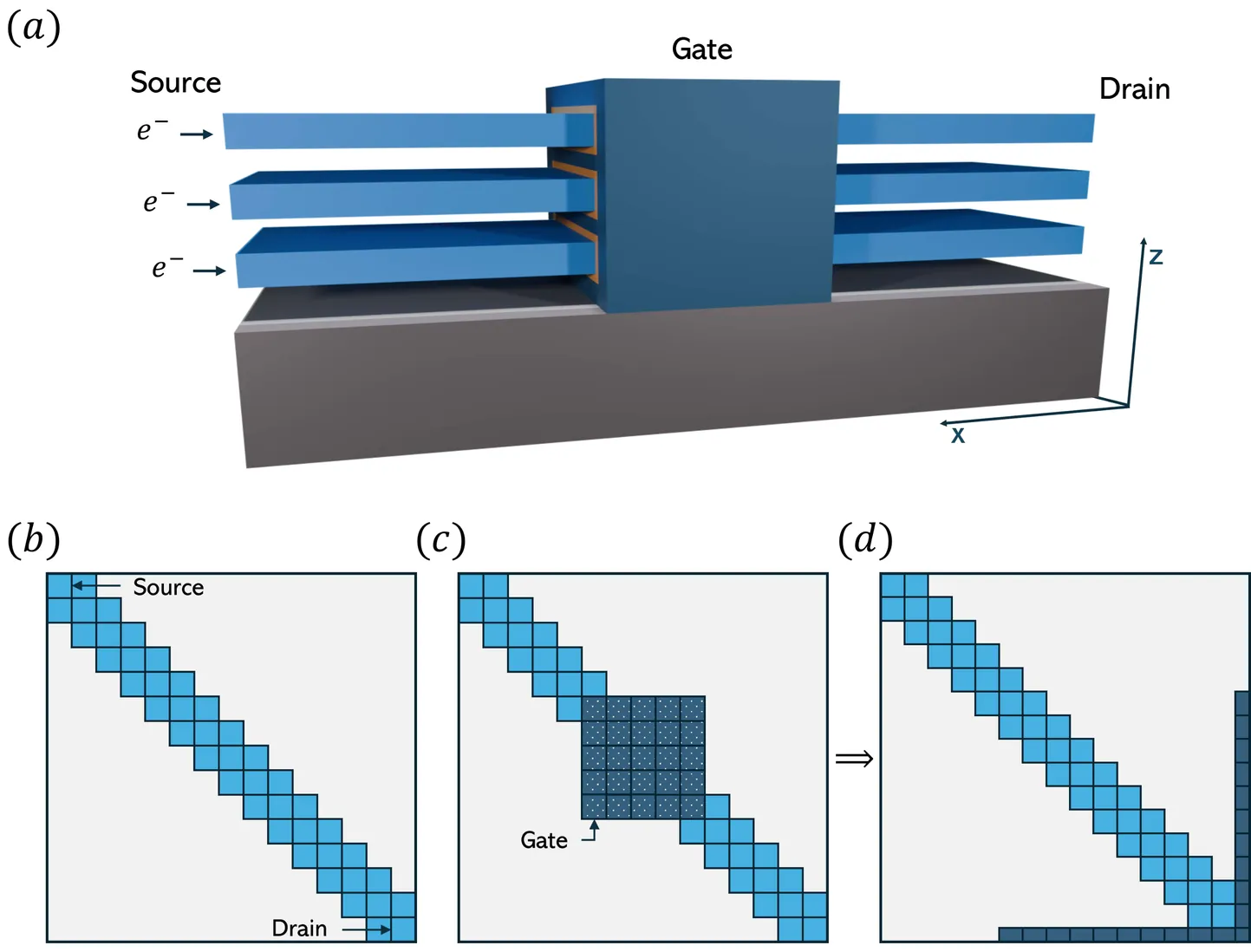
Driven by Moore's Law, the dimensions of transistors have been pushed down to the nanometer scale. Advanced quantum transport (QT) solvers are required to accurately simulate such nano-devices. The non-equilibrium Green's function (NEGF) formalism lends itself optimally to these tasks, but it is computationally very intensive, involving the selected inversion (SI) of matrices and the selected solution of quadratic matrix (SQ) equations. Existing algorithms to tackle these numerical problems are ideally suited to GPU acceleration, e.g., the so-called recursive Green's function (RGF) technique, but they are typically sequential, require block-tridiagonal (BT) matrices as inputs, and their implementation has been so far restricted to shared memory parallelism, thus limiting the achievable device sizes. To address these shortcomings, we introduce distributed methods that build on RGF and enable parallel selected inversion and selected solution of the quadratic matrix equation. We further extend them to handle BT matrices with arrowhead, which allows for the investigation of multi-terminal transistor structures. We evaluate the performance of our approach on a real dataset from the QT simulation of a nano-ribbon transistor and compare it with the sparse direct package PARDISO. When scaling to 16 GPUs, our fused SI and SQ solver is 5.2x faster than the SI module of PARDISO applied to a device 16x shorter. These results highlight the potential of our method to accelerate NEGF-based nano-device simulations.
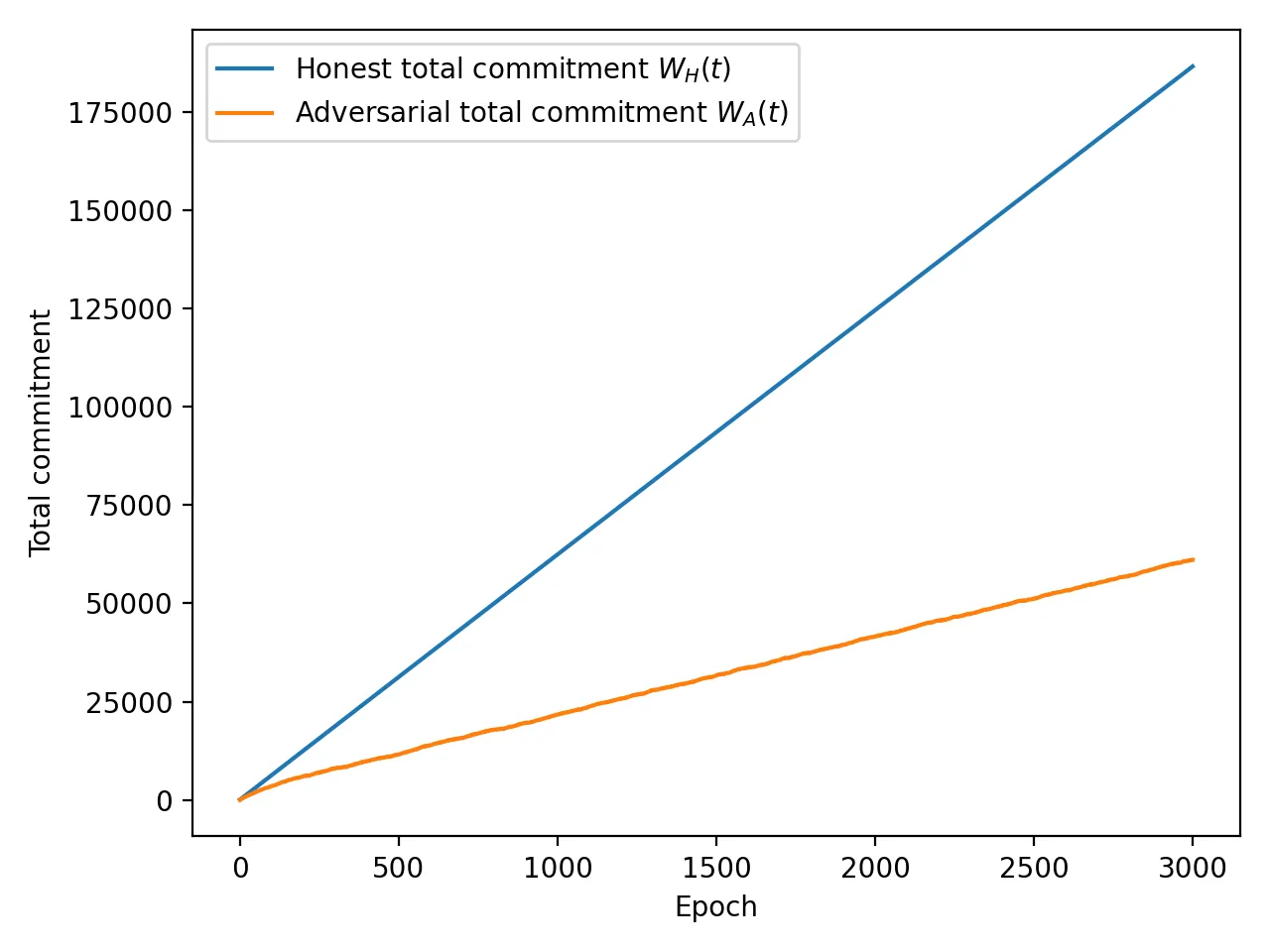
Permissionless consensus protocols require a scarce resource to regulate leader election and provide Sybil resistance. Existing paradigms such as Proof of Work and Proof of Stake instantiate this scarcity through parallelizable resources like computation or capital. Once acquired, these resources can be subdivided across many identities at negligible marginal cost, making linear Sybil cost fundamentally unattainable. We introduce Proof of Commitment (PoCmt), a consensus primitive grounded in a non-parallelizable resource: real-time human engagement. Validators maintain a commitment state capturing cumulative human effort, protocol participation, and online availability. Engagement is enforced through a Human Challenge Oracle that issues identity-bound, time-sensitive challenges, limiting the number of challenges solvable within each human window. Under this model, sustaining multiple active identities requires proportional human-time effort. We establish a cost-theoretic separation showing that protocols based on parallelizable resources admit zero marginal Sybil cost, whereas PoCmt enforces a strictly linear cost profile. Using a weighted-backbone analysis, we show that PoCmt achieves safety, liveness, and commitment-proportional fairness under partial synchrony. Simulations complement the analysis by isolating human-time capacity as the sole adversarial bottleneck and validating the predicted commitment drift and fairness properties. These results position PoCmt as a new point in the consensus design space, grounding permissionless security in sustained human effort rather than computation or capital.
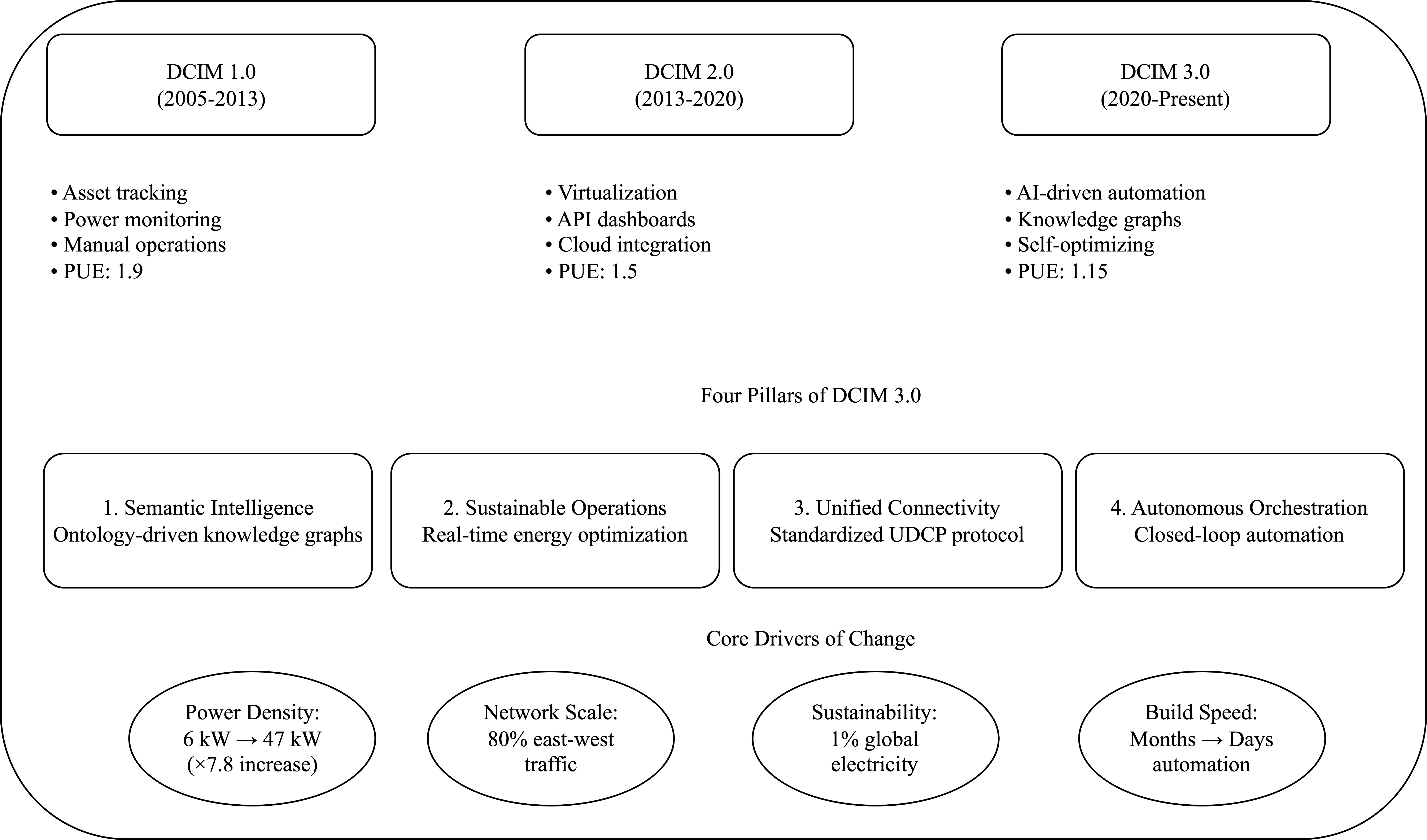
This work presents DCIM 3.0, a unified framework integrating semantic reasoning, predictive analytics, autonomous orchestration, and unified connectivity for next-generation AI data center management. The framework addresses critical challenges in infrastructure automation, sustainability, and digital-twin design through knowledge graph-based intelligence, thermal modeling, and the Unified Device Connectivity Protocol (UDCP).Keywords-Data Center Infrastructure Management, DCIM, AI Data Centers, Knowledge Graphs, Digital Twin, Thermal Management, Infrastructure Automation, Sustainability, GPU Computing, Data Center
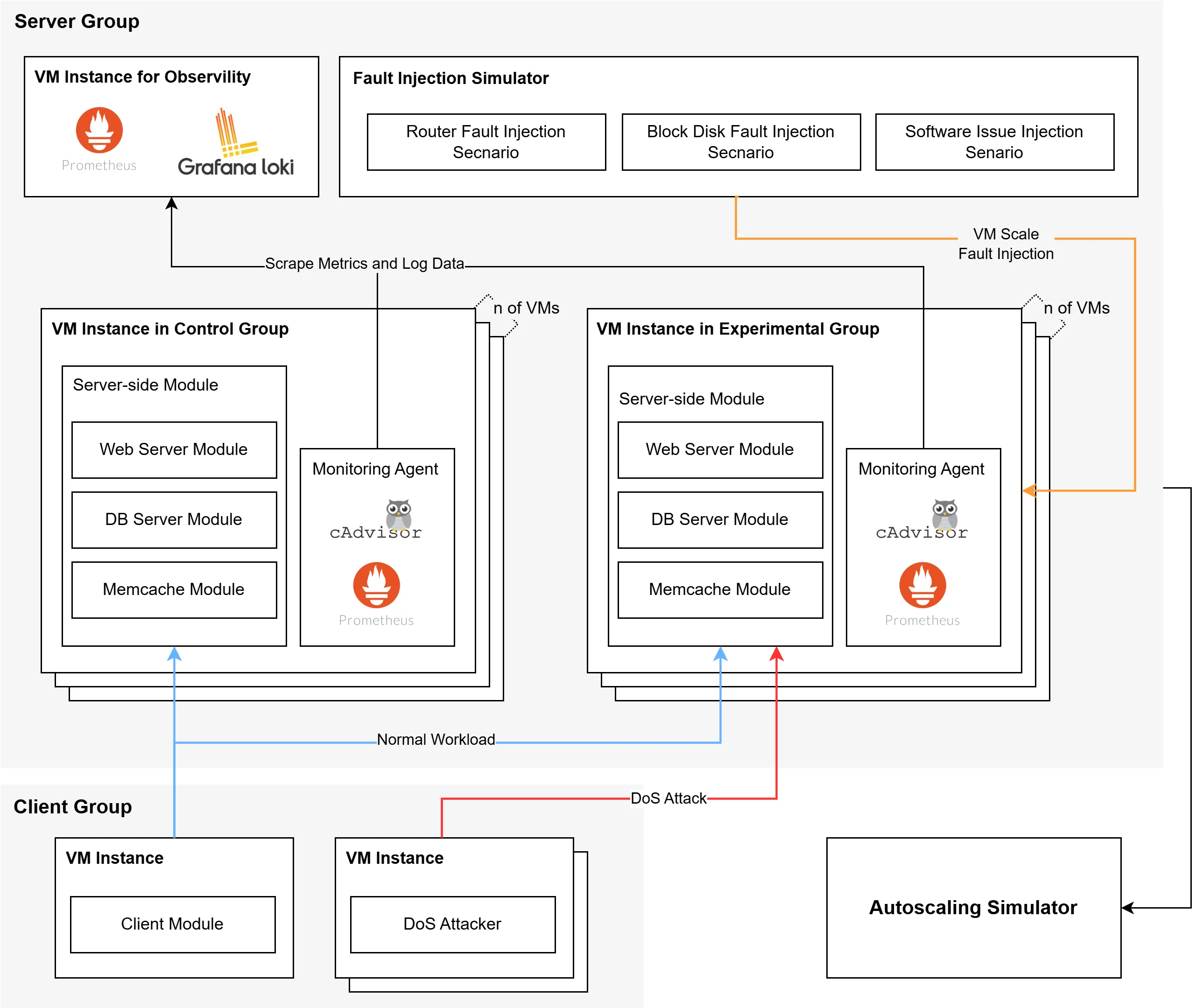
Resource autoscaling mechanisms in cloud environments depend on accurate performance metrics to make optimal provisioning decisions. When infrastructure faults including hardware malfunctions, network disruptions, and software anomalies corrupt these metrics, autoscalers may systematically over- or under-provision resources, resulting in elevated operational expenses or degraded service reliability. This paper conducts controlled simulation experiments to measure how four prevalent fault categories affect both vertical and horizontal autoscaling behaviors across multiple instance configurations and service level objective (SLO) thresholds. Experimental findings demonstrate that storage-related faults generate the largest cost overhead, adding up to $258 monthly under horizontal scaling policies, whereas routing anomalies consistently bias autoscalers toward insufficient resource allocation. The sensitivity to fault-induced metric distortions differs markedly between scaling strategies: horizontal autoscaling exhibits greater susceptibility to transient anomalies, particularly near threshold boundaries. These empirically-grounded insights offer actionable recommendations for designing fault-tolerant autoscaling policies that distinguish genuine workload fluctuations from failure artifacts.
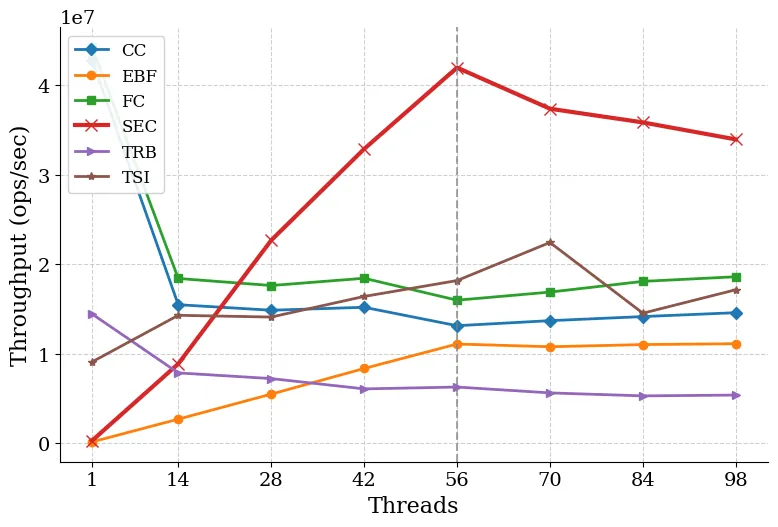
We present a new blocking linearizable stack implementation which utilizes sharding and fetch&increment to achieve significantly better performance than all existing concurrent stacks. The proposed implementation is based on a novel elimination mechanism and a new combining approach that are efficiently blended to gain high performance. Our implementation results in enhanced parallelism and low contention when accessing the shared stack. Experiments show that the proposed stack implementation outperforms all existing concurrent stacks by up to 2X in most workloads. It is particularly efficient in systems supporting a large number of threads and in high contention scenarios.
Scientific research increasingly depends on robust and scalable IT infrastructures to support complex computational workflows. With the proliferation of services provided by research infrastructures, NRENs, and commercial cloud providers, researchers must navigate a fragmented ecosystem of computing environments, balancing performance, cost, scalability, and accessibility. Hybrid cloud architectures offer a compelling solution by integrating multiple computing environments to enhance flexibility, resource efficiency, and access to specialised hardware. This paper provides a comprehensive overview of hybrid cloud deployment models, focusing on grid and cloud platforms (OpenPBS, SLURM, OpenStack, Kubernetes) and workflow management tools (Nextflow, Snakemake, CWL). We explore strategies for federated computing, multi-cloud orchestration, and workload scheduling, addressing key challenges such as interoperability, data security, reproducibility, and network performance. Drawing on implementations from life sciences, as coordinated by the ELIXIR Compute Platform and their integration into a wider EOSC context, we propose a roadmap for accelerating hybrid cloud adoption in research computing, emphasising governance frameworks and technical solutions that can drive sustainable and scalable infrastructure development.

Parallel programming is central to HPC and AI, but producing code that is correct and fast remains challenging, especially for OpenMP GPU offload, where data movement and tuning dominate. Autonomous coding agents can compile, test, and profile on target hardware, but outputs are brittle without domain scaffolding. We present ParaCodex, an HPC-engineer workflow that turns a Codex-based agent into an autonomous OpenMP GPU offload system using staged hotspot analysis, explicit data planning, correctness gating, and profiling-guided refinement. We evaluate translation from serial CPU kernels to OpenMP GPU offload kernels on HeCBench, Rodinia, and NAS. After excluding five kernels, ParaCodex succeeded on all 31 valid kernels. The generated kernels improved GPU time over reference OpenMP implementations in 25/31 cases, achieving geometric-mean speedups of 3x on HeCBench and 5x on Rodinia, and outperforming a zero-shot Codex baseline on all suites. We also evaluate CUDA to OpenMP offload translation on ParEval, where ParaCodex maintains high compilation and validation rates in code-only and end-to-end settings.

Deploying microservice-based applications (MSAs) on heterogeneous and dynamic Cloud-Edge infrastructures requires balancing conflicting objectives, such as failure resilience, performance, and environmental sustainability. In this article, we introduce the FREEDA toolchain, designed to automate the failure-resilient and carbon-efficient deployment of MSAs over the Cloud-Edge Continuum. The FREEDA toolchain continuously adapts deployment configurations to changing operational conditions, resource availability, and sustainability constraints, aiming to maintain the MSA quality and service continuity while reducing carbon emissions. We also introduce an experimental suite using diverse simulated and emulated scenarios to validate the effectiveness of the toolchain against real-world challenges, including resource exhaustion, node failures, and carbon intensity fluctuations. The results demonstrate FREEDA's capability to autonomously reconfigure deployments by migrating services, adjusting flavour selections, or rebalancing workloads, successfully achieving an optimal balance among resilience, efficiency, and environmental impact.
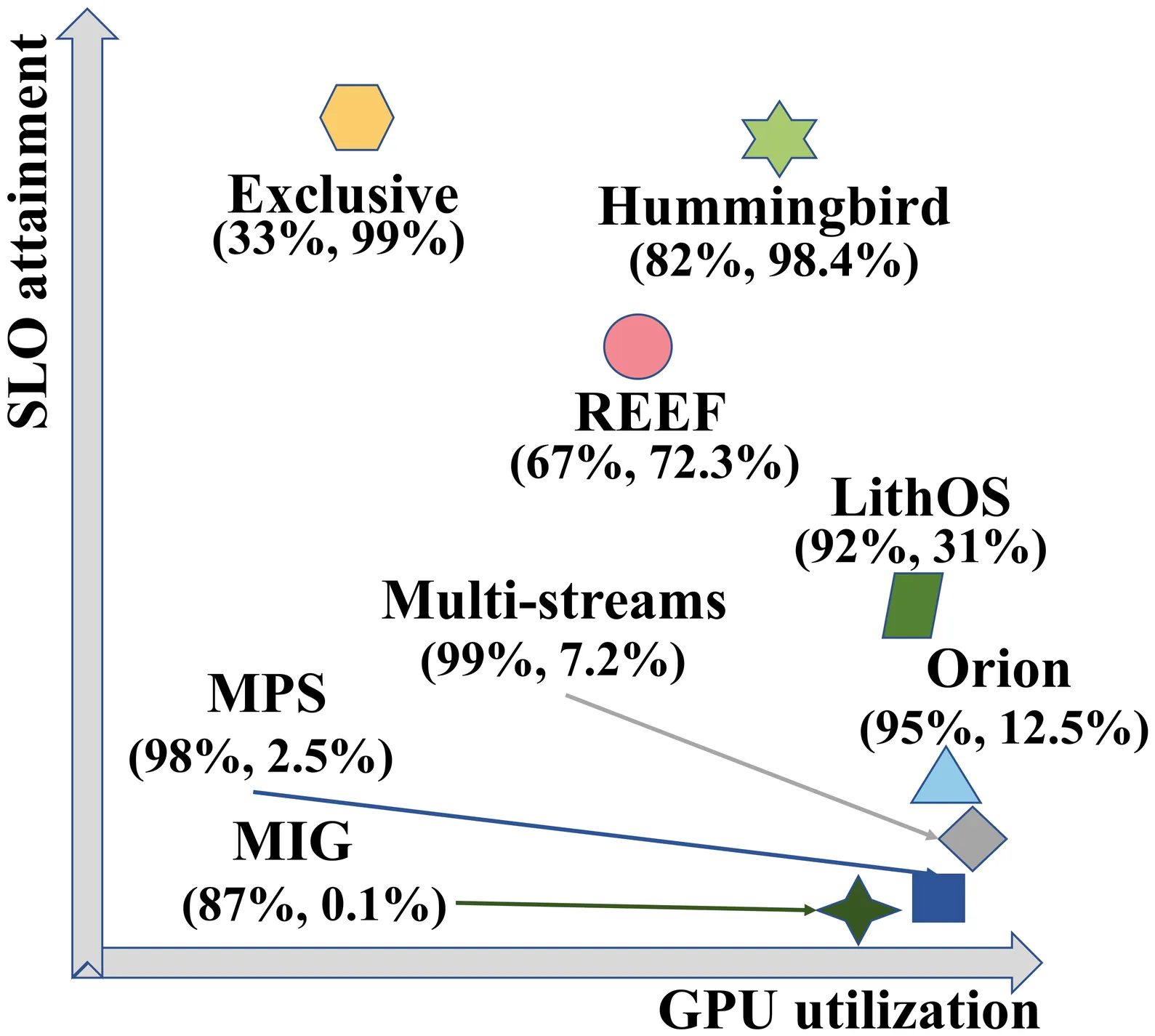
Existing GPU-sharing techniques, including spatial and temporal sharing, aim to improve utilization but face challenges in simultaneously ensuring SLO adherence and maximizing efficiency due to the lack of fine-grained task scheduling on closed-source GPUs. This paper presents Hummingbird, an SLO-oriented GPU scheduling system that overcomes these challenges by enabling microsecond-scale preemption on closed-source GPUs while effectively harvesting idle GPU time slices. Comprehensive evaluations across diverse GPU architectures reveal that Hummingbird improves the SLO attainment of high-priority tasks by 9.7x and 3.5x compared to the state-of-the-art spatial and temporal-sharing approaches. When compared to executing exclusively, the SLO attainment of the high-priority task, collocating with low-priority tasks on Hummingbird, only drops by less than 1%. Meanwhile, the throughput of the low-priority task outperforms the state-of-the-art temporal-sharing approaches by 2.4x. Hummingbird demonstrates significant effectiveness in ensuring the SLO while enhancing GPU utilization.
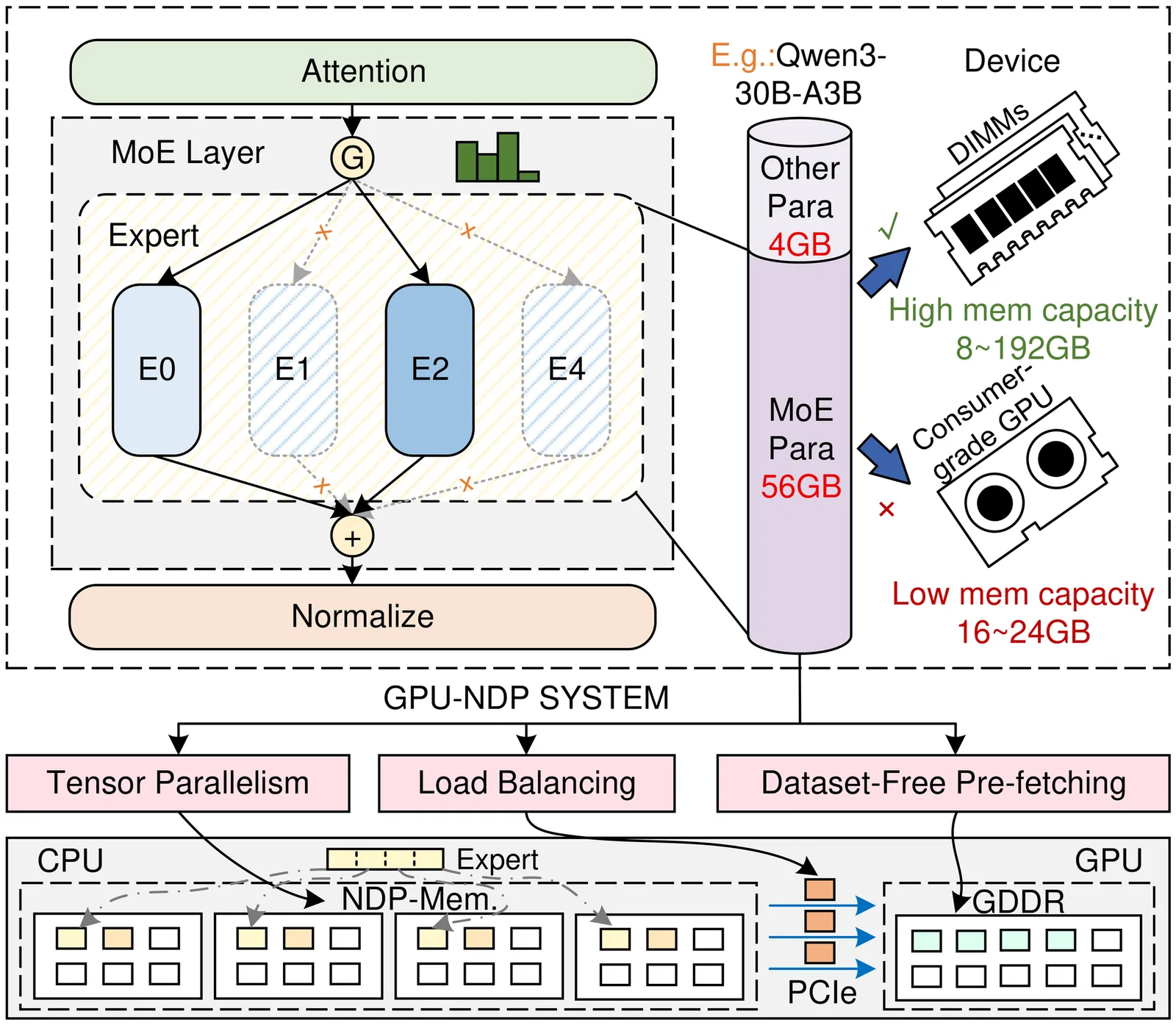
Mixture-of-Experts (MoE) models facilitate edge deployment by decoupling model capacity from active computation, yet their large memory footprint drives the need for GPU systems with near-data processing (NDP) capabilities that offload experts to dedicated processing units. However, deploying MoE models on such edge-based GPU-NDP systems faces three critical challenges: 1) severe load imbalance across NDP units due to non-uniform expert selection and expert parallelism, 2) insufficient GPU utilization during expert computation within NDP units, and 3) extensive data pre-profiling necessitated by unpredictable expert activation patterns for pre-fetching. To address these challenges, this paper proposes an efficient inference framework featuring three key optimizations. First, the underexplored tensor parallelism in MoE inference is exploited to partition and compute large expert parameters across multiple NDP units simultaneously towards edge low-batch scenarios. Second, a load-balancing-aware scheduling algorithm distributes expert computations across NDP units and GPU to maximize resource utilization. Third, a dataset-free pre-fetching strategy proactively loads frequently accessed experts to minimize activation delays. Experimental results show that our framework enables GPU-NDP systems to achieve 2.41x on average and up to 2.56x speedup in end-to-end latency compared to state-of-the-art approaches, significantly enhancing MoE inference efficiency in resource-constrained environments.
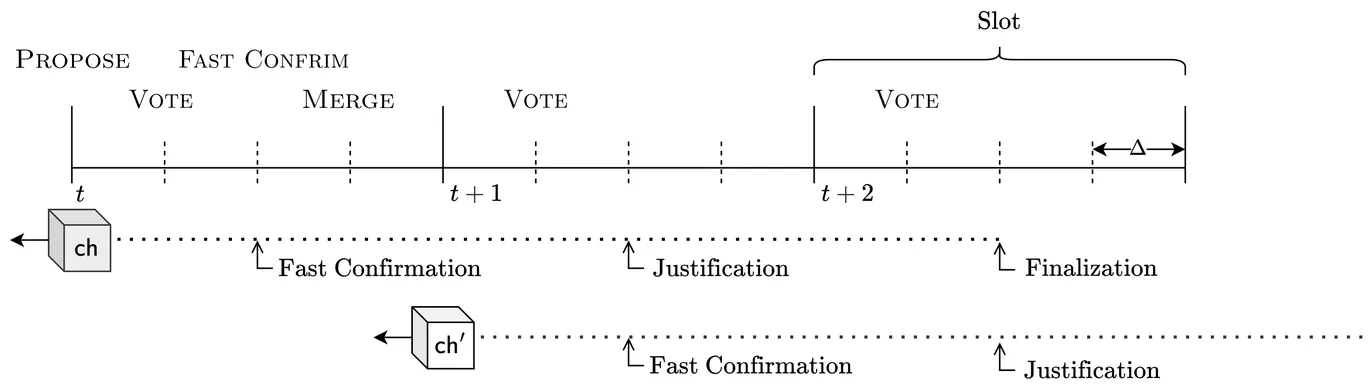
Dynamic availability is the ability of a consensus protocol to remain live despite honest participants going offline and later rejoining. A well-known limitation is that dynamically available protocols, on their own, cannot provide strong safety guarantees during network partitions or extended asynchrony. Ebb-and-flow protocols [SP21] address this by combining a dynamically available protocol with a partially synchronous finality protocol that irrevocably finalizes a prefix. We present Majorum, an ebb-and-flow construction whose dynamically available component builds on a quorum-based protocol (TOB-SVD). Under optimistic conditions, Majorum finalizes blocks in as few as three slots while requiring only a single voting phase per slot. In particular, when conditions remain favourable, each slot finalizes the next block extending the previously finalized one.
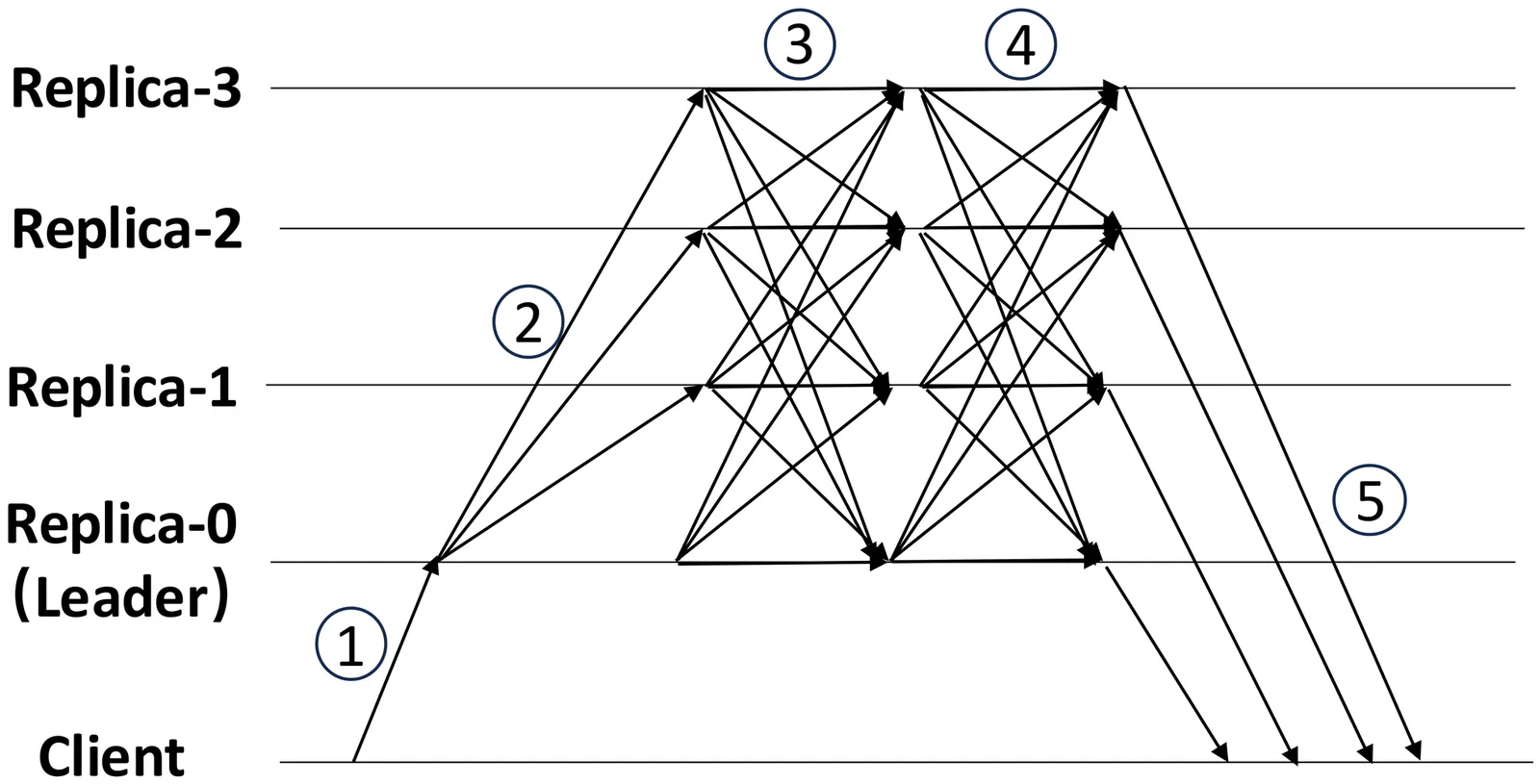
As Byzantine Fault Tolerant (BFT) protocols begin to be used in permissioned blockchains for user-facing applications such as payments, it is crucial that they provide low latency. In pursuit of low latency, some recently proposed BFT consensus protocols employ a leaderless optimistic fast path, in which clients broadcast their requests directly to replicas without first serializing requests at a leader, resulting in an end-to-end commit latency of 2 message delays ($2Δ$) during fault-free, synchronous periods. However, such a fast path only works if there is no contention: concurrent contending requests can cause replicas to diverge if they receive conflicting requests in different orders, triggering costly recovery procedures. In this work, we present Aspen, a leaderless BFT protocol that achieves a near-optimal latency of $2Δ+ \varepsilon$, where $\varepsilon$ indicates a short waiting delay. Aspen removes the no-contention condition by utilizing a best-effort sequencing layer based on loosely synchronized clocks and network delay estimates. Aspen requires $n = 3f + 2p + 1$ replicas to cope with up to $f$ Byzantine nodes. The $2p$ extra nodes allow Aspen's fast path to proceed even if up to $p$ replicas diverge due to unpredictable network delays. When its optimistic conditions do not hold, Aspen falls back to PBFT-style protocol, guaranteeing safety and liveness under partial synchrony. In experiments with wide-area distributed replicas, Aspen commits requests in less than 75 ms, a 1.2 to 3.3$\times$ improvement compared to previous protocols, while supporting 19,000 requests per second.

As multi-agent LLM pipelines grow in complexity, existing serving paradigms fail to adapt to the dynamic serving conditions. We argue that agentic serving systems should be programmable and system-aware, unlike existing serving which statically encode the parameters. In this work, we propose a new SDN-inspired agentic serving framework that helps control the key attributes of communication based on runtime state. This architecture enables serving-efficient, responsive agent systems and paves the way for high-level intent-driven agentic serving.

Training large language models requires distributing computation across many accelerators, yet practitioners select parallelism strategies (data, tensor, pipeline, ZeRO) through trial and error because no unified systematic framework predicts their behavior. We introduce placement semantics: each strategy is specified by how it places four training states (parameters, optimizer, gradients, activations) across devices using five modes (replicated, sharded, sharded-with-gather, materialized, offloaded). From placement alone, without implementation details, we derive memory consumption and communication volume. Our predictions match published results exactly: ZeRO-3 uses 8x less memory than data parallelism at 1.5x communication cost, as reported in the original paper. We prove two conditions (gradient integrity, state consistency) are necessary and sufficient for distributed training to match single-device results, and provide composition rules for combining strategies safely. The framework unifies ZeRO Stages 1-3, Fully Sharded Data Parallel (FSDP), tensor parallelism, and pipeline parallelism as instances with different placement choices.
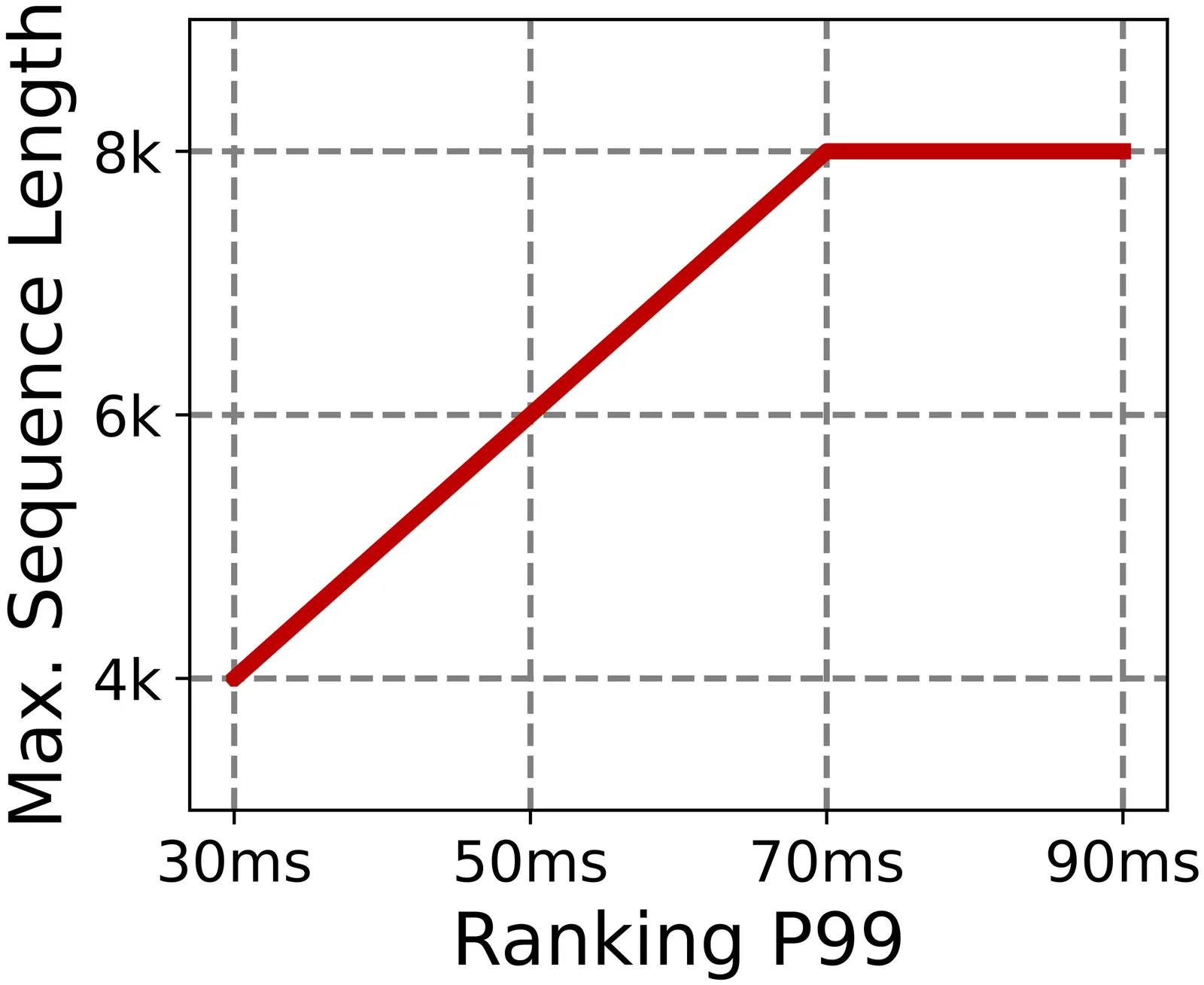
Real-time recommender systems execute multi-stage cascades (retrieval, pre-processing, fine-grained ranking) under strict tail-latency SLOs, leaving only tens of milliseconds for ranking. Generative recommendation (GR) models can improve quality by consuming long user-behavior sequences, but in production their online sequence length is tightly capped by the ranking-stage P99 budget. We observe that the majority of GR tokens encode user behaviors that are independent of the item candidates, suggesting an opportunity to pre-infer a user-behavior prefix once and reuse it during ranking rather than recomputing it on the critical path. Realizing this idea at industrial scale is non-trivial: the prefix cache must survive across multiple pipeline stages before the final ranking instance is determined, the user population implies cache footprints far beyond a single device, and indiscriminate pre-inference would overload shared resources under high QPS. We present RelayGR, a production system that enables in-HBM relay-race inference for GR. RelayGR selectively pre-infers long-term user prefixes, keeps their KV caches resident in HBM over the request lifecycle, and ensures the subsequent ranking can consume them without remote fetches. RelayGR combines three techniques: 1) a sequence-aware trigger that admits only at-risk requests under a bounded cache footprint and pre-inference load, 2) an affinity-aware router that co-locates cache production and consumption by routing both the auxiliary pre-infer signal and the ranking request to the same instance, and 3) a memory-aware expander that uses server-local DRAM to capture short-term cross-request reuse while avoiding redundant reloads. We implement RelayGR on Huawei Ascend NPUs and evaluate it with real queries. Under a fixed P99 SLO, RelayGR supports up to 1.5$\times$ longer sequences and improves SLO-compliant throughput by up to 3.6$\times$.
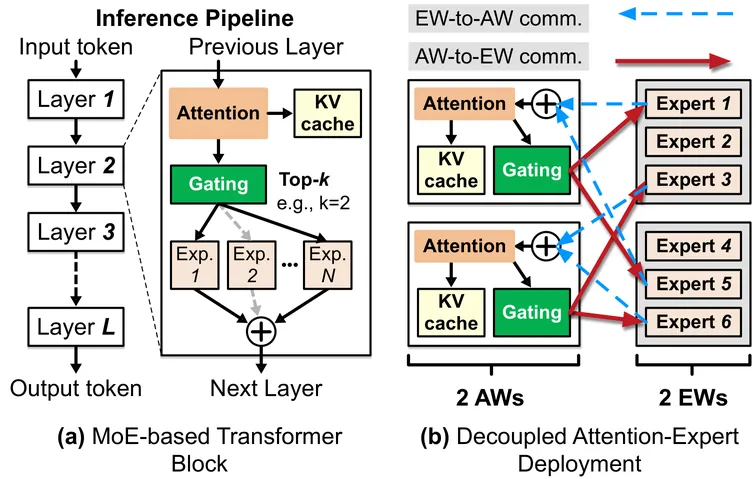
Mixture-of-Experts (MoE) models are increasingly used to serve LLMs at scale, but failures become common as deployment scale grows. Existing systems exhibit poor failure resilience: even a single worker failure triggers a coarse-grained, service-wide restart, discarding accumulated progress and halting the entire inference pipeline during recovery--an approach clearly ill-suited for latency-sensitive, LLM services. We present Tarragon, a resilient MoE inference framework that confines the failures impact to individual workers while allowing the rest of the pipeline to continue making forward progress. Tarragon exploits the natural separation between the attention and expert computation in MoE-based transformers, treating attention workers (AWs) and expert workers (EWs) as distinct failure domains. Tarragon introduces a reconfigurable datapath to mask failures by rerouting requests to healthy workers. On top of this datapath, Tarragon implements a self-healing mechanism that relaxes the tightly synchronized execution of existing MoE frameworks. For stateful AWs, Tarragon performs asynchronous, incremental KV cache checkpointing with per-request restoration, and for stateless EWs, it leverages residual GPU memory to deploy shadow experts. These together keep recovery cost and recomputation overhead extremely low. Our evaluation shows that, compared to state-of-the-art MegaScale-Infer, Tarragon reduces failure-induced stalls by 160-213x (from ~64 s down to 0.3-0.4 s) while preserving performance when no failures occur.
Post-training with reinforcement learning (RL) has greatly enhanced the capabilities of large language models. Disaggregating the generation and training stages in RL into a parallel, asynchronous pipeline offers the potential for flexible scaling and improved throughput. However, it still faces two critical challenges. First, the generation stage often becomes a bottleneck due to dynamic workload shifts and severe execution imbalances. Second, the decoupled stages result in diverse and dynamic network traffic patterns that overwhelm conventional network fabrics. This paper introduces OrchestrRL, an orchestration framework that dynamically manages compute and network rhythms in disaggregated RL. To improve generation efficiency, OrchestrRL employs an adaptive compute scheduler that dynamically adjusts parallelism to match workload characteristics within and across generation steps. This accelerates execution while continuously rebalancing requests to mitigate stragglers. To address the dynamic network demands inherent in disaggregated RL -- further intensified by parallelism switching -- we co-design RFabric, a reconfigurable hybrid optical-electrical fabric. RFabric leverages optical circuit switches at selected network tiers to reconfigure the topology in real time, enabling workload-aware circuits for (i) layer-wise collective communication during training iterations, (ii) generation under different parallelism configurations, and (iii) periodic inter-cluster weight synchronization. We evaluate OrchestrRL on a physical testbed with 48 H800 GPUs, demonstrating up to a 1.40x throughput improvement. Furthermore, we develop RLSim, a high-fidelity simulator, to evaluate RFabric at scale. Our results show that RFabric achieves superior performance-cost efficiency compared to static Fat-Tree networks, establishing it as a highly effective solution for large-scale RL workloads.
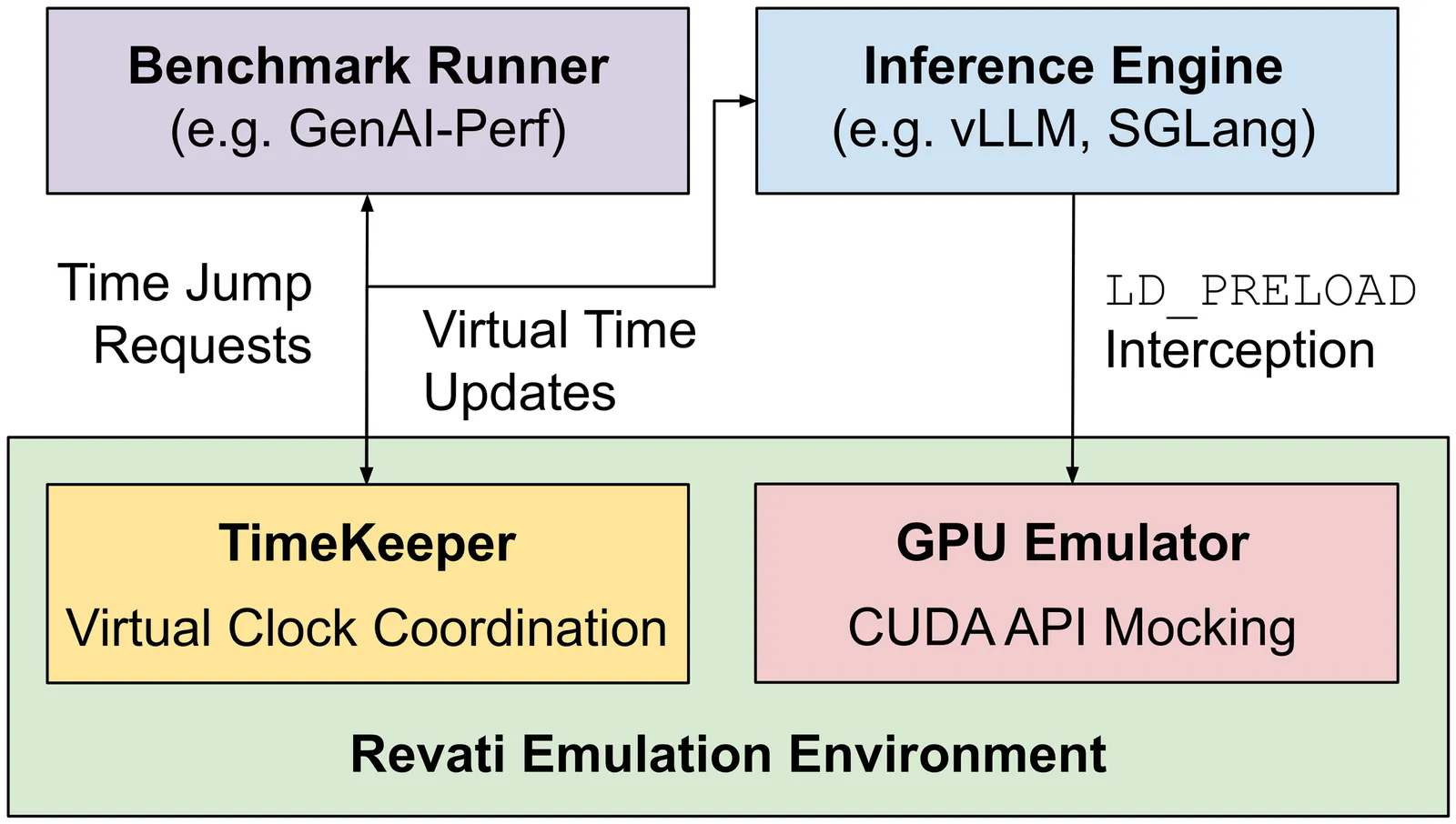
Deploying LLMs efficiently requires testing hundreds of serving configurations, but evaluating each one on a GPU cluster takes hours and costs thousands of dollars. Discrete-event simulators are faster and cheaper, but they require re-implementing the serving system's control logic -- a burden that compounds as frameworks evolve. We present Revati, a time-warp emulator that enables performance modeling by directly executing real serving system code at simulation-like speed. The system intercepts CUDA API calls to virtualize device management, allowing serving frameworks to run without physical GPUs. Instead of executing GPU kernels, it performs time jumps -- fast-forwarding virtual time by predicted kernel durations. We propose a coordination protocol that synchronizes these jumps across distributed processes while preserving causality. On vLLM and SGLang, Revati achieves less than 5% prediction error across multiple models and parallelism configurations, while running 5-17x faster than real GPU execution.