Software Engineering
arXiv:cs.SE
Covers software design, verification, validation, documentation, and software development tools.
Looking for a broader view? This category is part of:
Covers software design, verification, validation, documentation, and software development tools.
Looking for a broader view? This category is part of:
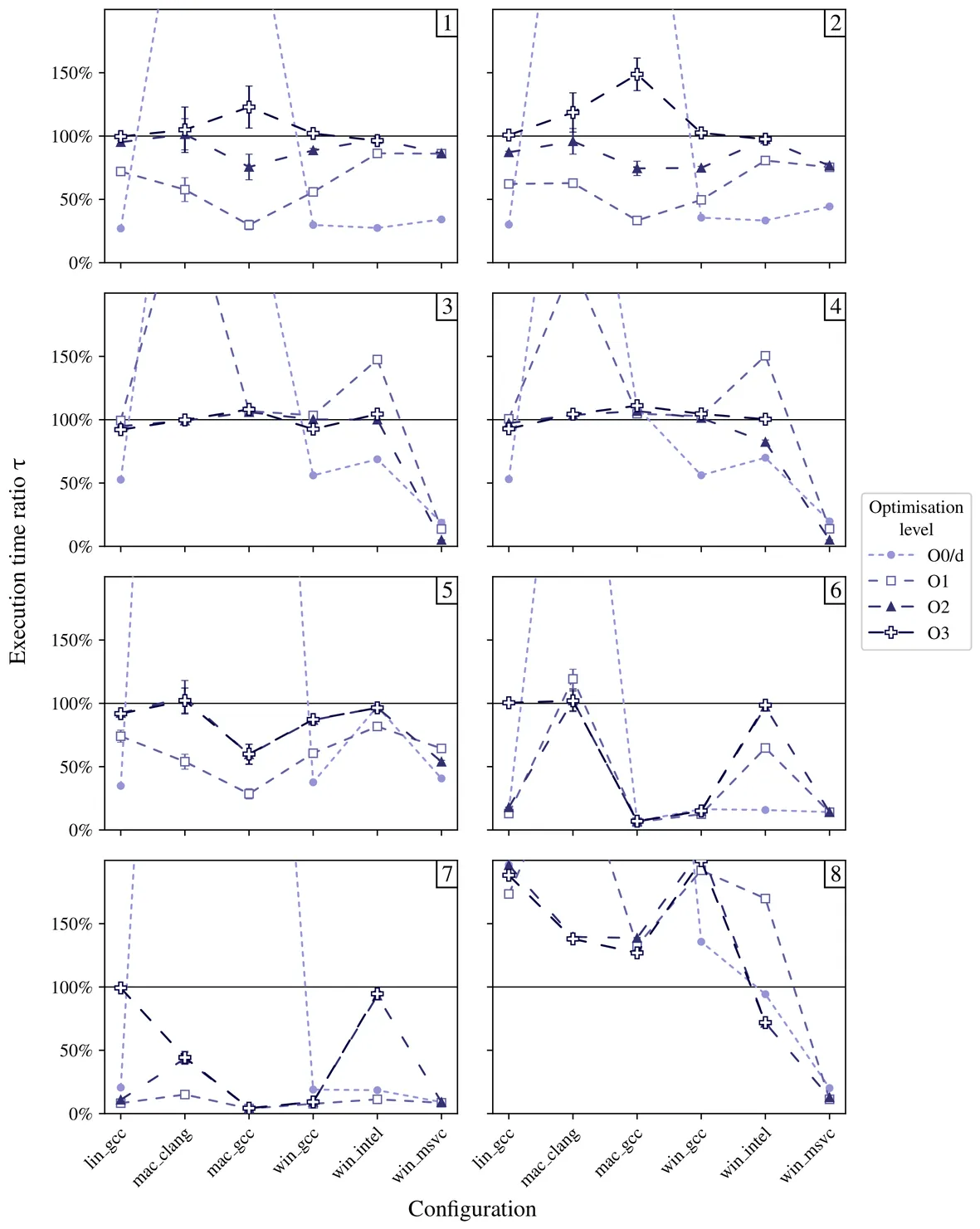
A cross-configuration benchmark is proposed to explore the capacities and limitations of AVX / NEON intrinsic functions in a generic context of development project, when a vectorisation strategy is required to optimise the code. The main aim is to guide developers to choose when using intrinsic functions, depending on the OS, architecture and/or available compiler. Intrinsic functions were observed highly efficient in conditional branching, with intrinsic version execution time reaching around 5% of plain code execution time. However, intrinsic functions were observed as unnecessary in many cases, as the compilers already well auto-vectorise the code.
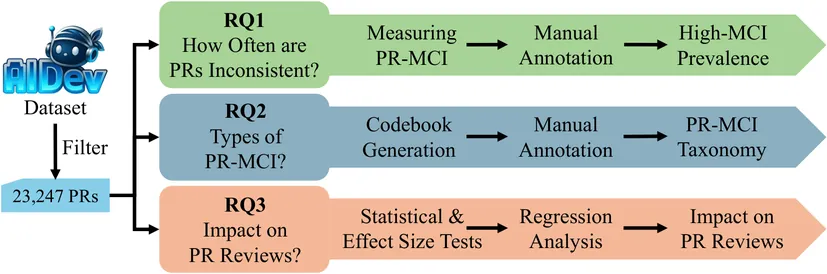
Pull request (PR) descriptions generated by AI coding agents are the primary channel for communicating code changes to human reviewers. However, the alignment between these messages and the actual changes remains unexplored, raising concerns about the trustworthiness of AI agents. To fill this gap, we analyzed 23,247 agentic PRs across five agents using PR message-code inconsistency (PR-MCI). We contributed 974 manually annotated PRs, found 406 PRs (1.7%) exhibited high PR-MCI, and identified eight PR-MCI types, revealing that descriptions claiming unimplemented changes was the most common issue (45.4%). Statistical tests confirmed that high-MCI PRs had 51.7% lower acceptance rates (28.3% vs. 80.0%) and took 3.5x longer to merge (55.8 vs. 16.0 hours). Our findings suggest that unreliable PR descriptions undermine trust in AI agents, highlighting the need for PR-MCI verification mechanisms and improved PR generation to enable trustworthy human-AI collaboration.

This paper presents a longitudinal ethical analysis of Untappd, a social drinking application that gamifies beer consumption through badges, streaks, and social sharing. Building on an exploratory study conducted in 2020, we revisit the platform in 2025 to examine how its gamification features and ethical framings have evolved. Drawing on traditional ethical theory and practical frameworks for Software Engineering, we analyze five categories of badges and their implications for user autonomy and well-being. Our findings show that, despite small adjustments and superficial disclaimers, many of the original ethical issues remain. We argue for continuous ethical reflection built embedded into software lifecycles to prevent the normalization of risky behaviors through design.
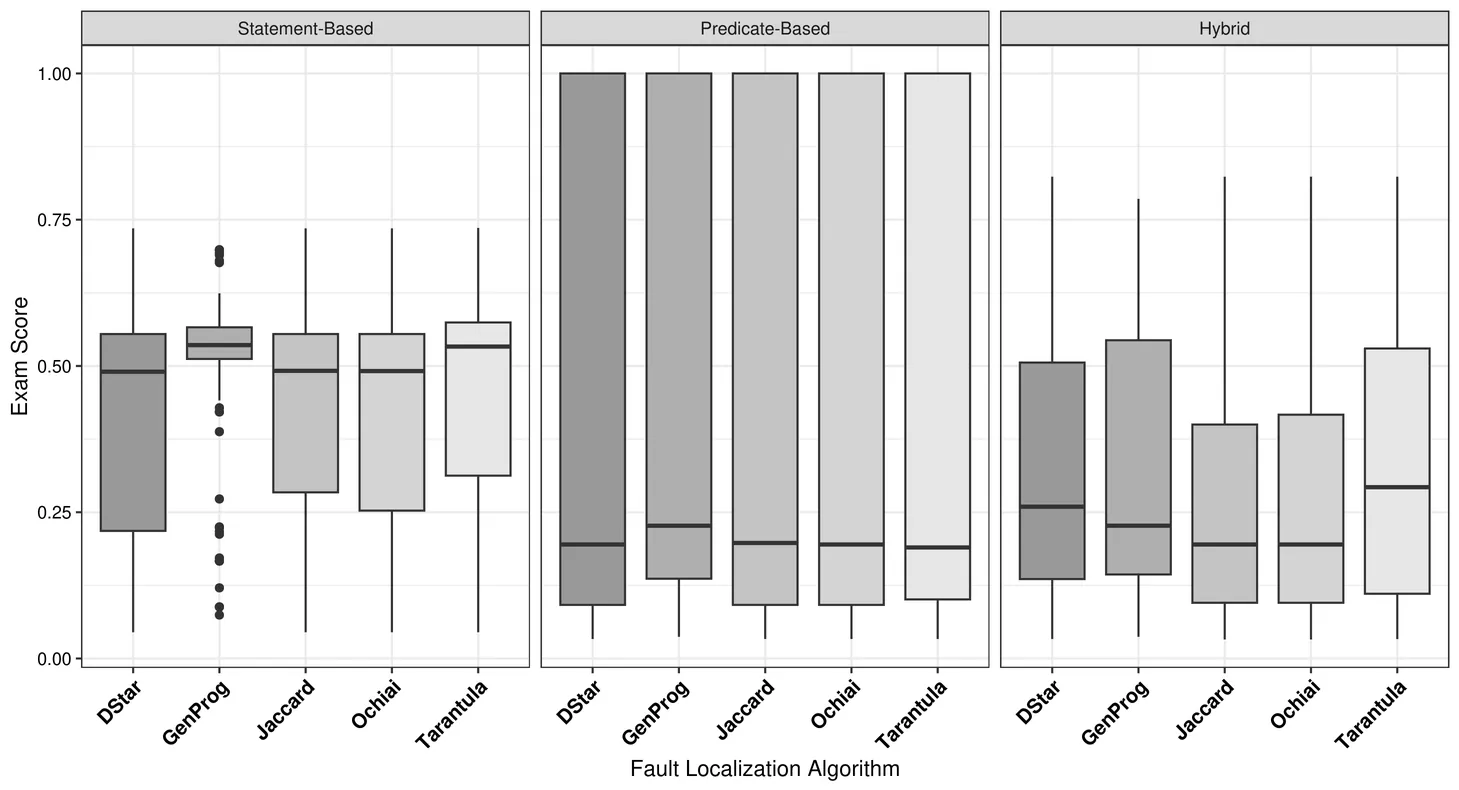
This paper introduces DDMIN-LOC, a technique that combines Delta Debugging Minimization (DDMIN) with Spectrum-Based Fault Localization (SBFL). It can be applied to programs taking string inputs, even when only a single failure-inducing input is available. DDMIN is an algorithm that systematically explores the minimal failure-inducing input that exposes a bug, given an initial failing input. However, it does not provide information about the faulty statements responsible for the failure. DDMIN-LOC addresses this limitation by collecting the passing and failing inputs generated during the DDMIN process and computing suspiciousness scores for program statements and predicates using SBFL algorithms. These scores are then combined to rank statements according to their likelihood of being faulty. DDMIN-LOC requires only one failing input of the buggy program, although it can be applied only to programs that take string inputs. DDMIN-LOC was evaluated on 136 programs selected from the QuixBugs and Codeflaws benchmarks using the SBFL algorithms Tarantula, Ochiai, GenProg, Jaccard and DStar. Experimental results show that DDMIN-LOC performs best with Jaccard: in most subjects, fewer than 20% executable lines need to be examined to locate the faulty statements. Moreover, in most subjects, faulty statements are ranked within the top 3 positions in all the generated test suites derived from different failing inputs.

We deployed an LLM agent with ReAct reasoning and full data access. It executed flawlessly, yet when asked "Why is completion rate 80%?", it returned metrics instead of causal explanation. The agent knew how to reason but we had not specified what to reason about. This reflects a gap: runtime reasoning frameworks (ReAct, Chain-of-Thought) have transformed LLM agents, but design-time specification--determining what domain knowledge agents need--remains under-explored. We propose 4D-ARE (4-Dimensional Attribution-Driven Agent Requirements Engineering), a preliminary methodology for specifying attribution-driven agents. The core insight: decision-makers seek attribution, not answers. Attribution concerns organize into four dimensions (Results -> Process -> Support -> Long-term), motivated by Pearl's causal hierarchy. The framework operationalizes through five layers producing artifacts that compile directly to system prompts. We demonstrate the methodology through an industrial pilot deployment in financial services. 4D-ARE addresses what agents should reason about, complementing runtime frameworks that address how. We hypothesize systematic specification amplifies the power of these foundational advances. This paper presents a methodological proposal with preliminary industrial validation; rigorous empirical evaluation is planned for future work.
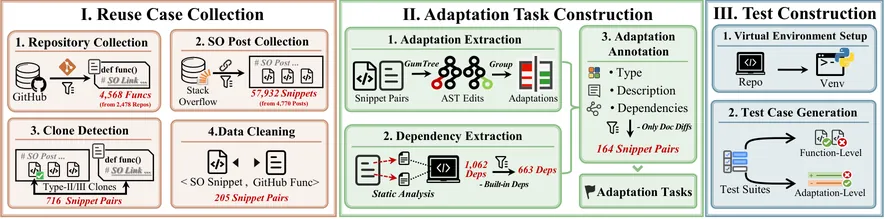
Recent advancements in large language models (LLMs) have automated various software engineering tasks, with benchmarks emerging to evaluate their capabilities. However, for adaptation, a critical activity during code reuse, there is no benchmark to assess LLMs' performance, leaving their practical utility in this area unclear. To fill this gap, we propose AdaptEval, a benchmark designed to evaluate LLMs on code snippet adaptation. Unlike existing benchmarks, AdaptEval incorporates the following three distinctive features: First, Practical Context. Tasks in AdaptEval are derived from developers' practices, preserving rich contextual information from Stack Overflow and GitHub communities. Second, Multi-granularity Annotation. Each task is annotated with requirements at both task and adaptation levels, supporting the evaluation of LLMs across diverse adaptation scenarios. Third, Fine-grained Evaluation. AdaptEval includes a two-tier testing framework combining adaptation-level and function-level tests, which enables evaluating LLMs' performance across various individual adaptations. Based on AdaptEval, we conduct the first empirical study to evaluate six instruction-tuned LLMs and especially three reasoning LLMs on code snippet adaptation. Experimental results demonstrate that AdaptEval enables the assessment of LLMs' adaptation capabilities from various perspectives. It also provides critical insights into their current limitations, particularly their struggle to follow explicit instructions. We hope AdaptEval can facilitate further investigation and enhancement of LLMs' capabilities in code snippet adaptation, supporting their real-world applications.
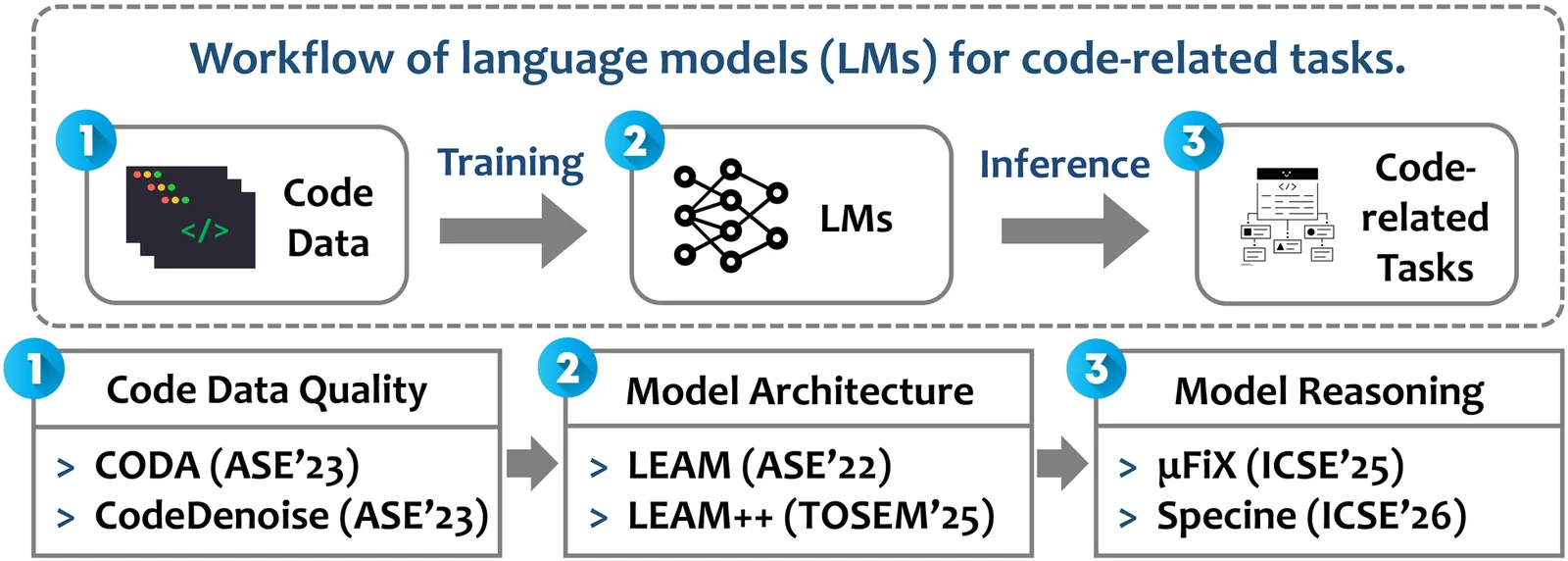
Recent advances in language models (LMs) have driven significant progress in various software engineering tasks. However, existing LMs still struggle with complex programming scenarios due to limitations in data quality, model architecture, and reasoning capability. This research systematically addresses these challenges through three complementary directions: (1) improving code data quality with a code difference-guided adversarial augmentation technique (CODA) and a code denoising technique (CodeDenoise); (2) enhancing model architecture via syntax-guided code LMs (LEAM and LEAM++); and (3) advancing model reasoning with a prompting technique (muFiX) and an agent-based technique (Specine). These techniques aim to promote the practical adoption of LMs in software development and further advance intelligent software engineering.
Issue Tracking Systems (ITSs) enable software developers and managers to collect and resolve issues collaboratively. While researchers have extensively analysed ITS data to automate or assist specific activities such as issue assignments, duplicate detection, or priority prediction, developer studies on ITSs remain rare. Particularly, little is known about the challenges Software Engineering (SE) teams encounter in ITSs and when certain practices and workarounds (such as leaving issue fields like "priority" empty) are considered problematic. To fill this gap, we conducted an in-depth interview study with 26 experienced SE practitioners from different organisations and industries. We asked them about general problems encountered, as well as the relevance of 31 ITS smells (aka potentially problematic practices) discussed in the literature. By applying Thematic Analysis to the interview notes, we identified 14 common problems including issue findability, zombie issues, workflow bloat, and lack of workflow enforcement. Participants also stated that many of the ITS smells do not occur or are not problematic. Our results suggest that ITS problems and smells are highly dependent on context factors such as ITS configuration, workflow stage, and team size. We also discuss potential tooling solutions to configure, monitor, and visualise ITS smells to cope with these challenges.

As Autonomous Driving Systems (ADS) progress towards commercial deployment, there is an increasing focus on ensuring their safety and reliability. While considerable research has been conducted on testing methods for detecting faults in ADS, very little attention has been paid to debugging in ADS. Debugging is an essential process that follows test failures to localise and repair the faults in the systems to maintain their safety and reliability. This Systematic Mapping Study (SMS) aims to provide a detailed overview of the current landscape of ADS debugging, highlighting existing approaches and identifying gaps in research. The study also proposes directions for future work and standards for problem definition and terminology in the field. Our findings reveal various methods for ADS debugging and highlight the current fragmented yet promising landscape.
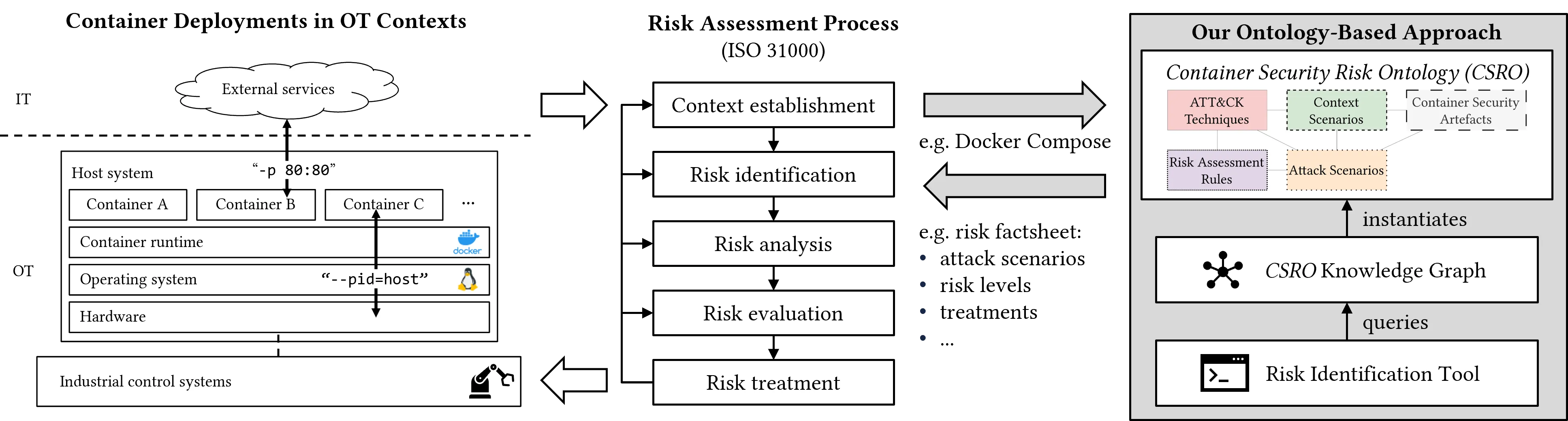
In operational technology (OT) contexts, containerised applications often require elevated privileges to access low-level network interfaces or perform administrative tasks such as application monitoring. These privileges reduce the default isolation provided by containers and introduce significant security risks. Security risk identification for OT container deployments is challenged by hybrid IT/OT architectures, fragmented stakeholder knowledge, and continuous system changes. Existing approaches lack reproducibility, interpretability across contexts, and technical integration with deployment artefacts. We propose a model-based approach, implemented as the Container Security Risk Ontology (CSRO), which integrates five key domains: adversarial behaviour, contextual assumptions, attack scenarios, risk assessment rules, and container security artefacts. Our evaluation of CSRO in a case study demonstrates that the end-to-end formalisation of risk calculation, from artefact to risk level, enables automated and reproducible risk identification. While CSRO currently focuses on technical, container-level treatment measures, its modular and flexible design provides a solid foundation for extending the approach to host-level and organisational risk factors.
Background: Extracting the stages that structure Machine Learning (ML) pipelines from source code is key for gaining a deeper understanding of data science practices. However, the diversity caused by the constant evolution of the ML ecosystem (e.g., algorithms, libraries, datasets) makes this task challenging. Existing approaches either depend on non-scalable, manual labeling, or on ML classifiers that do not properly support the diversity of the domain. These limitations highlight the need for more flexible and reliable solutions. Objective: We evaluate whether Small Language Models (SLMs) can leverage their code understanding and classification abilities to address these limitations, and subsequently how they can advance our understanding of data science practices. Method: We conduct a confirmatory study based on two reference works selected for their relevance regarding current state-of-the-art's limitations. First, we compare several SLMs using Cochran's Q test. The best-performing model is then evaluated against the reference studies using two distinct McNemar's tests. We further analyze how variations in taxonomy definitions affect performance through an additional Cochran's Q test. Finally, a goodness-of-fit analysis is conducted using Pearson's chi-squared tests to compare our insights on data science practices with those from prior studies.
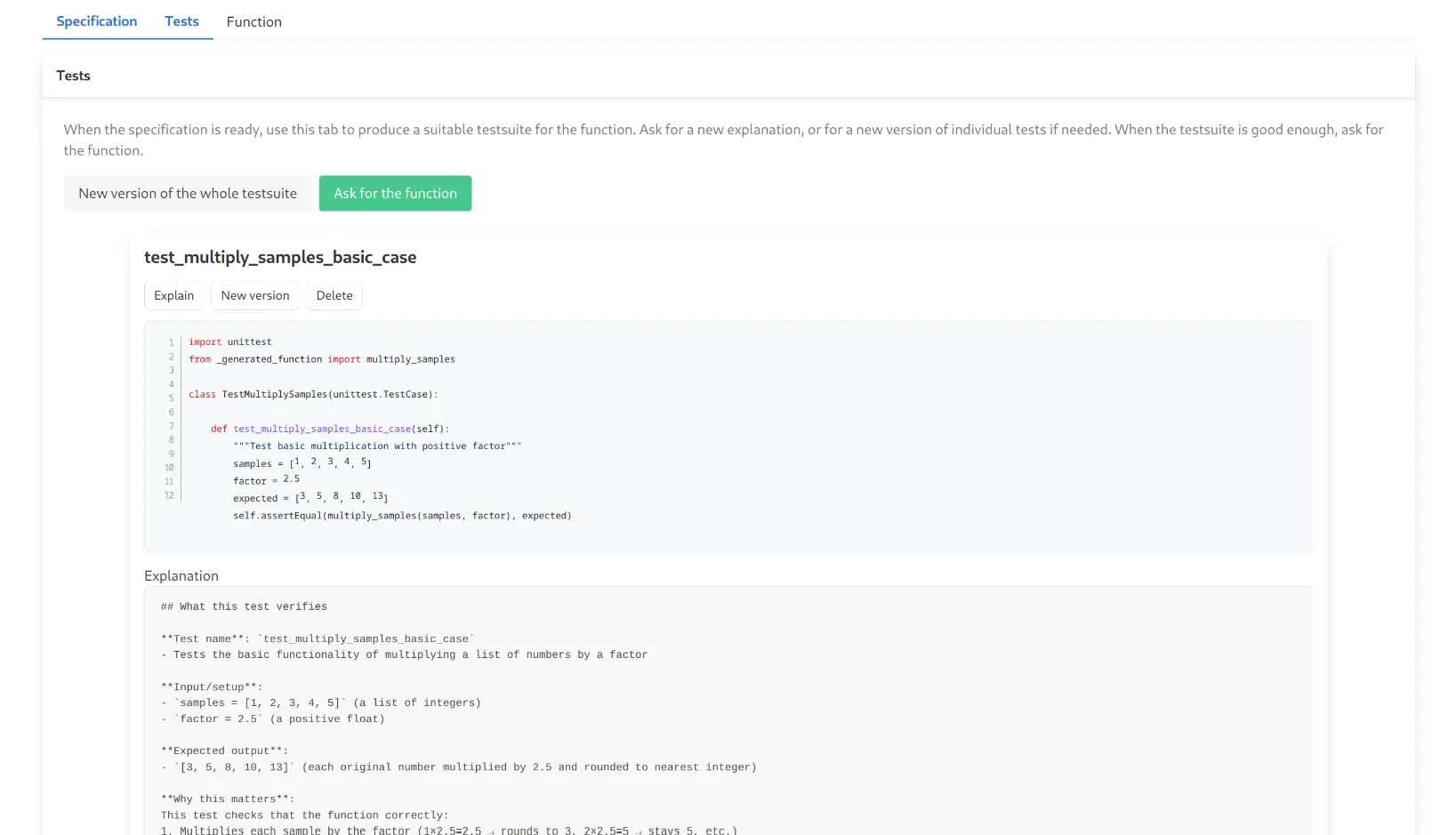
Large Language Models (LLMs) are increasingly integrated into software development workflows, yet their behavior in structured, specification-driven processes remains poorly understood. This paper presents an empirical study design using CURRANTE, a Visual Studio Code extension that enables a human-in-the-loop workflow for LLM-assisted code generation. The tool guides developers through three sequential stages--Specification, Tests, and Function--allowing them to define requirements, generate and refine test suites, and produce functions that satisfy those tests. Participants will solve medium-difficulty problems from the LiveCodeBench dataset, while the tool records fine-grained interaction logs, effectiveness metrics (e.g., pass rate, all-pass completion), efficiency indicators (e.g., time-to-pass), and iteration behaviors. The study aims to analyze how human intervention in specification and test refinement influences the quality and dynamics of LLM-generated code. The results will provide empirical insights into the design of next-generation development environments that align human reasoning with model-driven code generation.
LLMs are increasingly used to boost productivity and support software engineering tasks. However, when applied to socially sensitive decisions such as team composition and task allocation, they raise concerns of fairness. Prior studies have revealed that LLMs may reproduce stereotypes; however, these analyses remain exploratory and examine sensitive attributes in isolation. This study investigates whether LLMs exhibit bias in team composition and task assignment by analyzing the combined effects of candidates' country and pronouns. Using three LLMs and 3,000 simulated decisions, we find systematic disparities: demographic attributes significantly shaped both selection likelihood and task allocation, even when accounting for expertise-related factors. Task distributions further reflected stereotypes, with technical and leadership roles unevenly assigned across groups. Our findings indicate that LLMs exacerbate demographic inequities in software engineering contexts, underscoring the need for fairness-aware assessment.

Large Language Models (LLMs) such as GPT-4, Claude and LLaMA have shown impressive performance in code generation, typically evaluated using benchmarks (e.g., HumanEval). However, effective code generation requires models to understand and apply a wide range of language concepts. If the concepts exercised in benchmarks are not representative of those used in real-world projects, evaluations may yield incomplete. Despite this concern, the representativeness of code concepts in benchmarks has not been systematically examined. To address this gap, we present the first empirical study that analyzes the representativeness of code generation benchmarks through the lens of Knowledge Units (KUs) - cohesive sets of programming language capabilities provided by language constructs and APIs. We analyze KU coverage in two widely used Python benchmarks, HumanEval and MBPP, and compare them with 30 real-world Python projects. Our results show that each benchmark covers only half of the identified 20 KUs, whereas projects exercise all KUs with relatively balanced distributions. In contrast, benchmark tasks exhibit highly skewed KU distributions. To mitigate this misalignment, we propose a prompt-based LLM framework that synthesizes KU-based tasks to rebalance benchmark KU distributions and better align them with real-world usage. Using this framework, we generate 440 new tasks and augment existing benchmarks. The augmented benchmarks substantially improve KU coverage and achieve over a 60% improvement in distributional alignment. Evaluations of state-of-the-art LLMs on these augmented benchmarks reveal consistent and statistically significant performance drops (12.54-44.82%), indicating that existing benchmarks overestimate LLM performance due to their limited KU coverage. Our findings provide actionable guidance for building more realistic evaluations of LLM code-generation capabilities.
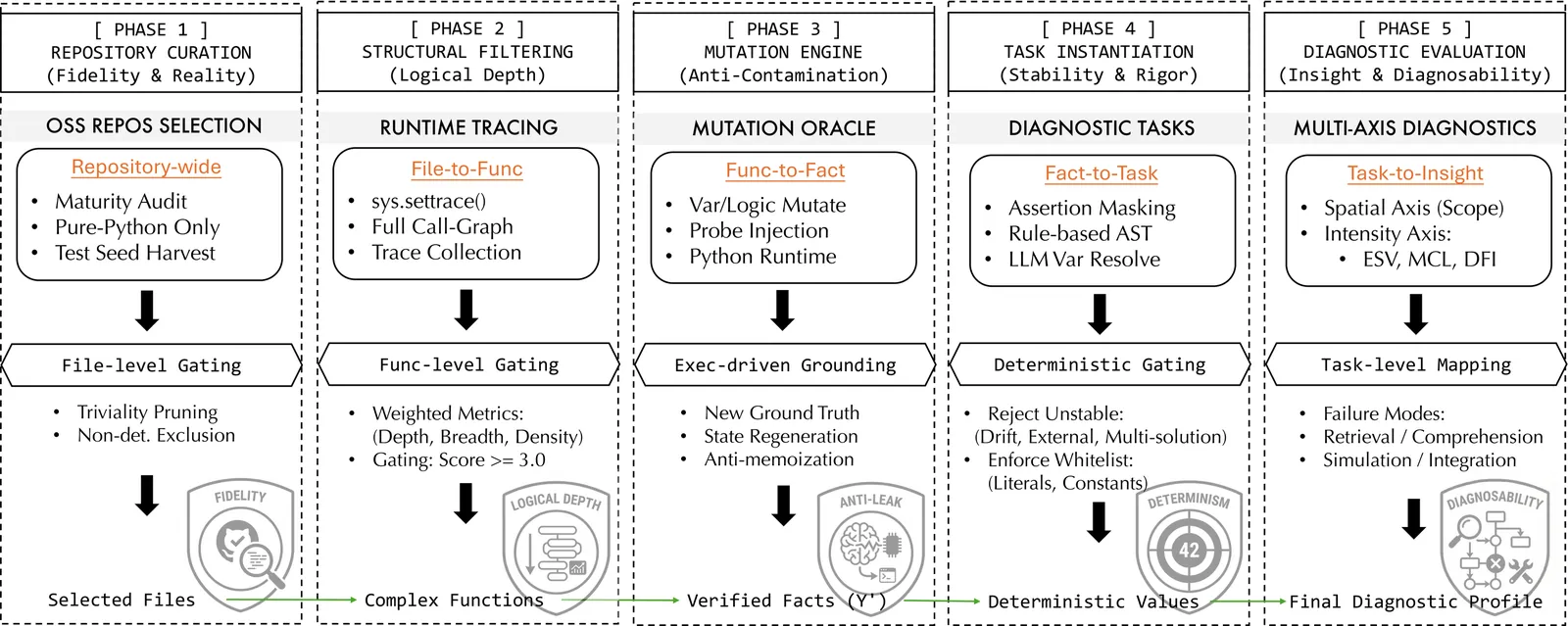
As large language models (LLMs) evolve into autonomous agents, evaluating repository-level reasoning, the ability to maintain logical consistency across massive, real-world, interdependent file systems, has become critical. Current benchmarks typically fluctuate between isolated code snippets and black-box evaluations. We present RepoReason, a white-box diagnostic benchmark centered on abductive assertion verification. To eliminate memorization while preserving authentic logical depth, we implement an execution-driven mutation framework that utilizes the environment as a semantic oracle to regenerate ground-truth states. Furthermore, we establish a fine-grained diagnostic system using dynamic program slicing, quantifying reasoning via three orthogonal metrics: $ESV$ (reading load), $MCL$ (simulation depth), and $DFI$ (integration width). Comprehensive evaluations of frontier models (e.g., Claude-4.5-Sonnet, DeepSeek-v3.1-Terminus) reveal a prevalent aggregation deficit, where integration width serves as the primary cognitive bottleneck. Our findings provide granular white-box insights for optimizing the next generation of agentic software engineering.

Many real-world software tasks require exact transcription of provided data into code, such as cryptographic constants, protocol test vectors, allowlists, and calibration tables. These tasks are operationally sensitive because small omissions or alterations can remain silent while producing syntactically valid programs. This paper introduces a deliberately minimal transcription-to-code benchmark to isolate this reliability concern in LLM-based code generation. Given a list of high-precision decimal constants, a model must generate Python code that embeds the constants verbatim and performs a simple aggregate computation. We describe the prompting variants, evaluation protocol based on exact-string inclusion, and analysis framework used to characterize state-tracking and long-horizon generation failures. The benchmark is intended as a compact stress test that complements existing code-generation evaluations by focusing on data integrity rather than algorithmic reasoning.
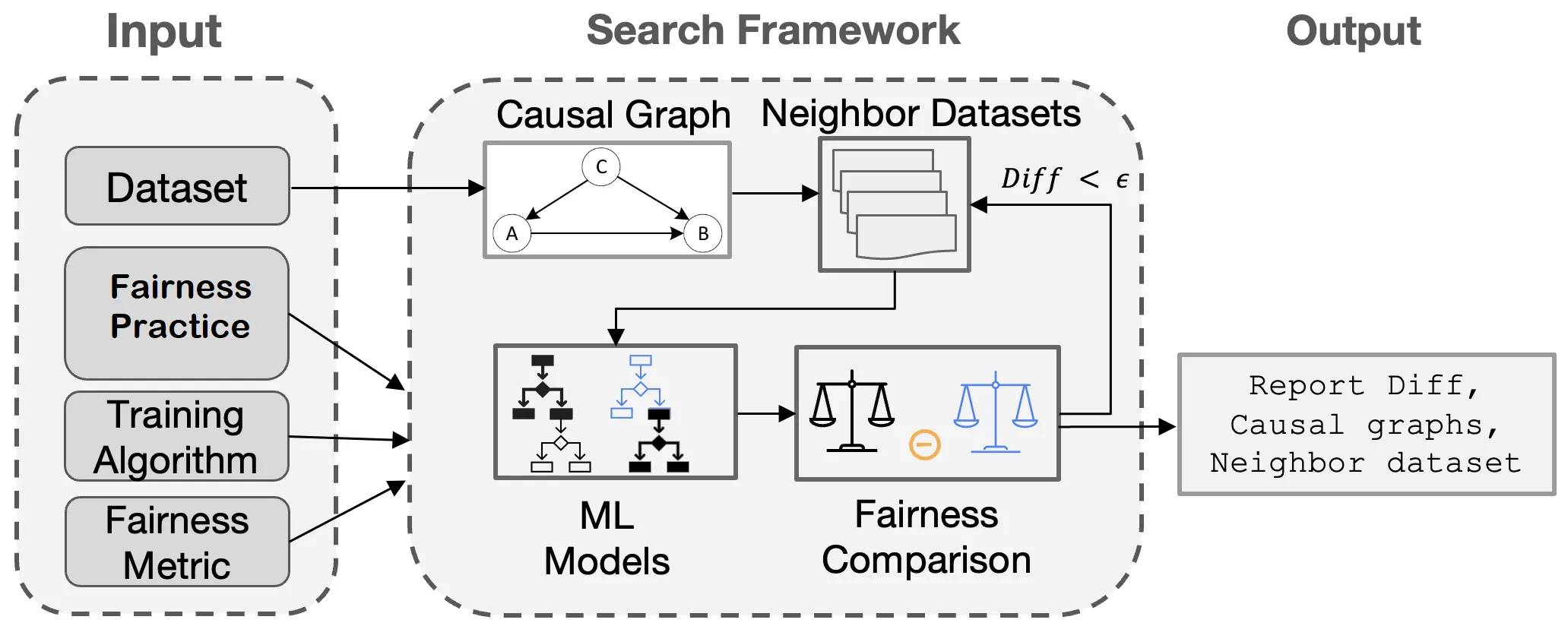
Machine learning (ML) algorithms are increasingly deployed to make critical decisions in socioeconomic applications such as finance, criminal justice, and autonomous driving. However, due to their data-driven and pattern-seeking nature, ML algorithms may develop decision logic that disproportionately distributes opportunities, benefits, resources, or information among different population groups, potentially harming marginalized communities. In response to such fairness concerns, the software engineering and ML communities have made significant efforts to establish the best practices for creating fair ML software. These include fairness interventions for training ML models, such as including sensitive features, selecting non-sensitive attributes, and applying bias mitigators. But how reliably can software professionals tasked with developing data-driven systems depend on these recommendations? And how well do these practices generalize in the presence of faulty labels, missing data, or distribution shifts? These questions form the core theme of this paper.
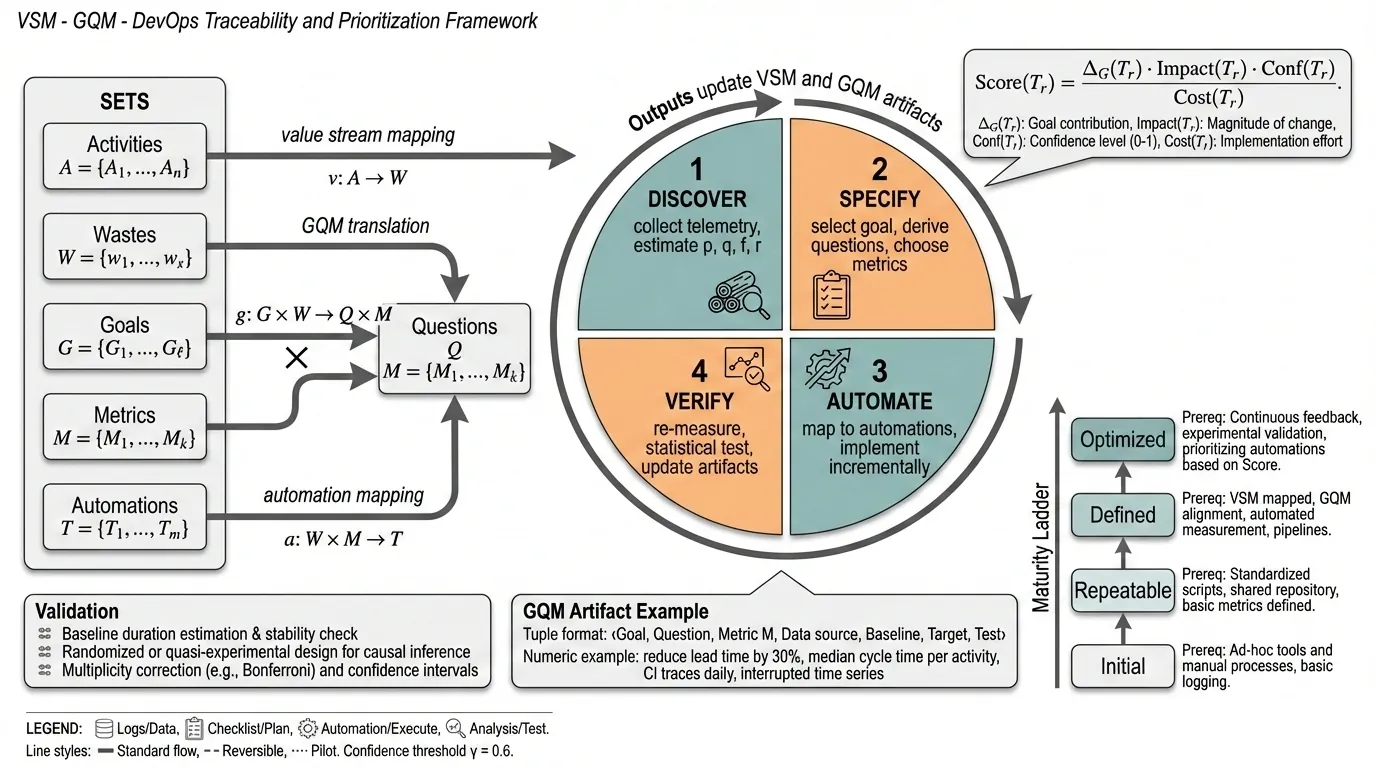
DevOps automation can accelerate software delivery, yet many organizations still struggle to justify and prioritize automation work in terms of strategic project-management outcomes such as waste reduction, delivery predictability, cross-team coordination, and customer-facing quality. This paper presents \textit{VSM--GQM--DevOps}, a unified, traceable framework that integrates (i) Value Stream Mapping (VSM) to visualize the end-to-end delivery system and quantify delays, rework, and handoffs, (ii) the Goal--Question--Metric (GQM) paradigm to translate stakeholder objectives into a minimal, decision-relevant measurement model (combining DORA with project and team outcomes), and (iii) maturity-aligned DevOps automation to remediate empirically observed bottlenecks through small, reversible interventions. The framework operationalizes traceability from observed waste to goal-aligned questions, metrics, and automation candidates, and provides a defensible prioritization approach that balances expected impact, confidence, and cost. We also define a multi-site, longitudinal mixed-method validation protocol that combines telemetry-based quasi-experimental analysis (interrupted time series and, where feasible, controlled rollouts) with qualitative triangulation from interviews and retrospectives. The expected contribution is a validated pathway and a set of practical instruments that enables organizations to select automation investments that demonstrably improve both delivery performance and project-management outcomes.
Testing is a critical practice for ensuring software correctness and long-term maintainability. As agentic coding tools increasingly submit pull requests (PRs), it becomes essential to understand how testing appears in these agent-driven workflows. Using the AIDev dataset, we present an empirical study of test inclusion in agentic pull requests. We examine how often tests are included, when they are introduced during the PR lifecycle and how test-containing PRs differ from non-test PRs in terms of size, turnaround time, and merge outcomes. Across agents, test-containing PRs are more common over time and tend to be larger and take longer to complete, while merge rates remain largely similar. We also observe variation across agents in both test adoption and the balance between test and production code within test PRs. Our findings provide a descriptive view of testing behavior in agentic pull requests and offer empirical grounding for future studies of autonomous software development.

Open-source scientific software is abundant, yet most tools remain difficult to compile, configure, and reuse, sustaining a small-workshop mode of scientific computing. This deployment bottleneck limits reproducibility, large-scale evaluation, and the practical integration of scientific tools into modern AI-for-Science (AI4S) and agentic workflows. We present Deploy-Master, a one-stop agentic workflow for large-scale tool discovery, build specification inference, execution-based validation, and publication. Guided by a taxonomy spanning 90+ scientific and engineering domains, our discovery stage starts from a recall-oriented pool of over 500,000 public repositories and progressively filters it to 52,550 executable tool candidates under license- and quality-aware criteria. Deploy-Master transforms heterogeneous open-source repositories into runnable, containerized capabilities grounded in execution rather than documentation claims. In a single day, we performed 52,550 build attempts and constructed reproducible runtime environments for 50,112 scientific tools. Each successful tool is validated by a minimal executable command and registered in SciencePedia for search and reuse, enabling direct human use and optional agent-based invocation. Beyond delivering runnable tools, we report a deployment trace at the scale of 50,000 tools, characterizing throughput, cost profiles, failure surfaces, and specification uncertainty that become visible only at scale. These results explain why scientific software remains difficult to operationalize and motivate shared, observable execution substrates as a foundation for scalable AI4S and agentic science.
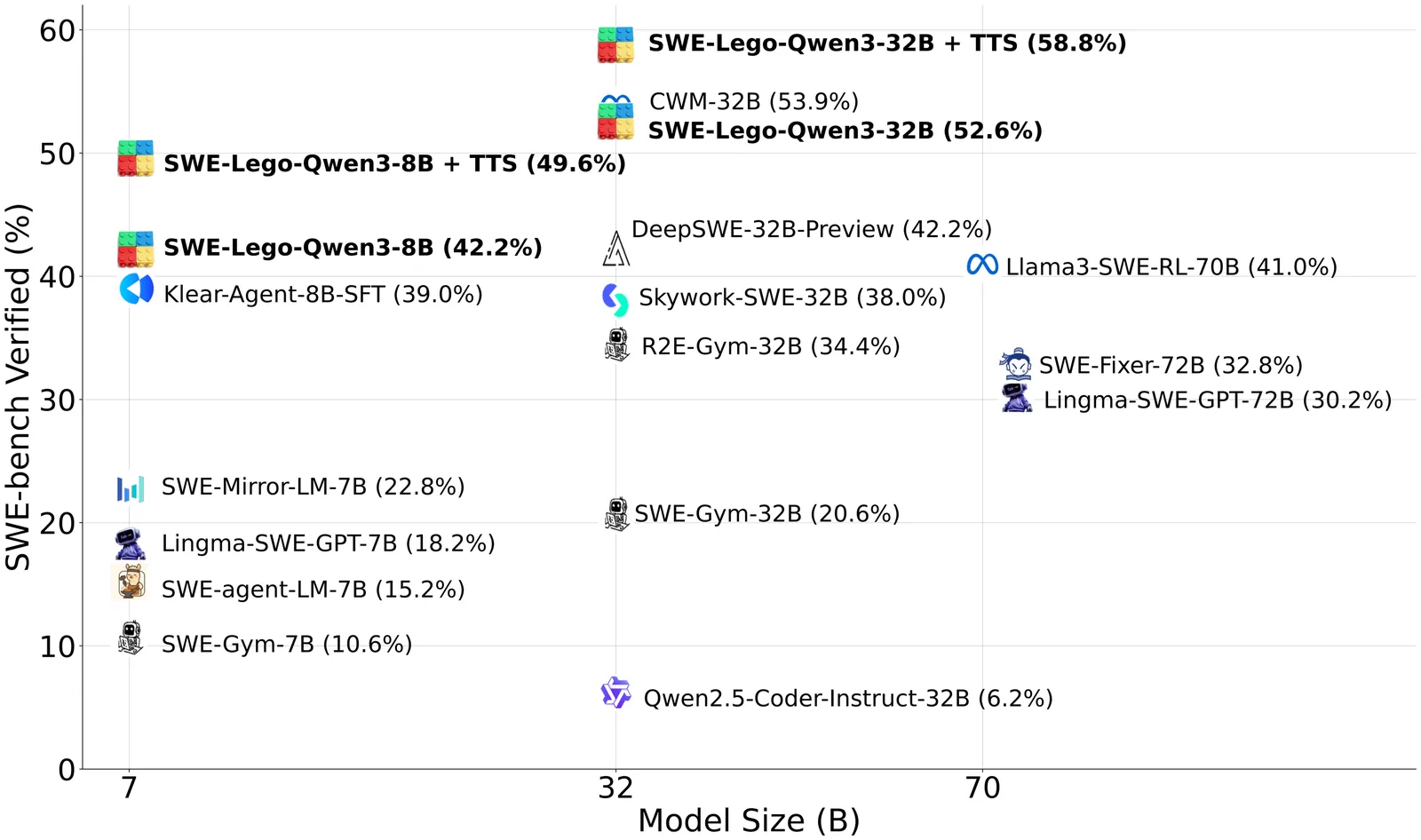
We present SWE-Lego, a supervised fine-tuning (SFT) recipe designed to achieve state-ofthe-art performance in software engineering (SWE) issue resolving. In contrast to prevalent methods that rely on complex training paradigms (e.g., mid-training, SFT, reinforcement learning, and their combinations), we explore how to push the limits of a lightweight SFT-only approach for SWE tasks. SWE-Lego comprises three core building blocks, with key findings summarized as follows: 1) the SWE-Lego dataset, a collection of 32k highquality task instances and 18k validated trajectories, combining real and synthetic data to complement each other in both quality and quantity; 2) a refined SFT procedure with error masking and a difficulty-based curriculum, which demonstrably improves action quality and overall performance. Empirical results show that with these two building bricks alone,the SFT can push SWE-Lego models to state-of-the-art performance among open-source models of comparable size on SWE-bench Verified: SWE-Lego-Qwen3-8B reaches 42.2%, and SWE-Lego-Qwen3-32B attains 52.6%. 3) We further evaluate and improve test-time scaling (TTS) built upon the SFT foundation. Based on a well-trained verifier, SWE-Lego models can be significantly boosted--for example, 42.2% to 49.6% and 52.6% to 58.8% under TTS@16 for the 8B and 32B models, respectively.
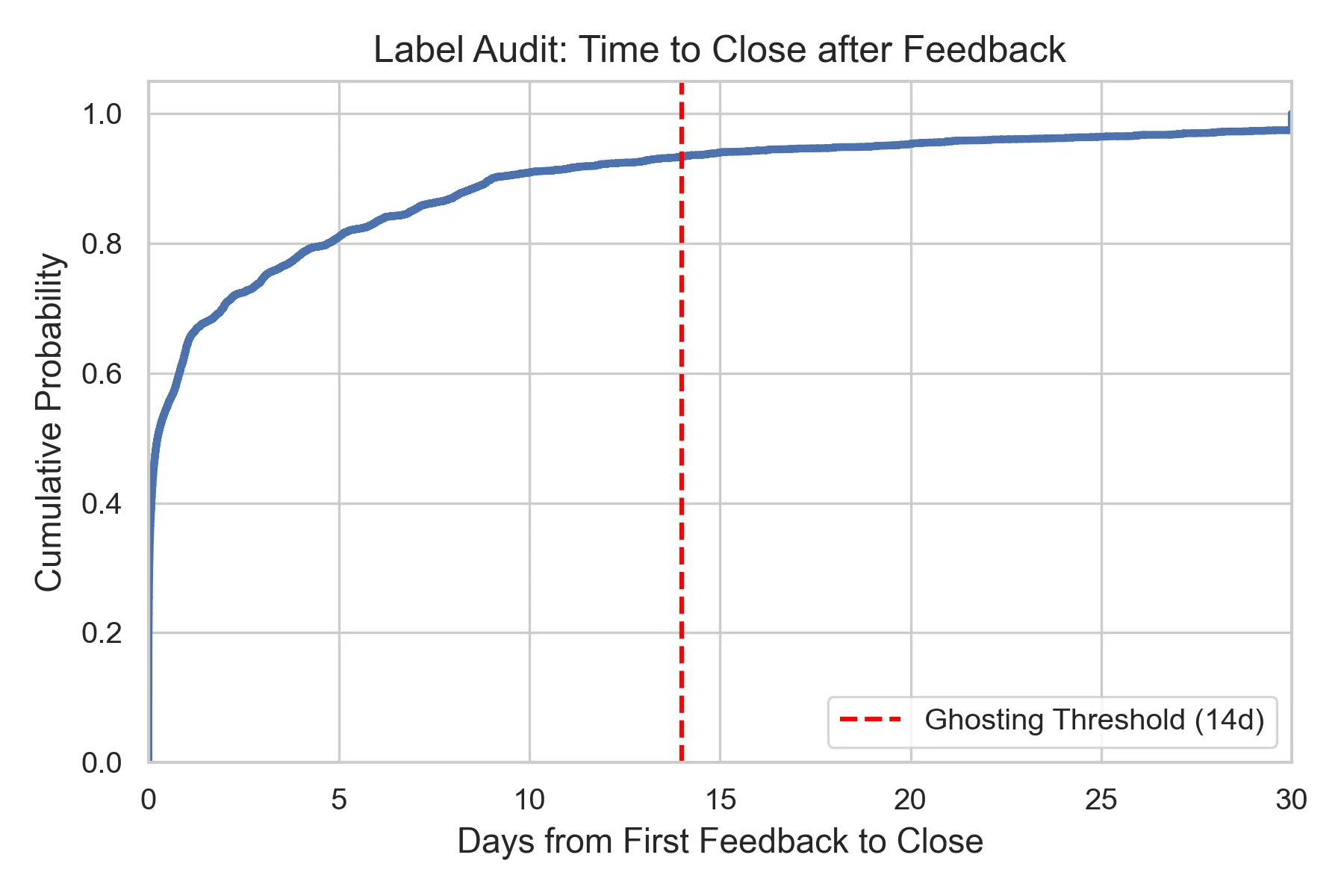
As autonomous AI agents transition from code completion tools to full-fledged teammates capable of opening pull requests (PRs) at scale, software maintainers face a new challenge: not just reviewing code, but managing complex interaction loops with non-human contributors. This paradigm shift raises a critical question: can we predict which agent-generated PRs will consume excessive review effort before any human interaction begins? Analyzing 33,707 agent-authored PRs from the AIDev dataset across 2,807 repositories, we uncover a striking two-regime behavioral pattern that fundamentally distinguishes autonomous agents from human developers. The first regime, representing 28.3 percent of all PRs, consists of instant merges (less than 1 minute), reflecting success on narrow automation tasks. The second regime involves iterative review cycles where agents frequently stall or abandon refinement (ghosting). We propose a Circuit Breaker triage model that predicts high-review-effort PRs (top 20 percent) at creation time using only static structural features. A LightGBM model achieves AUC 0.957 on a temporal split, while semantic text features (TF-IDF, CodeBERT) provide negligible predictive value. At a 20 percent review budget, the model intercepts 69 percent of total review effort, enabling zero-latency governance. Our findings challenge prevailing assumptions in AI-assisted code review: review burden is dictated by what agents touch, not what they say, highlighting the need for structural governance mechanisms in human-AI collaboration.
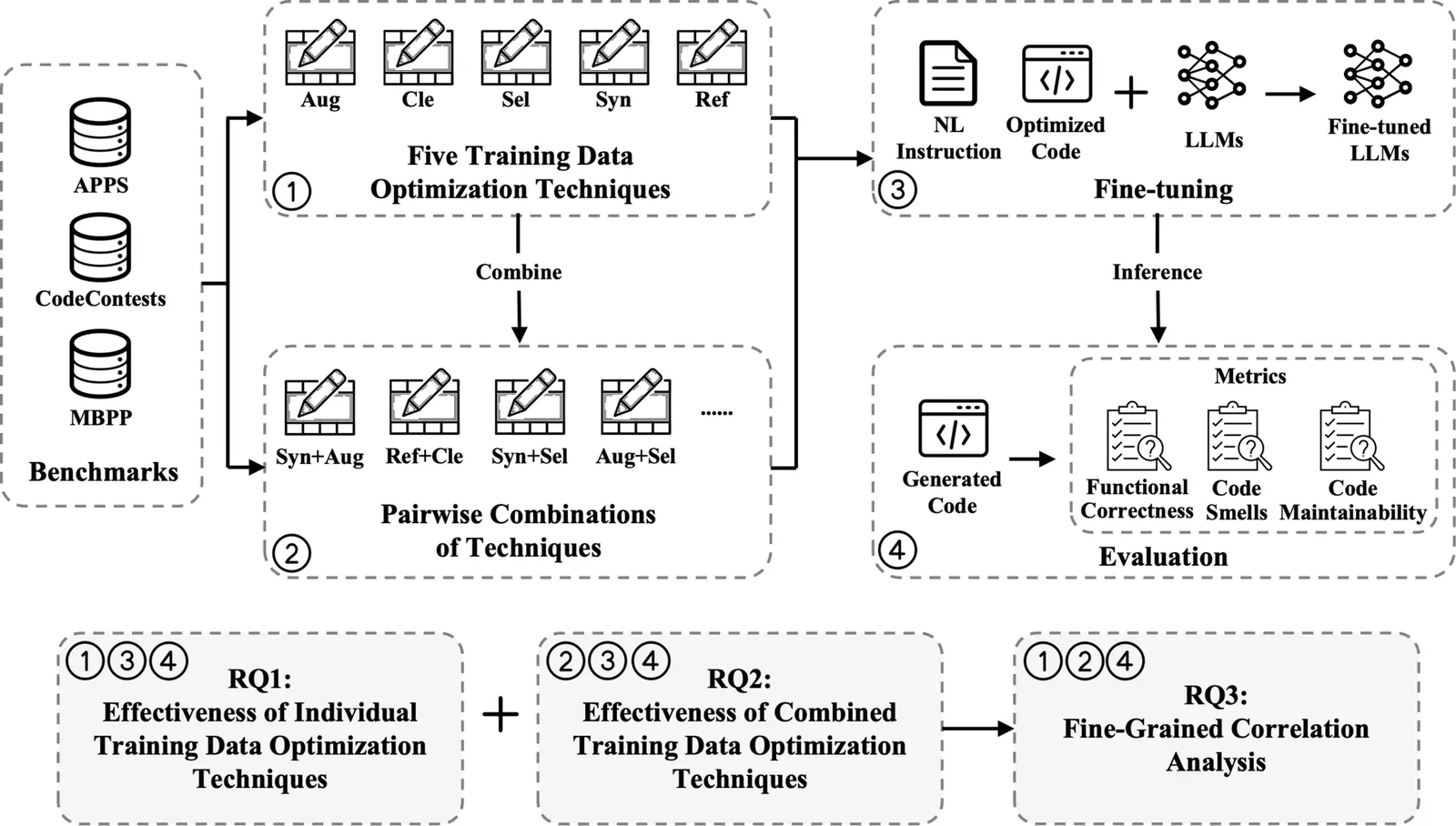
Large language models (LLMs) have achieved remarkable progress in code generation, largely driven by the availability of high-quality code datasets for effective training. To further improve data quality, numerous training data optimization techniques have been proposed; however, their overall effectiveness has not been systematically evaluated. To bridge this gap, we conduct the first large-scale empirical study, examining five widely-used training data optimization techniques and their pairwise combinations for LLM-based code generation across three benchmarks and four LLMs. Our results show that data synthesis is the most effective technique for improving functional correctness and reducing code smells, although it performs relatively worse on code maintainability compared to data refactoring, cleaning, and selection. Regarding combinations, we find that most combinations do not further improve functional correctness but can effectively enhance code quality (code smells and maintainability). Among all combinations, data synthesis combined with data refactoring achieves the strongest overall performance. Furthermore, our fine-grained analysis reinforces these findings and provides deeper insights into how individual techniques and their combinations influence code generation effectiveness. Overall, this work represents a first step toward a systematic understanding of training data optimization and combination strategies, offering practical guidance for future research and deployment in LLM-based code generation.
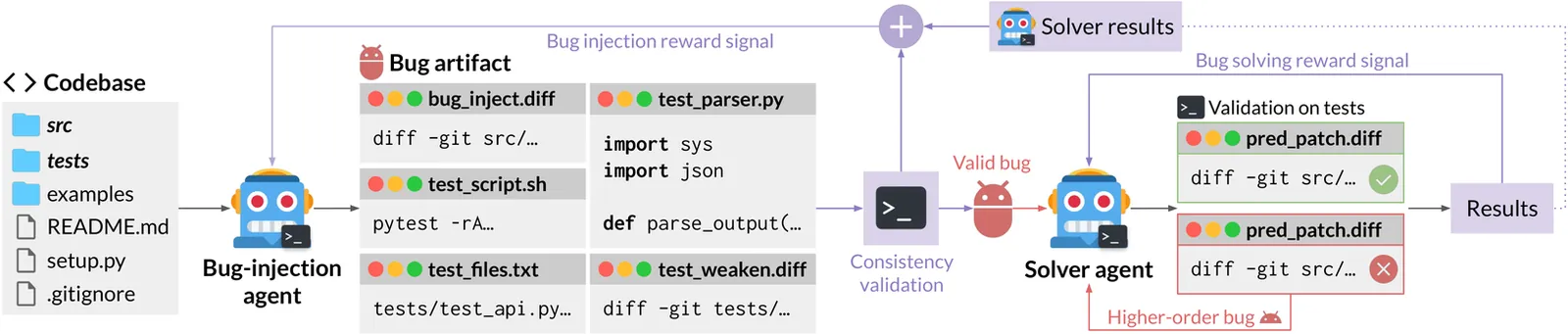
While current software agents powered by large language models (LLMs) and agentic reinforcement learning (RL) can boost programmer productivity, their training data (e.g., GitHub issues and pull requests) and environments (e.g., pass-to-pass and fail-to-pass tests) heavily depend on human knowledge or curation, posing a fundamental barrier to superintelligence. In this paper, we present Self-play SWE-RL (SSR), a first step toward training paradigms for superintelligent software agents. Our approach takes minimal data assumptions, only requiring access to sandboxed repositories with source code and installed dependencies, with no need for human-labeled issues or tests. Grounded in these real-world codebases, a single LLM agent is trained via reinforcement learning in a self-play setting to iteratively inject and repair software bugs of increasing complexity, with each bug formally specified by a test patch rather than a natural language issue description. On the SWE-bench Verified and SWE-Bench Pro benchmarks, SSR achieves notable self-improvement (+10.4 and +7.8 points, respectively) and consistently outperforms the human-data baseline over the entire training trajectory, despite being evaluated on natural language issues absent from self-play. Our results, albeit early, suggest a path where agents autonomously gather extensive learning experiences from real-world software repositories, ultimately enabling superintelligent systems that exceed human capabilities in understanding how systems are constructed, solving novel challenges, and autonomously creating new software from scratch.

Locating the files and functions requiring modification in large open-source software (OSS) repositories is challenging due to their scale and structural complexity. Existing large language model (LLM)-based methods typically treat this as a repository-level retrieval task and rely on multiple auxiliary tools, which overlook code execution logic and complicate model control. We propose RepoNavigator, an LLM agent equipped with a single execution-aware tool-jumping to the definition of an invoked symbol. This unified design reflects the actual flow of code execution while simplifying tool manipulation. RepoNavigator is trained end-to-end via Reinforcement Learning (RL) directly from a pretrained model, without any closed-source distillation. Experiments demonstrate that RL-trained RepoNavigator achieves state-of-the-art performance, with the 7B model outperforming 14B baselines, the 14B model surpassing 32B competitors, and even the 32B model exceeding closed-source models such as Claude-3.7. These results confirm that integrating a single, structurally grounded tool with RL training provides an efficient and scalable solution for repository-level issue localization.
Coding agents are becoming increasingly capable of completing end-to-end software engineering workflows that previously required a human developer, including raising pull requests (PRs) to propose their changes. However, we still know little about how these agents use libraries when generating code, a core part of real-world software development. To fill this gap, we study 26,760 agent-authored PRs from the AIDev dataset to examine three questions: how often do agents import libraries, how often do they introduce new dependencies (and with what versioning), and which specific libraries do they choose? We find that agents often import libraries (29.5% of PRs) but rarely add new dependencies (1.3% of PRs); and when they do, they follow strong versioning practices (75.0% specify a version), an improvement on direct LLM usage where versions are rarely mentioned. Generally, agents draw from a surprisingly diverse set of external libraries, contrasting with the limited "library preferences" seen in prior non-agentic LLM studies. Our results offer an early empirical view into how AI coding agents interact with today's software ecosystems.
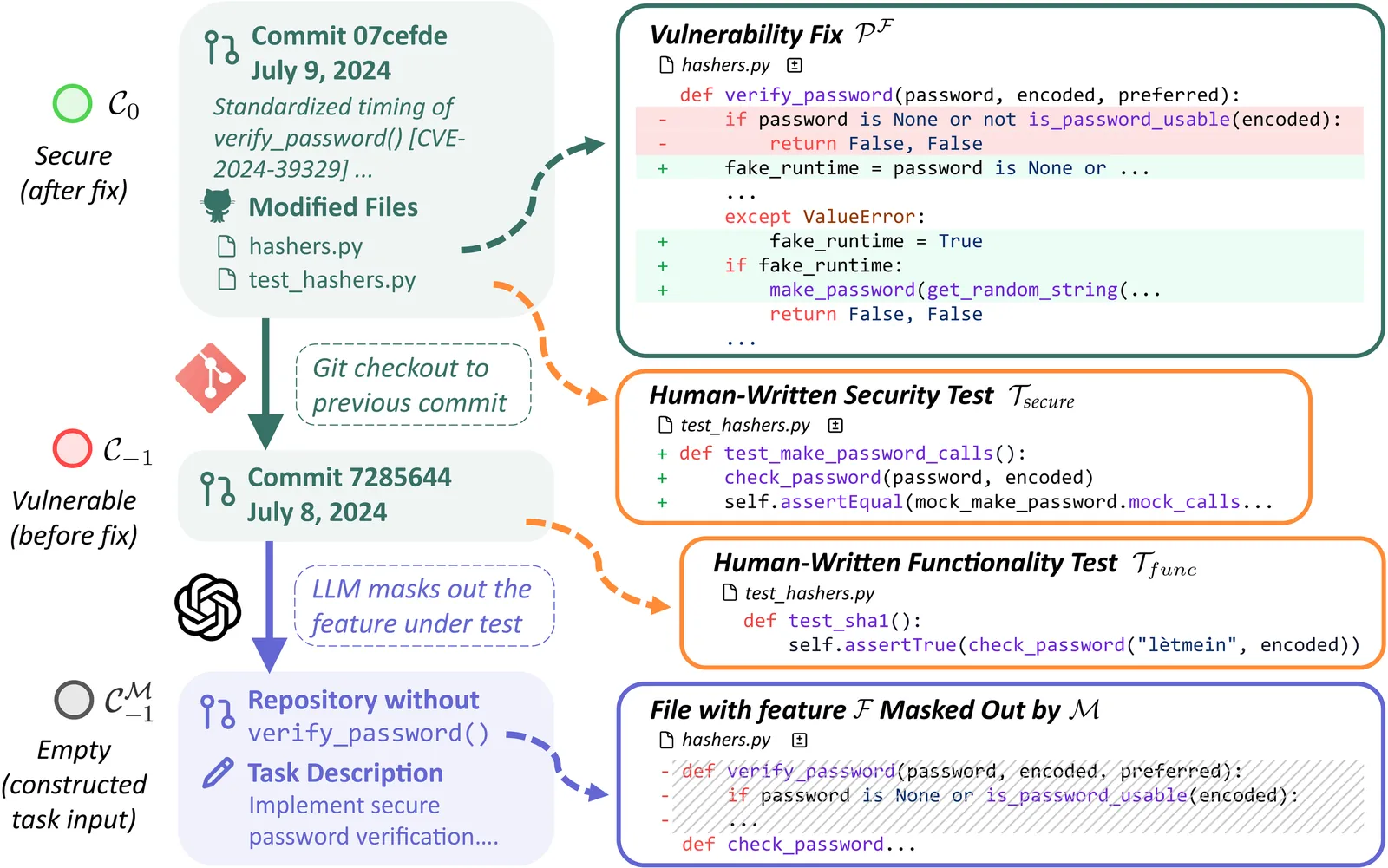
Vibe coding is a new programming paradigm in which human engineers instruct large language model (LLM) agents to complete complex coding tasks with little supervision. Although it is increasingly adopted, are vibe coding outputs really safe to deploy in production? To answer this question, we propose SU S VI B E S, a benchmark consisting of 200 feature-request software engineering tasks from real-world open-source projects, which, when given to human programmers, led to vulnerable implementations. We evaluate multiple widely used coding agents with frontier models on this benchmark. Disturbingly, all agents perform poorly in terms of software security. Although 61% of the solutions from SWE-Agent with Claude 4 Sonnet are functionally correct, only 10.5% are secure. Further experiments demonstrate that preliminary security strategies, such as augmenting the feature request with vulnerability hints, cannot mitigate these security issues. Our findings raise serious concerns about the widespread adoption of vibe-coding, particularly in security-sensitive applications.
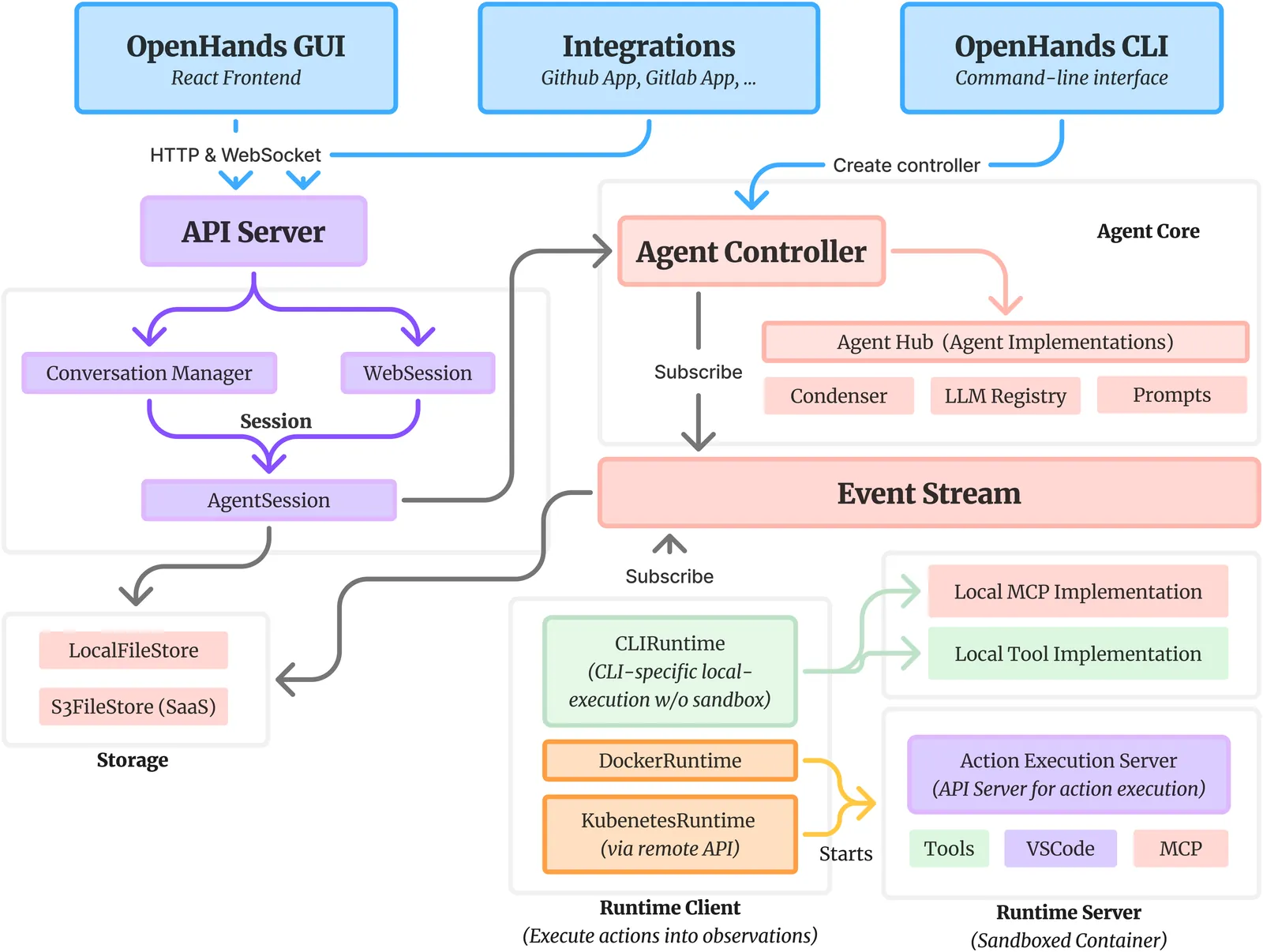
Agents are now used widely in the process of software development, but building production-ready software engineering agents is a complex task. Deploying software agents effectively requires flexibility in implementation and experimentation, reliable and secure execution, and interfaces for users to interact with agents. In this paper, we present the OpenHands Software Agent SDK, a toolkit for implementing software development agents that satisfy these desiderata. This toolkit is a complete architectural redesign of the agent components of the popular OpenHands framework for software development agents, which has 64k+ GitHub stars. To achieve flexibility, we design a simple interface for implementing agents that requires only a few lines of code in the default case, but is easily extensible to more complex, full-featured agents with features such as custom tools, memory management, and more. For security and reliability, it delivers seamless local-to-remote execution portability, integrated REST/WebSocket services. For interaction with human users, it can connect directly to a variety of interfaces, such as visual workspaces (VS Code, VNC, browser), command-line interfaces, and APIs. Compared with existing SDKs from OpenAI, Claude, and Google, OpenHands uniquely integrates native sandboxed execution, lifecycle control, model-agnostic multi-LLM routing, and built-in security analysis. Empirical results on SWE-Bench Verified and GAIA benchmarks demonstrate strong performance. Put together, these elements allow the OpenHands Software Agent SDK to provide a practical foundation for prototyping, unlocking new classes of custom applications, and reliably deploying agents at scale.
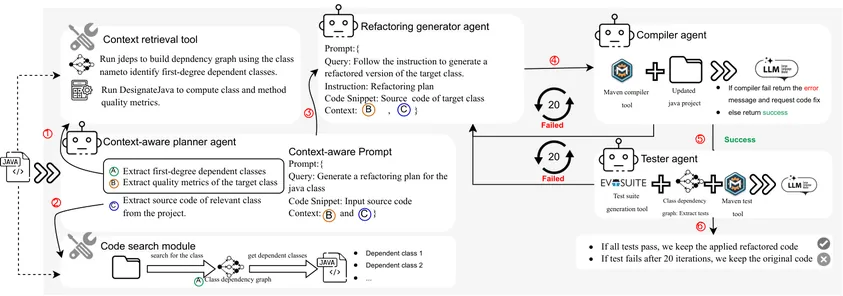
Large Language Models (LLMs) have substantially influenced various software engineering tasks. Indeed, in the case of software refactoring, traditional LLMs have shown the ability to reduce development time and enhance code quality. However, these LLMs often rely on static, detailed instructions for specific tasks. In contrast, LLM-based agents can dynamically adapt to evolving contexts and autonomously make decisions by interacting with software tools and executing workflows. In this paper, we explore the potential of LLM-based agents in supporting refactoring activities. Specifically, we introduce RefAgent, a multi-agent LLM-based framework for end-to-end software refactoring. RefAgent consists of specialized agents responsible for planning, executing, testing, and iteratively refining refactorings using self-reflection and tool-calling capabilities. We evaluate RefAgent on eight open-source Java projects, comparing its effectiveness against a single-agent approach, a search-based refactoring tool, and historical developer refactorings. Our assessment focuses on: (1) the impact of generated refactorings on software quality, (2) the ability to identify refactoring opportunities, and (3) the contribution of each LLM agent through an ablation study. Our results show that RefAgent achieves a median unit test pass rate of 90%, reduces code smells by a median of 52.5%, and improves key quality attributes (e.g., reusability) by a median of 8.6%. Additionally, it closely aligns with developer refactorings and the search-based tool in identifying refactoring opportunities, attaining a median F1-score of 79.15% and 72.7%, respectively. Compared to single-agent approaches, RefAgent improves the median unit test pass rate by 64.7% and the median compilation success rate by 40.1%. These findings highlight the promise of multi-agent architectures in advancing automated software refactoring.