Human-Computer Interaction
arXiv:cs.HC
Covers human factors, user interfaces, and collaborative computing. Roughly includes material in ACM Subject Classes H.1.2 and all of H.5, except for H.5.1.
Looking for a broader view? This category is part of:
Covers human factors, user interfaces, and collaborative computing. Roughly includes material in ACM Subject Classes H.1.2 and all of H.5, except for H.5.1.
Looking for a broader view? This category is part of:
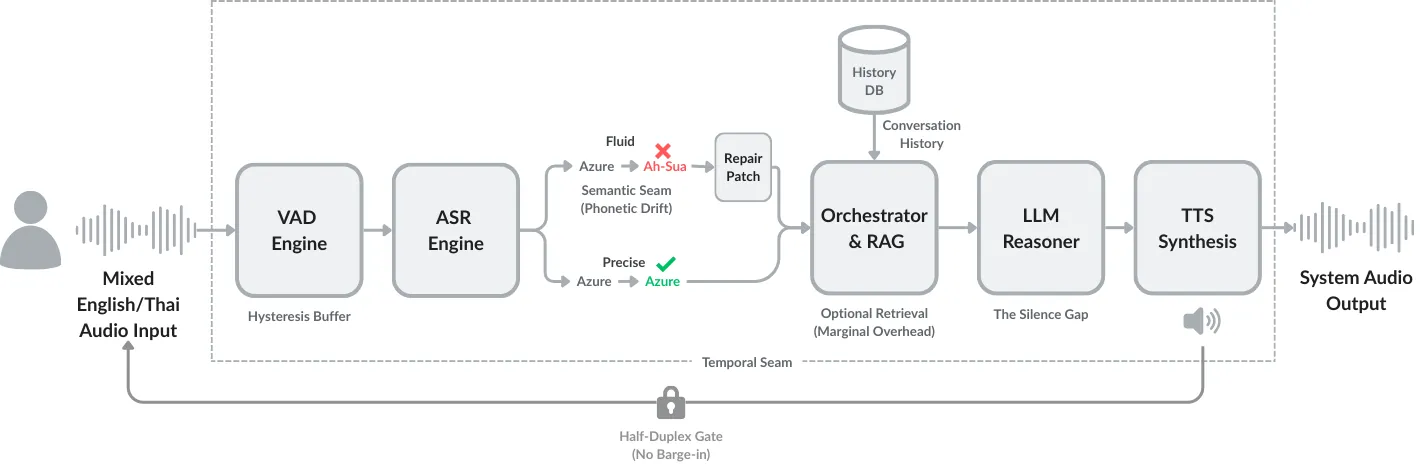
While voice-based AI systems have achieved remarkable generative capabilities, their interactions often feel conversationally broken. This paper examines the interactional friction that emerges in modular Speech-to-Speech Retrieval-Augmented Generation (S2S-RAG) pipelines. By analyzing a representative production system, we move beyond simple latency metrics to identify three recurring patterns of conversational breakdown: (1) Temporal Misalignment, where system delays violate user expectations of conversational rhythm; (2) Expressive Flattening, where the loss of paralinguistic cues leads to literal, inappropriate responses; and (3) Repair Rigidity, where architectural gating prevents users from correcting errors in real-time. Through system-level analysis, we demonstrate that these friction points should not be understood as defects or failures, but as structural consequences of a modular design that prioritizes control over fluidity. We conclude that building natural spoken AI is an infrastructure design challenge, requiring a shift from optimizing isolated components to carefully choreographing the seams between them.
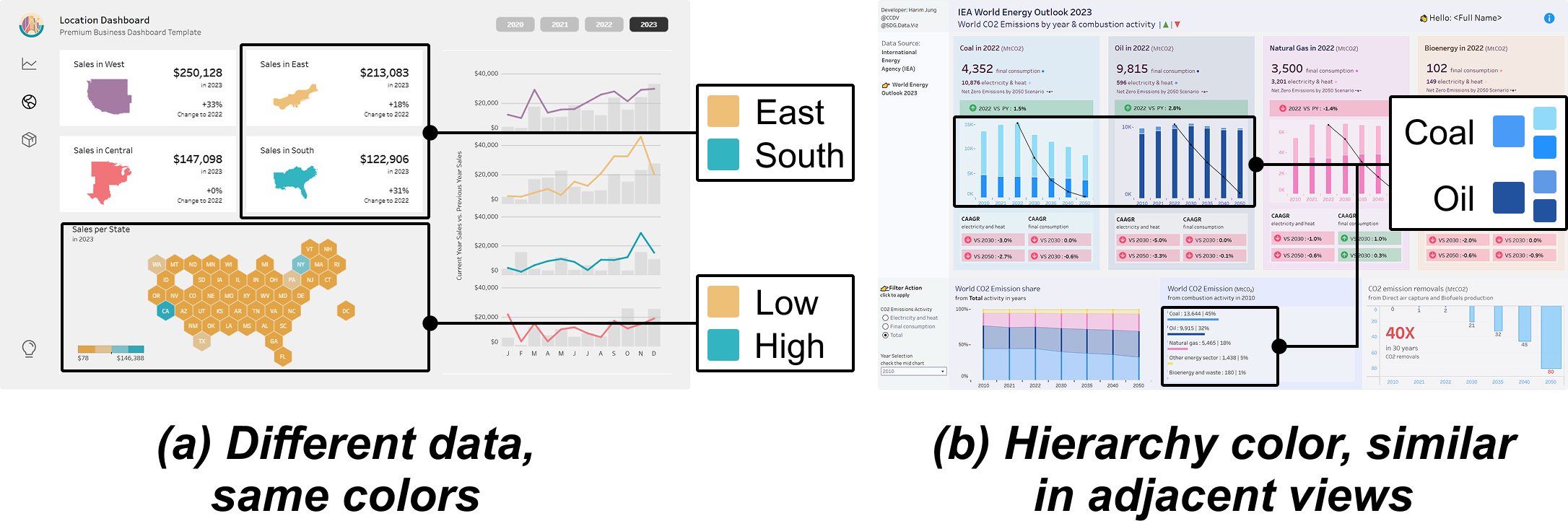
Multiple-view (MV) visualization provides a comprehensive and integrated perspective on complex data, establishing itself as an effective method for visual communication and exploratory data analysis. While existing studies have predominantly focused on designing explicit visual linkages and coordinated interactions to facilitate the exploration of MV visualizations, these approaches often demand extra graphical and interactive effort, overlooking the potential of color as an effective channel for encoding data and relationships. Addressing this oversight, we introduce C2Views, a new framework for colormap design that implicitly shows the relation across views. We begin by structuring the components and their relationships within MVs into a knowledge-based graph specification, wherein colormaps, data, and views are denoted as entities, and the interactions among them are illustrated as relations. Building on this representation, we formulate the design criteria as an optimization problem and employ a genetic algorithm enhanced by Pareto optimality, generating colormaps that balance single-view effectiveness and multiple-view consistency. Our approach is further complemented with an interactive interface for user-intended refinement. We demonstrate the feasibility of C2Views through various colormap design examples for MVs, underscoring its adaptability to diverse data relationships and view layouts. Comparative user studies indicate that our method outperforms the existing approach in facilitating color distinction and enhancing multiple-view consistency, thereby simplifying data exploration processes.

Brain-computer interfaces (BCIs) allow direct communication between the brain and electronics without the need for speech or physical movement. Such interfaces can be particularly beneficial in applications requiring rapid response times, such as driving, where a vehicle's advanced driving assistance systems could benefit from immediate understanding of a driver's intentions. This study presents a novel method for predicting a driver's intention to steer using electroencephalography (EEG) signals through deep learning. A driving simulator created a controlled environment in which participants imagined controlling a vehicle during various driving scenarios, including left and right turns, as well as straight driving. A convolutional neural network (CNN) classified the detected EEG data with minimal pre-processing. Our model achieved an accuracy of 83.7% in distinguishing between the three steering intentions and demonstrated the ability of CNNs to process raw EEG data effectively. The classification accuracy was highest for right-turn segments, which suggests a potential spatial bias in brain activity. This study lays the foundation for more intuitive brain-to-vehicle communication systems.
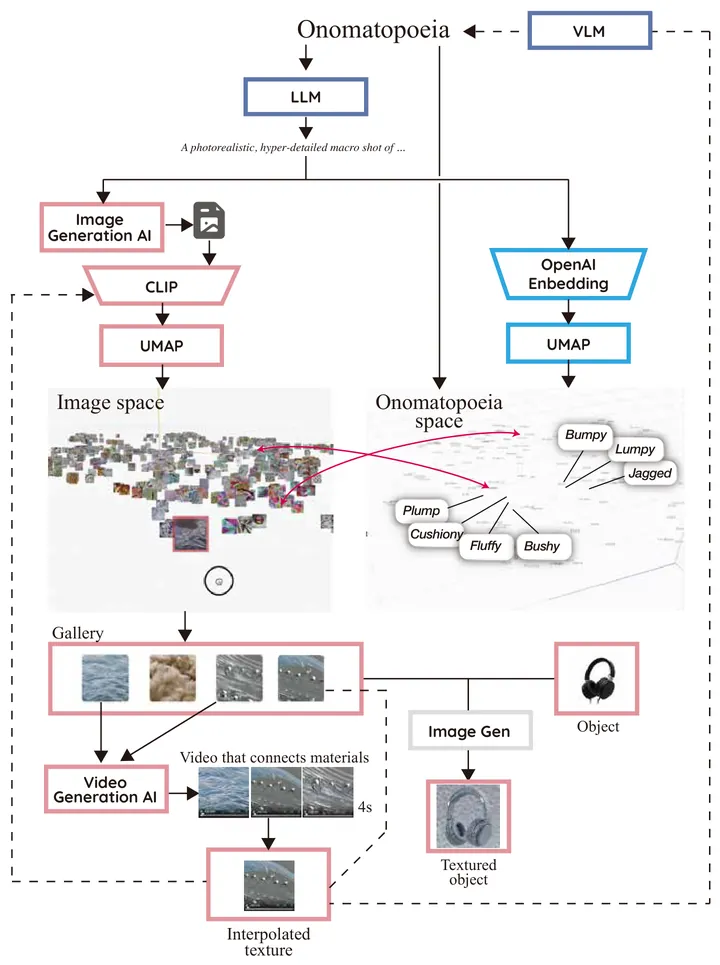
Humans can finely perceive material textures, yet articulating such somatic impressions in words is a cognitive bottleneck in design ideation. We present OnomaCompass, a web-based exploration system that links sound-symbolic onomatopoeia and visual texture representations to support early-stage material discovery. Instead of requiring users to craft precise prompts for generative AI, OnomaCompass provides two coordinated latent-space maps--one for texture images and one for onomatopoeic term--built from an authored dataset of invented onomatopoeia and corresponding textures generated via Stable Diffusion. Users can navigate both spaces, trigger cross-modal highlighting, curate findings in a gallery, and preview textures applied to objects via an image-editing model. The system also supports video interpolation between selected textures and re-embedding of extracted frames to form an emergent exploration loop. We conducted a within-subjects study with 11 participants comparing OnomaCompass to a prompt-based image-generation workflow using Gemini 2.5 Flash Image ("Nano Banana"). OnomaCompass significantly reduced workload (NASA-TLX overall, mental demand, effort, and frustration; p < .05) and increased hedonic user experience (UEQ), while usability (SUS) favored the baseline. Qualitative findings indicate that OnomaCompass helps users externalize vague sensory expectations and promotes serendipitous discovery, but also reveals interaction challenges in spatial navigation. Overall, leveraging sound symbolism as a lightweight cue offers a complementary approach to Kansei-driven material ideation beyond prompt-centric generation.

Thermal feedback is critical to a range of Virtual Reality (VR) applications, such as firefighting training or thermal comfort simulation. Previous studies showed that adding congruent thermal feedback positively influences User eXperience (UX). However, existing work did not compare different levels of thermal feedback quality and mostly used less immersive virtual environments. To investigate these gaps in the scientific literature, we conducted a within-participant user study in two highly-immersive scenarios, Desert Island (n=25) and Snowy Mountains (n=24). Participants explored the scenarios in three conditions (Audio-Visual only, Static-Thermal Feedback, and Dynamic-Thermal Feedback). To assess the complex and subtle effects of thermal feedback on UX, we performed a multimodal analysis by crossing data from questionnaires, semi-structured interviews, and behavioral indicators. Our results show that despite an already high level of presence in the Audio-Visual only condition, adding thermal feedback increased presence further. Comparison between levels of thermal feedback quality showed no significant difference in UX questionnaires, however this result is nuanced according to participant profiles and interviews. Furthermore, we show that although the order of passage did not influence UX directly, it influenced user behavior. We propose guidelines for the use of thermal feedback in VR, and the design of studies in complex multisensory scenarios.
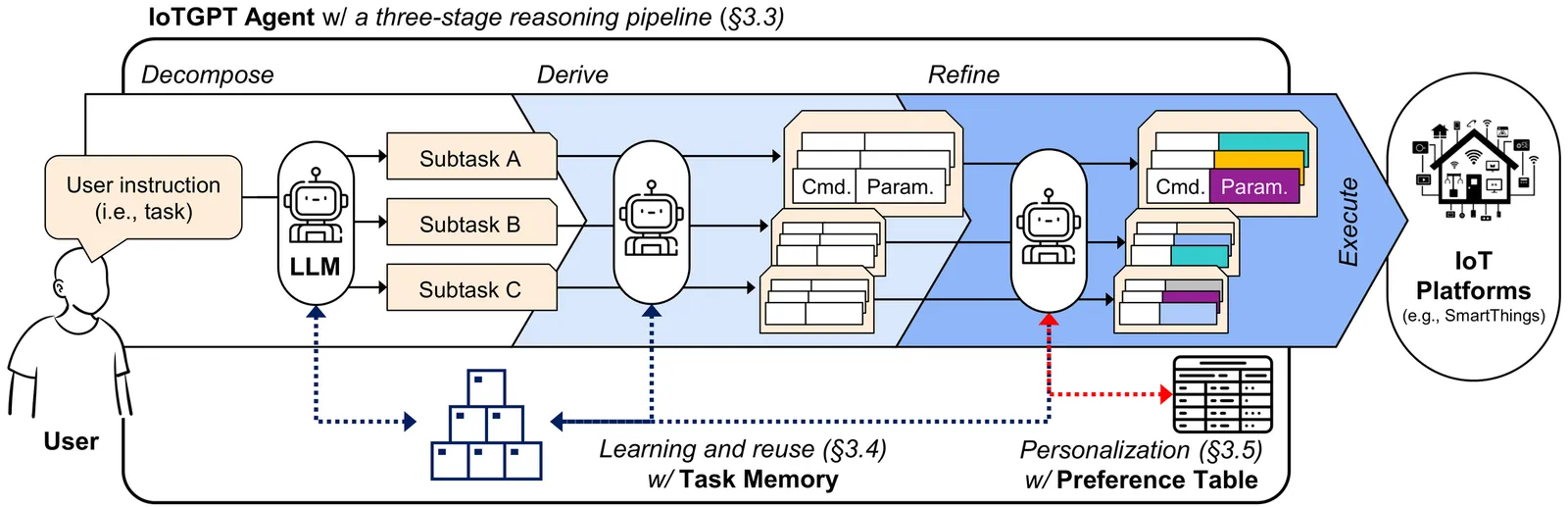
The proliferation of smart home devices has increased the complexity of controlling and managing them, leading to user fatigue. In this context, large language models (LLMs) offer a promising solution by enabling natural-language interfaces for Internet of Things (IoT) control. However, existing LLM-based approaches suffer from unreliable and inefficient device control due to the non-deterministic nature of LLMs, high inference latency and cost, and limited personalization. To address these challenges, we present IoTGPT, an LLM-based smart home agent designed to execute IoT commands in a reliable, efficient, and personalized manner. Inspired by how humans manage complex tasks, IoTGPT decomposes user instructions into subtasks and memorizes them. By reusing learned subtasks, subsequent instructions can be processed more efficiently with fewer LLM calls, improving reliability and reducing both latency and cost. IoTGPT also supports fine-grained personalization by adapting individual subtasks to user preferences. Our evaluation demonstrates that IoTGPT outperforms baselines in accuracy, latency/cost, and personalization, while reducing user workload.
Online recruitment platforms have become the dominant channel for modern hiring, yet most platforms offer only basic filtering capabilities, such as job title, keyword, and salary range. This hinders comprehensive analysis of multi-attribute relationships and job market patterns across different scales. We present RecruitScope, a visual analytics system designed to support multidimensional and cross-level exploration of recruitment data for job seekers and employers, particularly HR specialists. Through coordinated visualizations, RecruitScope enables users to analyze job positions and salary patterns from multiple perspectives, interpret industry dynamics at the macro level, and identify emerging positions at the micro level. We demonstrate the effectiveness of RecruitScope through case studies that reveal regional salary distribution patterns, characterize industry growth trajectories, and discover high-demand emerging roles in the job market.
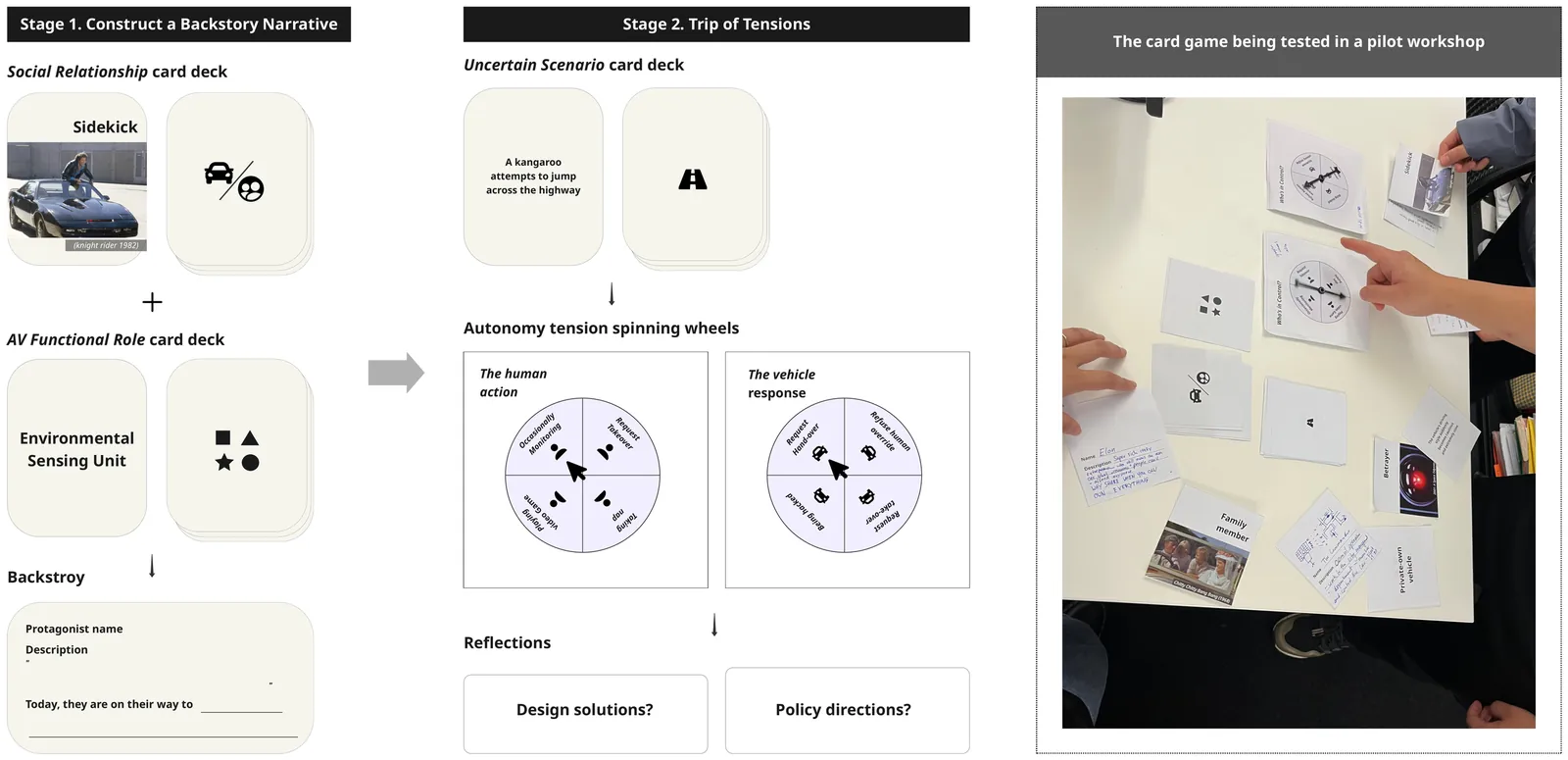
The rapid advancement of autonomous vehicle (AV) technologies is fundamentally reshaping paradigms of human-vehicle collaboration, raising not only an urgent need for innovative design solutions but also for policies that address corresponding broader tensions in society. To bridge the gap between HCI research and policy making, this workshop will bring together researchers and practitioners in the automotive community to explore AV policy directions through collaborative speculation on the future of AVs. We designed The UnScripted Trip, a card game rooted in fictional narratives of autonomous mobility, to surface tensions around human-vehicle collaboration in future AV scenarios and to provoke critical reflections on design solutions and policy directions. Our goal is to provide an engaging, participatory space and method for automotive researchers, designers, and industry practitioners to collectively explore and shape the future of human-vehicle collaboration and its policy implications.

Virtual reality (VR) has been increasingly utilised as a simulation tool for human-robot interaction (HRI) studies due to its ability to facilitate fast and flexible prototyping. Despite efforts to achieve high validity in VR studies, haptic sensation, an essential sensory modality for perception and a critical factor in enhancing VR realism, is often absent from these experiments. Studying an interactive robot help-seeking scenario, we used a VR simulation with haptic gloves that provide highly realistic tactile and force feedback to examine the effects of haptic sensation on VR-based HRI. We compared participants' sense of presence and their assessments of the robot to a traditional setup using hand controllers. Our results indicate that haptic sensation enhanced participants' social and self-presence in VR and fostered more diverse and natural bodily engagement. Additionally, haptic sensations significantly influenced participants' affective-related perceptions of the robot. Our study provides insights to guide HRI researchers in building VR-based simulations that better align with their study contexts and objectives.
Health information websites offer instantaneous access to information, but have important privacy implications as they can associate a visitor with specific medical conditions. We interviewed 35 residents of Canada to better understand whether and how online health information seekers exercise three potential means of protection against surveillance: website selection, privacy-enhancing technologies, and self-censorship, as well as their understanding of web tracking. Our findings reveal how users' limited initiative and effectiveness in protecting their privacy could be associated with a missing or inaccurate understanding of how implicit data collection by third parties takes place on the web, and who collects the data. We conclude that to help Internet users achieve better self-data protection, we may need to shift privacy awareness efforts from what information is collected to how it is collected.
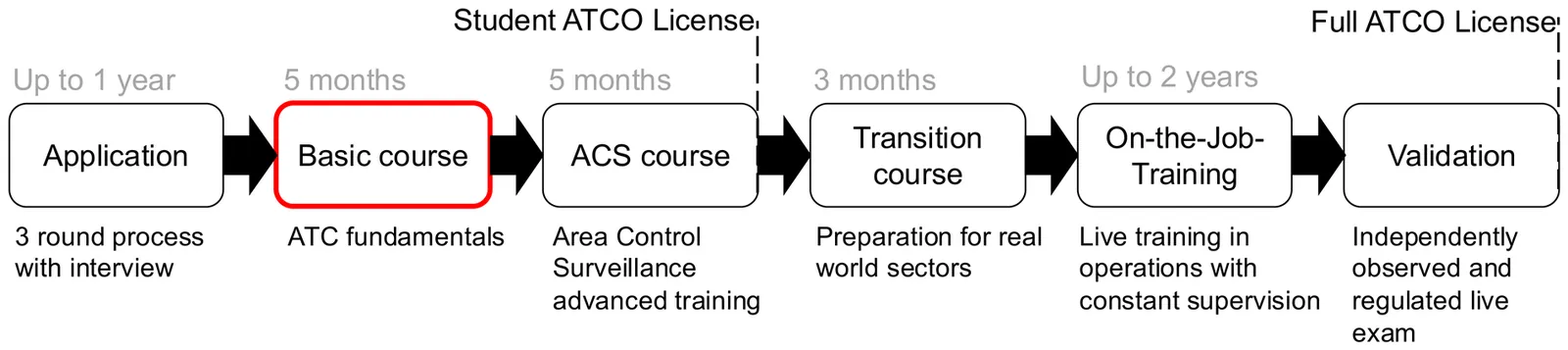
We present a rigorous, human-in-the-loop evaluation framework for assessing the performance of AI agents on the task of Air Traffic Control, grounded in a regulator-certified simulator-based curriculum used for training and testing real-world trainee controllers. By leveraging legally regulated assessments and involving expert human instructors in the evaluation process, our framework enables a more authentic and domain-accurate measurement of AI performance. This work addresses a critical gap in the existing literature: the frequent misalignment between academic representations of Air Traffic Control and the complexities of the actual operational environment. It also lays the foundations for effective future human-machine teaming paradigms by aligning machine performance with human assessment targets.
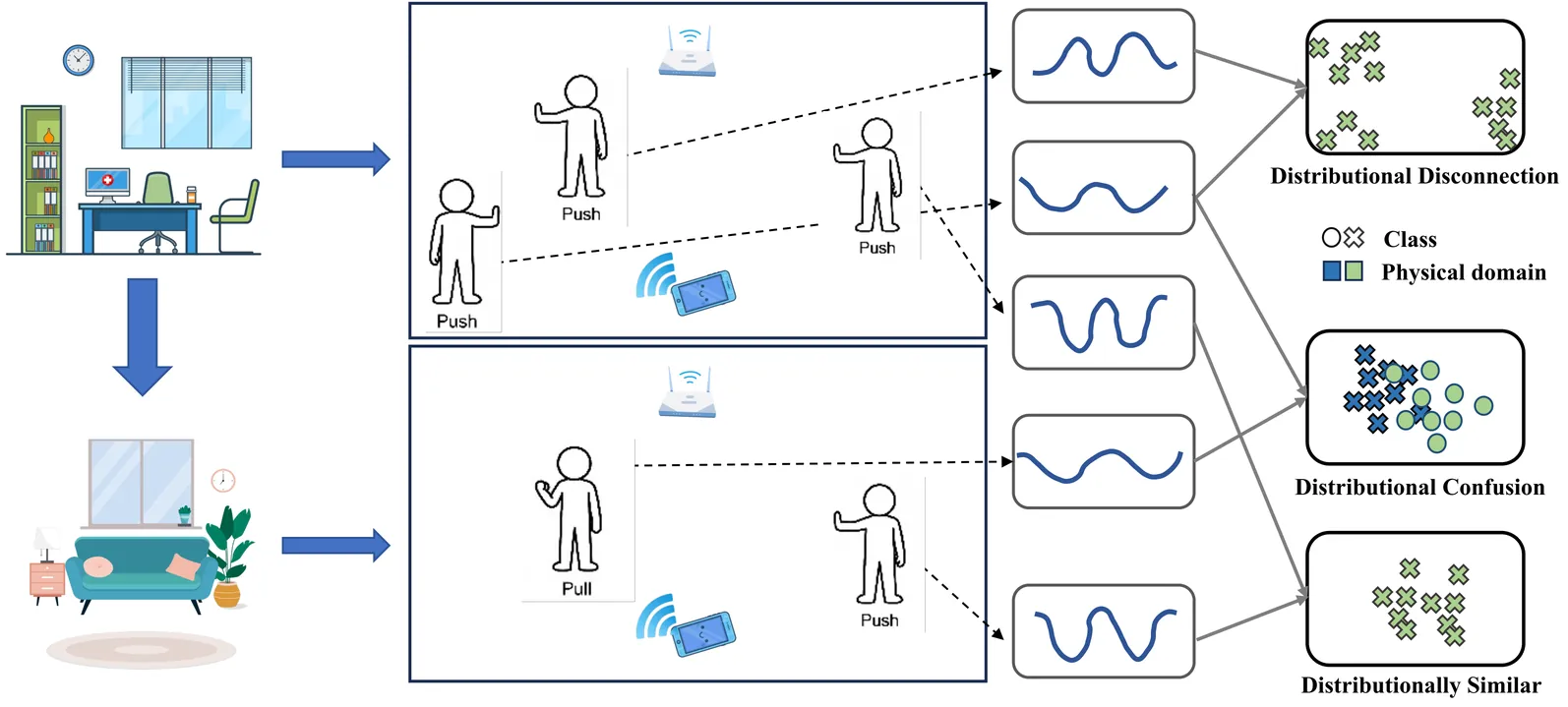
In this paper, we propose GesFi, a novel WiFi-based gesture recognition system that introduces WiFi latent domain mining to redefine domains directly from the data itself. GesFi first processes raw sensing data collected from WiFi receivers using CSI-ratio denoising, Short-Time Fast Fourier Transform, and visualization techniques to generate standardized input representations. It then employs class-wise adversarial learning to suppress gesture semantic and leverages unsupervised clustering to automatically uncover latent domain factors responsible for distributional shifts. These latent domains are then aligned through adversarial learning to support robust cross-domain generalization. Finally, the system is applied to the target environment for robust gesture inference. We deployed GesFi under both single-pair and multi-pair settings using commodity WiFi transceivers, and evaluated it across multiple public datasets and real-world environments. Compared to state-of-the-art baselines, GesFi achieves up to 78% and 50% performance improvements over existing adversarial methods, and consistently outperforms prior generalization approaches across most cross-domain tasks.
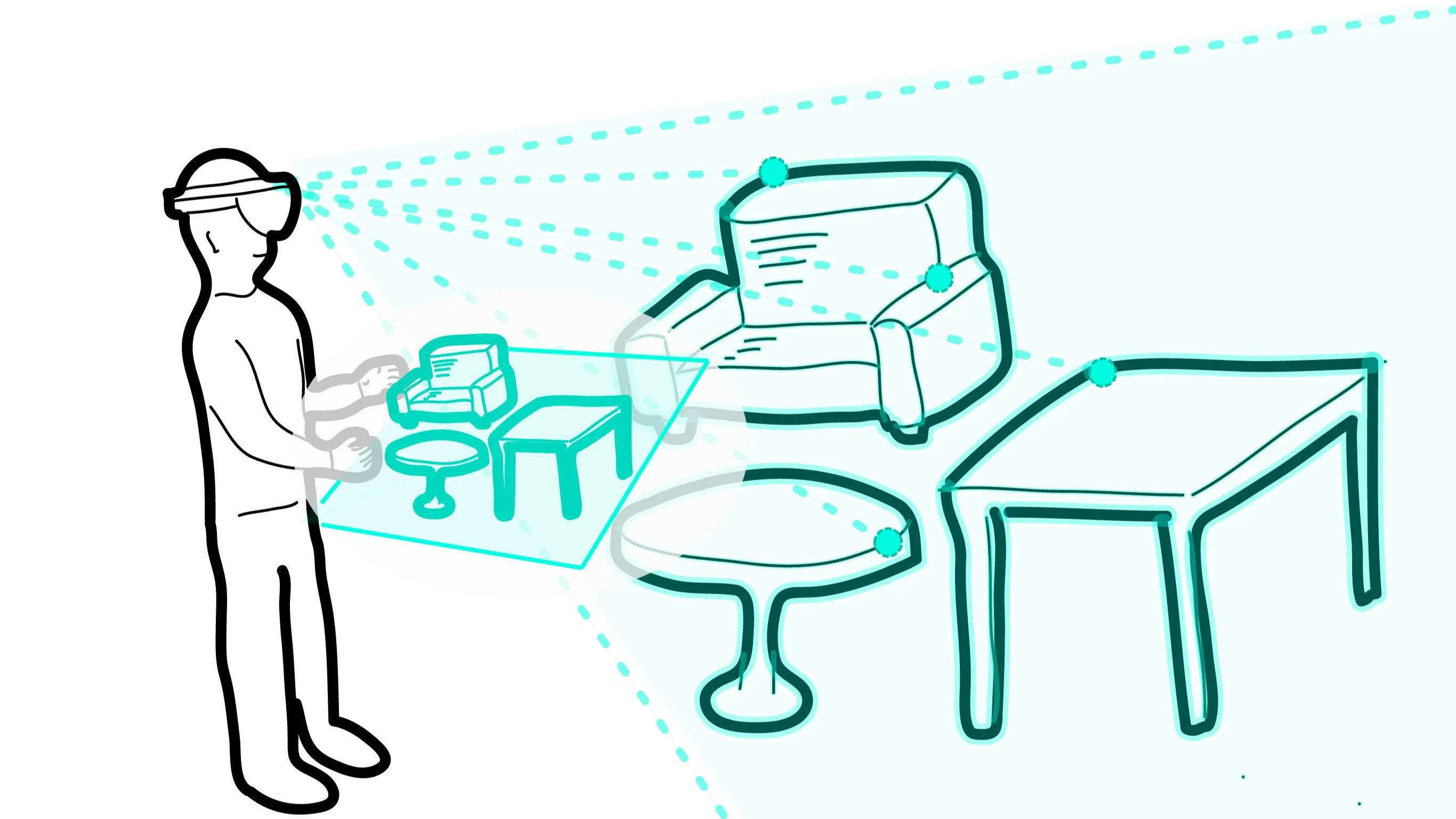
In augmented reality (AR), users can place virtual objects anywhere in a real-world room, called AR layout. Although several object manipulation techniques have been proposed in AR, it is difficult to use them for AR layout owing to the difficulty in freely changing the position and size of virtual objects. In this study, we make the World-in-Miniature (WIM) technique available in AR to support AR layout. The WIM technique is a manipulation technique that uses miniatures, which has been proposed as a manipulation technique for virtual reality (VR). Our system uses the AR device's depth sensors to acquire a mesh of the room in real-time to create and update a miniature of a room in real-time. In our system, users can use miniature objects to move virtual objects to arbitrary positions and scale them to arbitrary sizes. In addition, because the miniature object can be manipulated instead of the real-scale object, we assumed that our system will shorten the placement time and reduce the workload of the user. In our previous study, we created a prototype and investigated the properties of manipulating miniature objects in AR. In this study, we conducted an experiment to evaluate how our system can support AR layout. To conduct a task close to the actual use, we used various objects and made the participants design an AR layout of their own will. The results showed that our system significantly reduced workload in physical and temporal demand. Although, there was no significant difference in the total manipulation time.

Fulfilling social connections are crucial for human well-being and belonging, but not all relationships last forever. As interactions increasingly move online, the act of digitally severing a relationship - e.g. through blocking or unfriending - has become progressively more common as well. This study considers actions of "digital severance" through interviews with 30 participants with experience as the initiator and/or recipient of such situations. Through a critical interpretative lens, we explore how people perceive and interpret their severance experience and how the online setting of social media shapes these dynamics. We develop themes that position digital severance as being intertwined with power and control, and we highlight (im)balances between an individual's desires that can lead to feelings of disempowerment and ambiguous loss for both parties. We discuss the implications of our research, outlining three key tensions and four open questions regarding digital relationships, meaning-making, and design outcomes for future exploration.
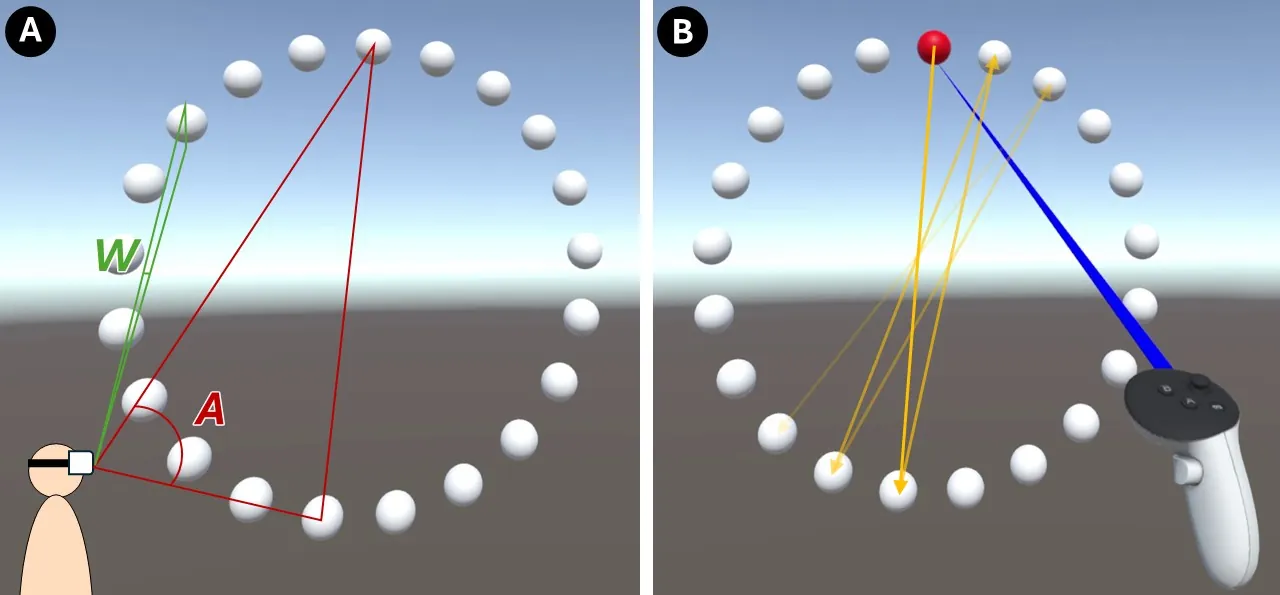
As XR devices become widespread, 3D interaction has become commonplace, and UI developers are increasingly required to consider usability to deliver better user experiences. The HCI community has long studied target-pointing performance, and research on 3D environments has progressed substantially. However, for practitioners to directly leverage research findings in UI improvements, practical tools are needed. To bridge this gap between research and development in VR systems, we propose a system that estimates object selection success rates within a development tool (Unity). In this paper, we validate the underlying theory, describe the tool's functions, and report feedback from VR developers who tried the tool to assess its usefulness.
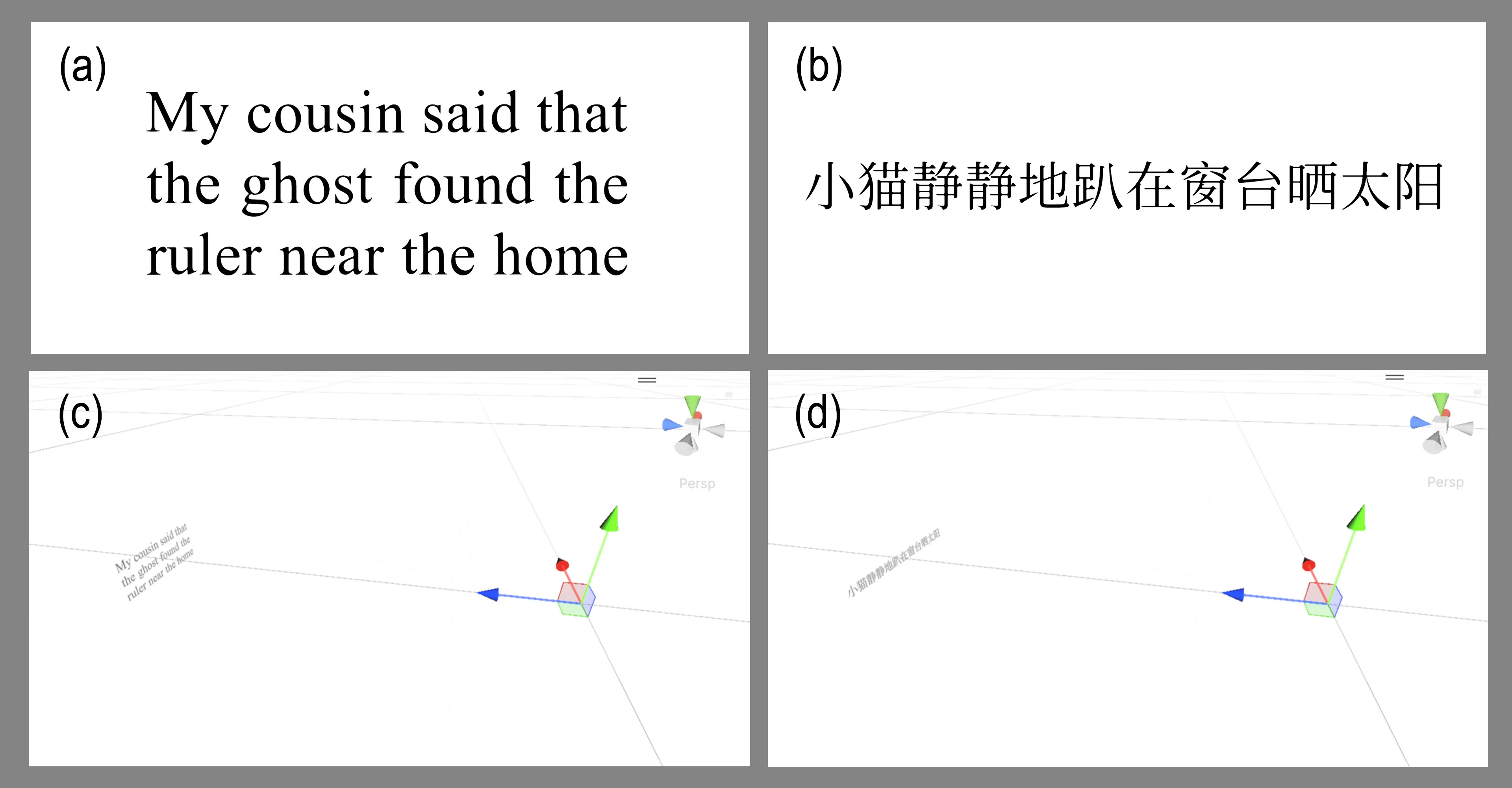
Extended reality (XR) is evolving into a general-purpose computing platform, yet its adoption for productivity is hindered by visual fatigue and simulator sickness. While these symptoms are often attributed to latency or motion conflicts, the precise impact of textual clarity on physiological comfort remains undefined. Here we show that sub-optimal effective resolution, the clarity that reaches the eye after the full display-optics-rendering pipeline, is a primary driver of simulator sickness during reading tasks in both virtual reality and video see-through environments. By systematically manipulating end-to-end effective resolution on a unified logMAR scale, we measured reading psychophysics and sickness symptoms in a controlled within-subjects study. We find that reading performance and user comfort degrade exponentially as resolution drops below 0 logMAR (normal visual acuity). Notably, our results reveal 0 logMAR as a key physiological tipping point: resolutions better than this threshold yield naked-eye-level performance with minimal sickness, whereas poorer resolutions trigger rapid, non-linear increases in nausea and oculomotor strain. These findings suggest that the cognitive and perceptual effort required to resolve blurry text directly compromises user comfort, establishing human-eye resolution as a critical baseline for the design of future ergonomic XR systems.
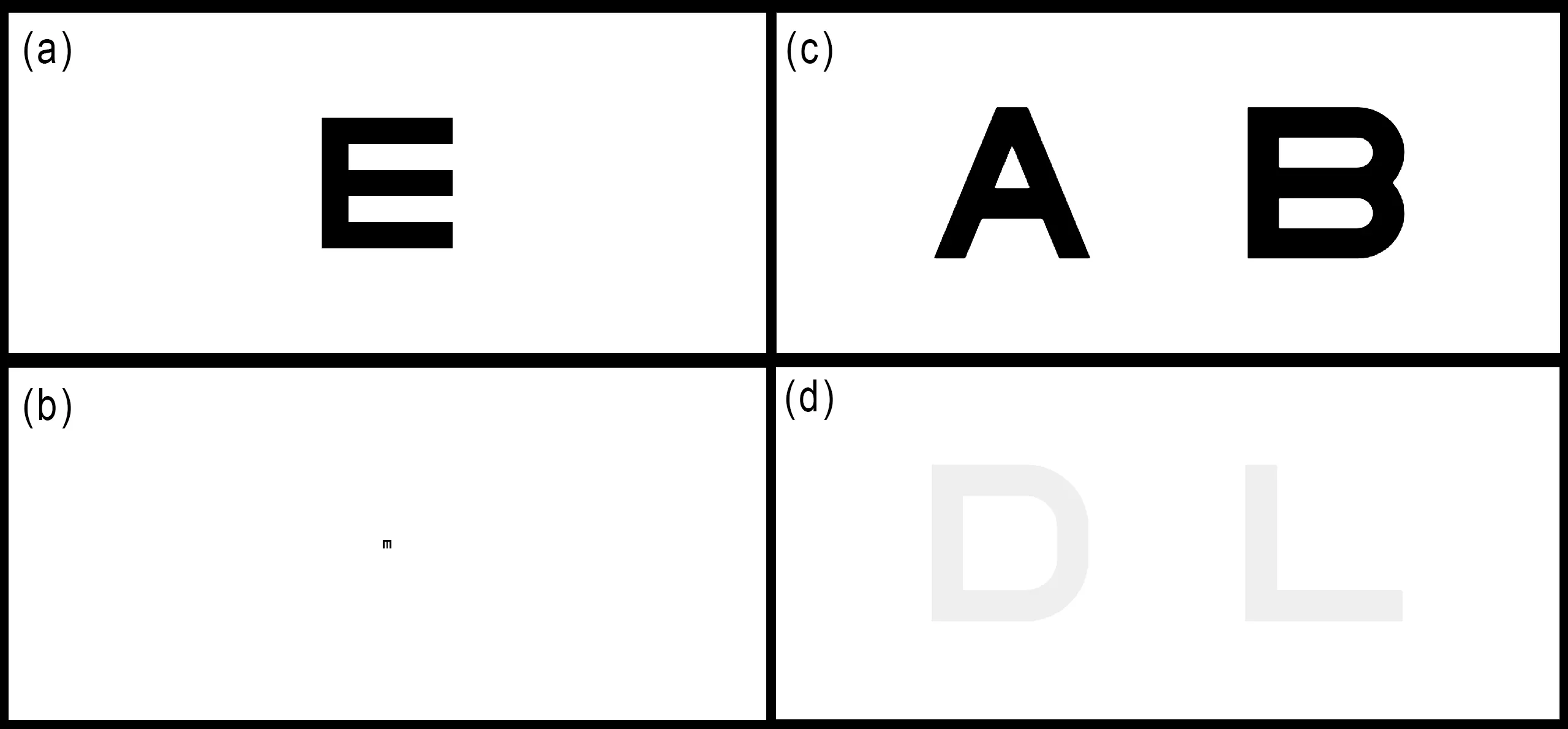
Video see-through (VST) technology aims to seamlessly blend virtual and physical worlds by reconstructing reality through cameras. While manufacturers promise perceptual fidelity, it remains unclear how close these systems are to replicating natural human vision across varying environmental conditions. In this work, we quantify the perceptual gap between the human eye and different popular VST headsets (Apple Vision Pro, Meta Quest 3, Quest Pro) using psychophysical measures of visual acuity, contrast sensitivity, and color vision. We show that despite hardware advancements, all tested VST systems fail to match the dynamic range and adaptability of the naked eye. While high-end devices approach human performance in ideal lighting, they exhibit significant degradation in low-light conditions, particularly in contrast sensitivity and acuity. Our results map the physiological limitations of digital reality reconstruction, establishing a specific perceptual gap that defines the roadmap for achieving indistinguishable VST experiences.
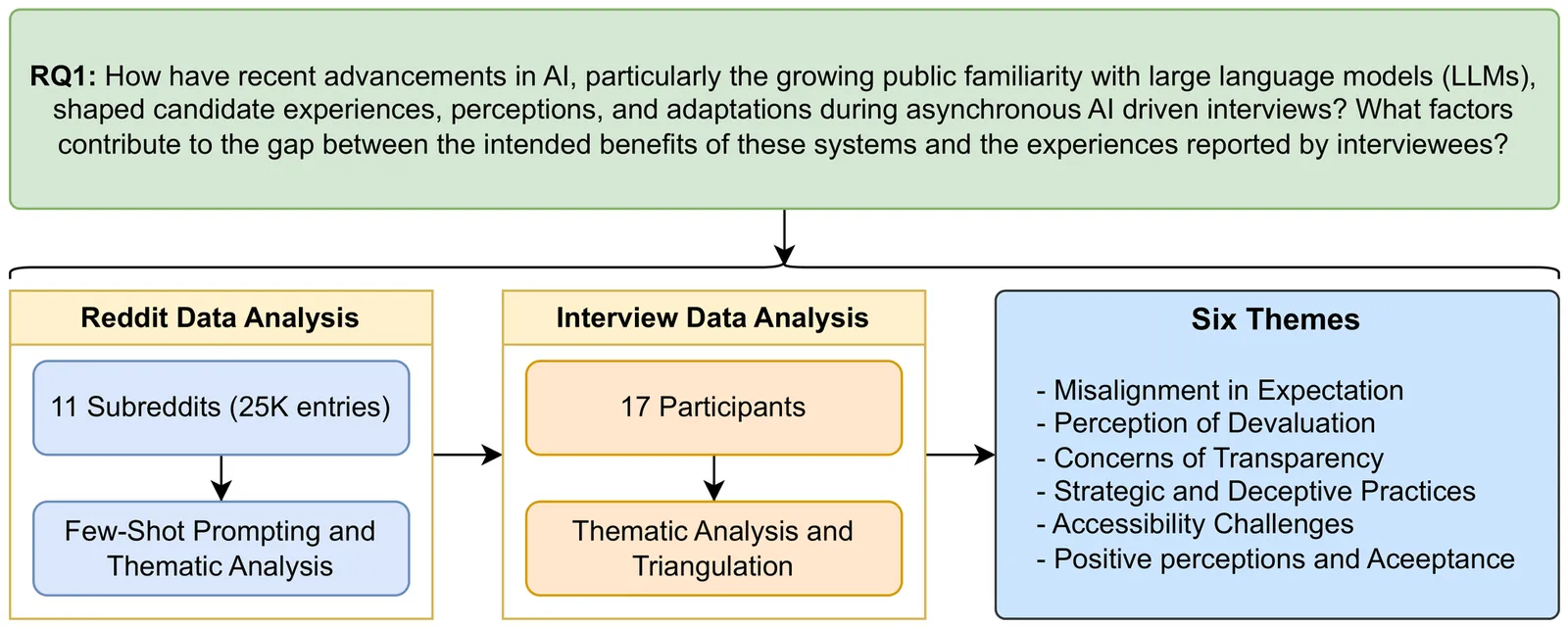
Automated interviewing tools are now widely adopted to manage recruitment at scale, often replacing early human screening with algorithmic assessments. While these systems are promoted as efficient and consistent, they also generate new forms of uncertainty for applicants. Efforts to soften these experiences through human-like design features have only partially addressed underlying concerns. To understand how candidates interpret and cope with such systems, we conducted a mixed empirical investigation that combined analysis of online discussions, responses from more than one hundred and fifty survey participants, and follow-up conversations with seventeen interviewees. The findings point to several recurring problems, including unclear evaluation criteria, limited organizational responsibility for automated outcomes, and a lack of practical support for preparation. Many participants described the technology as far less advanced than advertised, leading them to infer how decisions might be made in the absence of guidance. This speculation often intensified stress and emotional strain. Furthermore, the minimal sense of interpersonal engagement contributed to feelings of detachment and disposability. Based on these observations, we propose design directions aimed at improving clarity, accountability, and candidate support in AI-mediated hiring processes.

Autonomous vehicles (AVs) are rapidly advancing and are expected to play a central role in future mobility. Ensuring their safe deployment requires reliable interaction with other road users, not least pedestrians. Direct testing on public roads is costly and unsafe for rare but critical interactions, making simulation a practical alternative. Within simulation-based testing, adversarial scenarios are widely used to probe safety limits, but many prioritise difficulty over realism, producing exaggerated behaviours which may result in AV controllers that are overly conservative. We propose an alternative method, instead using a cognitively inspired pedestrian model featuring both inter-individual and intra-individual variability to generate behaviourally plausible adversarial scenarios. We provide a proof of concept demonstration of this method's potential for AV control optimisation, in closed-loop testing and tuning of an AV controller. Our results show that replacing the rule-based CARLA pedestrian with the human-like model yields more realistic gap acceptance patterns and smoother vehicle decelerations. Unsafe interactions occur only for certain pedestrian individuals and conditions, underscoring the importance of human variability in AV testing. Adversarial scenarios generated by this model can be used to optimise AV control towards safer and more efficient behaviour. Overall, this work illustrates how incorporating human-like road user models into simulation-based adversarial testing can enhance the credibility of AV evaluation and provide a practical basis to behaviourally informed controller optimisation.
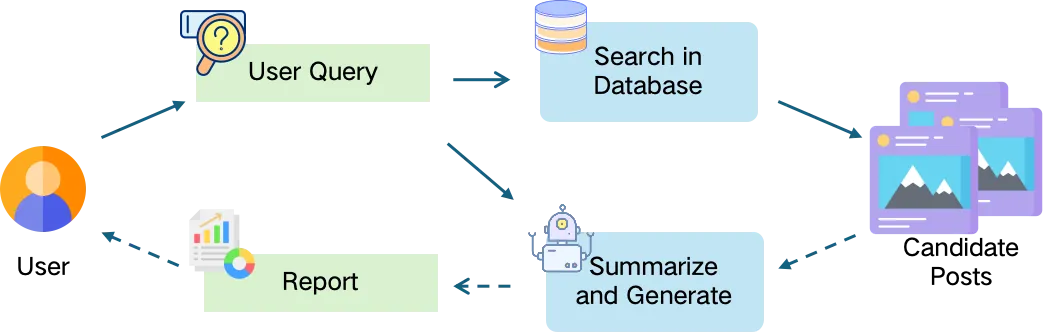
Social cues, which convey others' presence, behaviors, or identities, play a crucial role in human information seeking by helping individuals judge relevance and trustworthiness. However, existing LLM-based search systems primarily rely on semantic features, creating a misalignment with the socialized cognition underlying natural information seeking. To address this gap, we explore how the integration of social cues into LLM-based search influences users' perceptions, experiences, and behaviors. Focusing on social media platforms that are beginning to adopt LLM-based search, we integrate design workshops, the implementation of the prototype system (SoulSeek), a between-subjects study, and mixed-method analyses to examine both outcome- and process-level findings. The workshop informs the prototype's cue-integrated design. The study shows that social cues improve perceived outcomes and experiences, promote reflective information behaviors, and reveal limits of current LLM-based search. We propose design implications emphasizing better social-knowledge understanding, personalized cue settings, and controllable interactions.
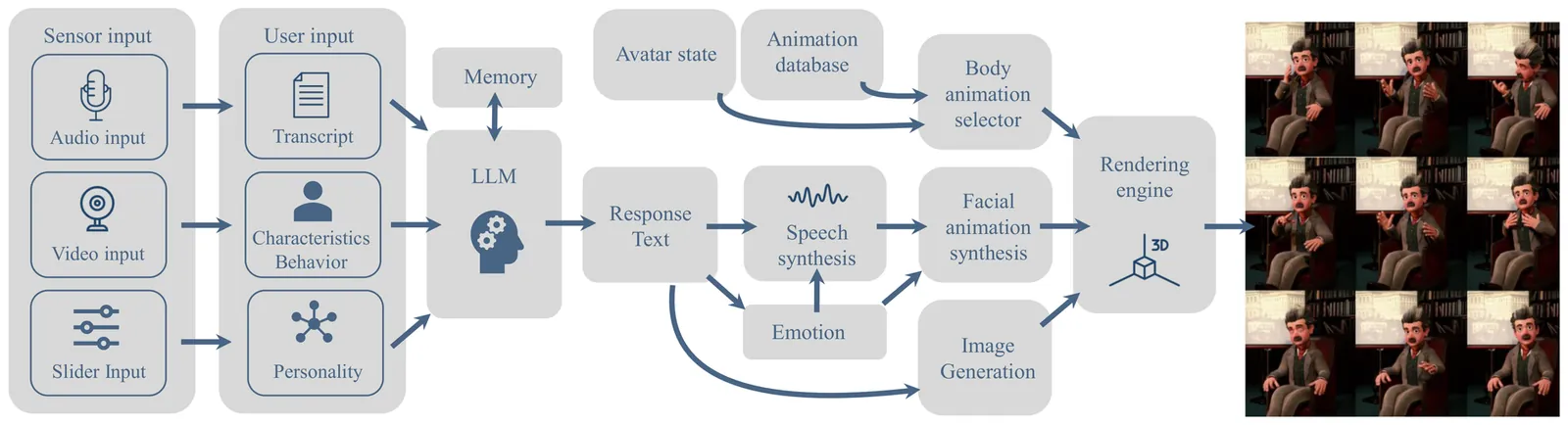
From movie characters to modern science fiction - bringing characters into interactive, story-driven conversations has captured imaginations across generations. Achieving this vision is highly challenging and requires much more than just language modeling. It involves numerous complex AI challenges, such as conversational AI, maintaining character integrity, managing personality and emotions, handling knowledge and memory, synthesizing voice, generating animations, enabling real-world interactions, and integration with physical environments. Recent advancements in the development of foundation models, prompt engineering, and fine-tuning for downstream tasks have enabled researchers to address these individual challenges. However, combining these technologies for interactive characters remains an open problem. We present a system and platform for conveniently designing believable digital characters, enabling a conversational and story-driven experience while providing solutions to all of the technical challenges. As a proof-of-concept, we introduce Digital Einstein, which allows users to engage in conversations with a digital representation of Albert Einstein about his life, research, and persona. While Digital Einstein exemplifies our methods for a specific character, our system is flexible and generalizes to any story-driven or conversational character. By unifying these diverse AI components into a single, easy-to-adapt platform, our work paves the way for immersive character experiences, turning the dream of lifelike, story-based interactions into a reality.
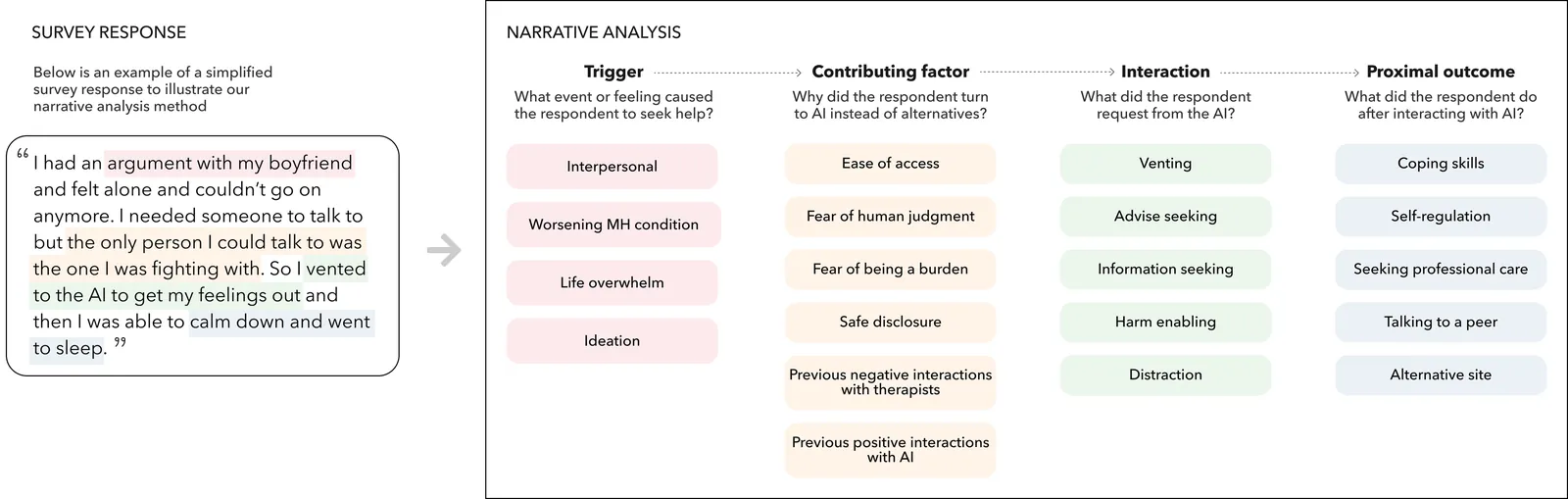
Online, people often recount their experiences turning to conversational AI agents (e.g., ChatGPT, Claude, Copilot) for mental health support -- going so far as to replace their therapists. These anecdotes suggest that AI agents have great potential to offer accessible mental health support. However, it's unclear how to meet this potential in extreme mental health crisis use cases. In this work, we explore the first-person experience of turning to a conversational AI agent in a mental health crisis. From a testimonial survey (n = 53) of lived experiences, we find that people use AI agents to fill the in-between spaces of human support; they turn to AI due to lack of access to mental health professionals or fears of burdening others. At the same time, our interviews with mental health experts (n = 16) suggest that human-human connection is an essential positive action when managing a mental health crisis. Using the stages of change model, our results suggest that a responsible AI crisis intervention is one that increases the user's preparedness to take a positive action while de-escalating any intended negative action. We discuss the implications of designing conversational AI agents as bridges towards human-human connection rather than ends in themselves.