Theory & Algorithms
Computational complexity, data structures, algorithms, and game theory
Computational complexity, data structures, algorithms, and game theory
This is a brief description of a project that has already autoformalized a large portion of the general topology from the Munkres textbook (which has in total 241 pages in 7 chapters and 39 sections). The project has been running since November 21, 2025 and has as of January 4, 2026, produced 160k lines of formalized topology. Most of it (about 130k lines) have been done in two weeks,from December 22 to January 4, for an LLM subscription cost of about \$100. This includes a 3k-line proof of Urysohn's lemma, a 2k-line proof of Urysohn's Metrization theorem, over 10k-line proof of the Tietze extension theorem, and many more (in total over 1.5k lemmas/theorems). The approach is quite simple and cheap: build a long-running feedback loop between an LLM and a reasonably fast proof checker equipped with a core foundational library. The LLM is now instantiated as ChatGPT (mostly 5.2) or Claude Sonnet (4.5) run through the respective Codex or Claude Code command line interfaces. The proof checker is Chad Brown's higher-order set theory system Megalodon, and the core library is Brown's formalization of basic set theory and surreal numbers (including reals, etc). The rest is some prompt engineering and technical choices which we describe here. Based on the fast progress, low cost, virtually unknown ITP/library, and the simple setup available to everyone, we believe that (auto)formalization may become quite easy and ubiquitous in 2026, regardless of which proof assistant is used.

In this paper, we address the complexity barrier inherent in Fourier-Motzkin elimination (FME) and cylindrical algebraic decomposition (CAD) when eliminating a block of (existential) quantifiers. To mitigate this, we propose exploiting structural sparsity in the variable dependency graph of quantified formulas. Utilizing tools from parameterized algorithms, we investigate the role of treewidth, a parameter that measures the graph's tree-likeness, in the process of quantifier elimination. A novel dynamic programming framework, structured over a tree decomposition of the dependency graph, is developed for applying FME and CAD, and is also extensible to general quantifier elimination procedures. Crucially, we prove that when the treewidth is a constant, the framework achieves a significant exponential complexity improvement for both FME and CAD, reducing the worst-case complexity bound from doubly exponential to single exponential. Preliminary experiments on sparse linear real arithmetic (LRA) and nonlinear real arithmetic (NRA) benchmarks confirm that our algorithm outperforms the existing popular heuristic-based approaches on instances exhibiting low treewidth.
In multi-agent tasks, the central challenge lies in the dynamic adaptation of strategies. However, directly conditioning on opponents' strategies is intractable in the prevalent deep reinforcement learning paradigm due to a fundamental ``representational bottleneck'': neural policies are opaque, high-dimensional parameter vectors that are incomprehensible to other agents. In this work, we propose a paradigm shift that bridges this gap by representing policies as human-interpretable source code and utilizing Large Language Models (LLMs) as approximate interpreters. This programmatic representation allows us to operationalize the game-theoretic concept of \textit{Program Equilibrium}. We reformulate the learning problem by utilizing LLMs to perform optimization directly in the space of programmatic policies. The LLM functions as a point-wise best-response operator that iteratively synthesizes and refines the ego agent's policy code to respond to the opponent's strategy. We formalize this process as \textit{Programmatic Iterated Best Response (PIBR)}, an algorithm where the policy code is optimized by textual gradients, using structured feedback derived from game utility and runtime unit tests. We demonstrate that this approach effectively solves several standard coordination matrix games and a cooperative Level-Based Foraging environment.
We present a \emph{deterministic exact algorithm} for the \emph{minimum $k$-cut problem} on simple graphs. Our approach combines the \emph{principal sequence of partitions (PSP)}, derived canonically from ideal loads, with a single level of \emph{Kawarabayashi--Thorup (KT)} contractions at the critical PSP threshold~$λ_j$. Let $j$ be the smallest index with $κ(P_j)\ge k$ and $R := k - κ(P_{j-1})$. We prove a structural decomposition theorem showing that an optimal $k$-cut can be expressed as the level-$(j\!-\!1)$ boundary $A_{\le j-1}$ together with exactly $(R-r)$ \emph{non-trivial} internal cuts of value at most~$λ_j$ and $r$ \emph{singleton isolations} (``islands'') inside the parts of~$P_{j-1}$. At this level, KT contractions yield kernels of total size $\widetilde{O}(n / λ_j)$, and from them we build a \emph{canonical border family}~$\mathcal{B}$ of the same order that deterministically covers all optimal refinement choices. Branching only over~$\mathcal{B}$ (and also including an explicit ``island'' branch) gives total running time $$ T(n,m,k) = \widetilde{O}\left(\mathrm{poly}(m)+\Bigl(\tfrac{n}{λ_j}+n^{ω/3}\Bigr)^{R}\right), $$ where $ω< 2.373$ is the matrix multiplication exponent. In particular, if $λ_j \ge n^{\varepsilon}$ for some constant $\varepsilon > 0$, we obtain a \emph{deterministic sub-$n^k$-time algorithm}, running in $n^{(1-\varepsilon)(k-1)+o(k)}$ time. Finally, combining our PSP$\times$KT framework with a small-$λ$ exact subroutine via a simple meta-reduction yields a deterministic $n^{c k+O(1)}$ algorithm for $c = \max\{ t/(t+1), ω/3 \} < 1$, aligning with the exponent in the randomized bound of He--Li (STOC~2022) under the assumed subroutine.
We study "space efficient" FPT algorithms for graph problems with limited memory. Let n be the size of the input graph and k be the parameter. We present algorithms that run in time f(k)*poly(n) and use g(k)*polylog(n) working space, where f and g are functions of k alone, for k-Path, MaxLeaf SubTree and Multicut in Trees. These algorithms are motivated by big-data settings where very large problem instances must be solved, and using poly(n) memory is prohibitively expensive. They are also theoretically interesting, since most of the standard methods tools, such as deleting a large set of vertices or edges, are unavailable, and we must a develop different way to tackle them.

The reachability problem in multi-pushdown automata (MPDA) has many applications in static analysis of recursive programs. An example is safety verification of multi-threaded recursive programs with shared memory. Since these problems are undecidable, the literature contains many decidable (and efficient) underapproximations of MPDA. A uniform framework that captures many of these underapproximations is that of bounded treewidth (tw): To each execution of the MPDA, we associate a graph; then we consider the subset of all graphs that have a wt at most $k$, for some constant $k$. In fact, bounding tw is a generic approach to obtain classes of systems with decidable reachability, even beyond MPDA underapproximations. The resulting systems are also called MSO-definable bounded-tw systems. While bounded tw is a powerful tool for reachability and similar types of analysis, the word languages (i.e. action sequences corresponding to executions) of these systems remain far from understood. For the slight restriction of bounded special tw, or "bounded-stw" (which is equivalent to bounded tw on MPDA, and even includes all bounded-tw systems studied in the literature), this work reveals a connection with multiple context-free languages (MCFL), a concept from computational linguistics. We show that the word languages of MSO-definable bounded-stw systems are exactly the MCFL. We exploit this connection to provide an optimal algorithm for computing downward closures (dcl) for MSO-definable bounded-stw systems. Computing dcl is a notoriously difficult task that has many applications in the verification of complex systems: As an example application, we show that in programs with dynamic spawning of MSO-definable bounded-stw processes, safety verification has the same complexity as in the case of processes with sequential recursive processes.
Several recent works [DHLNSY25, CPPS25a, CPPS25b] have studied a model of property testing of Boolean functions under a \emph{relative-error} criterion. In this model, the distance from a target function $f: \{0,1\}^n \to \{0,1\}$ that is being tested to a function $g$ is defined relative to the number of inputs $x$ for which $f(x)=1$; moreover, testing algorithms in this model have access both to a black-box oracle for $f$ and to independent uniform satisfying assignments of $f$. The motivation for this model is that it provides a natural framework for testing \emph{sparse} Boolean functions that have few satisfying assignments, analogous to well-studied models for property testing of sparse graphs. The main result of this paper is a lower bound for testing \emph{halfspaces} (i.e., linear threshold functions) in the relative error model: we show that $\tildeΩ(\log n)$ oracle calls are required for any relative-error halfspace testing algorithm over the Boolean hypercube $\{0,1\}^n$. This stands in sharp contrast both with the constant-query testability (independent of $n$) of halfspaces in the standard model [MORS10], and with the positive results for relative-error testing of many other classes given in [DHLNSY25, CPPS25a, CPPS25b]. Our lower bound for halfspaces gives the first example of a well-studied class of functions for which relative-error testing is provably more difficult than standard-model testing.
With the rapid advancement of generative AI (GenAI), mechanism design adapted to its unique characteristics poses new theoretical and practical challenges. Unlike traditional goods, content from one domain can enhance the training and performance of GenAI models in other domains. For example, OpenAI's video generation model Sora (Liu et al., 2024b) relies heavily on image data to improve video generation quality. In this work, we study nonlinear procurement mechanism design under data transferability, where online platforms employ both human creators and GenAI to satisfy cross-domain content demand. We propose optimal mechanisms that maximize either platform revenue or social welfare and identify the specific properties of GenAI that make such high-dimensional design problems tractable. Our analysis further reveals which domains face stronger competitive pressure and which tend to experience overproduction. Moreover, the growing role of data intermediaries, including labeling companies such as Scale AI and creator organizations such as The Wall Street Journal, introduces a third layer into the traditional platform-creator structure. We show that this three-layer market can result in a lose-lose outcome, reducing both platform revenue and social welfare, as large pre-signed contracts distort creators' incentives and lead to inefficiencies in the data market. These findings suggest a need for government regulation of the GenAI data ecosystem, and our theoretical insights are further supported by numerical simulations.
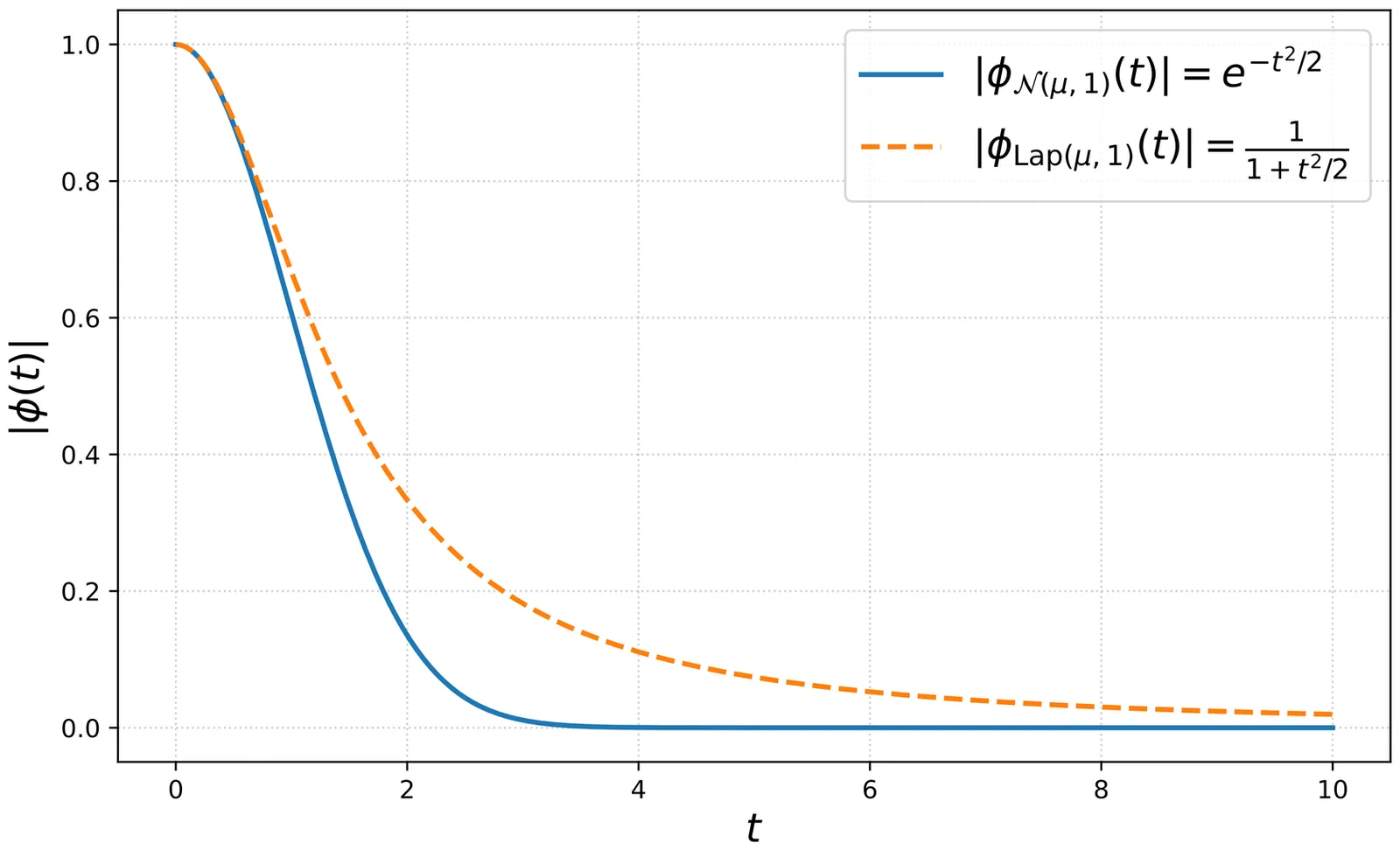
In this work, we give a ${\rm poly}(d,k)$ time and sample algorithm for efficiently learning the parameters of a mixture of $k$ spherical distributions in $d$ dimensions. Unlike all previous methods, our techniques apply to heavy-tailed distributions and include examples that do not even have finite covariances. Our method succeeds whenever the cluster distributions have a characteristic function with sufficiently heavy tails. Such distributions include the Laplace distribution but crucially exclude Gaussians. All previous methods for learning mixture models relied implicitly or explicitly on the low-degree moments. Even for the case of Laplace distributions, we prove that any such algorithm must use super-polynomially many samples. Our method thus adds to the short list of techniques that bypass the limitations of the method of moments. Somewhat surprisingly, our algorithm does not require any minimum separation between the cluster means. This is in stark contrast to spherical Gaussian mixtures where a minimum $\ell_2$-separation is provably necessary even information-theoretically [Regev and Vijayaraghavan '17]. Our methods compose well with existing techniques and allow obtaining ''best of both worlds" guarantees for mixtures where every component either has a heavy-tailed characteristic function or has a sub-Gaussian tail with a light-tailed characteristic function. Our algorithm is based on a new approach to learning mixture models via efficient high-dimensional sparse Fourier transforms. We believe that this method will find more applications to statistical estimation. As an example, we give an algorithm for consistent robust mean estimation against noise-oblivious adversaries, a model practically motivated by the literature on multiple hypothesis testing. It was formally proposed in a recent Master's thesis by one of the authors, and has already inspired follow-up works.
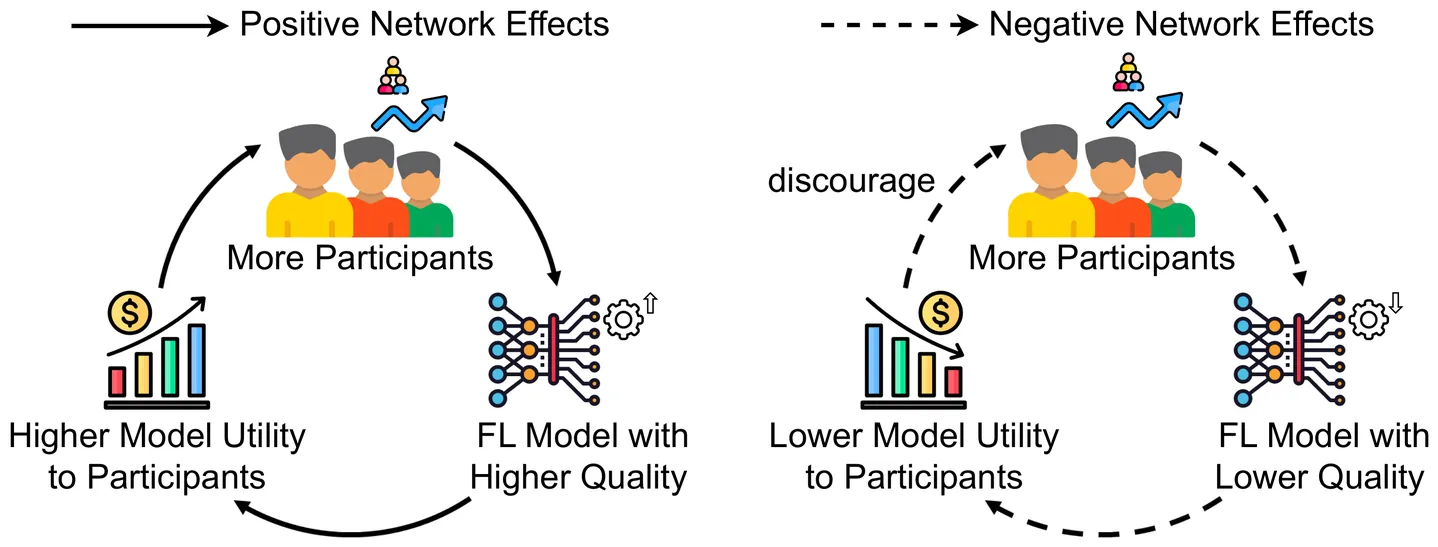
Mechanism design is pivotal to federated learning (FL) for maximizing social welfare by coordinating self-interested clients. Existing mechanisms, however, often overlook the network effects of client participation and the diverse model performance requirements (i.e., generalization error) across applications, leading to suboptimal incentives and social welfare, or even inapplicability in real deployments. To address this gap, we explore incentive mechanism design for FL with network effects and application-specific requirements of model performance. We develop a theoretical model to quantify the impact of network effects on heterogeneous client participation, revealing the non-monotonic nature of such effects. Based on these insights, we propose a Model Trading and Sharing (MoTS) framework, which enables clients to obtain FL models through either participation or purchase. To further address clients' strategic behaviors, we design a Social Welfare maximization with Application-aware and Network effects (SWAN) mechanism, exploiting model customer payments for incentivization. Experimental results on a hardware prototype demonstrate that our SWAN mechanism outperforms existing FL mechanisms, improving social welfare by up to $352.42\%$ and reducing extra incentive costs by $93.07\%$.

A Multinomial Logit (MNL) model is composed of a finite universe of items $[n]=\{1,..., n\}$, each assigned a positive weight. A query specifies an admissible subset -- called a slate -- and the model chooses one item from that slate with probability proportional to its weight. This query model is also known as the Plackett-Luce model or conditional sampling oracle in the literature. Although MNLs have been studied extensively, a basic computational question remains open: given query access to slates, how efficiently can we learn weights so that, for every slate, the induced choice distribution is within total variation distance $\varepsilon$ of the ground truth? This question is central to MNL learning and has direct implications for modern recommender system interfaces. We provide two algorithms for this task, one with adaptive queries and one with non-adaptive queries. Each algorithm outputs an MNL $M'$ that induces, for each slate $S$, a distribution $M'_S$ on $S$ that is within $\varepsilon$ total variation distance of the true distribution. Our adaptive algorithm makes $O\left(\frac{n}{\varepsilon^{3}}\log n\right)$ queries, while our non-adaptive algorithm makes $O\left(\frac{n^{2}}{\varepsilon^{3}}\log n \log\frac{n}{\varepsilon}\right)$ queries. Both algorithms query only slates of size two and run in time proportional to their query complexity. We complement these upper bounds with lower bounds of $Ω\left(\frac{n}{\varepsilon^{2}}\log n\right)$ for adaptive queries and $Ω\left(\frac{n^{2}}{\varepsilon^{2}}\log n\right)$ for non-adaptive queries, thus proving that our adaptive algorithm is optimal in its dependence on the support size $n$, while the non-adaptive one is tight within a $\log n$ factor.
Given a planar graph, a subset of its vertices called terminals, and $k \in \mathbb{N}$, the Face Cover Number problem asks whether the terminals lie on the boundaries of at most $k$ faces of some embedding of the input graph. When a plane graph is given in the input, the problem is known to have a polynomial kernel~\cite{GarneroST17}. In this paper, we present the first polynomial kernel for Face Cover Number when the input is a planar graph (without a fixed embedding). Our approach overcomes the challenge of not having a predefined set of face boundaries by building a kernel bottom-up on an SPR-tree while preserving the essential properties of the face cover along the way.

To achieve fast recovery from link failures, most modern communication networks feature fully decentralized fast re-routing mechanisms. These re-routing mechanisms rely on pre-installed static re-routing rules at the nodes (the routers), which depend only on local failure information, namely on the failed links incident to the node. Ideally, a network is perfectly resilient: the re-routing rules ensure that packets are always successfully routed to their destinations as long as the source and the destination are still physically connected in the underlying network after the failures. Unfortunately, there are examples where achieving perfect resilience is not possible. Surprisingly, only very little is known about the algorithmic aspect of when and how perfect resilience can be achieved. We investigate the computational complexity of analyzing such local fast re-routing mechanisms. Our main result is a negative one: we show that even checking whether a given set of static re-routing rules ensures perfect resilience is coNP-complete. We also show coNP-completeness of the so-called ideal resilience, a weaker notion of resilience often considered in the literature. Additionally, we investigate other fundamental variations of the problem. In particular, we show that our coNP-completeness proof also applies to scenarios where the re-routing rules have specific patterns (known as skipping in the literature). On the positive side, for scenarios where nodes do not have information about the link from which a packet arrived (the so-called in-port), we present linear-time algorithms for both the verification and synthesis problem for perfect resilience.

In Bayesian single-item auctions, a monotone bidding strategy--one that prescribes a higher bid for a higher value type--can be equivalently represented as a partition of the quantile space into consecutive intervals corresponding to increasing bids. Kumar et al. (2024) prove that agile online gradient descent (OGD), when used to update a monotone bidding strategy through its quantile representation, is strategically robust in repeated first-price auctions: when all bidders employ agile OGD in this way, the auctioneer's average revenue per round is at most the revenue of Myerson's optimal auction, regardless of how she adjusts the reserve price over time. In this work, we show that this strategic robustness guarantee is not unique to agile OGD or to the first-price auction: any no-regret learning algorithm, when fed gradient feedback with respect to the quantile representation, is strategically robust, even if the auction format changes every round, provided the format satisfies allocation monotonicity and voluntary participation. In particular, the multiplicative weights update (MWU) algorithm simultaneously achieves the optimal regret guarantee and the best-known strategic robustness guarantee. At a technical level, our results are established via a simple relation that bridges Myerson's auction theory and standard no-regret learning theory. This showcases the potential of translating standard regret guarantees into strategic robustness guarantees for specific games, without explicitly minimizing any form of swap regret.
LPTP (Logic Program Theorem Prover) is an interactive natural-deduction-based theorem prover for pure Prolog programs with negation as failure, unification with the occurs check, and a restricted but extensible set of built-in predicates. With LPTP, one can formally prove termination and partial correctness of such Prolog programs. LPTP was designed in the mid-1990's by Robert F. Staerk. It is written in ISO-Prolog and comes with an Emacs user-interface. From a theoretical point of view, in his publications about LPTP, Staerk associates a set of first-order axioms IND(P) to the considered Prolog program P. IND(P) contains the Clark's equality theory for P, definitions of success, failure and termination for each user-defined logic procedure in P, axioms relating these three points of view, and an axiom schema for proving inductive properties. LPTP is thus a dedicated proof editor where these axioms are hard-wired. We propose to translate these axioms as first-order formulas (FOFs), and apply automated theorem provers to check the property of interest. Using FOF as an intermediary language, we experiment the use of automated theorem provers for Prolog program verification. We evaluate the approach over a benchmark of about 400 properties of Prolog programs from the library available with LPTP. Both the compiler which generates a set of FOF files from a given input Prolog program together with its properties and the benchmark are publicly available.

We present automated theorem provers for the first-order logic of here and there (HT). They are based on a native sequent calculus for the logic of HT and an axiomatic embedding of the logic of HT into intuitionistic logic. The analytic proof search in the sequent calculus is optimized by using free variables and skolemization. The embedding is used in combination with sequent, tableau and connection calculi for intuitionistic first-order logic. All provers are evaluated on a large benchmark set of first-order formulas, providing a foundation for the development of more efficient HT provers.

The logical semantics of normal logic programs has traditionally been based on the notions of Clark's completion and two-valued or three-valued canonical models, including supported, stable, regular, and well-founded models. Two-valued interpretations can also be seen as states evolving under a program's update operator, producing a transition graph whose fixed points and cycles capture stable and oscillatory behaviors, respectively. We refer to this view as dynamical semantics since it characterizes the program's meaning in terms of state-space trajectories, as first introduced in the stable (supported) class semantics. Recently, we have established a formal connection between Datalog^\neg programs (i.e., normal logic programs without function symbols) and Boolean networks, leading to the introduction of the trap space concept for Datalog^\neg programs. In this paper, we generalize the trap space concept to arbitrary normal logic programs, introducing trap space semantics as a new approach to their interpretation. This new semantics admits both model-theoretic and dynamical characterizations, providing a comprehensive approach to understanding program behavior. We establish the foundational properties of the trap space semantics and systematically relate it to the established model-theoretic semantics, including the stable (supported), stable (supported) partial, regular, and L-stable model semantics, as well as to the dynamical stable (supported) class semantics. Our results demonstrate that the trap space semantics offers a unified and precise framework for proving the existence of supported classes, strict stable (supported) classes, and regular models, in addition to uncovering and formalizing deeper relationships among the existing semantics of normal logic programs.
DatalogMTL with negation is an extension of Datalog with metric temporal operators enriched with unstratifiable negation. In this paper, we define the stable, well-founded, Kripke-Kleene, and supported model semantics for DatalogMTL with negation in a very simple and straightforward way, by using the solid mathematical formalism of Approximation Fixpoint Theory (AFT). Moreover, we prove that the stable model semantics obtained via AFT coincides with the one defined in previous work, through the employment of pairs of interpretations stemming from the logic of here-and-there.
A $k$-connectivity oracle for a graph $G=(V,E)$ is a data structure that given $s,t \in V$ determines whether there are at least $k+1$ internally disjoint $st$-paths in $G$. For undirected graphs, Pettie, Saranurak & Yin [STOC 2022, pp. 151-161] proved that any $k$-connectivity oracle requires $Ω(kn)$ bits of space. They asked whether $Ω(kn)$ bits are still necessary if $G$ is $k$-connected. We will show by a very simple proof that this is so even if $G$ is $k$-connected, answering this open question.
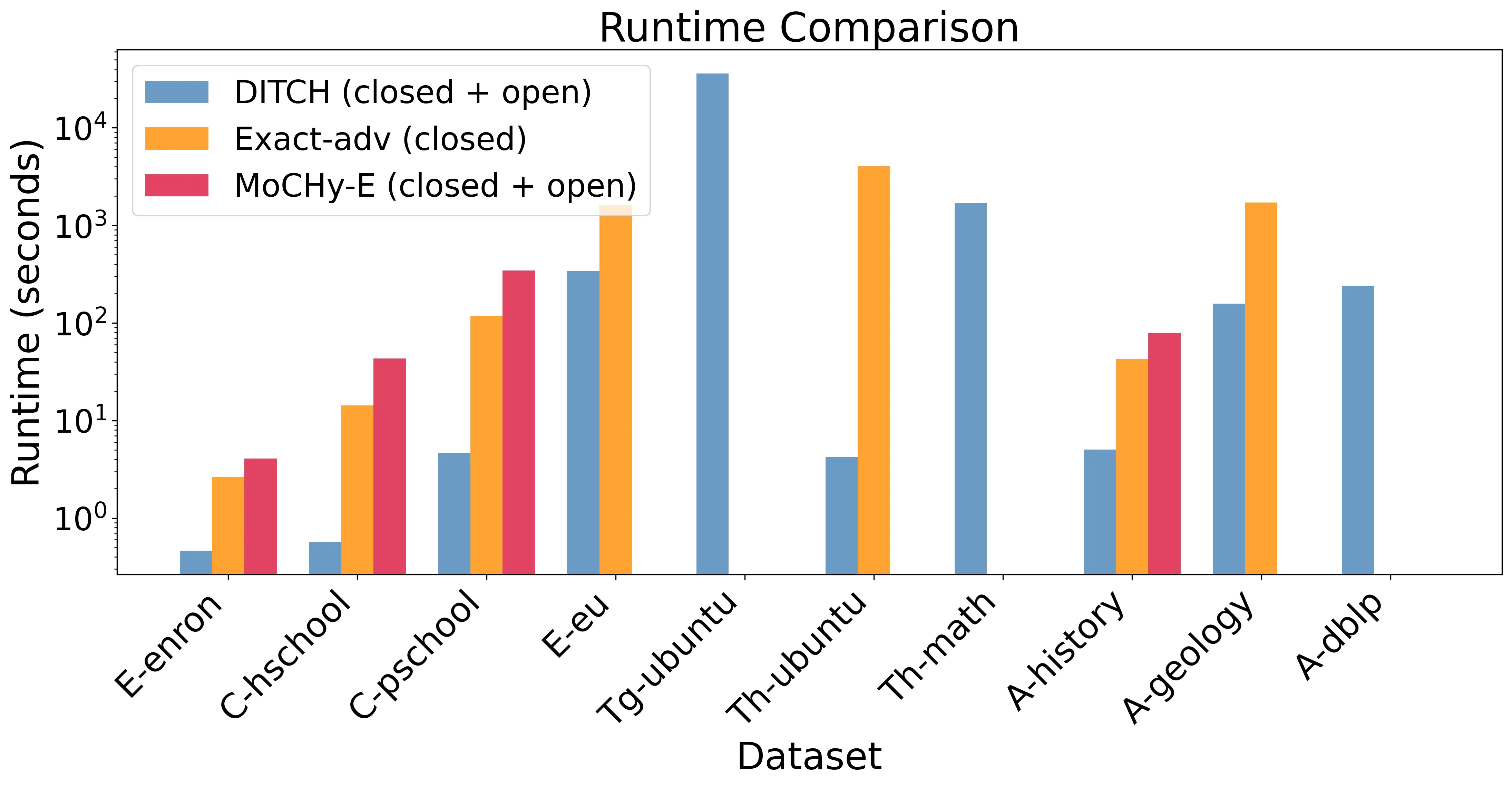
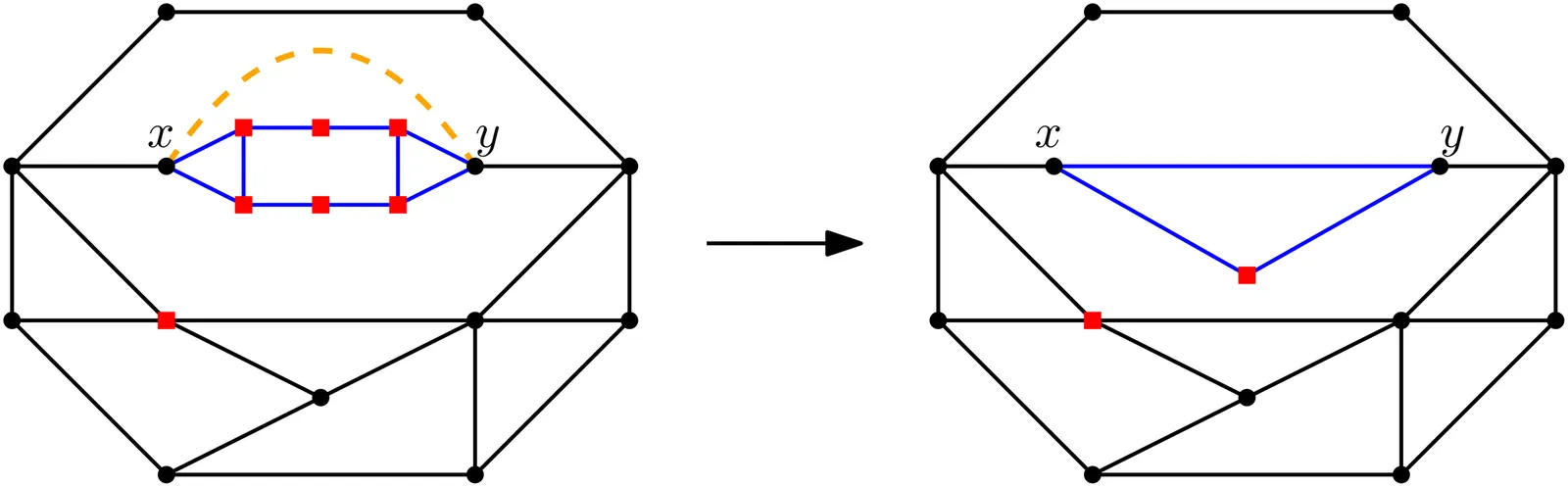
Counting the number of small patterns is a central task in network analysis. While this problem is well studied for graphs, many real-world datasets are naturally modeled as hypergraphs, motivating the need for efficient hypergraph motif counting algorithms. In particular, we study the problem of counting hypertriangles - collections of three pairwise-intersecting hyperedges. These hypergraph patterns have a rich structure with multiple distinct intersection patterns unlike graph triangles. Inspired by classical graph algorithms based on orientations and degeneracy, we develop a theoretical framework that generalizes these concepts to hypergraphs and yields provable algorithms for hypertriangle counting. We implement these ideas in DITCH (Degeneracy Inspired Triangle Counter for Hypergraphs) and show experimentally that it is 10-100x faster and more memory efficient than existing state-of-the-art methods.
$\mathsf{QAC}^0$ is the class of constant-depth polynomial-size quantum circuits constructed from arbitrary single-qubit gates and generalized Toffoli gates. It is arguably the smallest natural class of constant-depth quantum computation which has not been shown useful for computing any non-trivial Boolean function. Despite this, many attempts to port classical $\mathsf{AC}^0$ lower bounds to $\mathsf{QAC}^0$ have failed. We give one possible explanation of this: $\mathsf{QAC}^0$ circuits are significantly more powerful than their classical counterparts. We show the unconditional separation $\mathsf{QAC}^0\not\subset\mathsf{AC}^0[p]$ for decision problems, which also resolves for the first time whether $\mathsf{AC}^0$ could be more powerful than $\mathsf{QAC}^0$. Moreover, we prove that $\mathsf{QAC}^0$ circuits can compute a wide range of Boolean functions if given multiple copies of the input: $\mathsf{TC}^0 \subseteq \mathsf{QAC}^0 \circ \mathsf{NC}^0$. Along the way, we introduce an amplitude amplification technique that makes several approximate constant-depth constructions exact.

Expressive querying of machine learning models - viewed as a form of intentional data - enables their verification and interpretation using declarative languages, thereby making learned representations of data more accessible. Motivated by the querying of feedforward neural networks, we investigate logics for weighted structures. In the absence of a bound on neural network depth, such logics must incorporate recursion; thereto we revisit the functional fixpoint mechanism proposed by Grädel and Gurevich. We adopt it in a Datalog-like syntax; we extend normal forms for fixpoint logics to weighted structures; and show an equivalent "loose" fixpoint mechanism that allows values of inductively defined weight functions to be overwritten. We propose a "scalar" restriction of functional fixpoint logic, of polynomial-time data complexity, and show it can express all PTIME model-agnostic queries over reduced networks with polynomially bounded weights. In contrast, we show that very simple model-agnostic queries are already NP-complete. Finally, we consider transformations of weighted structures by iterated transductions.

We study $τ$-Bounded-Density Edge Deletion ($τ$-BDED), where given an undirected graph $G$, the task is to remove as few edges as possible to obtain a graph $G'$ where no subgraph of $G'$ has density more than $τ$. The density of a (sub)graph is the number of edges divided by the number of vertices. This problem was recently introduced and shown to be NP-hard for $τ\in \{2/3, 3/4, 1 + 1/25\}$, but polynomial-time solvable for $τ\in \{0,1/2,1\}$ [Bazgan et al., JCSS 2025]. We provide a complete dichotomy with respect to the target density $τ$: 1. If $2τ\in \mathbb{N}$ (half-integral target density) or $τ< 2/3$, then $τ$-BDED is polynomial-time solvable. 2. Otherwise, $τ$-BDED is NP-hard. We complement the NP-hardness with fixed-parameter tractability with respect to the treewidth of $G$. Moreover, for integral target density $τ\in \mathbb{N}$, we show $τ$-BDED to be solvable in randomized $O(m^{1 + o(1)})$ time. Our algorithmic results are based on a reduction to a new general flow problem on restricted networks that, depending on $τ$, can be solved via Maximum s-t-Flow or General Factors. We believe this connection between these variants of flow and matching to be of independent interest.
The regular expression matching problem asks whether a given regular expression of length $m$ matches a given string of length $n$. As is well known, the problem can be solved in $O(nm)$ time using Thompson's algorithm. Moreover, recent studies have shown that the matching problem for regular expressions extended with a practical extension called lookaround can be solved in the same time complexity. In this work, we consider three well-known extensions to regular expressions called backreference, intersection and complement, and we show that, unlike in the case of lookaround, the matching problem for regular expressions extended with any of the three (for backreference, even when restricted to one capturing group) cannot be solved in $O(n^{2-\varepsilon} \mathrm{poly}(m))$ time for any constant $\varepsilon > 0$ under the Orthogonal Vectors Conjecture. Moreover, we study the matching problem for regular expressions extended with complement in more detail, which is also known as extended regular expression (ERE) matching. We show that there is no ERE matching algorithm that runs in $O(n^{ω-\varepsilon} \mathrm{poly}(m))$ time ($2 \le ω< 2.3716$ is the exponent of square matrix multiplication) for any constant $\varepsilon > 0$ under the $k$-Clique Hypothesis, and there is no combinatorial ERE matching algorithm that runs in $O(n^{3-\varepsilon} \mathrm{poly}(m))$ time for any constant $\varepsilon > 0$ under the Combinatorial $k$-Clique Hypothesis. This shows that the $O(n^3 m)$-time algorithm introduced by Hopcroft and Ullman in 1979 and recently improved by Bille et al. to run in $O(n^ωm)$ time using fast matrix multiplication was already optimal in a sense, and sheds light on why the theoretical computer science community has struggled to improve the time complexity of ERE matching with respect to $n$ and $m$ for more than 45 years.
In moldable job scheduling, we are provided $m$ identical machines and $n$ jobs that can be executed on a variable number of machines. The execution time of each job depends on the number of machines assigned to execute that job. For the specific problem of monotone moldable job scheduling, jobs are assumed to have a processing time that is non-increasing in the number of machines. The previous best-known algorithms are: (1) a polynomial-time approximation scheme with time complexity $Ω(n^{g(1/\varepsilon)})$, where $g(\cdot)$ is a super-exponential function [Jansen and Thöle '08; Jansen and Land '18], (2) a fully polynomial approximation scheme for the case of $m \geq 8\frac{n}{\varepsilon}$ [Jansen and Land '18], and (3) a $\frac{3}{2}$ approximation with time complexity $O(nm\log(mn))$ [Wu, Zhang, and Chen '23]. We present a new practically efficient algorithm with an approximation ratio of $\approx (1.4593 + \varepsilon)$ and a time complexity of $O(nm \log \frac{1}{\varepsilon})$. Our result also applies to the contiguous variant of the problem. In addition to our theoretical results, we implement the presented algorithm and show that the practical performance is significantly better than the theoretical worst-case approximation ratio.
This is a brief description of a project that has already autoformalized a large portion of the general topology from the Munkres textbook (which has in total 241 pages in 7 chapters and 39 sections). The project has been running since November 21, 2025 and has as of January 4, 2026, produced 160k lines of formalized topology. Most of it (about 130k lines) have been done in two weeks,from December 22 to January 4, for an LLM subscription cost of about \$100. This includes a 3k-line proof of Urysohn's lemma, a 2k-line proof of Urysohn's Metrization theorem, over 10k-line proof of the Tietze extension theorem, and many more (in total over 1.5k lemmas/theorems). The approach is quite simple and cheap: build a long-running feedback loop between an LLM and a reasonably fast proof checker equipped with a core foundational library. The LLM is now instantiated as ChatGPT (mostly 5.2) or Claude Sonnet (4.5) run through the respective Codex or Claude Code command line interfaces. The proof checker is Chad Brown's higher-order set theory system Megalodon, and the core library is Brown's formalization of basic set theory and surreal numbers (including reals, etc). The rest is some prompt engineering and technical choices which we describe here. Based on the fast progress, low cost, virtually unknown ITP/library, and the simple setup available to everyone, we believe that (auto)formalization may become quite easy and ubiquitous in 2026, regardless of which proof assistant is used.
We study the parameterized complexity of the Cograph Deletion problem, which asks whether one can delete at most $k$ edges from a graph to make it $P_4$-free. This is a well-known graph modification problem with applications in computation biology and social network analysis. All current parameterized algorithms use a similar strategy, which is to find a $P_4$ and explore the local structure around it to perform an efficient recursive branching. The best known algorithm achieves running time $O^*(2.303^k)$ and requires an automated search of the branching cases due to their complexity. Since it appears difficult to further improve the current strategy, we devise a new approach using modular decompositions. We solve each module and the quotient graph independently, with the latter being the core problem. This reduces the problem to solving on a prime graph, in which all modules are trivial. We then use a characterization of Chudnovsky et al. stating that any large enough prime graph has one of seven structures as an induced subgraph. These all have many $P_4$s, with the quantity growing linearly with the graph size, and we show that these allow a recursive branch tree algorithm to achieve running time $O^*((2 + ε)^k)$ for any $ε> 0$. This appears to be the first algorithmic application of the prime graph characterization and it could be applicable to other modification problems. Towards this goal, we provide the exact set of graph classes $\H$ for which the $\H$-free editing problem can make use of our reduction to a prime graph, opening the door to improvements for other modification problems.
We present the SER modeling language for automatically verifying serializability of concurrent programs, i.e., whether every concurrent execution of the program is equivalent to some serial execution. SER programs are suitably restricted to make this problem decidable, while still allowing for an unbounded number of concurrent threads of execution, each potentially running for an unbounded number of steps. Building on prior theoretical results, we give the first automated end-to-end decision procedure that either proves serializability by producing a checkable certificate, or refutes it by producing a counterexample trace. We also present a network-system abstraction to which SER programs compile. Our decision procedure then reduces serializability in this setting to a Petri net reachability query. Furthermore, in order to scale, we curtail the search space via multiple optimizations, including Petri net slicing, semilinear-set compression, and Presburger-formula manipulation. We extensively evaluate our framework and show that, despite the theoretical hardness of the problem, it can successfully handle various models of real-world programs, including stateful firewalls, BGP routers, and more.