Sound
arXiv:cs.SD
Covers all aspects of computing with sound, and sound as an information channel.
Covers all aspects of computing with sound, and sound as an information channel.
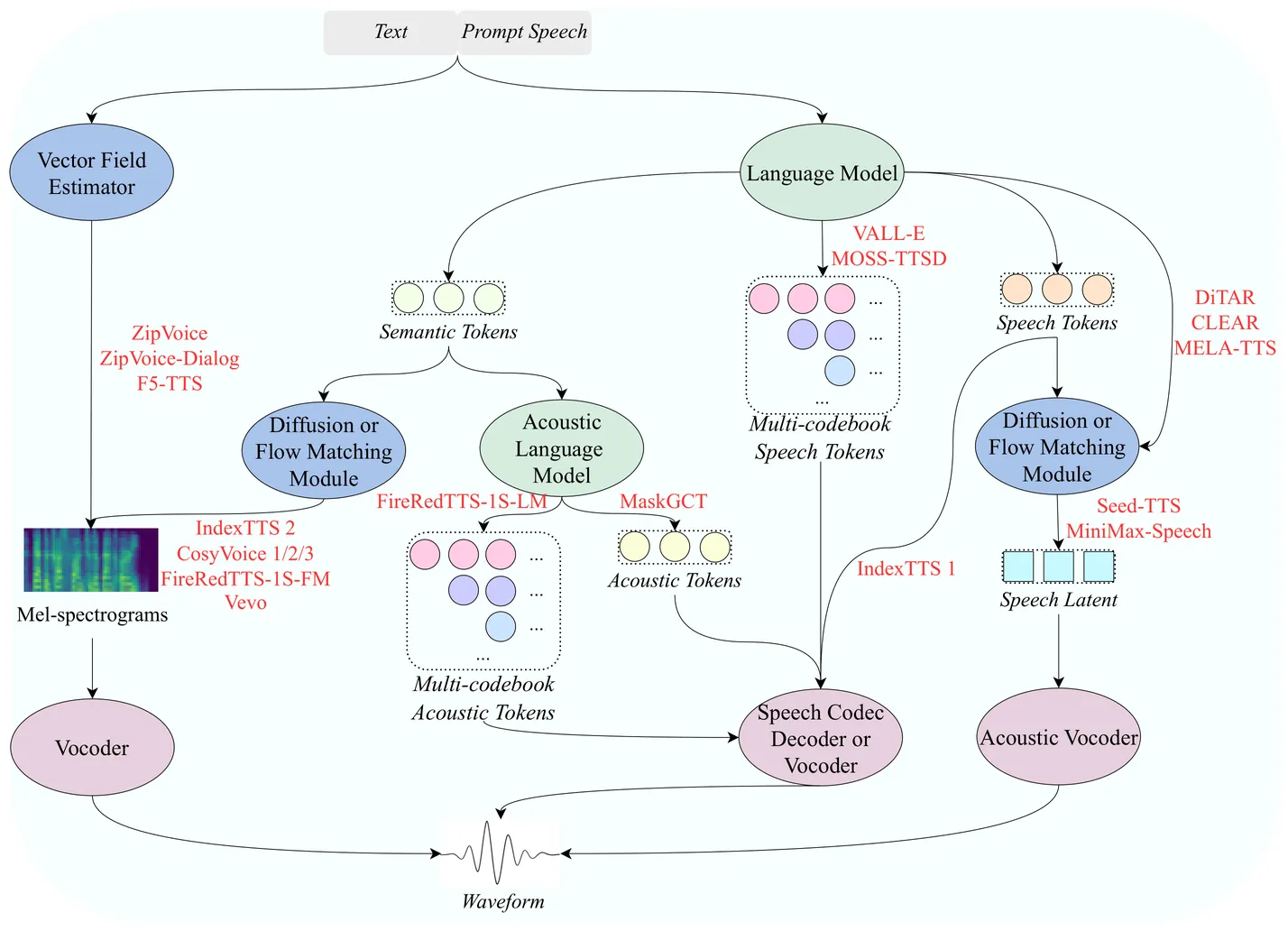
In prior work, we introduced IndexTTS 2, a zero-shot neural text-to-speech foundation model comprising two core components: a transformer-based Text-to-Semantic (T2S) module and a non-autoregressive Semantic-to-Mel (S2M) module, which together enable faithful emotion replication and establish the first autoregressive duration-controllable generative paradigm. Building upon this, we present IndexTTS 2.5, which significantly enhances multilingual coverage, inference speed, and overall synthesis quality through four key improvements: 1) Semantic Codec Compression: we reduce the semantic codec frame rate from 50 Hz to 25 Hz, halving sequence length and substantially lowering both training and inference costs; 2) Architectural Upgrade: we replace the U-DiT-based backbone of the S2M module with a more efficient Zipformer-based modeling architecture, achieving notable parameter reduction and faster mel-spectrogram generation; 3) Multilingual Extension: We propose three explicit cross-lingual modeling strategies, boundary-aware alignment, token-level concatenation, and instruction-guided generation, establishing practical design principles for zero-shot multilingual emotional TTS that supports Chinese, English, Japanese, and Spanish, and enables robust emotion transfer even without target-language emotional training data; 4) Reinforcement Learning Optimization: we apply GRPO in post-training of the T2S module, improving pronunciation accuracy and natrualness. Experiments show that IndexTTS 2.5 not only supports broader language coverage but also replicates emotional prosody in unseen languages under the same zero-shot setting. IndexTTS 2.5 achieves a 2.28 times improvement in RTF while maintaining comparable WER and speaker similarity to IndexTTS 2.
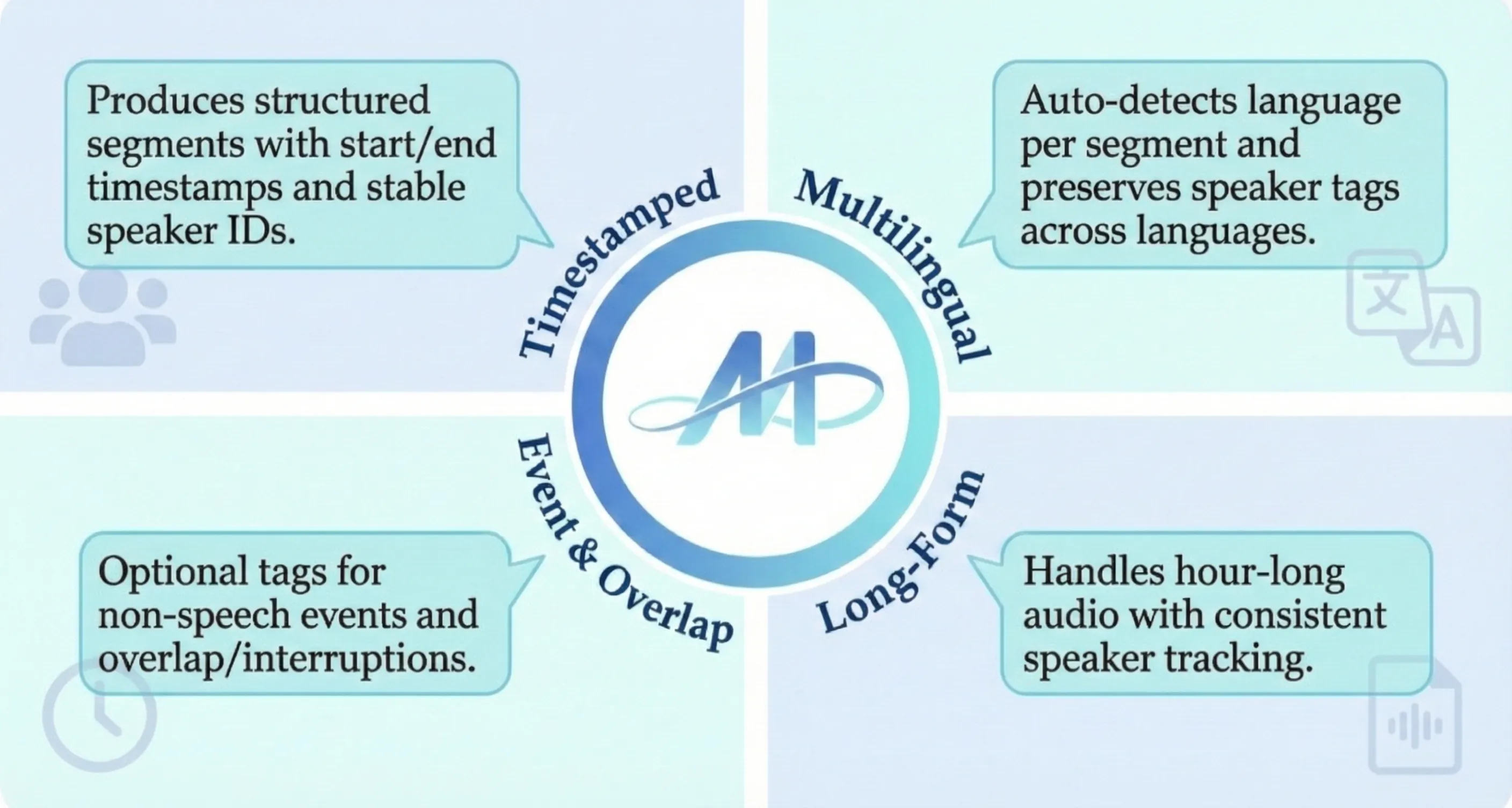
Speaker-Attributed, Time-Stamped Transcription (SATS) aims to transcribe what is said and to precisely determine the timing of each speaker, which is particularly valuable for meeting transcription. Existing SATS systems rarely adopt an end-to-end formulation and are further constrained by limited context windows, weak long-range speaker memory, and the inability to output timestamps. To address these limitations, we present MOSS Transcribe Diarize, a unified multimodal large language model that jointly performs Speaker-Attributed, Time-Stamped Transcription in an end-to-end paradigm. Trained on extensive real wild data and equipped with a 128k context window for up to 90-minute inputs, MOSS Transcribe Diarize scales well and generalizes robustly. Across comprehensive evaluations, it outperforms state-of-the-art commercial systems on multiple public and in-house benchmarks.

Joint audio-video generation aims to synthesize synchronized multisensory content, yet current unified models struggle with fine-grained acoustic control, particularly for identity-preserving speech. Existing approaches either suffer from temporal misalignment due to cascaded generation or lack the capability to perform zero-shot voice cloning within a joint synthesis framework. In this work, we present MM-Sonate, a multimodal flow-matching framework that unifies controllable audio-video joint generation with zero-shot voice cloning capabilities. Unlike prior works that rely on coarse semantic descriptions, MM-Sonate utilizes a unified instruction-phoneme input to enforce strict linguistic and temporal alignment. To enable zero-shot voice cloning, we introduce a timbre injection mechanism that effectively decouples speaker identity from linguistic content. Furthermore, addressing the limitations of standard classifier-free guidance in multimodal settings, we propose a noise-based negative conditioning strategy that utilizes natural noise priors to significantly enhance acoustic fidelity. Empirical evaluations demonstrate that MM-Sonate establishes new state-of-the-art performance in joint generation benchmarks, significantly outperforming baselines in lip synchronization and speech intelligibility, while achieving voice cloning fidelity comparable to specialized Text-to-Speech systems.
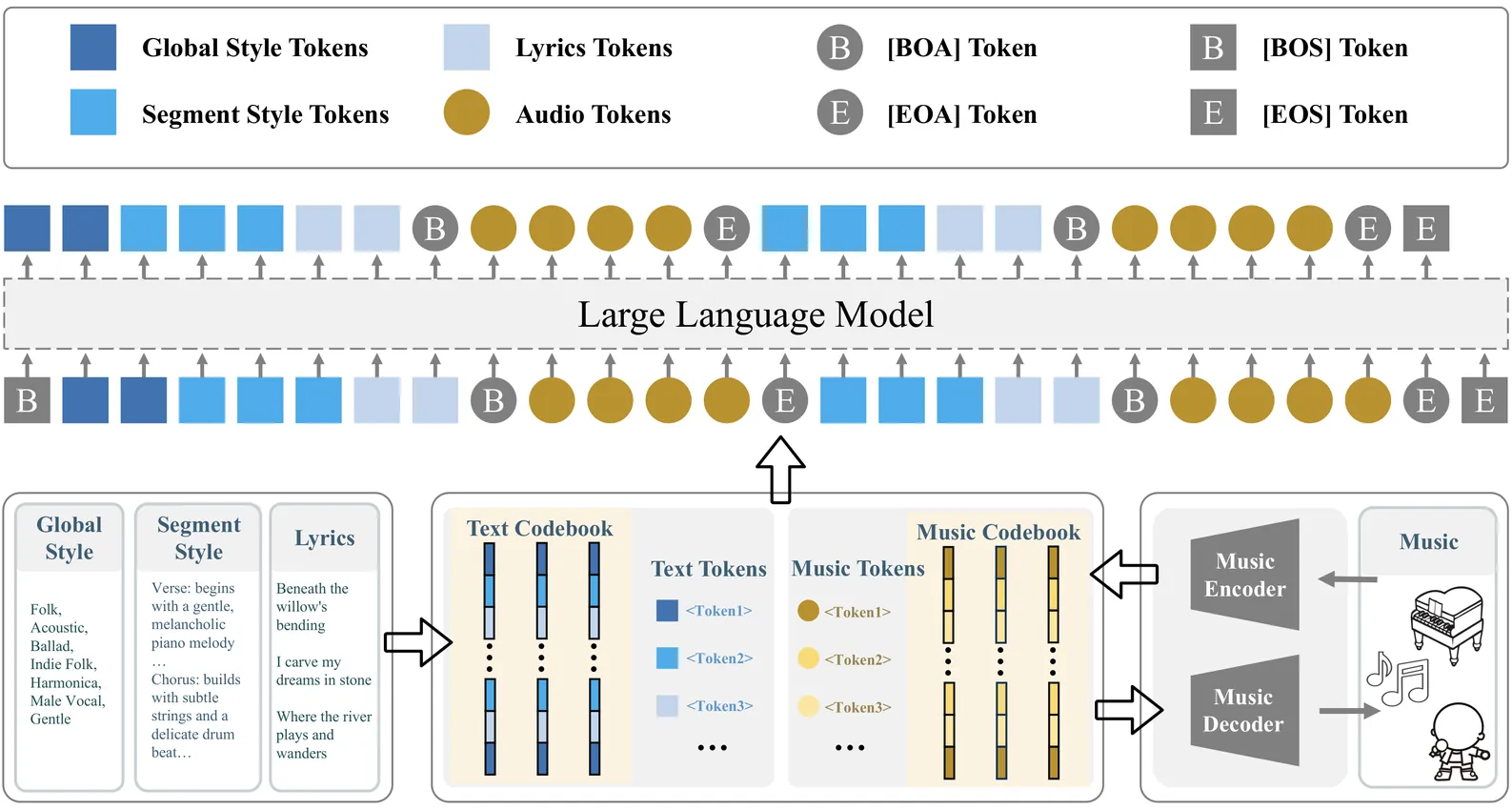
Recent commercial systems such as Suno demonstrate strong capabilities in long-form song generation, while academic research remains largely non-reproducible due to the lack of publicly available training data, hindering fair comparison and progress. To this end, we release a fully open-source system for long-form song generation with fine-grained style conditioning, including a licensed synthetic dataset, training and evaluation pipelines, and Muse, an easy-to-deploy song generation model. The dataset consists of 116k fully licensed synthetic songs with automatically generated lyrics and style descriptions paired with audio synthesized by SunoV5. We train Muse via single-stage supervised finetuning of a Qwen-based language model extended with discrete audio tokens using MuCodec, without task-specific losses, auxiliary objectives, or additional architectural components. Our evaluations find that although Muse is trained with a modest data scale and model size, it achieves competitive performance on phoneme error rate, text--music style similarity, and audio aesthetic quality, while enabling controllable segment-level generation across different musical structures. All data, model weights, and training and evaluation pipelines will be publicly released, paving the way for continued progress in controllable long-form song generation research. The project repository is available at https://github.com/yuhui1038/Muse.
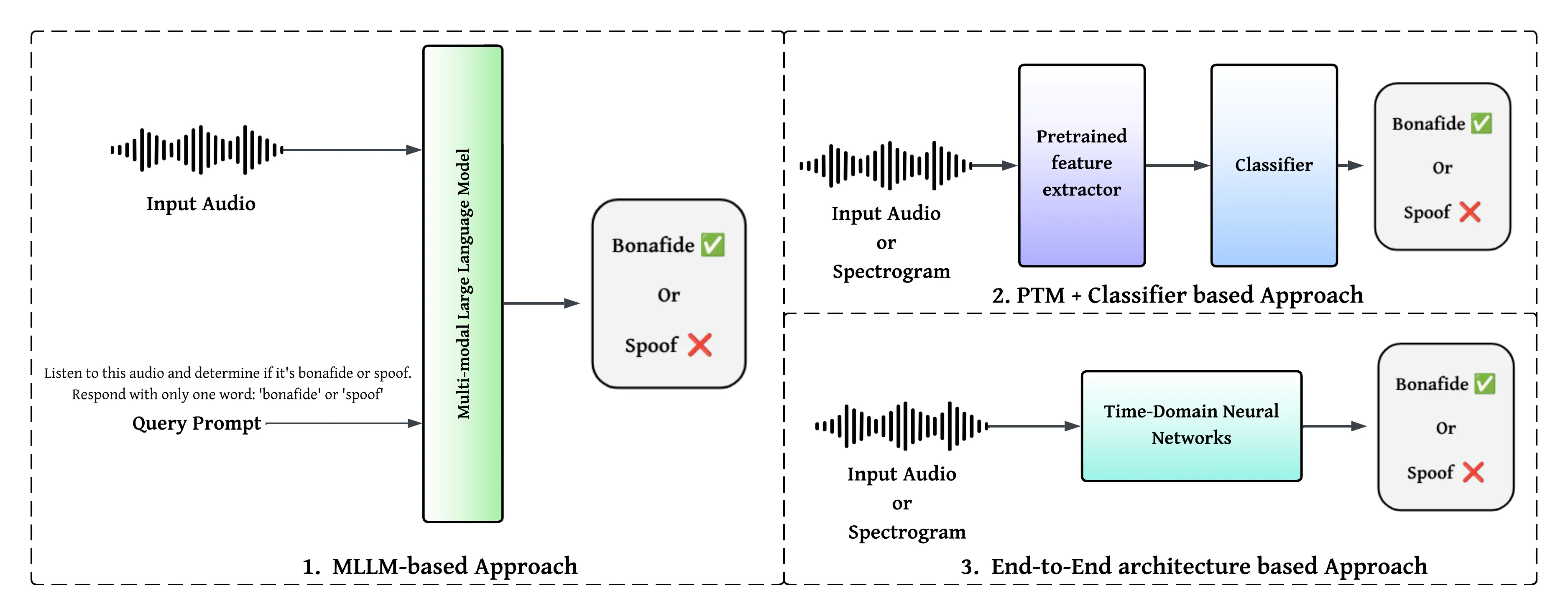
While Vision-Language Models (VLMs) and Multimodal Large Language Models (MLLMs) have shown strong generalisation in detecting image and video deepfakes, their use for audio deepfake detection remains largely unexplored. In this work, we aim to explore the potential of MLLMs for audio deepfake detection. Combining audio inputs with a range of text prompts as queries to find out the viability of MLLMs to learn robust representations across modalities for audio deepfake detection. Therefore, we attempt to explore text-aware and context-rich, question-answer based prompts with binary decisions. We hypothesise that such a feature-guided reasoning will help in facilitating deeper multimodal understanding and enable robust feature learning for audio deepfake detection. We evaluate the performance of two MLLMs, Qwen2-Audio-7B-Instruct and SALMONN, in two evaluation modes: (a) zero-shot and (b) fine-tuned. Our experiments demonstrate that combining audio with a multi-prompt approach could be a viable way forward for audio deepfake detection. Our experiments show that the models perform poorly without task-specific training and struggle to generalise to out-of-domain data. However, they achieve good performance on in-domain data with minimal supervision, indicating promising potential for audio deepfake detection.
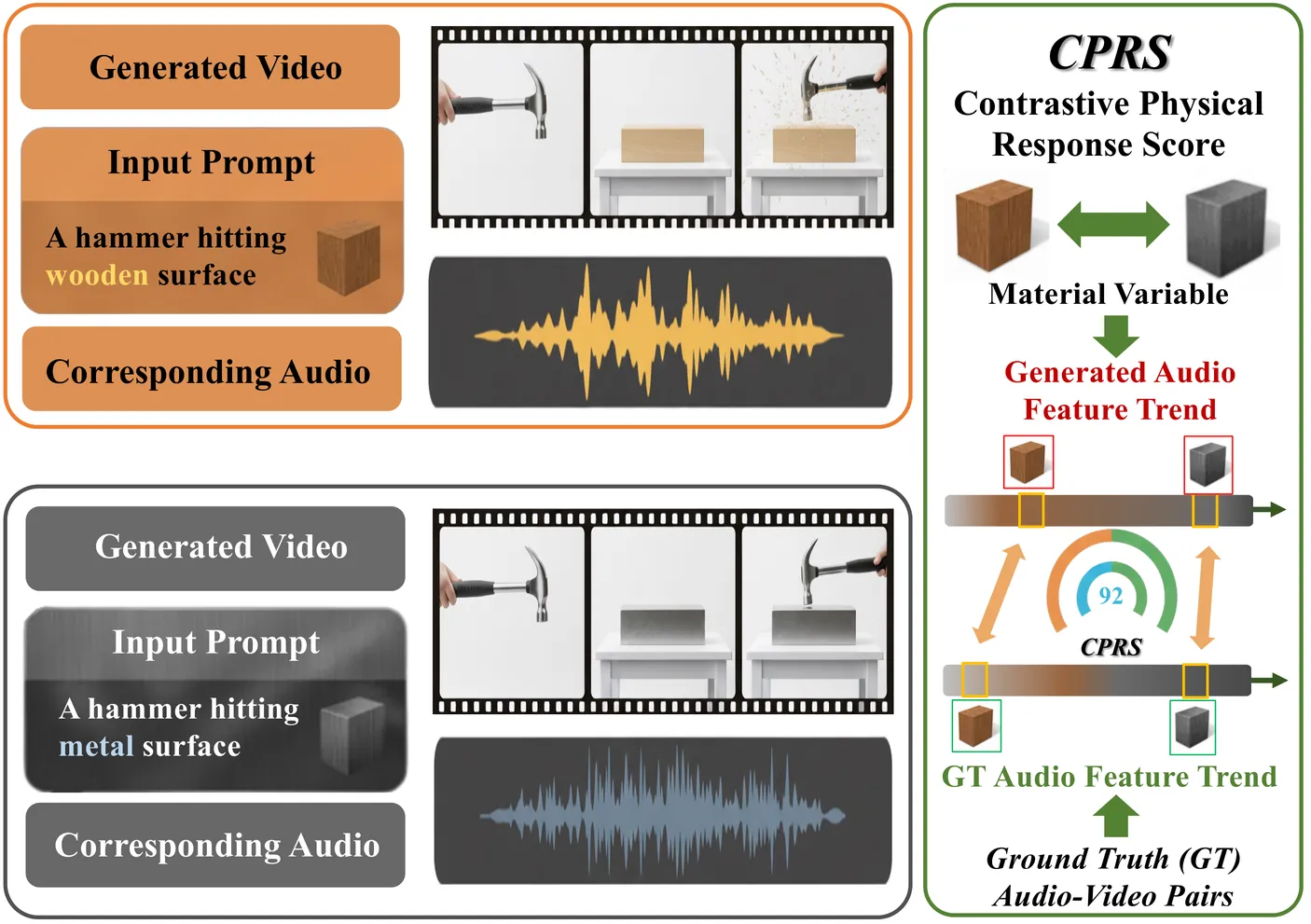
Text-to-audio-video (T2AV) generation underpins a wide range of applications demanding realistic audio-visual content, including virtual reality, world modeling, gaming, and filmmaking. However, existing T2AV models remain incapable of generating physically plausible sounds, primarily due to their limited understanding of physical principles. To situate current research progress, we present PhyAVBench, a challenging audio physics-sensitivity benchmark designed to systematically evaluate the audio physics grounding capabilities of existing T2AV models. PhyAVBench comprises 1,000 groups of paired text prompts with controlled physical variables that implicitly induce sound variations, enabling a fine-grained assessment of models' sensitivity to changes in underlying acoustic conditions. We term this evaluation paradigm the Audio-Physics Sensitivity Test (APST). Unlike prior benchmarks that primarily focus on audio-video synchronization, PhyAVBench explicitly evaluates models' understanding of the physical mechanisms underlying sound generation, covering 6 major audio physics dimensions, 4 daily scenarios (music, sound effects, speech, and their mix), and 50 fine-grained test points, ranging from fundamental aspects such as sound diffraction to more complex phenomena, e.g., Helmholtz resonance. Each test point consists of multiple groups of paired prompts, where each prompt is grounded by at least 20 newly recorded or collected real-world videos, thereby minimizing the risk of data leakage during model pre-training. Both prompts and videos are iteratively refined through rigorous human-involved error correction and quality control to ensure high quality. We argue that only models with a genuine grasp of audio-related physical principles can generate physically consistent audio-visual content. We hope PhyAVBench will stimulate future progress in this critical yet largely unexplored domain.

Neural vocoders and codecs reconstruct waveforms from acoustic representations, which directly impact the audio quality. Among existing methods, upsampling-based time-domain models are superior in both inference speed and synthesis quality, achieving state-of-the-art performance. Still, despite their success in producing perceptually natural sound, their synthesis fidelity remains limited due to the aliasing artifacts brought by the inadequately designed model architectures. In particular, the unconstrained nonlinear activation generates an infinite number of harmonics that exceed the Nyquist frequency, resulting in ``folded-back'' aliasing artifacts. The widely used upsampling layer, ConvTranspose, copies the mirrored low-frequency parts to fill the empty high-frequency region, resulting in ``mirrored'' aliasing artifacts. Meanwhile, the combination of its inherent periodicity and the mirrored DC bias also brings ``tonal artifact,'' resulting in constant-frequency ringing. This paper aims to solve these issues from a signal processing perspective. Specifically, we apply oversampling and anti-derivative anti-aliasing to the activation function to obtain its anti-aliased form, and replace the problematic ConvTranspose layer with resampling to avoid the ``tonal artifact'' and eliminate aliased components. Based on our proposed anti-aliased modules, we introduce Pupu-Vocoder and Pupu-Codec, and release high-quality pre-trained checkpoints to facilitate audio generation research. We build a test signal benchmark to illustrate the effectiveness of the anti-aliased modules, and conduct experiments on speech, singing voice, music, and audio to validate our proposed models. Experimental results confirm that our lightweight Pupu-Vocoder and Pupu-Codec models can easily outperform existing systems on singing voice, music, and audio, while achieving comparable performance on speech.
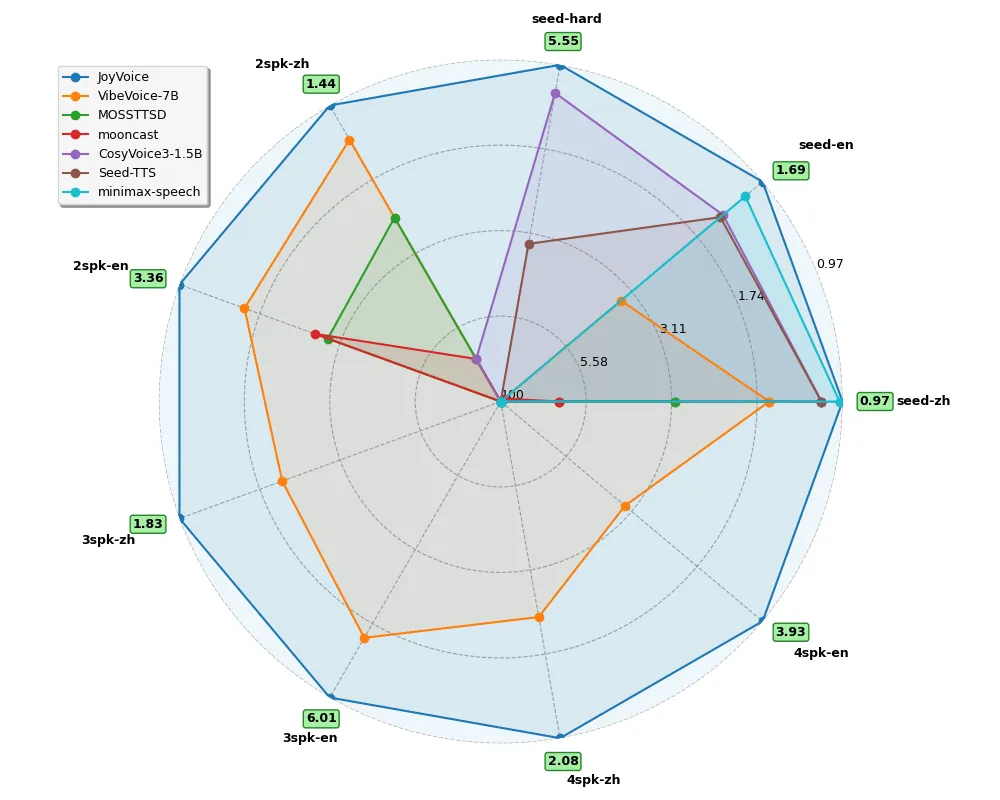
Large speech generation models are evolving from single-speaker, short sentence synthesis to multi-speaker, long conversation geneartion. Current long-form speech generation models are predominately constrained to dyadic, turn-based interactions. To address this, we introduce JoyVoice, a novel anthropomorphic foundation model designed for flexible, boundary-free synthesis of up to eight speakers. Unlike conventional cascaded systems, JoyVoice employs a unified E2E-Transformer-DiT architecture that utilizes autoregressive hidden representations directly for diffusion inputs, enabling holistic end-to-end optimization. We further propose a MM-Tokenizer operating at a low bitrate of 12.5 Hz, which integrates multitask semantic and MMSE losses to effectively model both semantic and acoustic information. Additionally, the model incorporates robust text front-end processing via large-scale data perturbation. Experiments show that JoyVoice achieves state-of-the-art results in multilingual generation (Chinese, English, Japanese, Korean) and zero-shot voice cloning. JoyVoice achieves top-tier results on both the Seed-TTS-Eval Benchmark and multi-speaker long-form conversational voice cloning tasks, demonstrating superior audio quality and generalization. It achieves significant improvements in prosodic continuity for long-form speech, rhythm richness in multi-speaker conversations, paralinguistic naturalness, besides superior intelligibility. We encourage readers to listen to the demo at https://jea-speech.github.io/JoyVoice
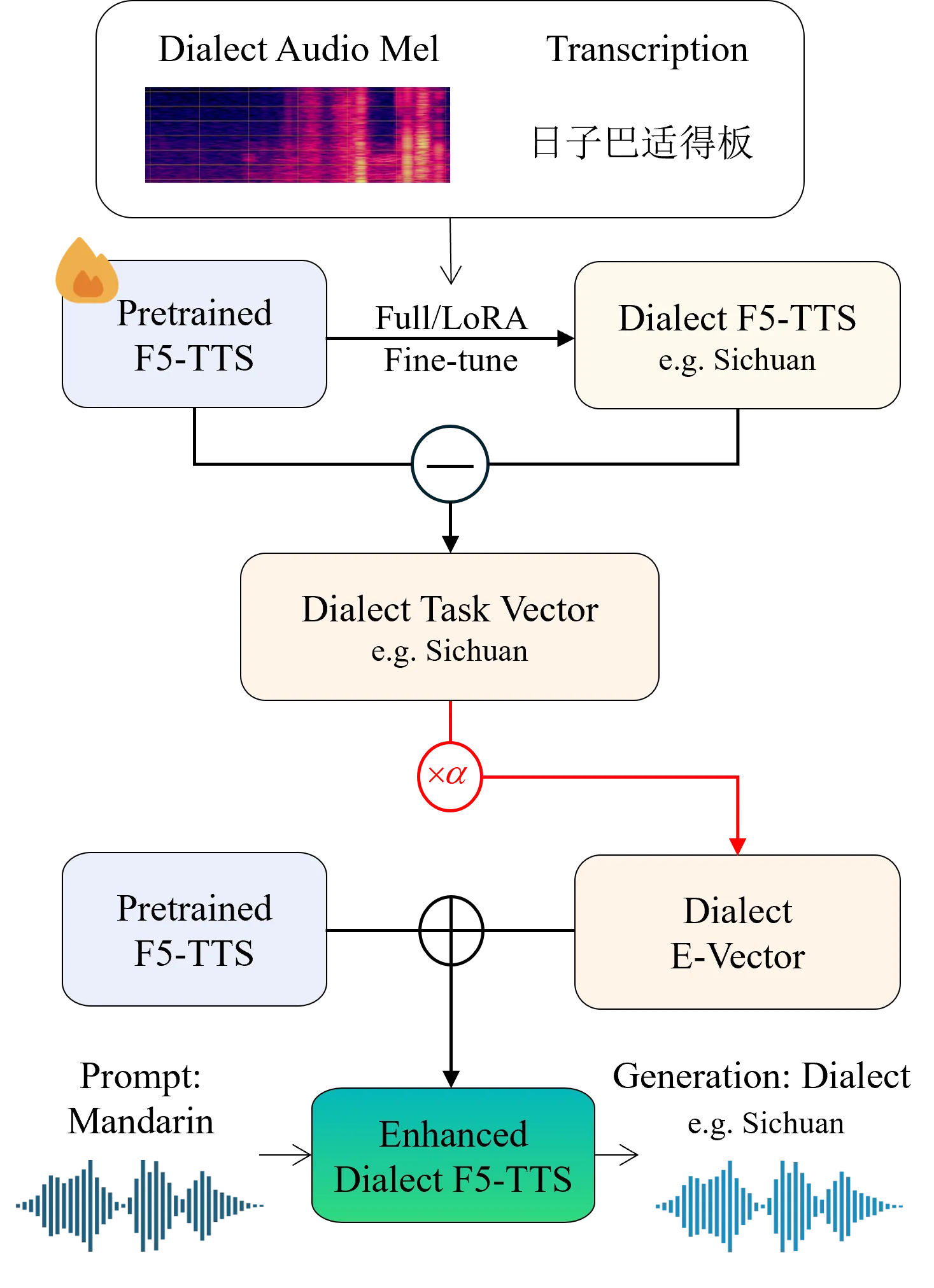
Recent advances in text-to-speech (TTS) have yielded remarkable improvements in naturalness and intelligibility. Building on these achievements, research has increasingly shifted toward enhancing the expressiveness of generated speech, such as dialectal and emotional TTS. However, cross-style synthesis combining both dialect and emotion remains challenging and largely unexplored, mainly due to the scarcity of dialectal data with emotional labels. To address this, we propose Hierarchical Expressive Vector (HE-Vector), a two-stage method for Emotional Dialectal TTS. In the first stage, we construct different task vectors to model dialectal and emotional styles independently, and then enhance single-style synthesis by adjusting their weights, a method we refer to as Expressive Vector (E-Vector). For the second stage, we hierarchically integrate these vectors to achieve controllable emotionally expressive dialect synthesis without requiring jointly labeled data, corresponding to Hierarchical Expressive Vector (HE-Vector). Experimental results demonstrate that HE-Vectors achieve superior performance in dialect synthesis, and promising results in synthesizing emotionally expressive dialectal speech in a zero-shot setting.
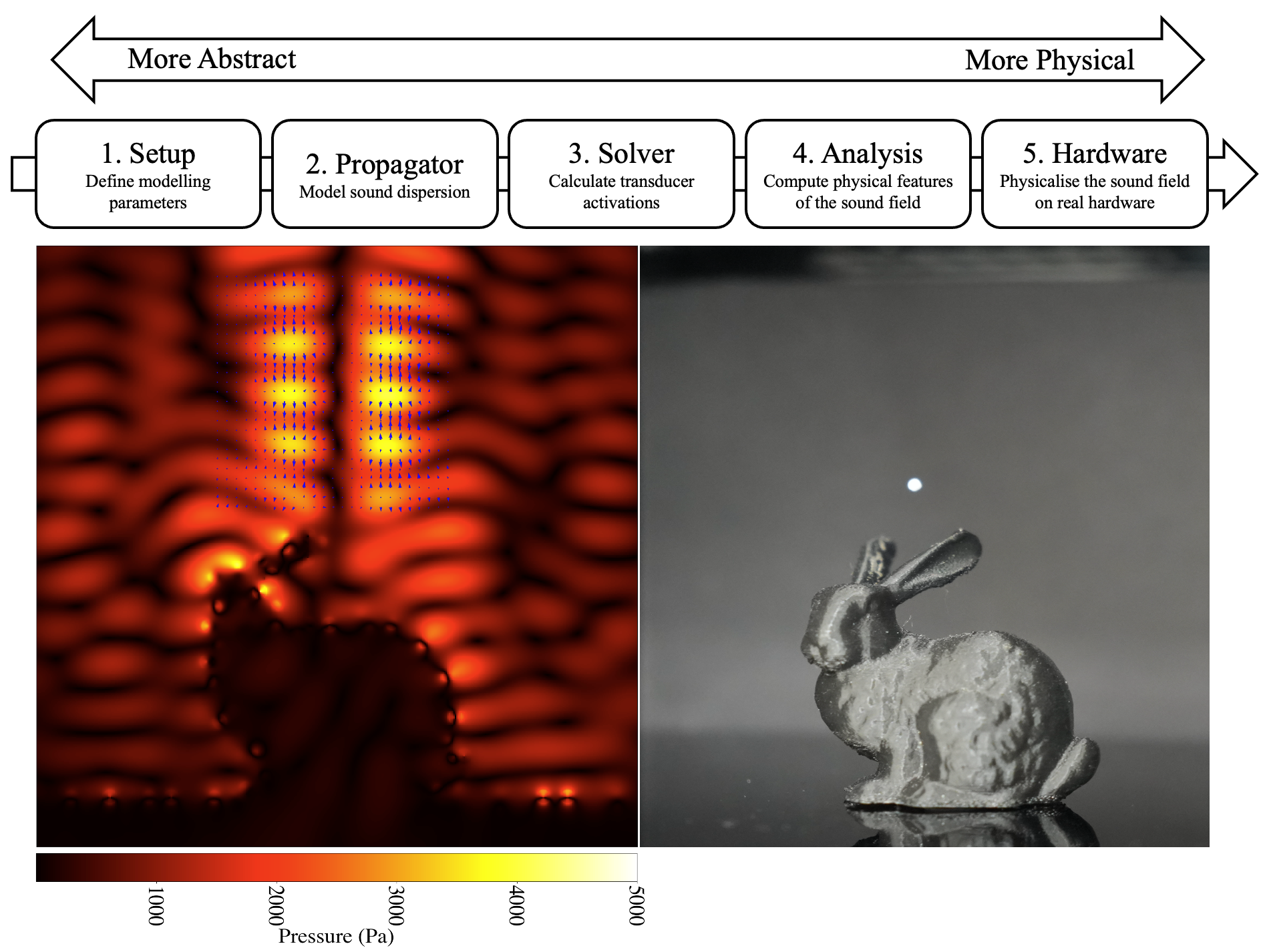
Acoustic Holography is an emerging field where mid-air ultrasound is controlled and manipulated for novel and exciting applications. These range from mid-air haptics, volumetric displays, contactless fabrication, and even chemical and biomedical applications such as drug delivery. To develop these applications, a software framework to predict acoustic behaviour and simulating resulting effects, such as applied forces or scattering patterns is desirable. There have been various software libraries and platforms that attempt to fill this role, but there is yet to be a single piece of software that acts as a 'full-stack' solution. We define this full-stack as the process from abstraction to physicalisation starting with setup, modelling acoustic propagation, transducer phase retrieval, sound field analysis, and control of the acoustic holographic hardware itself. Existing methods fail to fulfil one or more of these categories. To address this, we present AcousTools, a Python-based acoustic holography library, designed to support the full suite of acoustic holographic applications and we show AcousTools's ability to meet each step of the full-stack's requirements. AcousTools has the potential to become the standard code library for acoustic holography, with the uniquely complete suite of features wrapped in a language that is known to be easy to use, AcousTools will increase the ability for researchers to develop novel applications as well as accurately review other's work. The full-stack, aside from software, will also be useful for researchers - providing a way to view and compare methodologies by understanding where they fit into the stack.
In this paper, we trace the evolution of Music Information Retrieval (MIR) over the past 25 years. While MIR gathers all kinds of research related to music informatics, a large part of it focuses on signal processing techniques for music data, fostering a close relationship with the IEEE Audio and Acoustic Signal Processing Technical Commitee. In this paper, we reflect the main research achievements of MIR along the three EDICS related to music analysis, processing and generation. We then review a set of successful practices that fuel the rapid development of MIR research. One practice is the annual research benchmark, the Music Information Retrieval Evaluation eXchange, where participants compete on a set of research tasks. Another practice is the pursuit of reproducible and open research. The active engagement with industry research and products is another key factor for achieving large societal impacts and motivating younger generations of students to join the field. Last but not the least, the commitment to diversity, equity and inclusion ensures MIR to be a vibrant and open community where various ideas, methodologies, and career pathways collide. We finish by providing future challenges MIR will have to face.
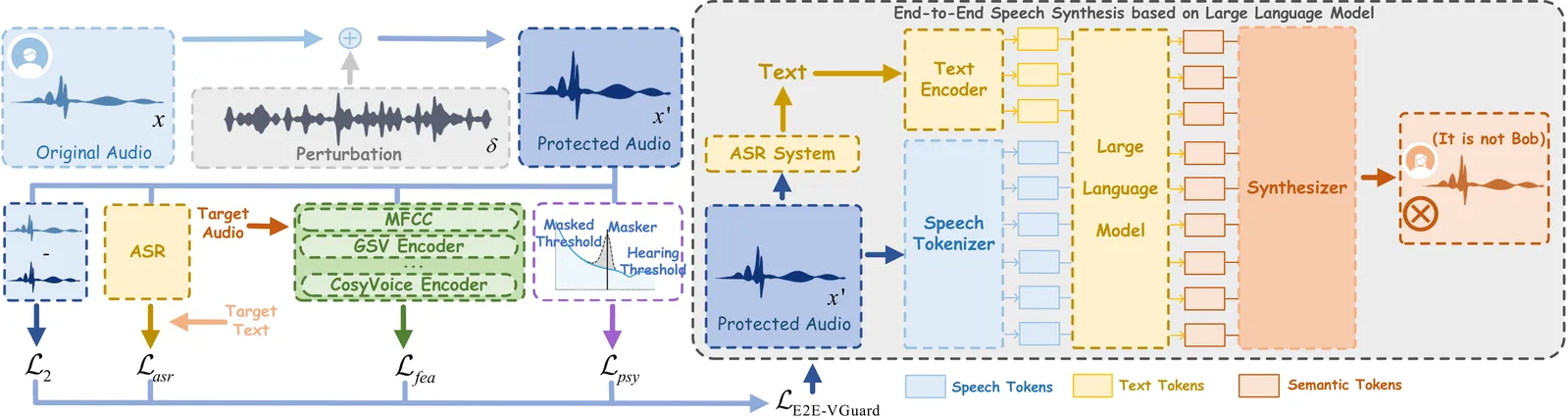
Recent advancements in speech synthesis technology have enriched our daily lives, with high-quality and human-like audio widely adopted across real-world applications. However, malicious exploitation like voice-cloning fraud poses severe security risks. Existing defense techniques struggle to address the production large language model (LLM)-based speech synthesis. While previous studies have considered the protection for fine-tuning synthesizers, they assume manually annotated transcripts. Given the labor intensity of manual annotation, end-to-end (E2E) systems leveraging automatic speech recognition (ASR) to generate transcripts are becoming increasingly prevalent, e.g., voice cloning via commercial APIs. Therefore, this E2E speech synthesis also requires new security mechanisms. To tackle these challenges, we propose E2E-VGuard, a proactive defense framework for two emerging threats: (1) production LLM-based speech synthesis, and (2) the novel attack arising from ASR-driven E2E scenarios. Specifically, we employ the encoder ensemble with a feature extractor to protect timbre, while ASR-targeted adversarial examples disrupt pronunciation. Moreover, we incorporate the psychoacoustic model to ensure perturbative imperceptibility. For a comprehensive evaluation, we test 16 open-source synthesizers and 3 commercial APIs across Chinese and English datasets, confirming E2E-VGuard's effectiveness in timbre and pronunciation protection. Real-world deployment validation is also conducted. Our code and demo page are available at https://wxzyd123.github.io/e2e-vguard/.
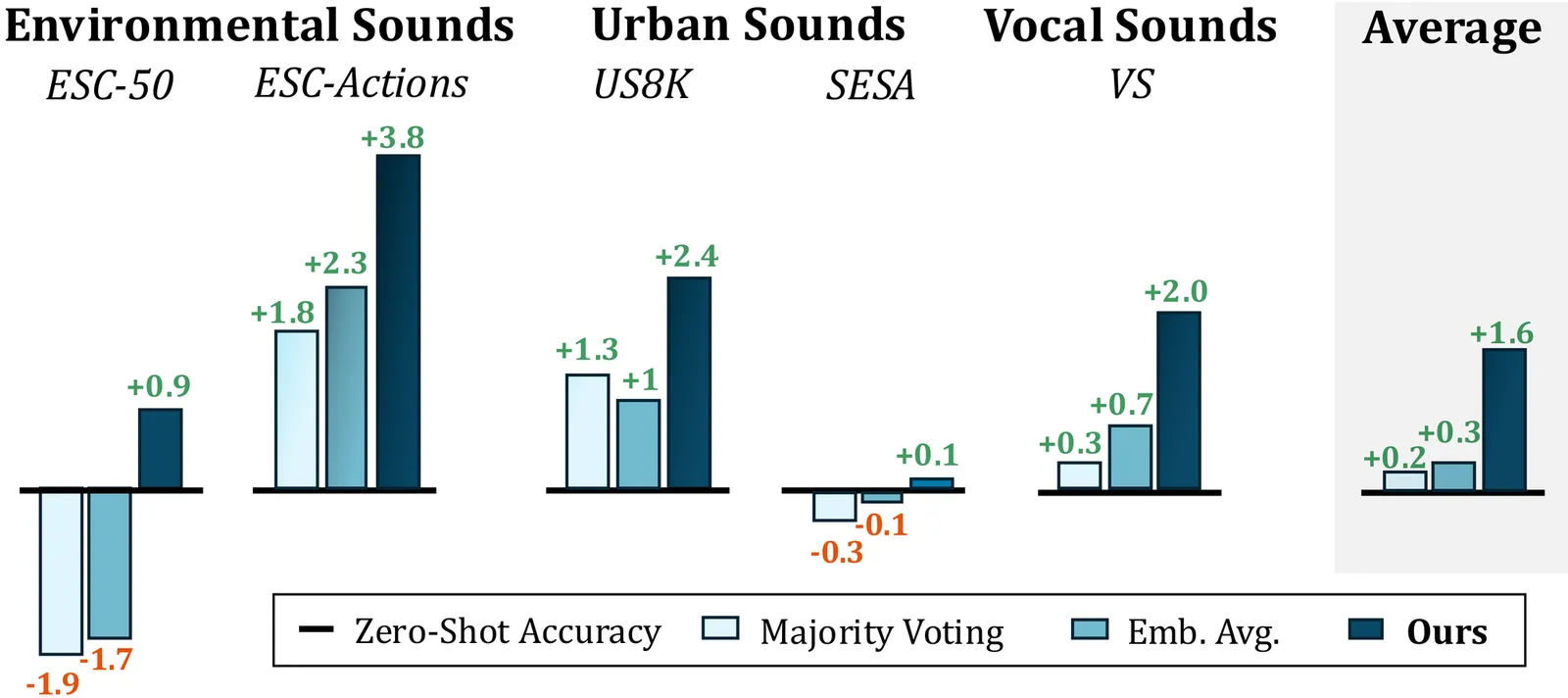
Audio-language models have recently demonstrated strong zero-shot capabilities by leveraging natural-language supervision to classify audio events without labeled training data. Yet, their performance is highly sensitive to the wording of text prompts, with small variations leading to large fluctuations in accuracy. Prior work has mitigated this issue through prompt learning or prompt ensembling. However, these strategies either require annotated data or fail to account for the fact that some prompts may negatively impact performance. In this work, we present an entropy-guided prompt weighting approach that aims to find a robust combination of prompt contributions to maximize prediction confidence. To this end, we formulate a tailored objective function that minimizes prediction entropy to yield new prompt weights, utilizing low-entropy as a proxy for high confidence. Our approach can be applied to individual samples or a batch of audio samples, requiring no additional labels and incurring negligible computational overhead. Experiments on five audio classification datasets covering environmental, urban, and vocal sounds, demonstrate consistent gains compared to classical prompt ensembling methods in a zero-shot setting, with accuracy improvements 5-times larger across the whole benchmark.

Detecting medical conditions from speech acoustics is fundamentally a weakly-supervised learning problem: a single, often noisy, session-level label must be linked to nuanced patterns within a long, complex audio recording. This task is further hampered by severe data scarcity and the subjective nature of clinical annotations. While semi-supervised learning (SSL) offers a viable path to leverage unlabeled data, existing audio methods often fail to address the core challenge that pathological traits are not uniformly expressed in a patient's speech. We propose a novel, audio-only SSL framework that explicitly models this hierarchy by jointly learning from frame-level, segment-level, and session-level representations within unsegmented clinical dialogues. Our end-to-end approach dynamically aggregates these multi-granularity features and generates high-quality pseudo-labels to efficiently utilize unlabeled data. Extensive experiments show the framework is model-agnostic, robust across languages and conditions, and highly data-efficient-achieving, for instance, 90\% of fully-supervised performance using only 11 labeled samples. This work provides a principled approach to learning from weak, far-end supervision in medical speech analysis.
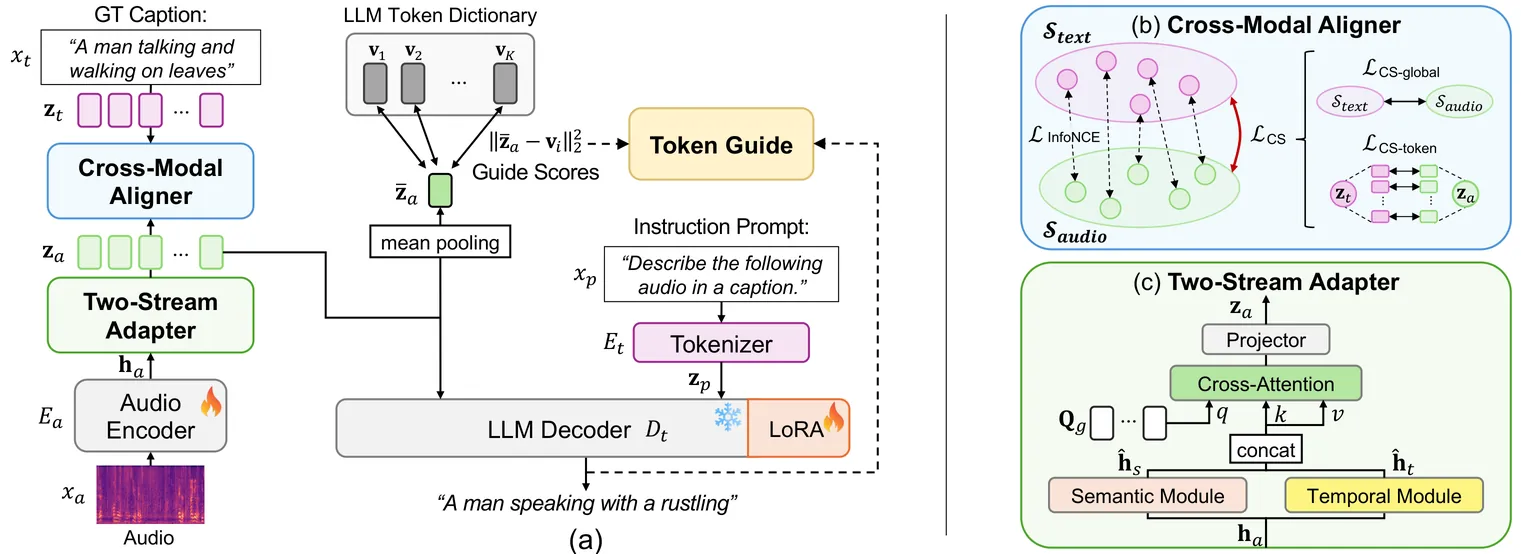
Automated Audio Captioning aims to describe the semantic content of input audio. Recent works have employed large language models (LLMs) as a text decoder to leverage their reasoning capabilities. However, prior approaches that project audio features into the LLM embedding space without considering cross-modal alignment fail to fully utilize these capabilities. To address this, we propose LAMB, an LLM-based audio captioning framework that bridges the modality gap between audio embeddings and the LLM text embedding space. LAMB incorporates a Cross-Modal Aligner that minimizes Cauchy-Schwarz divergence while maximizing mutual information, yielding tighter alignment between audio and text at both global and token levels. We further design a Two-Stream Adapter that extracts semantically enriched audio embeddings, thereby delivering richer information to the Cross-Modal Aligner. Finally, leveraging the aligned audio embeddings, a proposed Token Guide directly computes scores within the LLM text embedding space to steer the output logits of generated captions. Experimental results confirm that our framework strengthens the reasoning capabilities of the LLM decoder, achieving state-of-the-art performance on AudioCaps.
Music Source Restoration (MSR) aims to recover original, unprocessed instrument stems from professionally mixed and degraded audio, requiring the reversal of both production effects and real-world degradations. We present the inaugural MSR Challenge, which features objective evaluation on studio-produced mixtures using Multi-Mel-SNR, Zimtohrli, and FAD-CLAP, alongside subjective evaluation on real-world degraded recordings. Five teams participated in the challenge. The winning system achieved 4.46 dB Multi-Mel-SNR and 3.47 MOS-Overall, corresponding to relative improvements of 91% and 18% over the second-place system, respectively. Per-stem analysis reveals substantial variation in restoration difficulty across instruments, with bass averaging 4.59 dB across all teams, while percussion averages only 0.29 dB. The dataset, evaluation protocols, and baselines are available at https://msrchallenge.com/.
Recent commercial systems such as Suno demonstrate strong capabilities in long-form song generation, while academic research remains largely non-reproducible due to the lack of publicly available training data, hindering fair comparison and progress. To this end, we release a fully open-source system for long-form song generation with fine-grained style conditioning, including a licensed synthetic dataset, training and evaluation pipelines, and Muse, an easy-to-deploy song generation model. The dataset consists of 116k fully licensed synthetic songs with automatically generated lyrics and style descriptions paired with audio synthesized by SunoV5. We train Muse via single-stage supervised finetuning of a Qwen-based language model extended with discrete audio tokens using MuCodec, without task-specific losses, auxiliary objectives, or additional architectural components. Our evaluations find that although Muse is trained with a modest data scale and model size, it achieves competitive performance on phoneme error rate, text--music style similarity, and audio aesthetic quality, while enabling controllable segment-level generation across different musical structures. All data, model weights, and training and evaluation pipelines will be publicly released, paving the way for continued progress in controllable long-form song generation research. The project repository is available at https://github.com/yuhui1038/Muse.
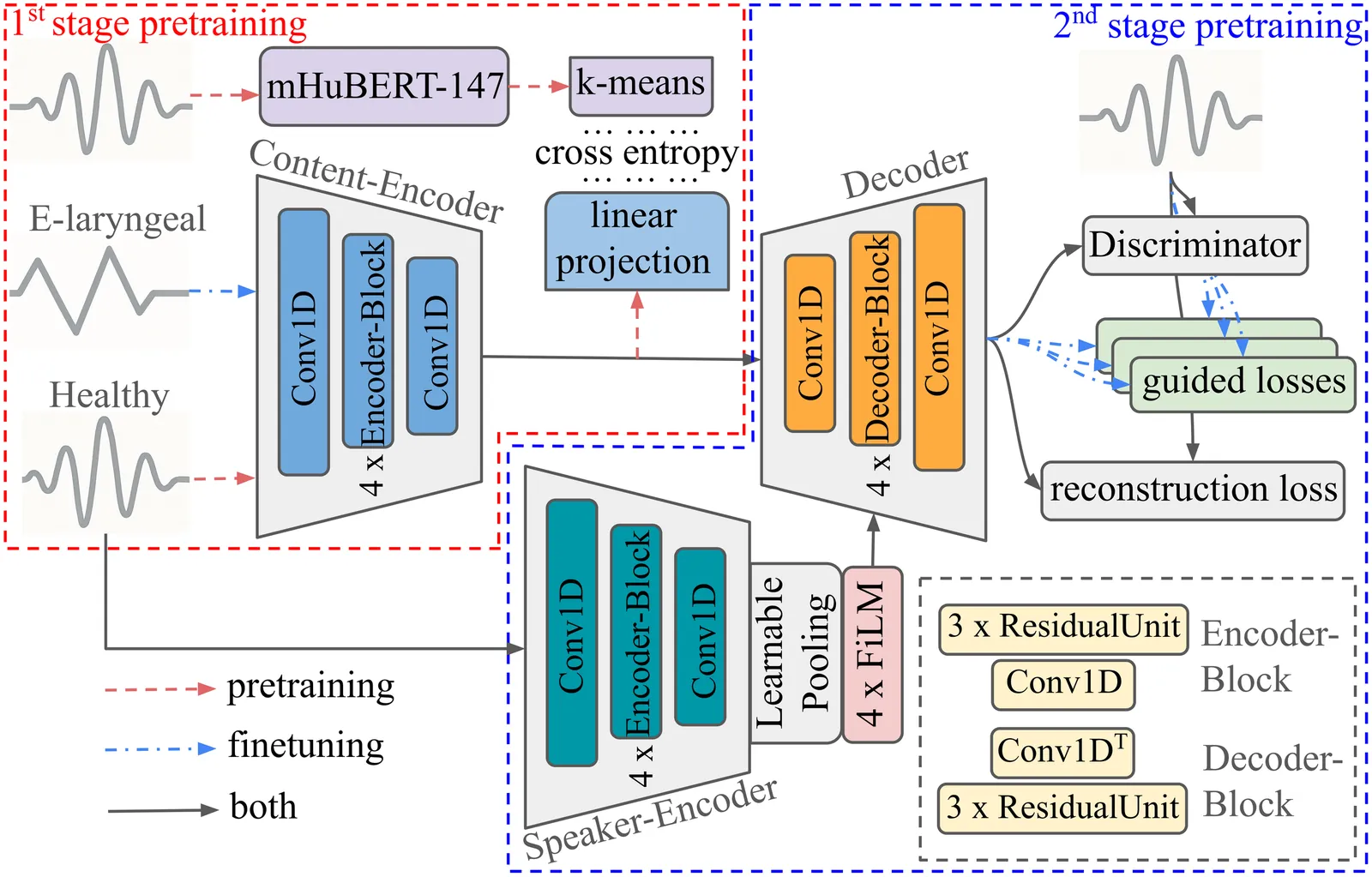
Electro-laryngeal (EL) speech is characterized by constant pitch, limited prosody, and mechanical noise, reducing naturalness and intelligibility. We propose a lightweight adaptation of the state-of-the-art StreamVC framework to this setting by removing pitch and energy modules and combining self-supervised pretraining with supervised fine-tuning on parallel EL and healthy (HE) speech data, guided by perceptual and intelligibility losses. Objective and subjective evaluations across different loss configurations confirm their influence: the best model variant, based on WavLM features and human-feedback predictions (+WavLM+HF), drastically reduces character error rate (CER) of EL inputs, raises naturalness mean opinion score (nMOS) from 1.1 to 3.3, and consistently narrows the gap to HE ground-truth speech in all evaluated metrics. These findings demonstrate the feasibility of adapting lightweight voice conversion architectures to EL voice rehabilitation while also identifying prosody generation and intelligibility improvements as the main remaining bottlenecks.
In prior work, we introduced IndexTTS 2, a zero-shot neural text-to-speech foundation model comprising two core components: a transformer-based Text-to-Semantic (T2S) module and a non-autoregressive Semantic-to-Mel (S2M) module, which together enable faithful emotion replication and establish the first autoregressive duration-controllable generative paradigm. Building upon this, we present IndexTTS 2.5, which significantly enhances multilingual coverage, inference speed, and overall synthesis quality through four key improvements: 1) Semantic Codec Compression: we reduce the semantic codec frame rate from 50 Hz to 25 Hz, halving sequence length and substantially lowering both training and inference costs; 2) Architectural Upgrade: we replace the U-DiT-based backbone of the S2M module with a more efficient Zipformer-based modeling architecture, achieving notable parameter reduction and faster mel-spectrogram generation; 3) Multilingual Extension: We propose three explicit cross-lingual modeling strategies, boundary-aware alignment, token-level concatenation, and instruction-guided generation, establishing practical design principles for zero-shot multilingual emotional TTS that supports Chinese, English, Japanese, and Spanish, and enables robust emotion transfer even without target-language emotional training data; 4) Reinforcement Learning Optimization: we apply GRPO in post-training of the T2S module, improving pronunciation accuracy and natrualness. Experiments show that IndexTTS 2.5 not only supports broader language coverage but also replicates emotional prosody in unseen languages under the same zero-shot setting. IndexTTS 2.5 achieves a 2.28 times improvement in RTF while maintaining comparable WER and speaker similarity to IndexTTS 2.
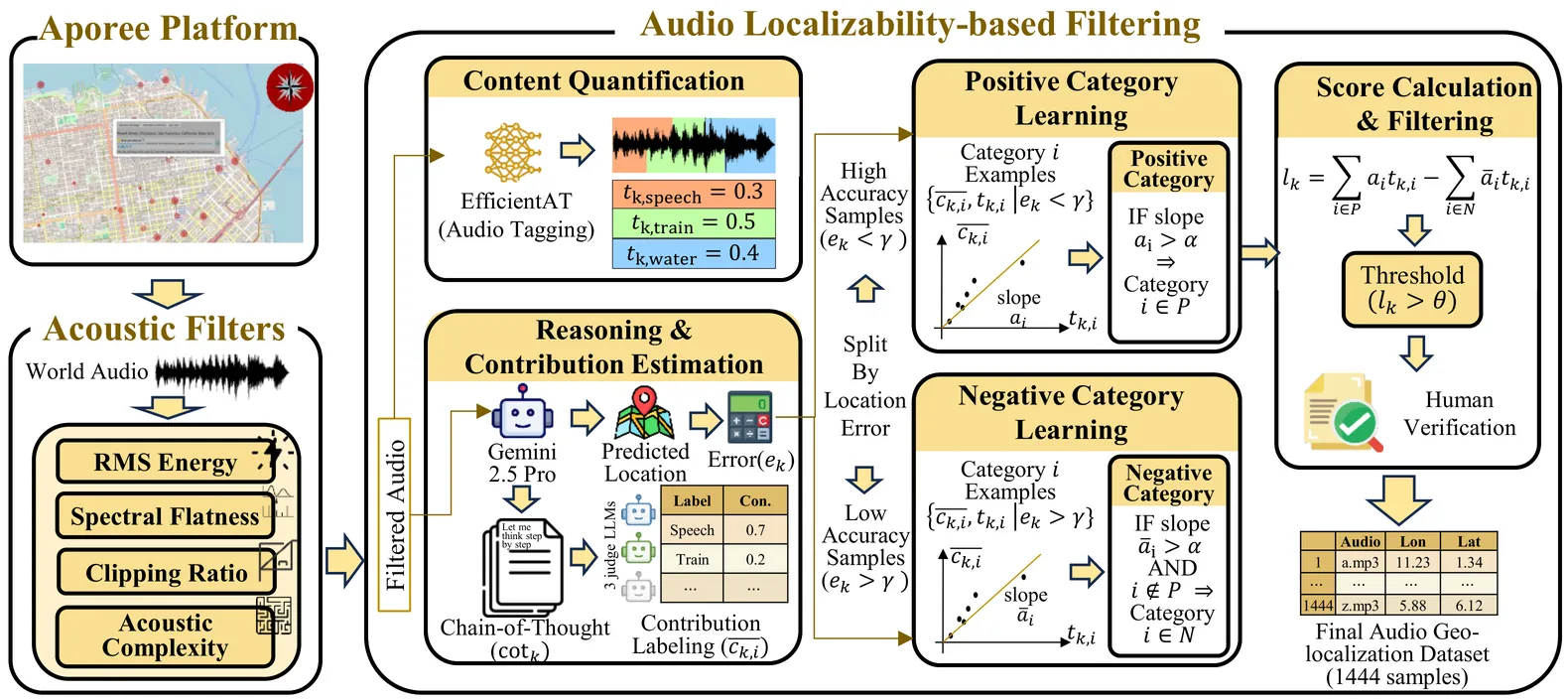
Geo-localization aims to infer the geographic origin of a given signal. In computer vision, geo-localization has served as a demanding benchmark for compositional reasoning and is relevant to public safety. In contrast, progress on audio geo-localization has been constrained by the lack of high-quality audio-location pairs. To address this gap, we introduce AGL1K, the first audio geo-localization benchmark for audio language models (ALMs), spanning 72 countries and territories. To extract reliably localizable samples from a crowd-sourced platform, we propose the Audio Localizability metric that quantifies the informativeness of each recording, yielding 1,444 curated audio clips. Evaluations on 16 ALMs show that ALMs have emerged with audio geo-localization capability. We find that closed-source models substantially outperform open-source models, and that linguistic clues often dominate as a scaffold for prediction. We further analyze ALMs' reasoning traces, regional bias, error causes, and the interpretability of the localizability metric. Overall, AGL1K establishes a benchmark for audio geo-localization and may advance ALMs with better geospatial reasoning capability.
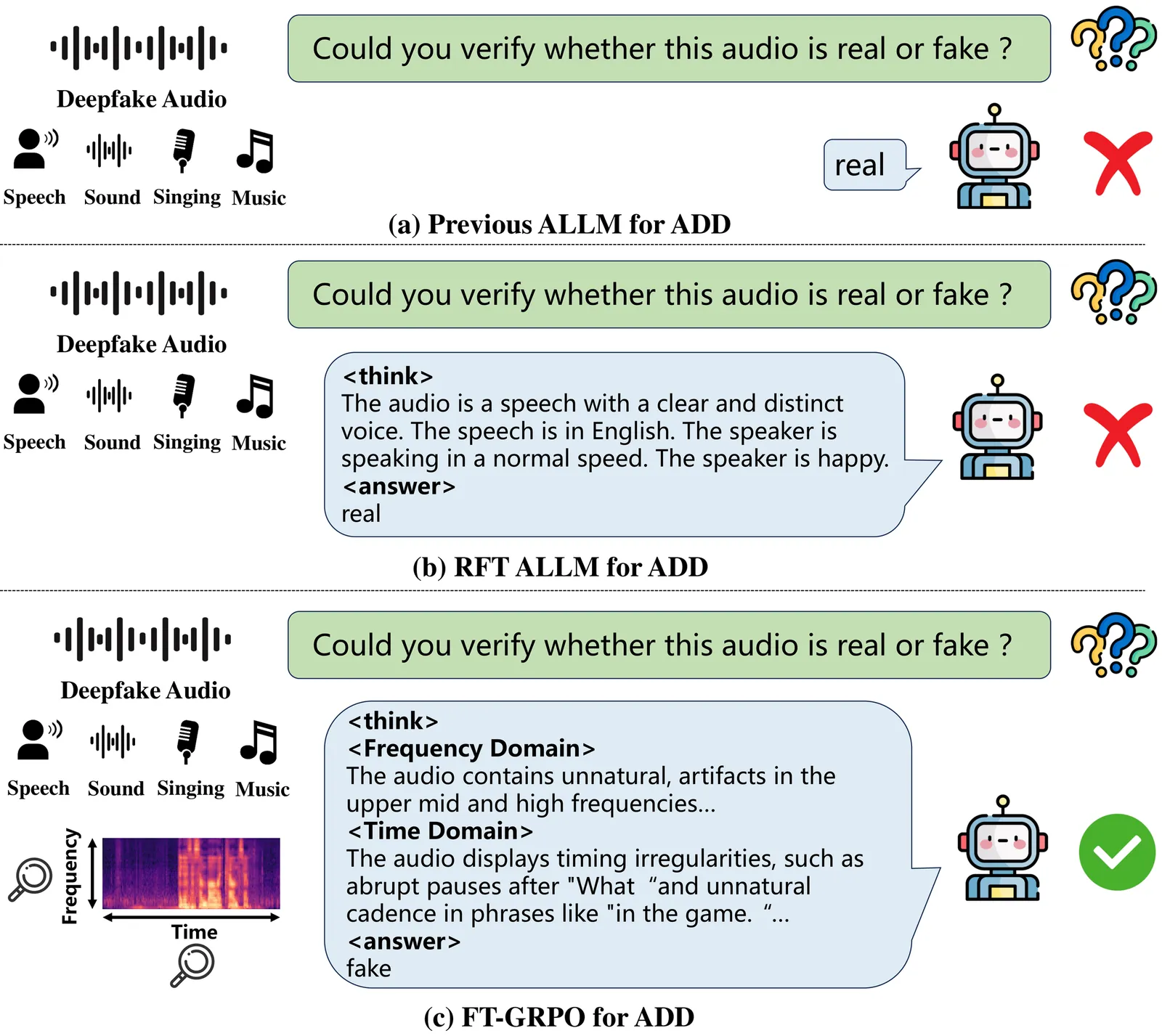
Recent advances in audio large language models (ALLMs) have made high-quality synthetic audio widely accessible, increasing the risk of malicious audio deepfakes across speech, environmental sounds, singing voice, and music. Real-world audio deepfake detection (ADD) therefore requires all-type detectors that generalize across heterogeneous audio and provide interpretable decisions. Given the strong multi-task generalization ability of ALLMs, we first investigate their performance on all-type ADD under both supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT). However, SFT using only binary real/fake labels tends to reduce the model to a black-box classifier, sacrificing interpretability. Meanwhile, vanilla RFT under sparse supervision is prone to reward hacking and can produce hallucinated, ungrounded rationales. To address this, we propose an automatic annotation and polishing pipeline that constructs Frequency-Time structured chain-of-thought (CoT) rationales, producing ~340K cold-start demonstrations. Building on CoT data, we propose Frequency Time-Group Relative Policy Optimization (FT-GRPO), a two-stage training paradigm that cold-starts ALLMs with SFT and then applies GRPO under rule-based frequency-time constraints. Experiments demonstrate that FT-GRPO achieves state-of-the-art performance on all-type ADD while producing interpretable, FT-grounded rationales. The data and code are available online.
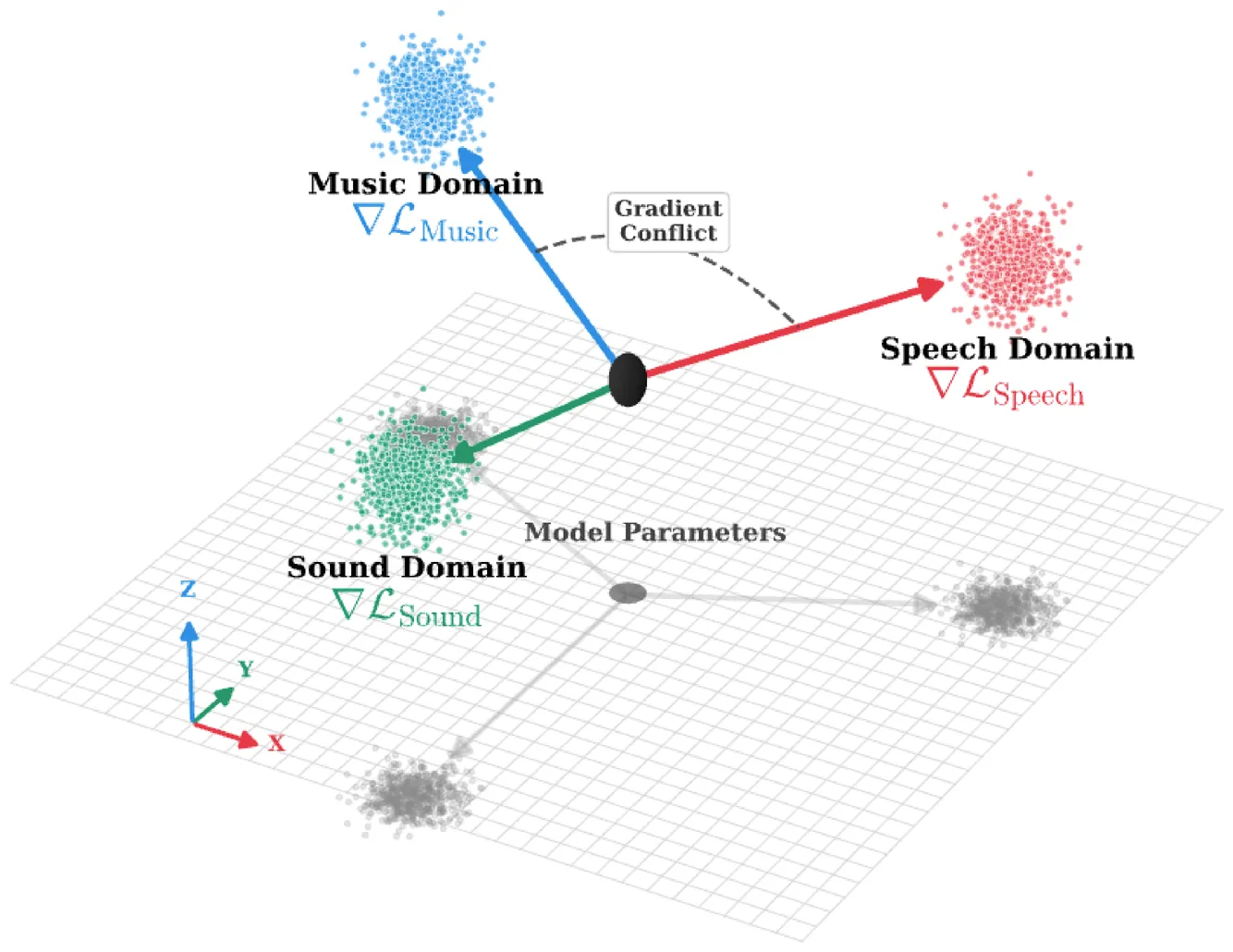
Extending the input modality of Large Language Models~(LLMs) to the audio domain is essential for achieving comprehensive multimodal perception. However, it is well-known that acoustic information is intrinsically \textit{heterogeneous}, entangling attributes such as speech, music, and environmental context. Existing research is limited to a dense, parameter-shared adapter to model these diverse patterns, which induces \textit{gradient conflict} during optimization, as parameter updates required for distinct attributes contradict each other. To address this limitation, we introduce the \textit{\textbf{MoE-Adapter}}, a sparse Mixture-of-Experts~(MoE) architecture designed to decouple acoustic information. Specifically, it employs a dynamic gating mechanism that routes audio tokens to specialized experts capturing complementary feature subspaces while retaining shared experts for global context, thereby mitigating gradient conflicts and enabling fine-grained feature learning. Comprehensive experiments show that the MoE-Adapter achieves superior performance on both audio semantic and paralinguistic tasks, consistently outperforming dense linear baselines with comparable computational costs. Furthermore, we will release the related code and models to facilitate future research.
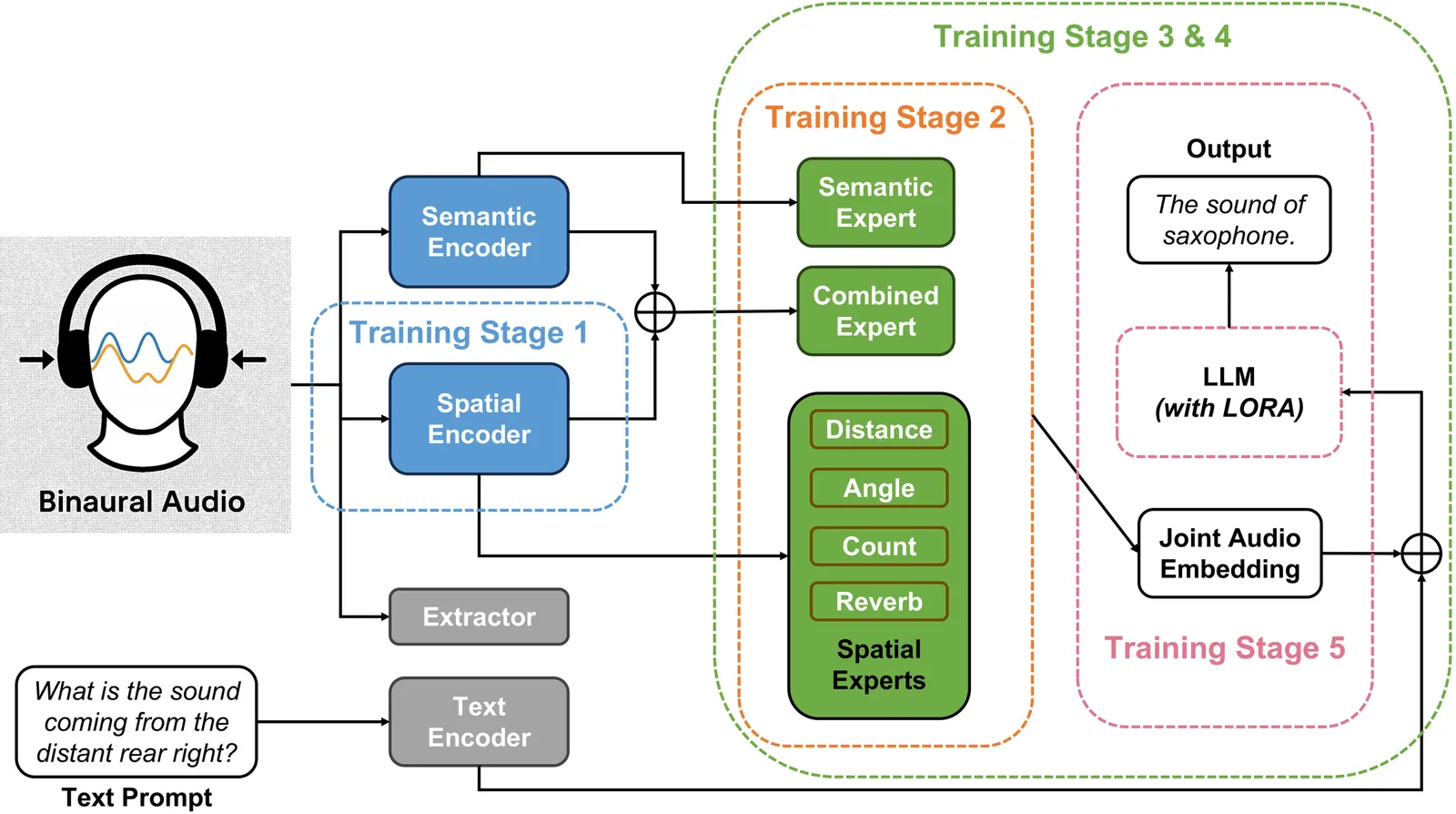
Existing large audio-language models perceive the world as "mono" -- a single stream of audio that ignores the critical spatial dimension ("where") required for universal acoustic scene analysis. To bridge this gap, we first introduce a hierarchical framework for Auditory Scene Analysis (ASA). Guided by this framework, we introduce a system that enables models like Qwen2-Audio to understand and reason about the complex acoustic world. Our framework achieves this through three core contributions: First, we build a large-scale, synthesized binaural audio dataset to provide the rich spatial cues. Second, we design a hybrid feature projector, which leverages parallel semantic and spatial encoders to extract decoupled representations. These distinct streams are integrated via a dense fusion mechanism, ensuring the model receives a holistic view of the acoustic scene. Finally, we employ a progressive training curriculum, advancing from supervised fine-tuning (SFT) to reinforcement learning via Group Relative Policy Optimization (GRPO), to explicitly evolve the model's capabilities towards reasoning. On our comprehensive benchmark, the model demonstrates comparatively strong capability for spatial understanding. By enabling this spatial perception, our work provides a clear pathway for leveraging the powerful reasoning abilities of large models towards holistic acoustic scene analysis, advancing from "mono" semantic recognition to spatial intelligence.
As audio deepfakes transition from research artifacts to widely available commercial tools, robust biometric authentication faces pressing security threats in high-stakes industries. This paper presents a systematic empirical evaluation of state-of-the-art speaker authentication systems based on a large-scale speech synthesis dataset, revealing two major security vulnerabilities: 1) modern voice cloning models trained on very small samples can easily bypass commercial speaker verification systems; and 2) anti-spoofing detectors struggle to generalize across different methods of audio synthesis, leading to a significant gap between in-domain performance and real-world robustness. These findings call for a reconsideration of security measures and stress the need for architectural innovations, adaptive defenses, and the transition towards multi-factor authentication.
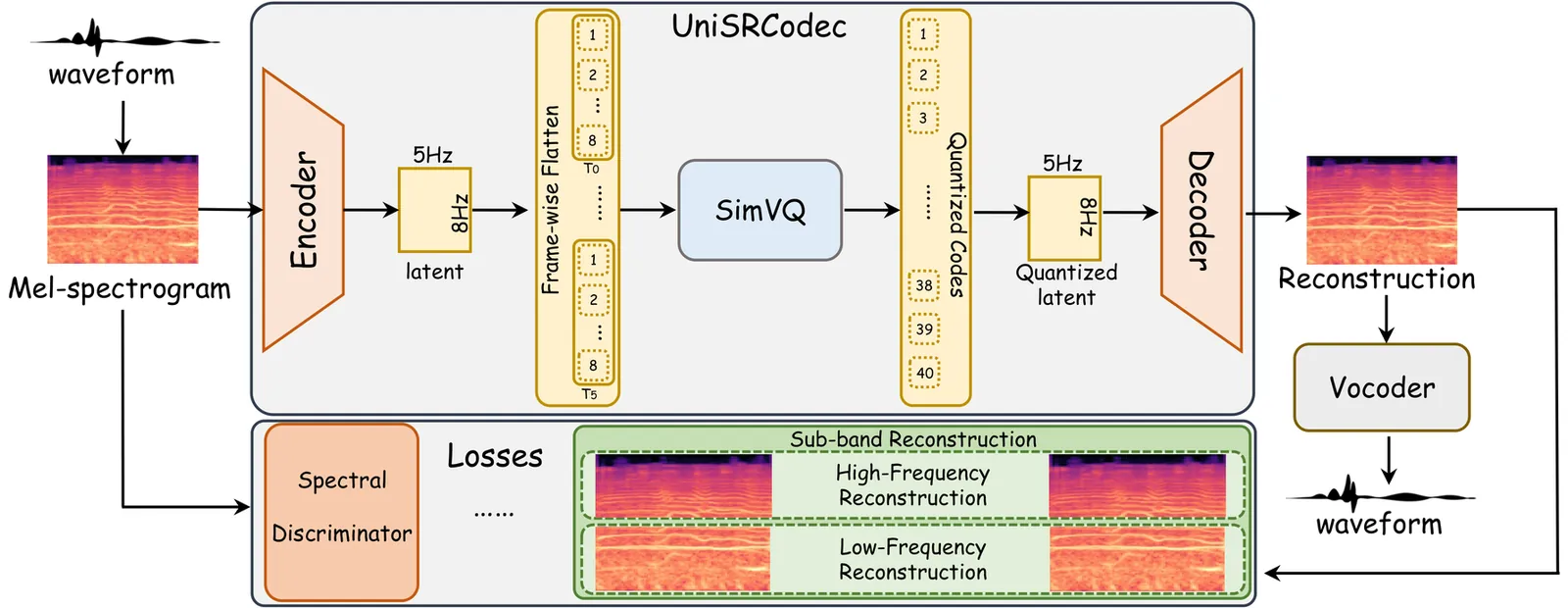
Neural Audio Codecs (NACs) can reduce transmission overhead by performing compact compression and reconstruction, which also aim to bridge the gap between continuous and discrete signals. Existing NACs can be divided into two categories: multi-codebook and single-codebook codecs. Multi-codebook codecs face challenges such as structural complexity and difficulty in adapting to downstream tasks, while single-codebook codecs, though structurally simpler, suffer from low-fidelity, ineffective modeling of unified audio, and an inability to support modeling of high-frequency audio. We propose the UniSRCodec, a single-codebook codec capable of supporting high sampling rate, low-bandwidth, high fidelity, and unified. We analyze the inefficiency of waveform-based compression and introduce the time and frequency compression method using the Mel-spectrogram, and cooperate with a Vocoder to recover the phase information of the original audio. Moreover, we propose a sub-band reconstruction technique to achieve high-quality compression across both low and high frequency bands. Subjective and objective experimental results demonstrate that UniSRCodec achieves state-of-the-art (SOTA) performance among cross-domain single-codebook codecs with only a token rate of 40, and its reconstruction quality is comparable to that of certain multi-codebook methods. Our demo page is available at https://wxzyd123.github.io/unisrcodec.
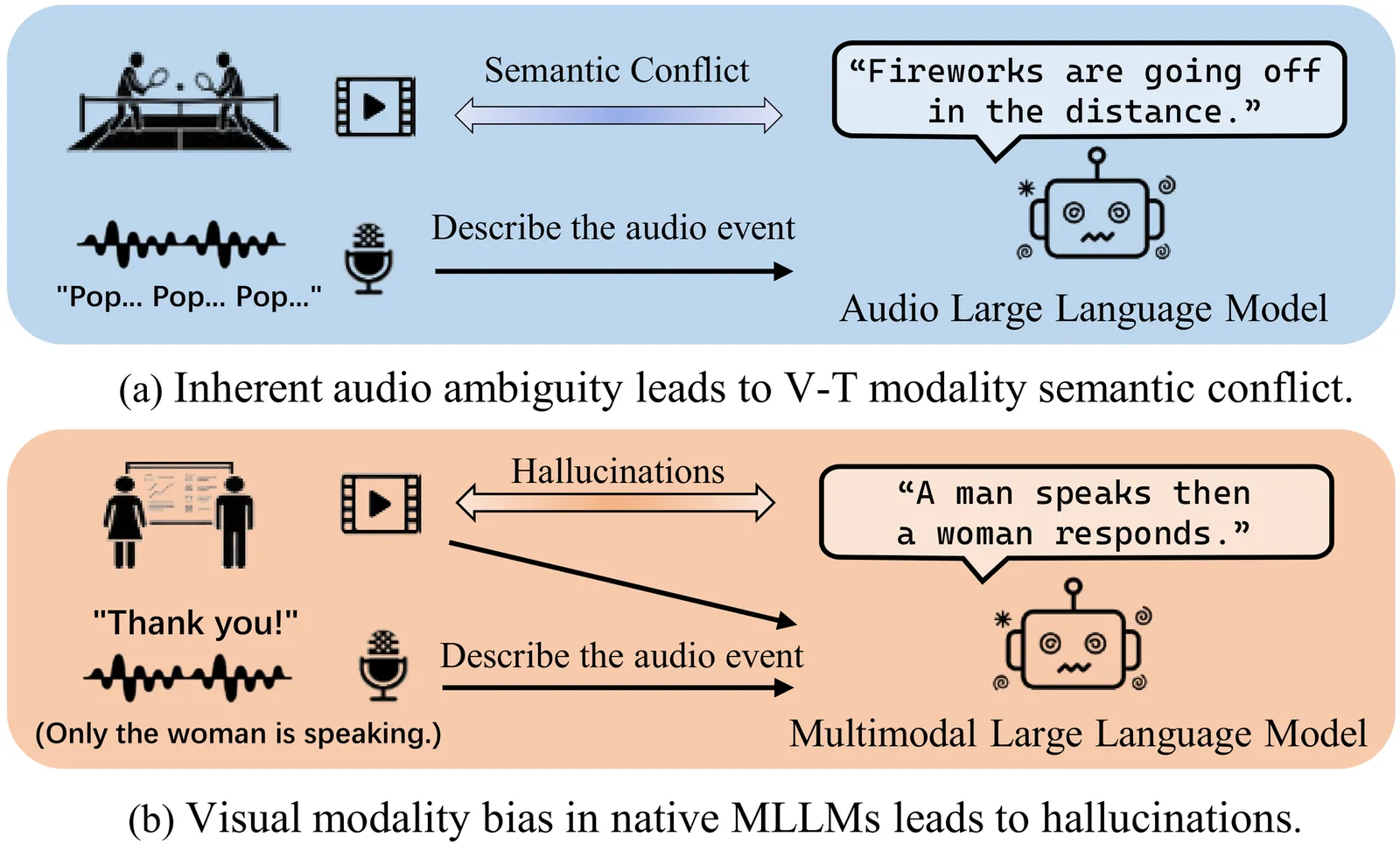
Training a unified model integrating video-to-audio (V2A), text-to-audio (T2A), and joint video-text-to-audio (VT2A) generation offers significant application flexibility, yet faces two unexplored foundational challenges: (1) the scarcity of high-quality audio captions with tight A-V-T alignment, leading to severe semantic conflict between multimodal conditions, and (2) cross-task and intra-task competition, manifesting as an adverse V2A-T2A performance trade-off and modality bias in the VT2A task. First, to address data scarcity, we introduce SoundAtlas, a large-scale dataset (470k pairs) that significantly outperforms existing benchmarks and even human experts in quality. Powered by a novel agentic pipeline, it integrates Vision-to-Language Compression to mitigate visual bias of MLLMs, a Junior-Senior Agent Handoff for a 5 times cost reduction, and rigorous Post-hoc Filtering to ensure fidelity. Consequently, SoundAtlas delivers semantically rich and temporally detailed captions with tight V-A-T alignment. Second, we propose Omni2Sound, a unified VT2A diffusion model supporting flexible input modalities. To resolve the inherent cross-task and intra-task competition, we design a three-stage multi-task progressive training schedule that converts cross-task competition into joint optimization and mitigates modality bias in the VT2A task, maintaining both audio-visual alignment and off-screen audio generation faithfulness. Finally, we construct VGGSound-Omni, a comprehensive benchmark for unified evaluation, including challenging off-screen tracks. With a standard DiT backbone, Omni2Sound achieves unified SOTA performance across all three tasks within a single model, demonstrating strong generalization across benchmarks with heterogeneous input conditions. The project page is at https://swapforward.github.io/Omni2Sound.
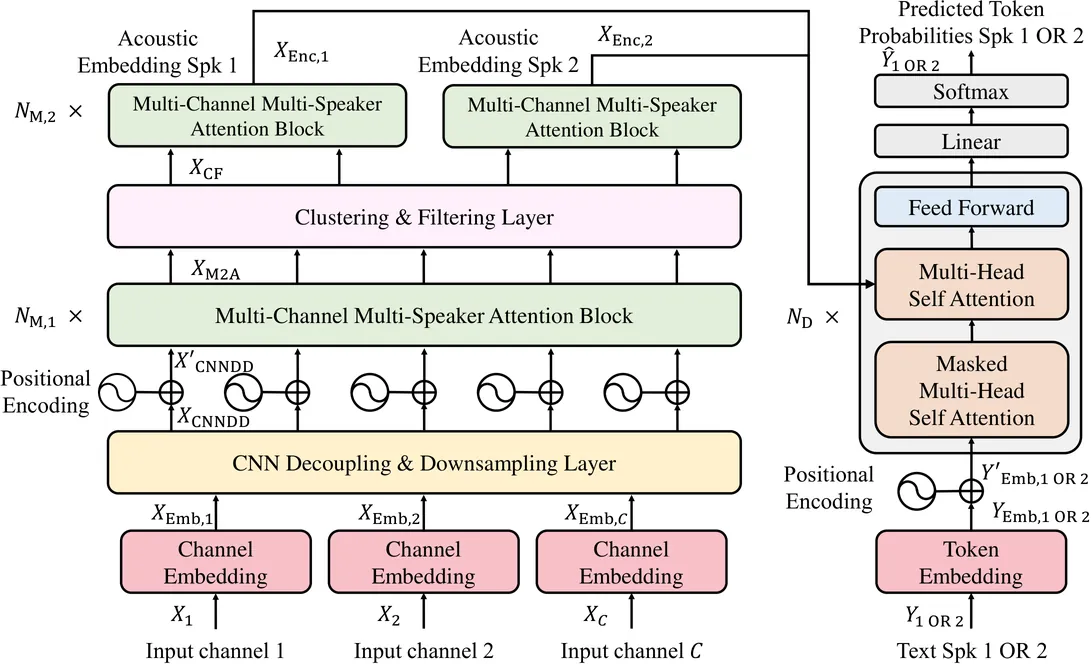
With the development of teleconferencing and in-vehicle voice assistants, far-field multi-speaker speech recognition has become a hot research topic. Recently, a multi-channel transformer (MCT) has been proposed, which demonstrates the ability of the transformer to model far-field acoustic environments. However, MCT cannot encode high-dimensional acoustic features for each speaker from mixed input audio because of the interference between speakers. Based on these, we propose the multi-channel multi-speaker transformer (M2Former) for far-field multi-speaker ASR in this paper. Experiments on the SMS-WSJ benchmark show that the M2Former outperforms the neural beamformer, MCT, dual-path RNN with transform-average-concatenate and multi-channel deep clustering based end-to-end systems by 9.2%, 14.3%, 24.9%, and 52.2% respectively, in terms of relative word error rate reduction.

Video game music (VGM) is often studied under the same lens as film music, which largely focuses on its theoretical functionality with relation to the identified genres of the media. However, till date, we are unaware of any systematic approach that analyzes the quantifiable musical features in VGM across several identified game genres. Therefore, we extracted musical features from VGM in games from three sub-genres of Role-Playing Games (RPG), and then hypothesized how different musical features are correlated to the perceptions and portrayals of each genre. This observed correlation may be used to further suggest such features are relevant to the expected storytelling elements or play mechanics associated with the sub-genre.

There is a wide variety of music similarity detection algorithms, while discussions about music plagiarism in the real world are often based on audience perceptions. Therefore, we aim to conduct a study to examine the key criteria of human perception of music plagiarism, focusing on the three commonly used musical features in similarity analysis: melody, rhythm, and chord progression. After identifying the key features and levels of variation humans use in perceiving musical similarity, we propose a LLM-as-a-judge framework that applies a systematic, step-by-step approach, drawing on modules that extract such high-level attributes.
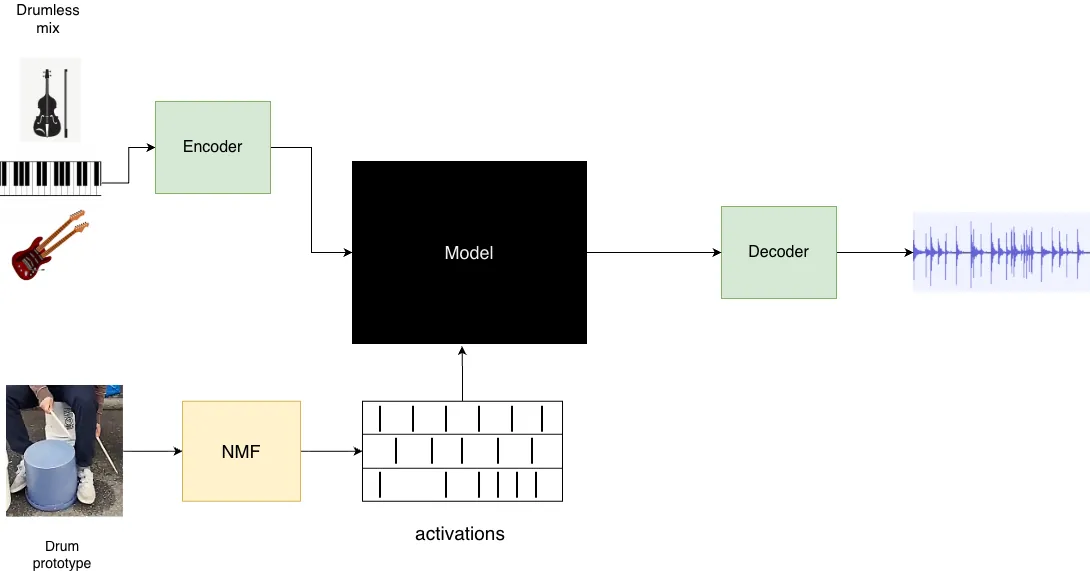
In music creation, rapid prototyping is essential for exploring and refining ideas, yet existing generative tools often fall short when users require both structural control and stylistic flexibility. Prior approaches in stem-to-stem generation can condition on other musical stems but offer limited control over rhythm, and timbre-transfer methods allow users to specify specific rhythms, but cannot condition on musical context. We introduce DARC, a generative drum accompaniment model that conditions both on musical context from other stems and explicit rhythm prompts such as beatboxing or tapping tracks. Using parameter-efficient fine-tuning, we augment STAGE, a state-of-the-art drum stem generator, with fine-grained rhythm control while maintaining musical context awareness.
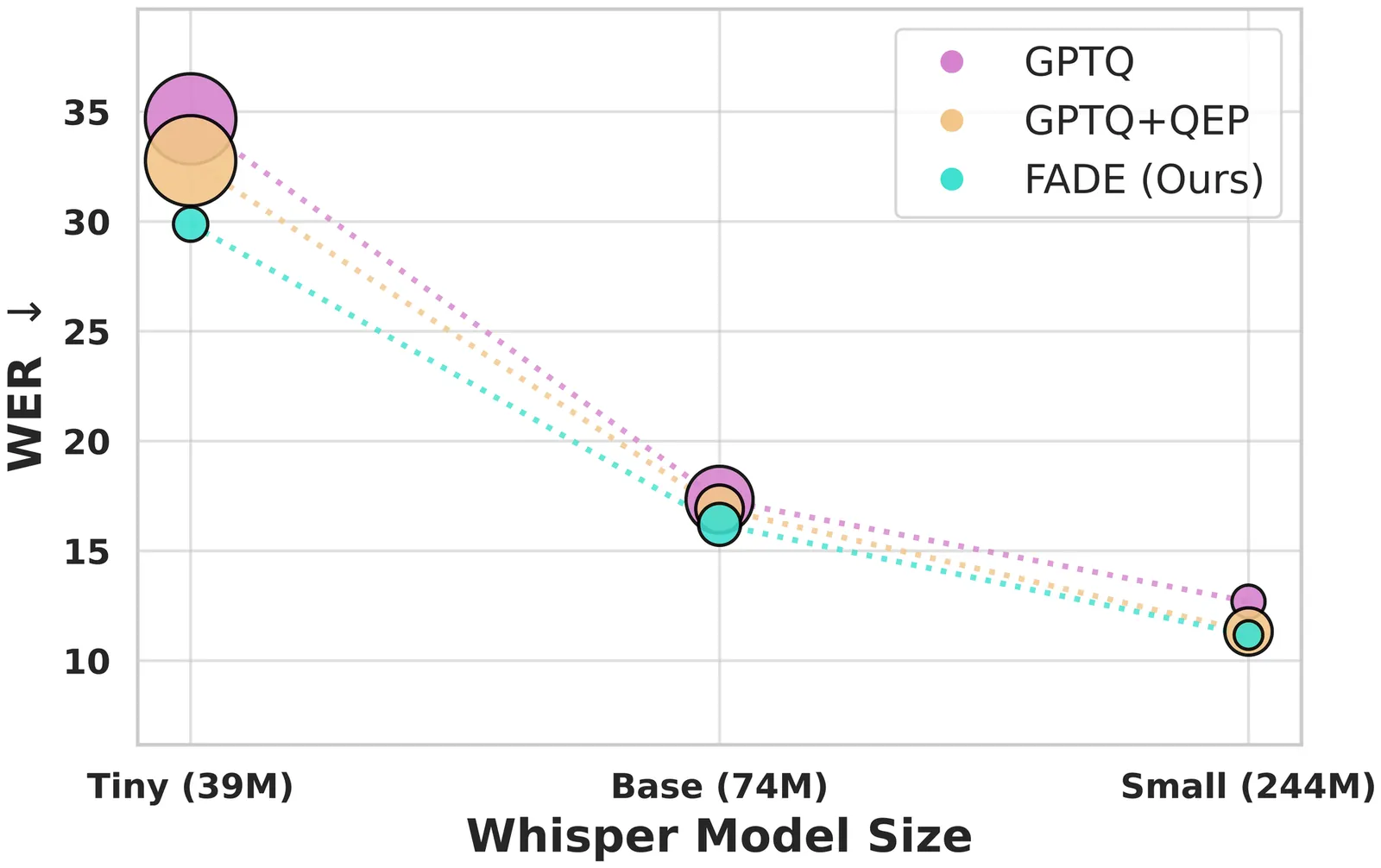
Running Automatic Speech Recognition (ASR) models on memory-constrained edge devices requires efficient compression. While layer-wise post-training quantization is effective, it suffers from error accumulation, especially in encoder-decoder architectures. Existing solutions like Quantization Error Propagation (QEP) are suboptimal for ASR due to the model's heterogeneity, processing acoustic features in the encoder while generating text in the decoder. To address this, we propose Fine-grained Alpha for Dynamic Quantization Error Propagation (FADE), which adaptively controls the trade-off between cross-layer error correction and local quantization. Experiments show that FADE significantly improves stability by reducing performance variance across runs, while simultaneously surpassing baselines in mean WER.
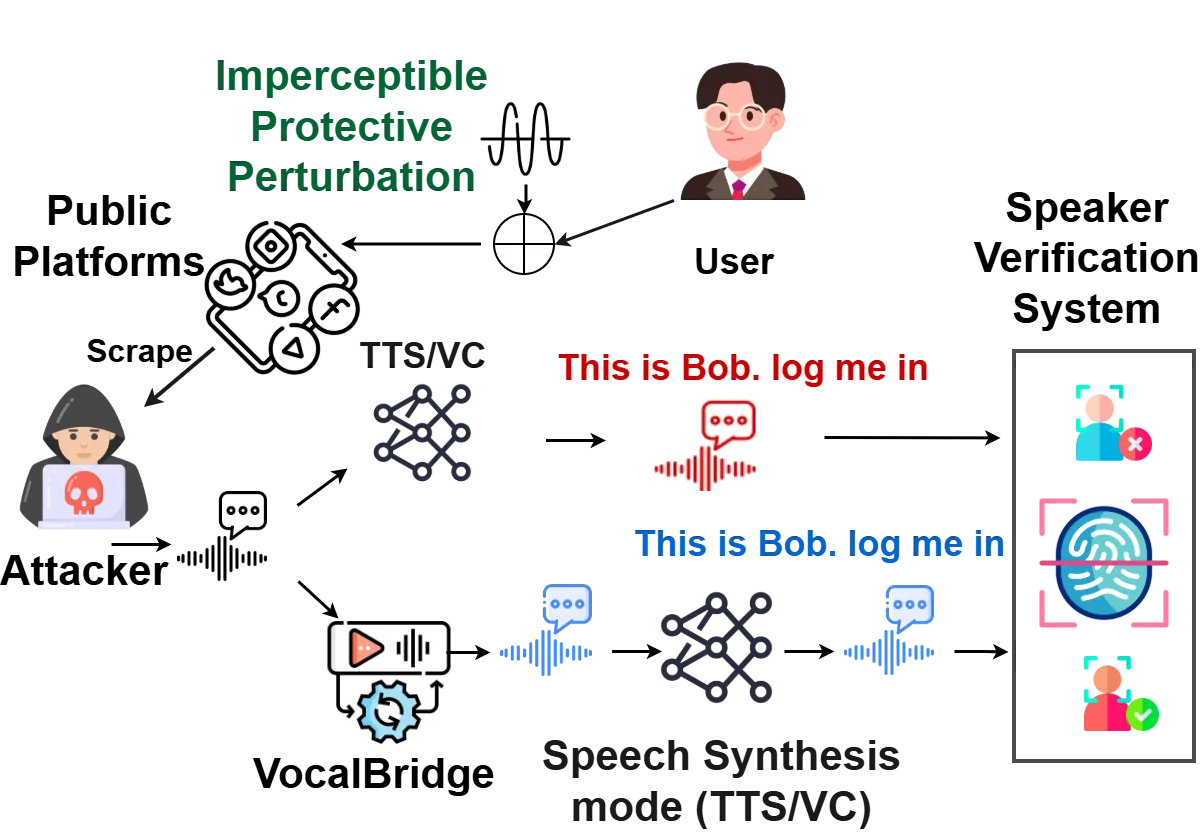
The rapid advancement of speech synthesis technologies, including text-to-speech (TTS) and voice conversion (VC), has intensified security and privacy concerns related to voice cloning. Recent defenses attempt to prevent unauthorized cloning by embedding protective perturbations into speech to obscure speaker identity while maintaining intelligibility. However, adversaries can apply advanced purification techniques to remove these perturbations, recover authentic acoustic characteristics, and regenerate cloneable voices. Despite the growing realism of such attacks, the robustness of existing defenses under adaptive purification remains insufficiently studied. Most existing purification methods are designed to counter adversarial noise in automatic speech recognition (ASR) systems rather than speaker verification or voice cloning pipelines. As a result, they fail to suppress the fine-grained acoustic cues that define speaker identity and are often ineffective against speaker verification attacks (SVA). To address these limitations, we propose Diffusion-Bridge (VocalBridge), a purification framework that learns a latent mapping from perturbed to clean speech in the EnCodec latent space. Using a time-conditioned 1D U-Net with a cosine noise schedule, the model enables efficient, transcript-free purification while preserving speaker-discriminative structure. We further introduce a Whisper-guided phoneme variant that incorporates lightweight temporal guidance without requiring ground-truth transcripts. Experimental results show that our approach consistently outperforms existing purification methods in recovering cloneable voices from protected speech. Our findings demonstrate the fragility of current perturbation-based defenses and highlight the need for more robust protection mechanisms against evolving voice-cloning and speaker verification threats.