Audio and Speech Processing
arXiv:eess.AS
Theory and methods for processing signals representing audio, speech, and language, and their applications.
Looking for a broader view? This category is part of:
Theory and methods for processing signals representing audio, speech, and language, and their applications.
Looking for a broader view? This category is part of:
Modulation effects such as phasers, flangers and chorus effects are heavily used in conjunction with the electric guitar. Machine learning based emulation of analog modulation units has been investigated in recent years, but most methods have either been limited to one class of effect or suffer from a high computational cost or latency compared to canonical digital implementations. Here, we build on previous work and present a framework for modelling flanger, chorus and phaser effects based on differentiable digital signal processing. The model is trained in the time-frequency domain, but at inference operates in the time-domain, requiring zero latency. We investigate the challenges associated with gradient-based optimisation of such effects, and show that low-frequency weighting of loss functions avoids convergence to local minima when learning delay times. We show that when trained against analog effects units, sound output from the model is in some cases perceptually indistinguishable from the reference, but challenges still remain for effects with long delay times and feedback.
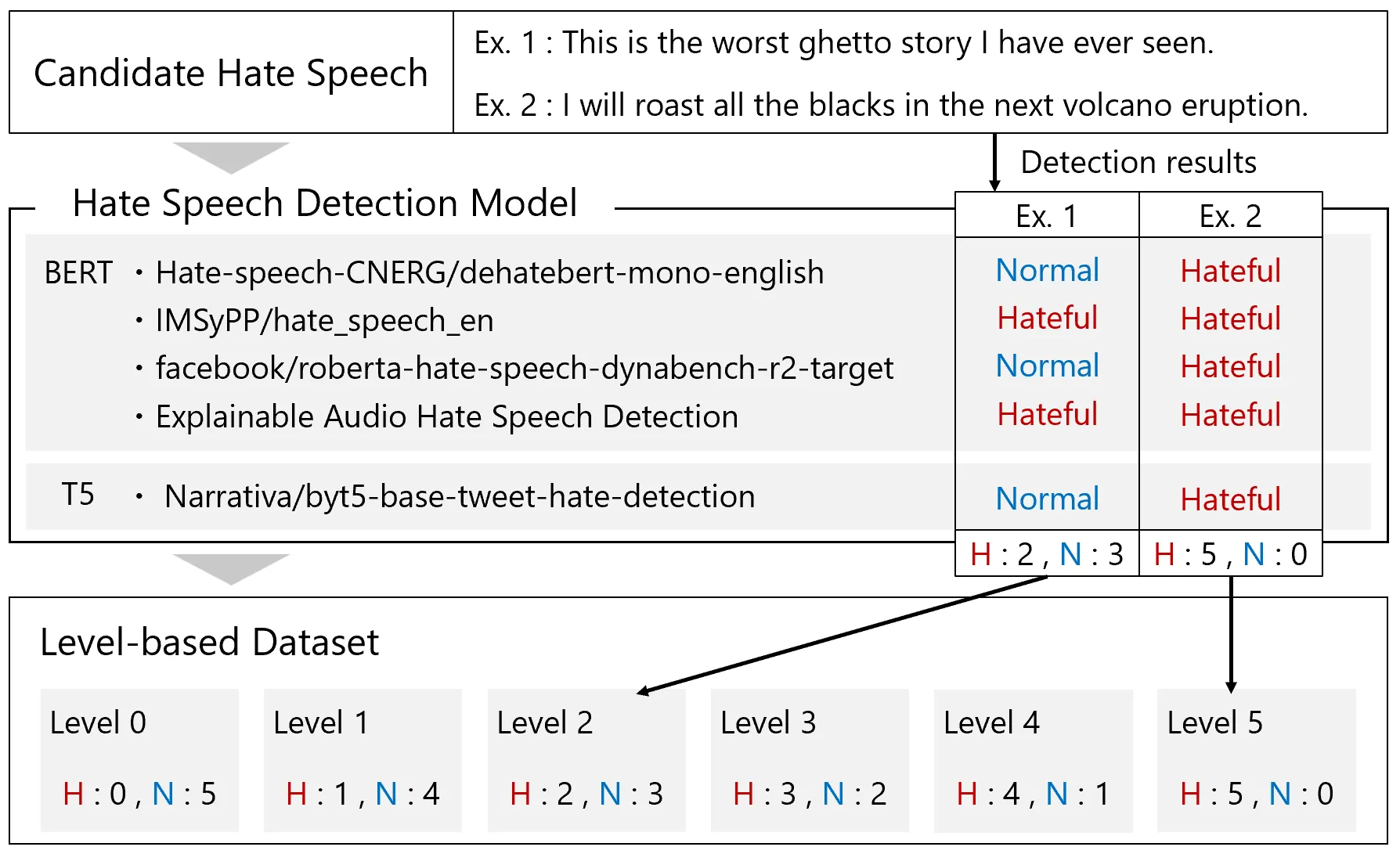
This paper proposes an automatic speech recognition (ASR) model for hate speech using large language models (LLMs). The proposed method integrates the encoder of the ASR model with the decoder of the LLMs, enabling simultaneous transcription and censorship tasks to prevent the exposure of harmful content. Instruction tuning of the LLM to mask hate-related words with specific tokens requires an annotated hate speech dataset, which is limited. We generate text samples using an LLM with the Chain-of-Thought (CoT) prompting technique guided by cultural context and examples and then convert them into speech samples using a text-to-speech (TTS) system. However, some of them contain non-hate speech samples with hate-related words, which degrades the censorship performance. This paper filters the samples which text classification models correctly label as hate content. By adjusting the threshold for the number of correct answer models, we can control the level of hate in the generated dataset, allowing us to train the LLMs through curriculum learning in a gradual manner. Experimental results show that the proposed method achieves a masking accuracy of 58.6\% for hate-related words, surpassing previous baselines. We also confirm that the curriculum training contributes to the efficiency of both transcription and censorship tasks.
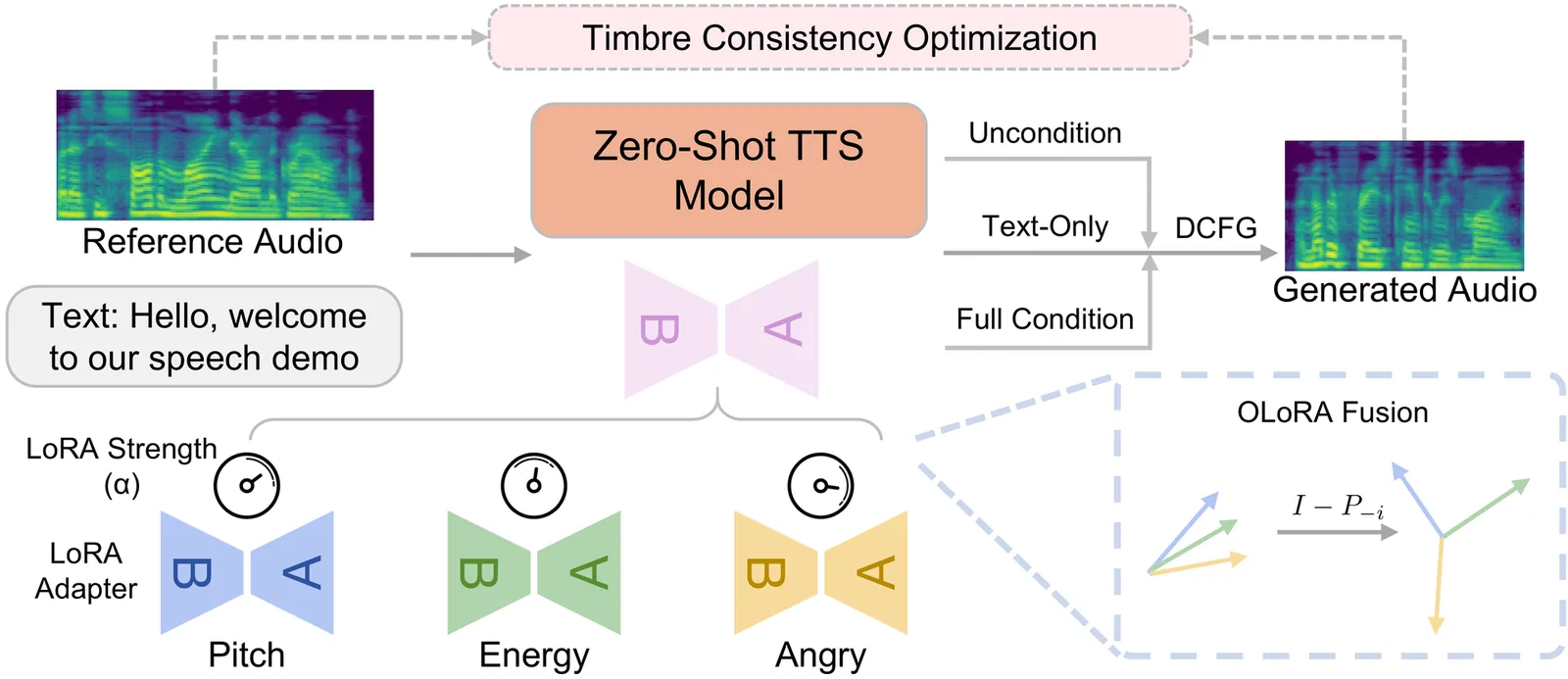
Zero-shot text-to-speech models can clone a speaker's timbre from a short reference audio, but they also strongly inherit the speaking style present in the reference. As a result, synthesizing speech with a desired style often requires carefully selecting reference audio, which is impractical when only limited or mismatched references are available. While recent controllable TTS methods attempt to address this issue, they typically rely on absolute style targets and discrete textual prompts, and therefore do not support continuous and reference-relative style control. We propose ReStyle-TTS, a framework that enables continuous and reference-relative style control in zero-shot TTS. Our key insight is that effective style control requires first reducing the model's implicit dependence on reference style before introducing explicit control mechanisms. To this end, we introduce Decoupled Classifier-Free Guidance (DCFG), which independently controls text and reference guidance, reducing reliance on reference style while preserving text fidelity. On top of this, we apply style-specific LoRAs together with Orthogonal LoRA Fusion to enable continuous and disentangled multi-attribute control, and introduce a Timbre Consistency Optimization module to mitigate timbre drift caused by weakened reference guidance. Experiments show that ReStyle-TTS enables user-friendly, continuous, and relative control over pitch, energy, and multiple emotions while maintaining intelligibility and speaker timbre, and performs robustly in challenging mismatched reference-target style scenarios.
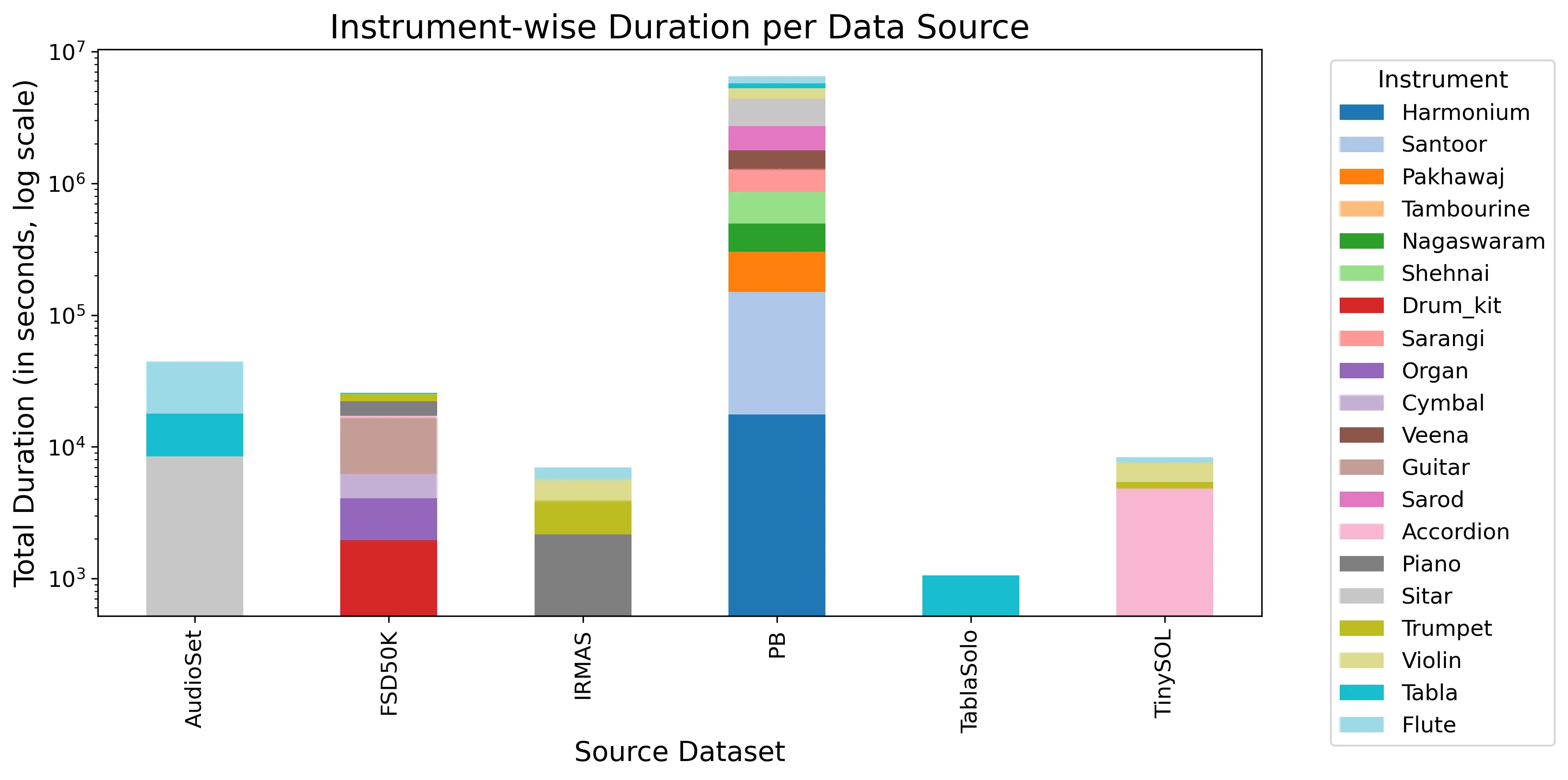
Supervised machine learning frameworks rely on extensive labeled datasets for robust performance on real-world tasks. However, there is a lack of large annotated datasets in audio and music domains, as annotating such recordings is resource-intensive, laborious, and often require expert domain knowledge. In this work, we explore the use of label propagation (LP), a graph-based semi-supervised learning technique, for automatically labeling the unlabeled set in an unsupervised manner. By constructing a similarity graph over audio embeddings, we propagate limited label information from a small annotated subset to a larger unlabeled corpus in a transductive, semi-supervised setting. We apply this method to two tasks in Indian Art Music (IAM): Raga identification and Instrument classification. For both these tasks, we integrate multiple public datasets along with additional recordings we acquire from Prasar Bharati Archives to perform LP. Our experiments demonstrate that LP significantly reduces labeling overhead and produces higher-quality annotations compared to conventional baseline methods, including those based on pretrained inductive models. These results highlight the potential of graph-based semi-supervised learning to democratize data annotation and accelerate progress in music information retrieval.
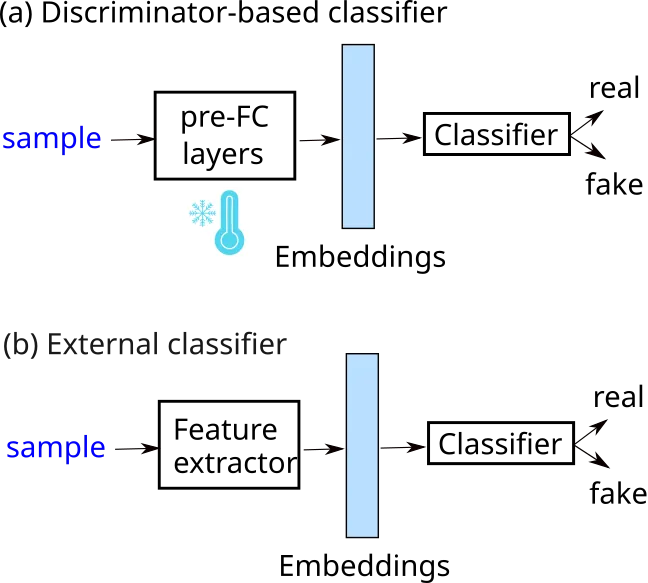
Generative adversarial networks (GANs) and diffusion models have recently achieved state-of-the-art performance in audio super-resolution (ADSR), producing perceptually convincing wideband audio from narrowband inputs. However, existing evaluations primarily rely on signal-level or perceptual metrics, leaving open the question of how closely the distributions of synthetic super-resolved and real wideband audio match. Here we address this problem by analyzing the separability of real and super-resolved audio in various embedding spaces. We consider both middle-band ($4\to 16$~kHz) and full-band ($16\to 48$~kHz) upsampling tasks for speech and music, training linear classifiers to distinguish real from synthetic samples based on multiple types of audio embeddings. Comparisons with objective metrics and subjective listening tests reveal that embedding-based classifiers achieve near-perfect separation, even when the generated audio attains high perceptual quality and state-of-the-art metric scores. This behavior is consistent across datasets and models, including recent diffusion-based approaches, highlighting a persistent gap between perceptual quality and true distributional fidelity in ADSR models.

Modeling fine-grained speaking styles remains challenging for language-speech representation pre-training, as existing speech-text models are typically trained with coarse captions or task-specific supervision, and scalable fine-grained style annotations are unavailable. We present FCaps, a large-scale dataset with fine-grained free-text style descriptions, encompassing 47k hours of speech and 19M fine-grained captions annotated via a novel end-to-end pipeline that directly grounds detailed captions in audio, thereby avoiding the error propagation caused by LLM-based rewriting in existing cascaded pipelines. Evaluations using LLM-as-a-judge demonstrate that our annotations surpass existing cascaded annotations in terms of correctness, coverage, and naturalness. Building on FCaps, we propose CLSP, a contrastive language-speech pre-trained model that integrates global and fine-grained supervision, enabling unified representations across multiple granularities. Extensive experiments demonstrate that CLSP learns fine-grained and multi-granular speech-text representations that perform reliably across global and fine-grained speech-text retrieval, zero-shot paralinguistic classification, and speech style similarity scoring, with strong alignment to human judgments. All resources will be made publicly available.
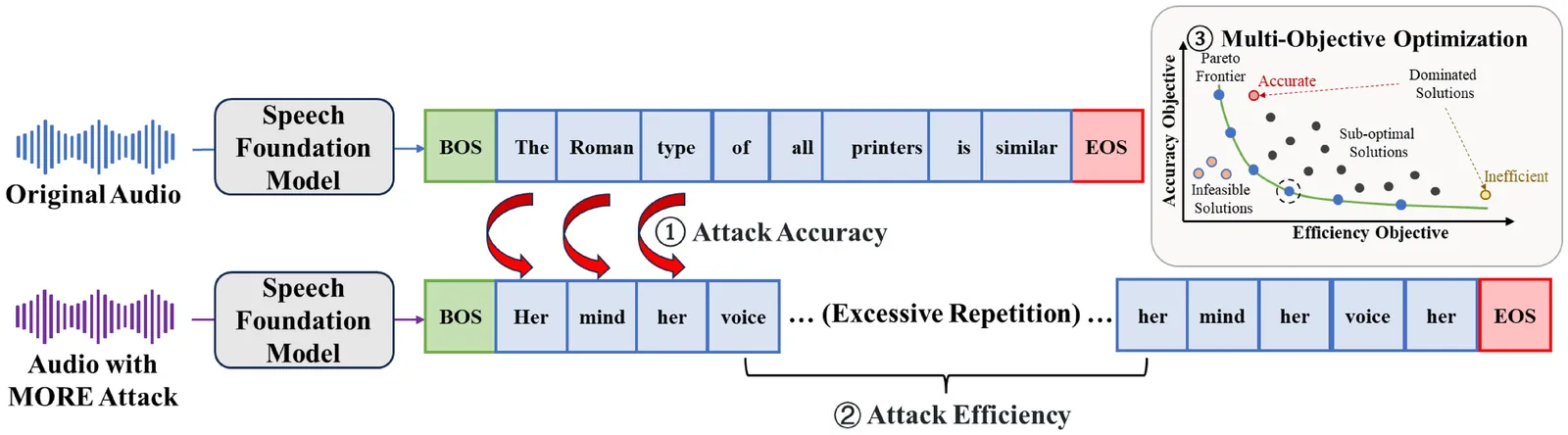
The emergence of large-scale automatic speech recognition (ASR) models such as Whisper has greatly expanded their adoption across diverse real-world applications. Ensuring robustness against even minor input perturbations is therefore critical for maintaining reliable performance in real-time environments. While prior work has mainly examined accuracy degradation under adversarial attacks, robustness with respect to efficiency remains largely unexplored. This narrow focus provides only a partial understanding of ASR model vulnerabilities. To address this gap, we conduct a comprehensive study of ASR robustness under multiple attack scenarios. We introduce MORE, a multi-objective repetitive doubling encouragement attack, which jointly degrades recognition accuracy and inference efficiency through a hierarchical staged repulsion-anchoring mechanism. Specifically, we reformulate multi-objective adversarial optimization into a hierarchical framework that sequentially achieves the dual objectives. To further amplify effectiveness, we propose a novel repetitive encouragement doubling objective (REDO) that induces duplicative text generation by maintaining accuracy degradation and periodically doubling the predicted sequence length. Overall, MORE compels ASR models to produce incorrect transcriptions at a substantially higher computational cost, triggered by a single adversarial input. Experiments show that MORE consistently yields significantly longer transcriptions while maintaining high word error rates compared to existing baselines, underscoring its effectiveness in multi-objective adversarial attack.
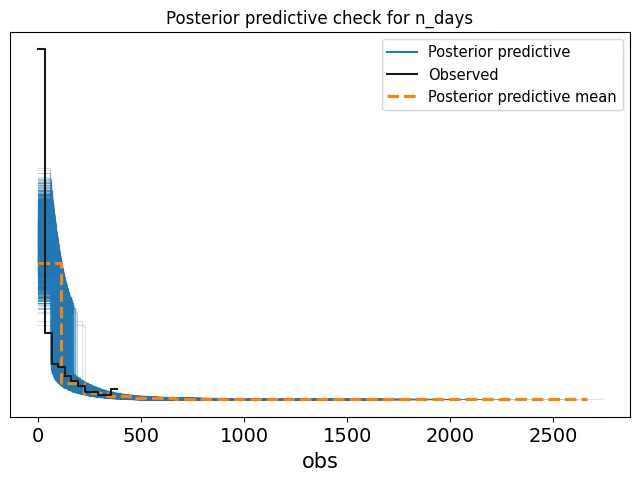
Afrobeats songs compete for attention on streaming platforms, where chart visibility can influence both revenue and cultural impact. This paper examines whether collaborations help songs remain on the charts longer, using daily Nigeria Spotify Top 200 data from 2024. Each track is summarized by the number of days it appears in the Top 200 during the year and its total annual streams in Nigeria. A Bayesian negative binomial regression is applied, with days on chart as the outcome and collaboration status (solo versus multi-artist) and log total streams as predictors. This approach is well suited for overdispersed count data and allows the effect of collaboration to be interpreted while controlling for overall popularity. Posterior inference is conducted using Markov chain Monte Carlo, and results are assessed using rate ratios, posterior probabilities, and predictive checks. The findings indicate that, after accounting for total streams, collaboration tracks tend to spend slightly fewer days on the chart than comparable solo tracks.
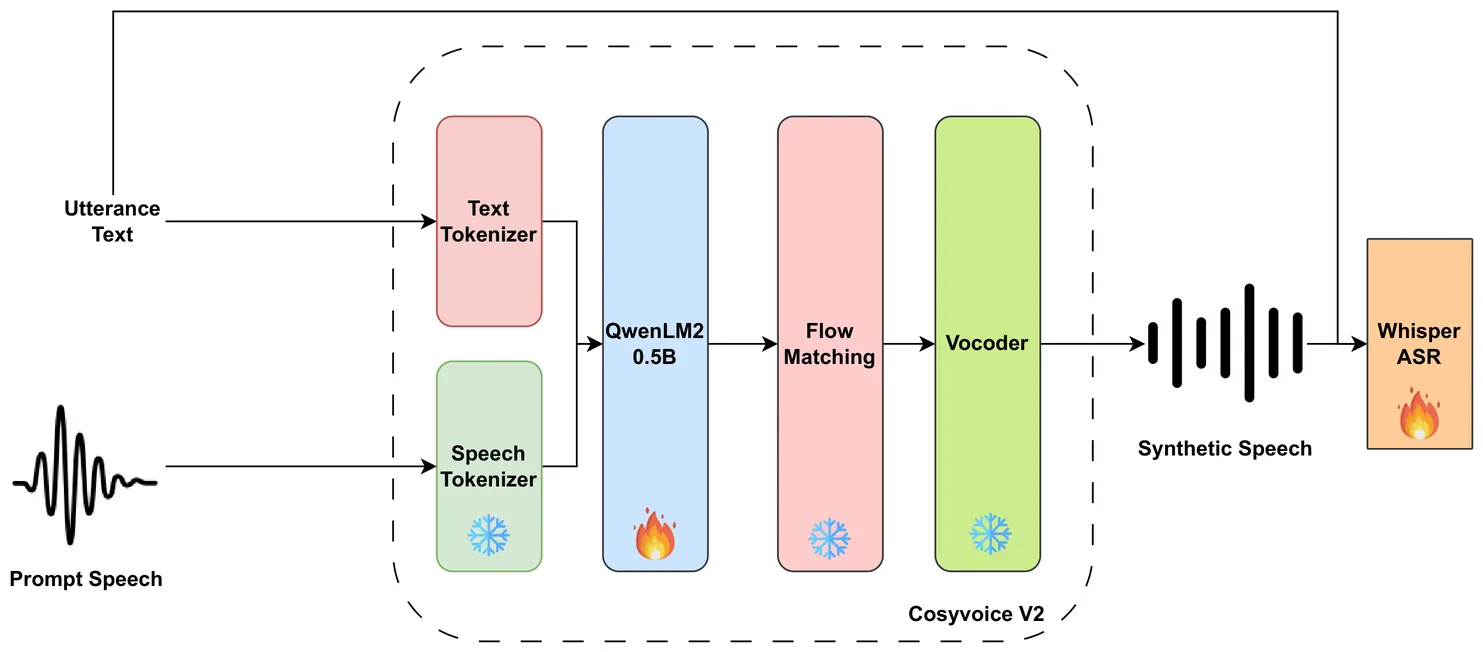
Automatic speech recognition (ASR) for conversational code-switching speech remains challenging due to the scarcity of realistic, high-quality labeled speech data. This paper explores multilingual text-to-speech (TTS) models as an effective data augmentation technique to address this shortage. Specifically, we fine-tune the multilingual CosyVoice2 TTS model on the SEAME dataset to generate synthetic conversational Chinese-English code-switching speech, significantly increasing the quantity and speaker diversity of available training data. Our experiments demonstrate that augmenting real speech with synthetic speech reduces the mixed error rate (MER) from 12.1 percent to 10.1 percent on DevMan and from 17.8 percent to 16.0 percent on DevSGE, indicating consistent performance gains. These results confirm that multilingual TTS is an effective and practical tool for enhancing ASR robustness in low-resource conversational code-switching scenarios.

Despite being the best known objective for learning speech representations, the HuBERT objective has not been further developed and improved. We argue that it is the lack of an underlying principle that stalls the development, and, in this paper, we show that predictive coding under a variational view is the principle behind the HuBERT objective. Due to its generality, our formulation provides opportunities to improve parameterization and optimization, and we show two simple modifications that bring immediate improvements to the HuBERT objective. In addition, the predictive coding formulation has tight connections to various other objectives, such as APC, CPC, wav2vec, and BEST-RQ. Empirically, the improvement in pre-training brings significant improvements to four downstream tasks: phone classification, f0 tracking, speaker recognition, and automatic speech recognition, highlighting the importance of the predictive coding interpretation.
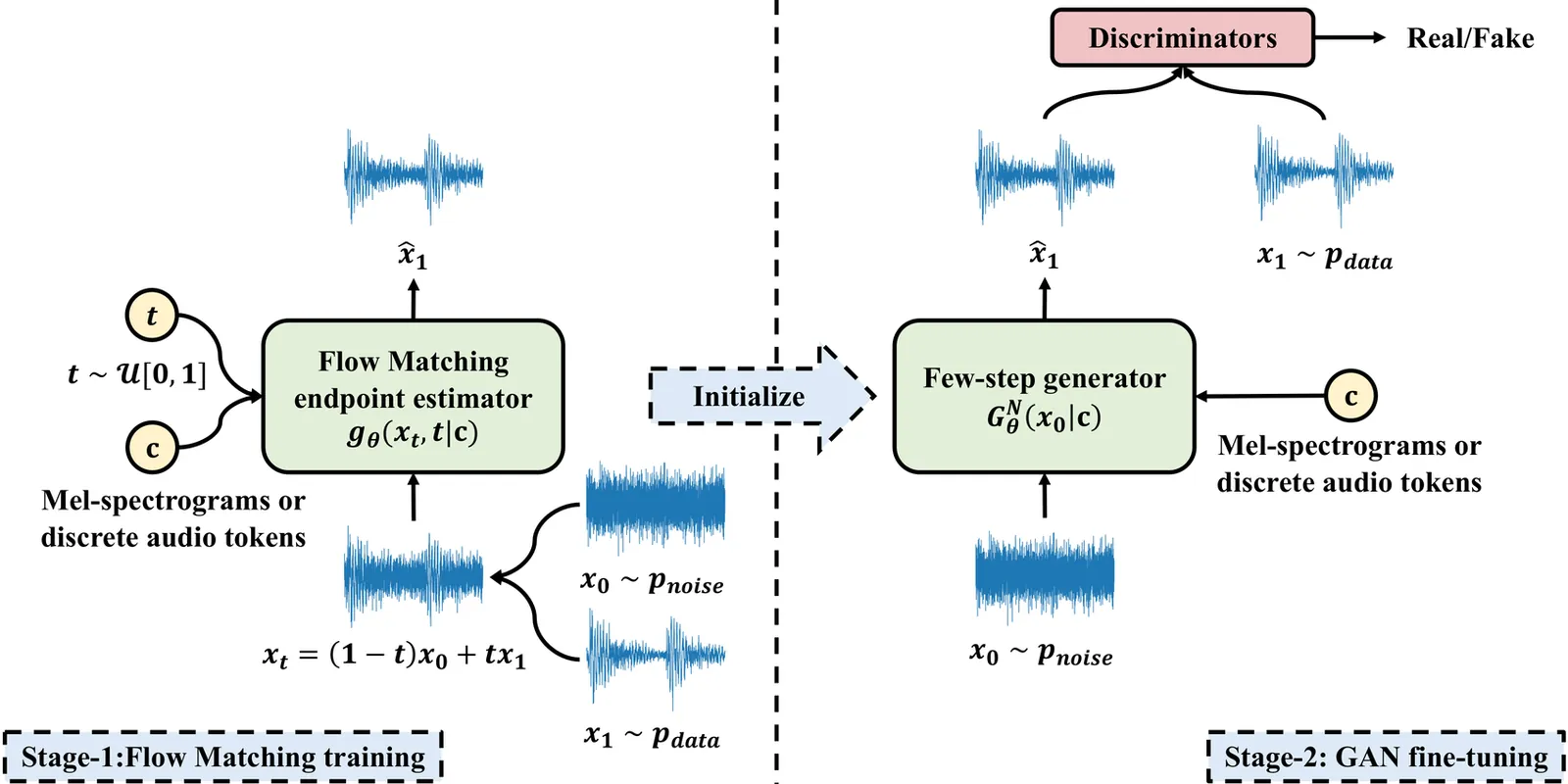
Existing dominant methods for audio generation include Generative Adversarial Networks (GANs) and diffusion-based methods like Flow Matching. GANs suffer from slow convergence and potential mode collapse during training, while diffusion methods require multi-step inference that introduces considerable computational overhead. In this work, we introduce Flow2GAN, a two-stage framework that combines Flow Matching training for learning generative capabilities with GAN fine-tuning for efficient few-step inference. Specifically, given audio's unique properties, we first improve Flow Matching for audio modeling through: 1) reformulating the objective as endpoint estimation, avoiding velocity estimation difficulties when involving empty regions; 2) applying spectral energy-based loss scaling to emphasize perceptually salient quieter regions. Building on these Flow Matching adaptations, we demonstrate that a further stage of lightweight GAN fine-tuning enables us to obtain one-step generator that produces high-quality audio. In addition, we develop a multi-branch network architecture that processes Fourier coefficients at different time-frequency resolutions, which improves the modeling capabilities compared to prior single-resolution designs. Experimental results indicate that our Flow2GAN delivers high-fidelity audio generation from Mel-spectrograms or discrete audio tokens, achieving better quality-efficiency trade-offs than existing state-of-the-art GAN-based and Flow Matching-based methods. Online demo samples are available at https://flow2gan.github.io, and the source code is released at https://github.com/k2-fsa/Flow2GAN.
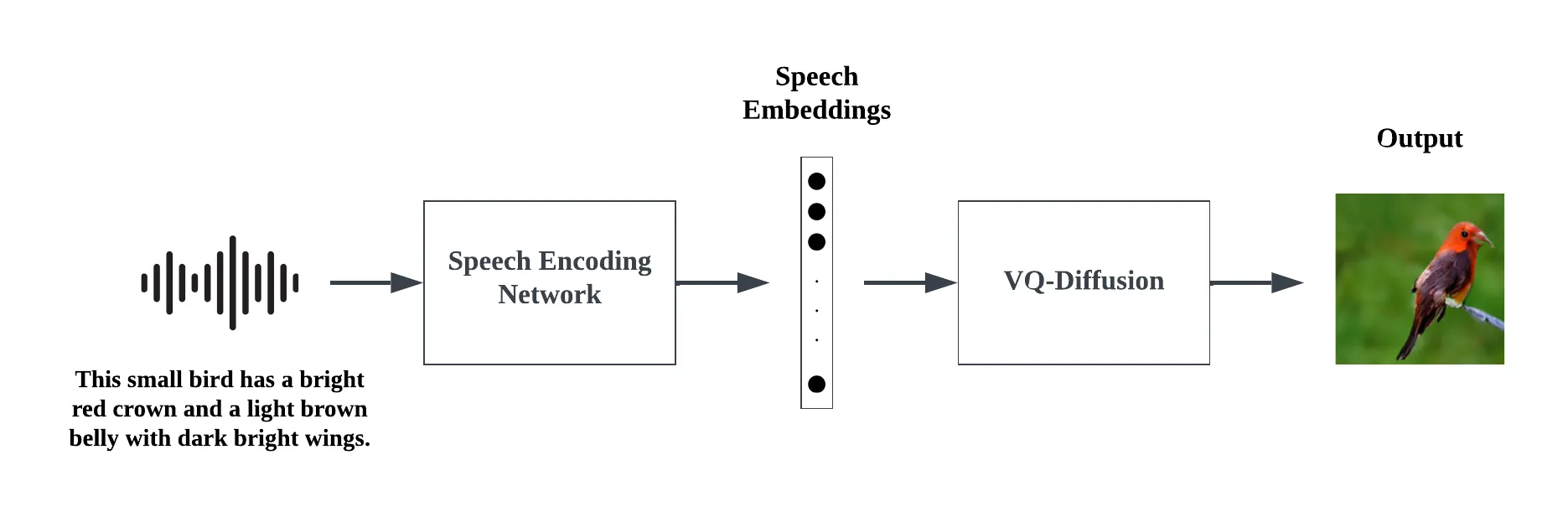
Direct speech-to-image generation has recently shown promising results. However, compared to text-to-image generation, there is still a large gap to enclose. Current approaches use two stages to tackle this task: speech encoding network and image generative adversarial network (GAN). The speech encoding networks in these approaches produce embeddings that do not capture sufficient linguistic information to semantically represent the input speech. GANs suffer from issues such as non-convergence, mode collapse, and diminished gradient, which result in unstable model parameters, limited sample diversity, and ineffective generator learning, respectively. To address these weaknesses, we introduce a framework called \textbf{Speak the Art (STA)} which consists of a speech encoding network and a VQ-Diffusion network conditioned on speech embeddings. To improve speech embeddings, the speech encoding network is supervised by a large pre-trained image-text model during training. Replacing GANs with diffusion leads to more stable training and the generation of diverse images. Additionally, we investigate the feasibility of extending our framework to be multilingual. As a proof of concept, we trained our framework with two languages: English and Arabic. Finally, we show that our results surpass state-of-the-art models by a large margin.
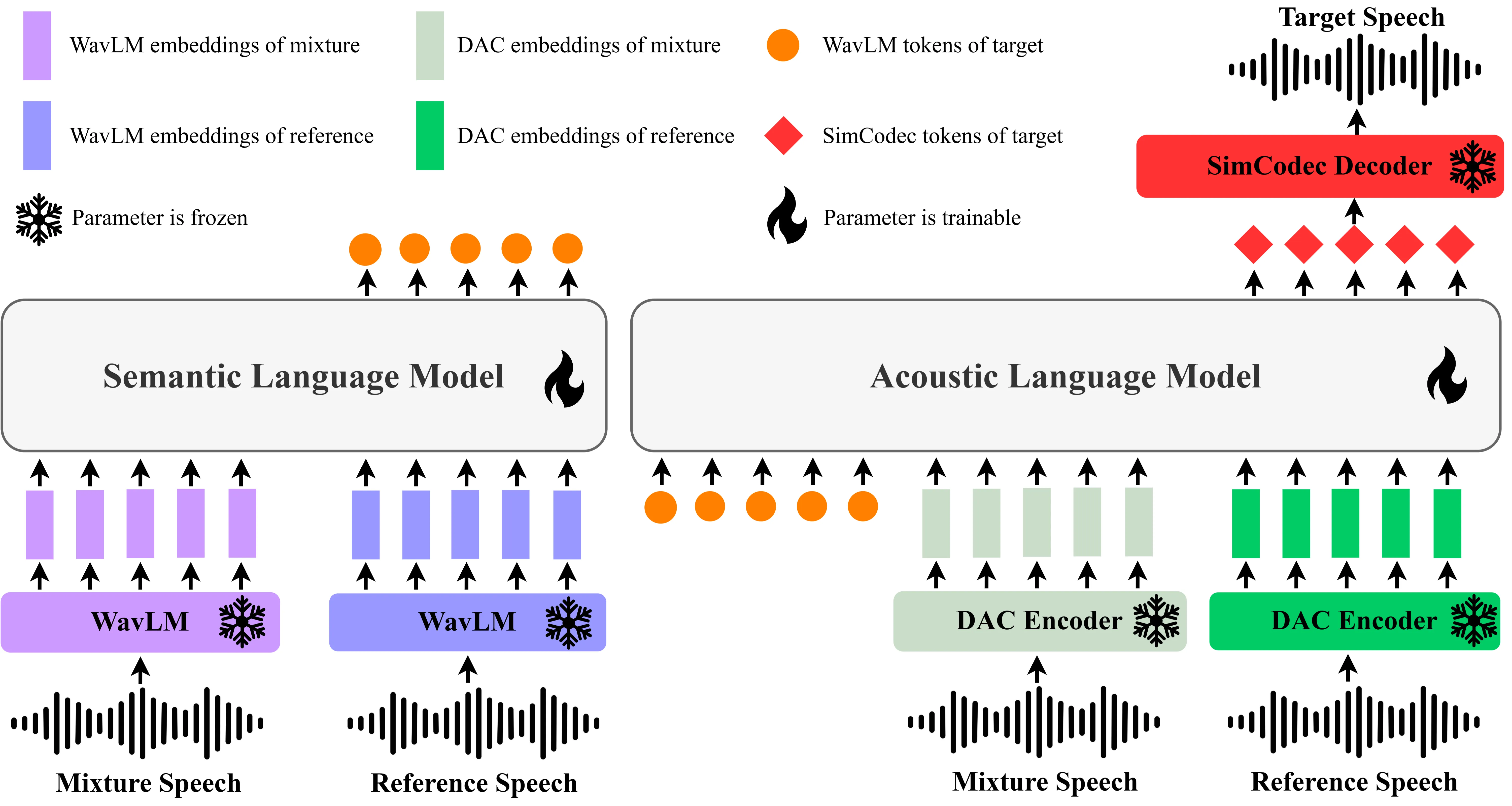
Language Model (LM)-based generative modeling has emerged as a promising direction for TSE, offering potential for improved generalization and high-fidelity speech. We present GenTSE, a two-stage decoder-only generative LM approach for TSE: Stage-1 predicts coarse semantic tokens, and Stage-2 generates fine acoustic tokens. Separating semantics and acoustics stabilizes decoding and yields more faithful, content-aligned target speech. Both stages use continuous SSL or codec embeddings, offering richer context than discretized-prompt methods. To reduce exposure bias, we employ a Frozen-LM Conditioning training strategy that conditions the LMs on predicted tokens from earlier checkpoints to reduce the gap between teacher-forcing training and autoregressive inference. We further employ DPO to better align outputs with human perceptual preferences. Experiments on Libri2Mix show that GenTSE surpasses previous LM-based systems in speech quality, intelligibility, and speaker consistency.

Many existing audio processing and generation models rely on task-specific architectures, resulting in fragmented development efforts and limited extensibility. It is therefore promising to design a unified framework capable of handling multiple tasks, while providing robust instruction and audio understanding and high-quality audio generation. This requires a compatible paradigm design, a powerful backbone, and a high-fidelity audio reconstruction module. To meet these requirements, this technical report introduces QuarkAudio, a decoder-only autoregressive (AR) LM-based generative framework that unifies multiple tasks. The framework includes a unified discrete audio tokenizer, H-Codec, which incorporates self-supervised learning (SSL) representations into the tokenization and reconstruction process. We further propose several improvements to H-Codec, such as a dynamic frame-rate mechanism and extending the audio sampling rate to 48 kHz. QuarkAudio unifies tasks by using task-specific conditional information as the conditioning sequence of the decoder-only LM, and predicting discrete target audio tokens in an AR manner. The framework supports a wide range of audio processing and generation tasks, including speech restoration (SR), target speaker extraction (TSE), speech separation (SS), voice conversion (VC), and language-queried audio source separation (LASS). In addition, we extend downstream tasks to universal free-form audio editing guided by natural language instructions (including speech semantic editing and audio event editing). Experimental results show that H-Codec achieves high-quality audio reconstruction with a low frame rate, improving both the efficiency and performance of downstream audio generation, and that QuarkAudio delivers competitive or comparable performance to state-of-the-art task-specific or multi-task systems across multiple tasks.
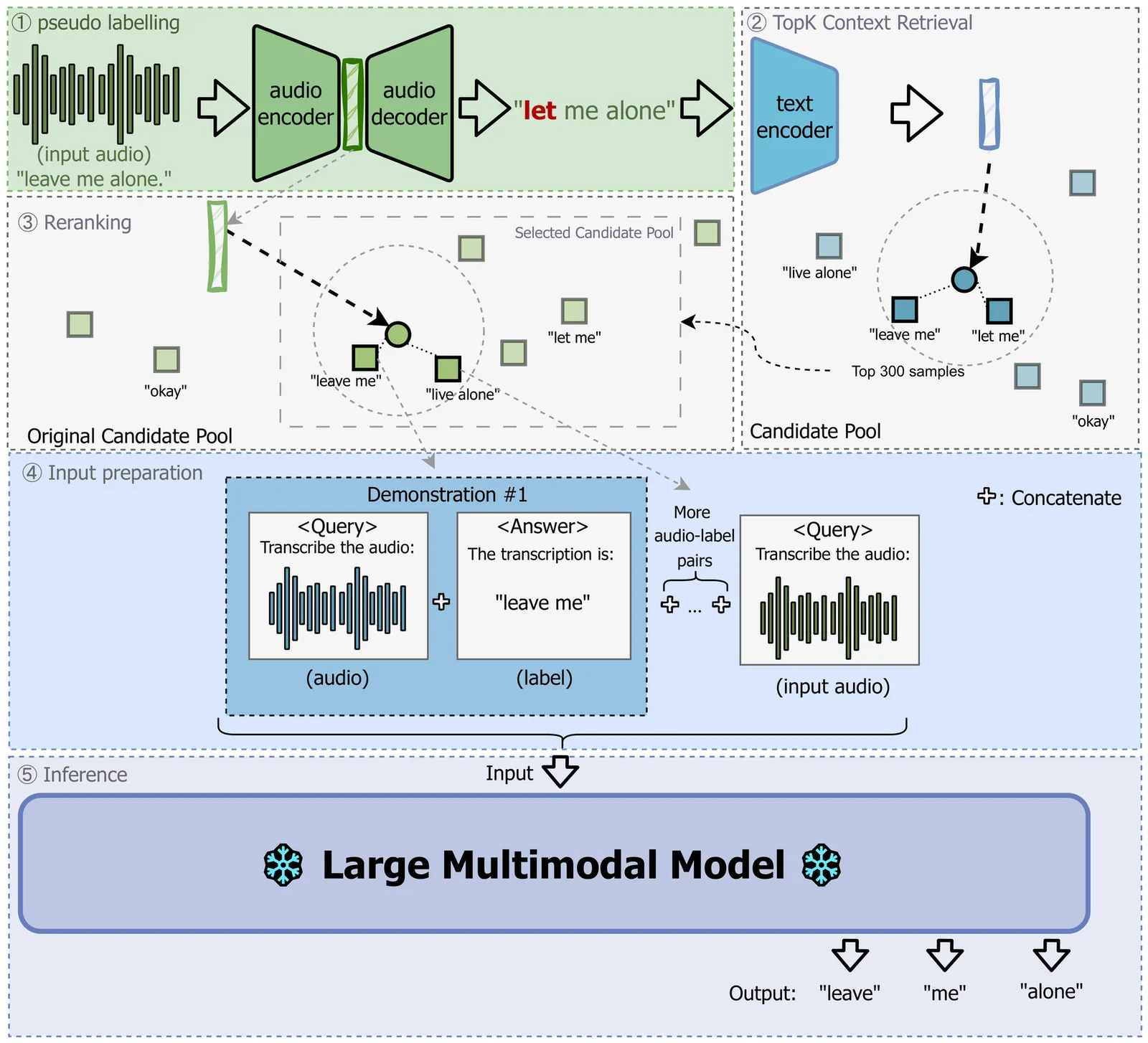
Children's speech recognition remains challenging due to substantial acoustic and linguistic variability, limited labeled data, and significant differences from adult speech. Speech foundation models can address these challenges through Speech In-Context Learning (SICL), allowing adaptation to new domains without fine-tuning. However, the effectiveness of SICL depends on how in-context examples are selected. We extend an existing retrieval-based method, Text-Embedding KNN for SICL (TICL), introducing an acoustic reranking step to create TICL+. This extension prioritizes examples that are both semantically and acoustically aligned with the test input. Experiments on four children's speech corpora show that TICL+ achieves up to a 53.3% relative word error rate reduction over zero-shot performance and 37.6% over baseline TICL, highlighting the value of combining semantic and acoustic information for robust, scalable ASR in children's speech.
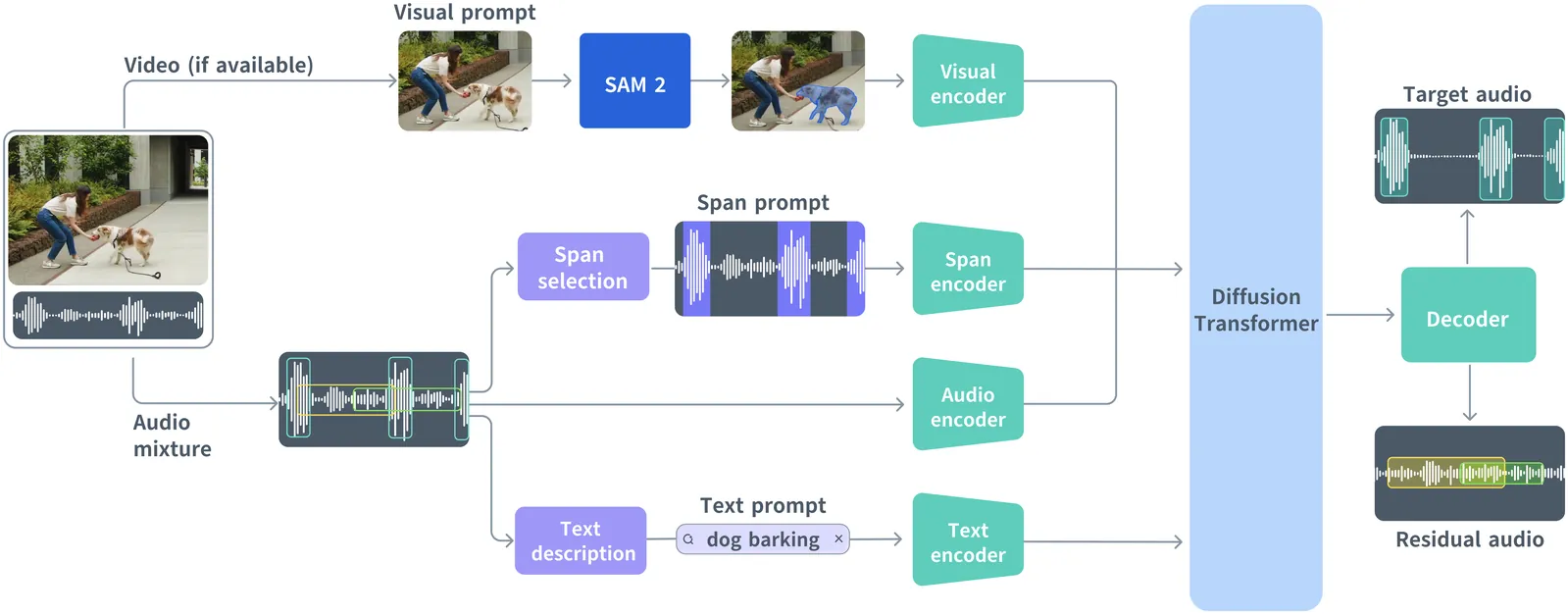
General audio source separation is a key capability for multimodal AI systems that can perceive and reason about sound. Despite substantial progress in recent years, existing separation models are either domain-specific, designed for fixed categories such as speech or music, or limited in controllability, supporting only a single prompting modality such as text. In this work, we present SAM Audio, a foundation model for general audio separation that unifies text, visual, and temporal span prompting within a single framework. Built on a diffusion transformer architecture, SAM Audio is trained with flow matching on large-scale audio data spanning speech, music, and general sounds, and can flexibly separate target sources described by language, visual masks, or temporal spans. The model achieves state-of-the-art performance across a diverse suite of benchmarks, including general sound, speech, music, and musical instrument separation in both in-the-wild and professionally produced audios, substantially outperforming prior general-purpose and specialized systems. Furthermore, we introduce a new real-world separation benchmark with human-labeled multimodal prompts and a reference-free evaluation model that correlates strongly with human judgment.
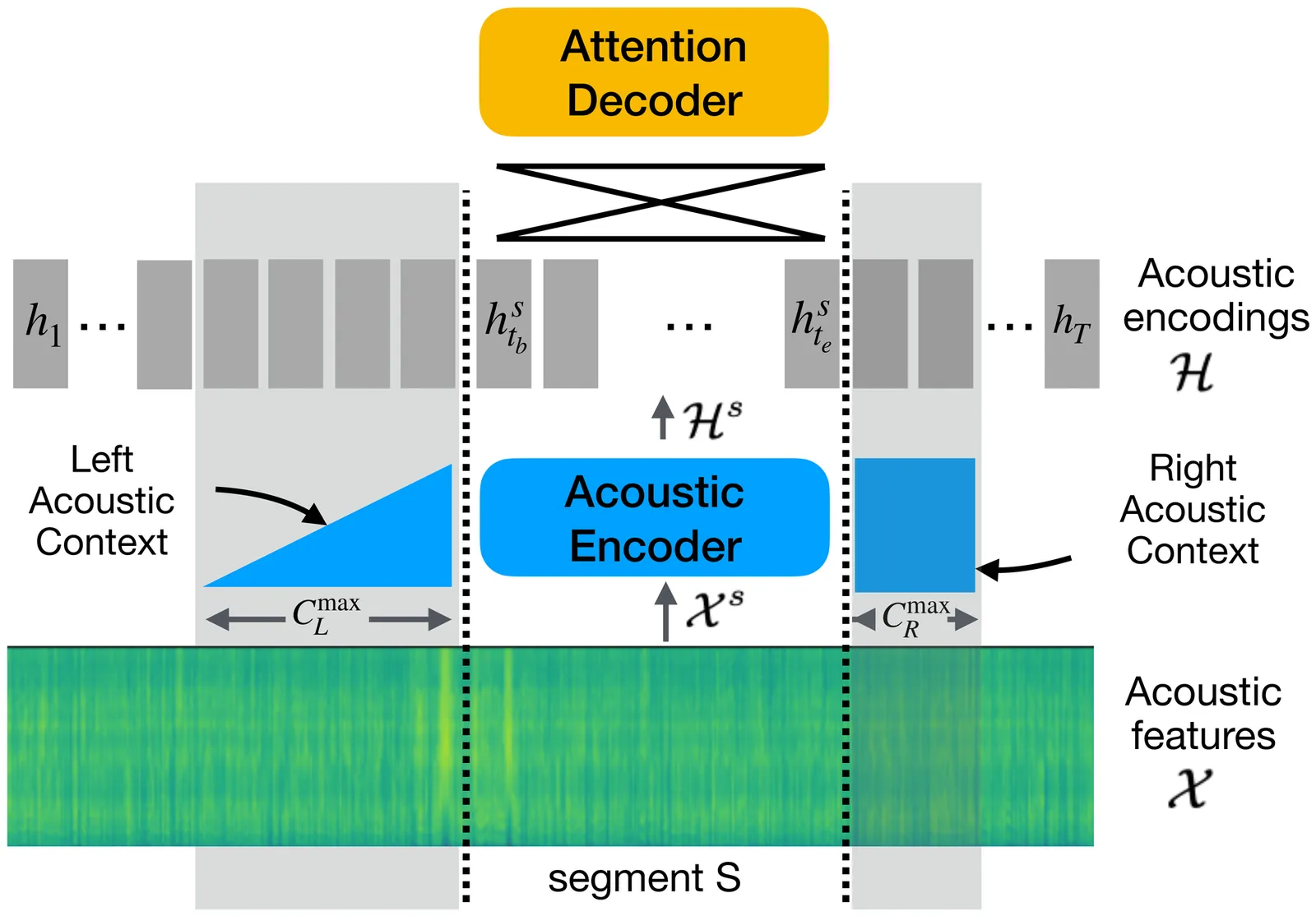
We address the fundamental incompatibility of attention-based encoder-decoder (AED) models with long-form acoustic encodings. AED models trained on segmented utterances learn to encode absolute frame positions by exploiting limited acoustic context beyond segment boundaries, but fail to generalize when decoding long-form segments where these cues vanish. The model loses ability to order acoustic encodings due to permutation invariance of keys and values in cross-attention. We propose four modifications: (1) injecting explicit absolute positional encodings into cross-attention for each decoded segment, (2) long-form training with extended acoustic context to eliminate implicit absolute position encoding, (3) segment concatenation to cover diverse segmentations needed during training, and (4) semantic segmentation to align AED-decoded segments with training segments. We show these modifications close the accuracy gap between continuous and segmented acoustic encodings, enabling auto-regressive use of the attention decoder.

The practical deployment of Audio-Visual Speech Recognition (AVSR) systems is fundamentally challenged by significant performance degradation in real-world environments, characterized by unpredictable acoustic noise and visual interference. This dissertation posits that a systematic, hierarchical approach is essential to overcome these challenges, achieving the robust scalability at the representation, architecture, and system levels. At the representation level, we investigate methods for building a unified model that learns audio-visual features inherently robust to diverse real-world corruptions, thereby enabling generalization to new environments without specialized modules. To address architectural scalability, we explore how to efficiently expand model capacity while ensuring the adaptive and reliable use of multimodal inputs, developing a framework that intelligently allocates computational resources based on the input characteristics. Finally, at the system level, we present methods to expand the system's functionality through modular integration with large-scale foundation models, leveraging their powerful cognitive and generative capabilities to maximize final recognition accuracy. By systematically providing solutions at each of these three levels, this dissertation aims to build a next-generation, robust, and scalable AVSR system with high reliability in real-world applications.
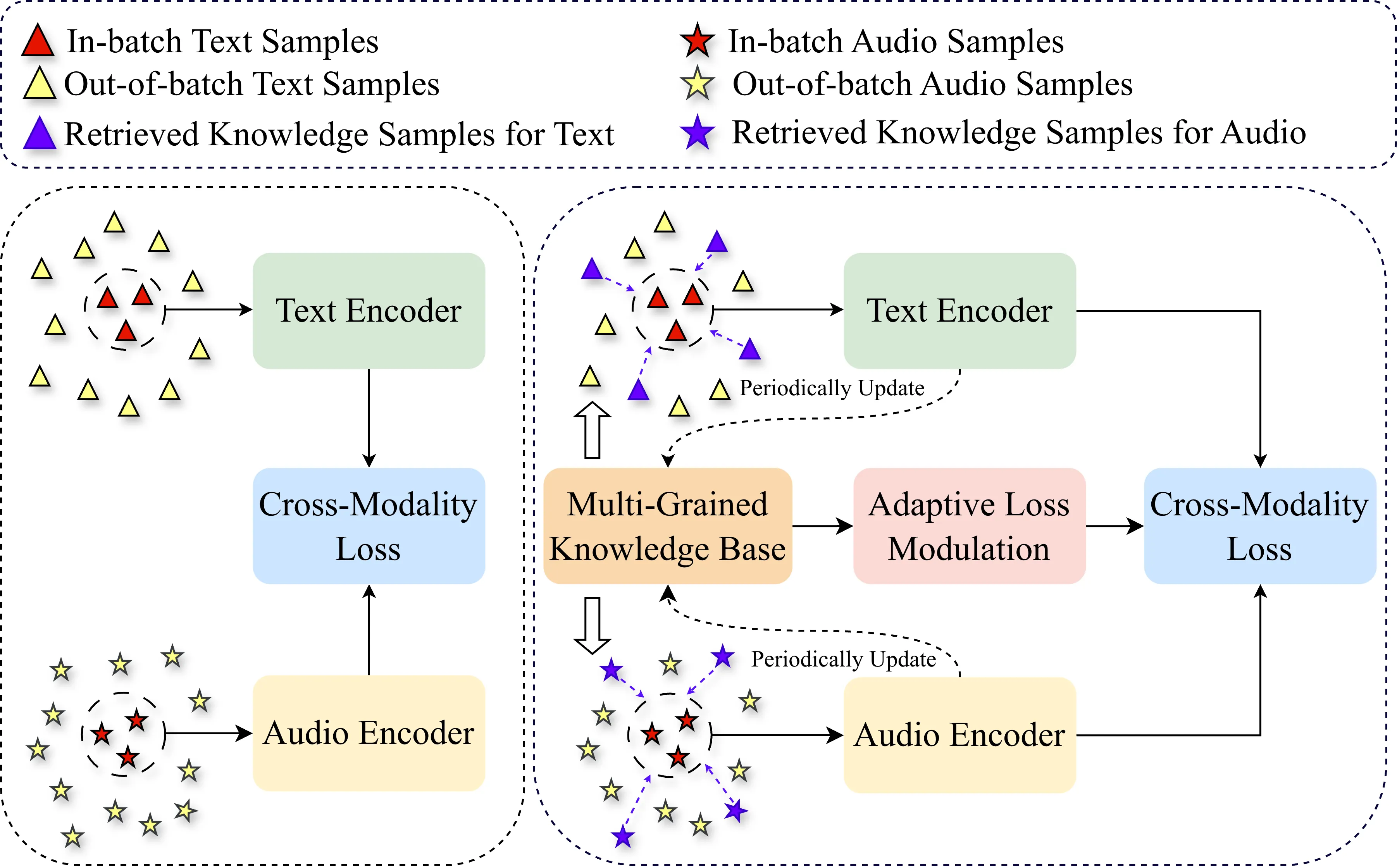
The dominant paradigm for Audio-Text Retrieval (ATR) relies on mini-batch-based contrastive learning. This process, however, is inherently limited by what we formalize as the Gradient Locality Bottleneck (GLB), which structurally prevents models from leveraging out-of-batch knowledge and thus impairs fine-grained and long-tail learning. While external knowledge-enhanced methods can alleviate the GLB, we identify a critical, unaddressed side effect: the Representation-Drift Mismatch (RDM), where a static knowledge base becomes progressively misaligned with the evolving model, turning guidance into noise. To address this dual challenge, we propose the Adaptive Self-improving Knowledge (ASK) framework, a model-agnostic, plug-and-play solution. ASK breaks the GLB via multi-grained knowledge injection, systematically mitigates RDM through dynamic knowledge refinement, and introduces a novel adaptive reliability weighting scheme to ensure consistent knowledge contributes to optimization. Experimental results on two benchmark datasets with superior, state-of-the-art performance justify the efficacy of our proposed ASK framework.
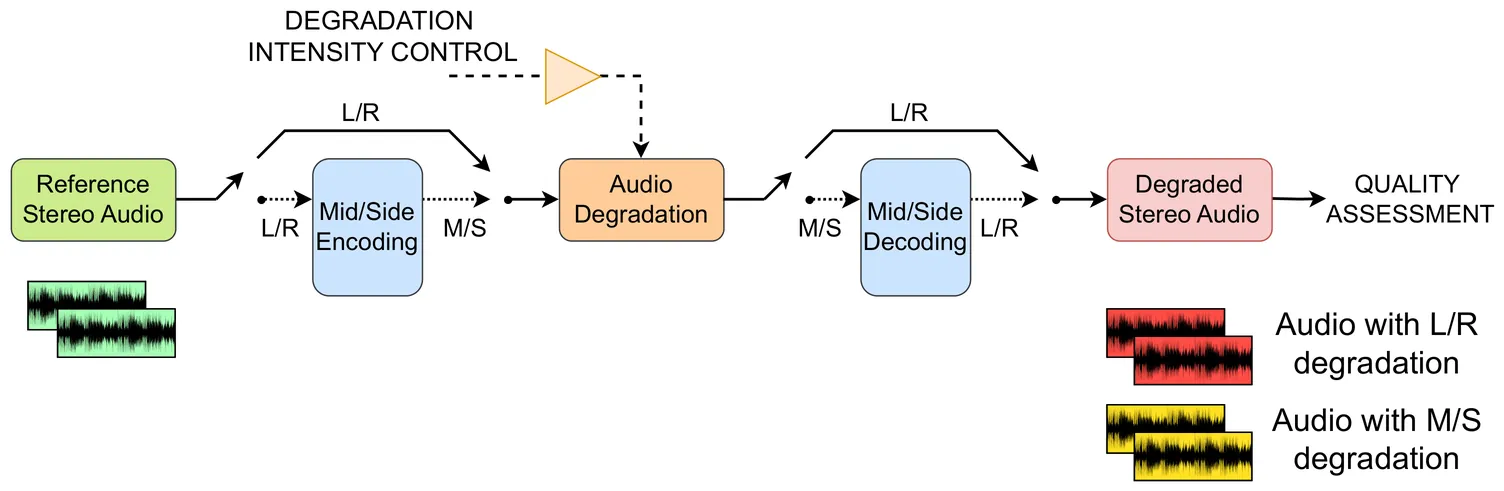
ODAQ (Open Dataset of Audio Quality) provides a comprehensive framework for exploring both monaural and binaural audio quality degradations across a range of distortion classes and signals, accompanied by subjective quality ratings. A recent update of ODAQ, focusing on the impact of stereo processing methods such as Mid/Side (MS) and Left/Right (LR), provides test signals and subjective ratings for the in-depth investigation of state-of-the-art objective audio quality metrics. Our evaluation results suggest that, while timbre-focused metrics often yield robust results under simpler conditions, their prediction performance tends to suffer under the conditions with a more complex presentation context. Our findings underscore the importance of modeling the interplay of bottom-up psychoacoustic processes and top-down contextual factors, guiding future research toward models that more effectively integrate both timbral and spatial dimensions of perceived audio quality.
Zero-shot text-to-speech models can clone a speaker's timbre from a short reference audio, but they also strongly inherit the speaking style present in the reference. As a result, synthesizing speech with a desired style often requires carefully selecting reference audio, which is impractical when only limited or mismatched references are available. While recent controllable TTS methods attempt to address this issue, they typically rely on absolute style targets and discrete textual prompts, and therefore do not support continuous and reference-relative style control. We propose ReStyle-TTS, a framework that enables continuous and reference-relative style control in zero-shot TTS. Our key insight is that effective style control requires first reducing the model's implicit dependence on reference style before introducing explicit control mechanisms. To this end, we introduce Decoupled Classifier-Free Guidance (DCFG), which independently controls text and reference guidance, reducing reliance on reference style while preserving text fidelity. On top of this, we apply style-specific LoRAs together with Orthogonal LoRA Fusion to enable continuous and disentangled multi-attribute control, and introduce a Timbre Consistency Optimization module to mitigate timbre drift caused by weakened reference guidance. Experiments show that ReStyle-TTS enables user-friendly, continuous, and relative control over pitch, energy, and multiple emotions while maintaining intelligibility and speaker timbre, and performs robustly in challenging mismatched reference-target style scenarios.
Modeling fine-grained speaking styles remains challenging for language-speech representation pre-training, as existing speech-text models are typically trained with coarse captions or task-specific supervision, and scalable fine-grained style annotations are unavailable. We present FCaps, a large-scale dataset with fine-grained free-text style descriptions, encompassing 47k hours of speech and 19M fine-grained captions annotated via a novel end-to-end pipeline that directly grounds detailed captions in audio, thereby avoiding the error propagation caused by LLM-based rewriting in existing cascaded pipelines. Evaluations using LLM-as-a-judge demonstrate that our annotations surpass existing cascaded annotations in terms of correctness, coverage, and naturalness. Building on FCaps, we propose CLSP, a contrastive language-speech pre-trained model that integrates global and fine-grained supervision, enabling unified representations across multiple granularities. Extensive experiments demonstrate that CLSP learns fine-grained and multi-granular speech-text representations that perform reliably across global and fine-grained speech-text retrieval, zero-shot paralinguistic classification, and speech style similarity scoring, with strong alignment to human judgments. All resources will be made publicly available.
Existing dominant methods for audio generation include Generative Adversarial Networks (GANs) and diffusion-based methods like Flow Matching. GANs suffer from slow convergence and potential mode collapse during training, while diffusion methods require multi-step inference that introduces considerable computational overhead. In this work, we introduce Flow2GAN, a two-stage framework that combines Flow Matching training for learning generative capabilities with GAN fine-tuning for efficient few-step inference. Specifically, given audio's unique properties, we first improve Flow Matching for audio modeling through: 1) reformulating the objective as endpoint estimation, avoiding velocity estimation difficulties when involving empty regions; 2) applying spectral energy-based loss scaling to emphasize perceptually salient quieter regions. Building on these Flow Matching adaptations, we demonstrate that a further stage of lightweight GAN fine-tuning enables us to obtain one-step generator that produces high-quality audio. In addition, we develop a multi-branch network architecture that processes Fourier coefficients at different time-frequency resolutions, which improves the modeling capabilities compared to prior single-resolution designs. Experimental results indicate that our Flow2GAN delivers high-fidelity audio generation from Mel-spectrograms or discrete audio tokens, achieving better quality-efficiency trade-offs than existing state-of-the-art GAN-based and Flow Matching-based methods. Online demo samples are available at https://flow2gan.github.io, and the source code is released at https://github.com/k2-fsa/Flow2GAN.
Many existing audio processing and generation models rely on task-specific architectures, resulting in fragmented development efforts and limited extensibility. It is therefore promising to design a unified framework capable of handling multiple tasks, while providing robust instruction and audio understanding and high-quality audio generation. This requires a compatible paradigm design, a powerful backbone, and a high-fidelity audio reconstruction module. To meet these requirements, this technical report introduces QuarkAudio, a decoder-only autoregressive (AR) LM-based generative framework that unifies multiple tasks. The framework includes a unified discrete audio tokenizer, H-Codec, which incorporates self-supervised learning (SSL) representations into the tokenization and reconstruction process. We further propose several improvements to H-Codec, such as a dynamic frame-rate mechanism and extending the audio sampling rate to 48 kHz. QuarkAudio unifies tasks by using task-specific conditional information as the conditioning sequence of the decoder-only LM, and predicting discrete target audio tokens in an AR manner. The framework supports a wide range of audio processing and generation tasks, including speech restoration (SR), target speaker extraction (TSE), speech separation (SS), voice conversion (VC), and language-queried audio source separation (LASS). In addition, we extend downstream tasks to universal free-form audio editing guided by natural language instructions (including speech semantic editing and audio event editing). Experimental results show that H-Codec achieves high-quality audio reconstruction with a low frame rate, improving both the efficiency and performance of downstream audio generation, and that QuarkAudio delivers competitive or comparable performance to state-of-the-art task-specific or multi-task systems across multiple tasks.
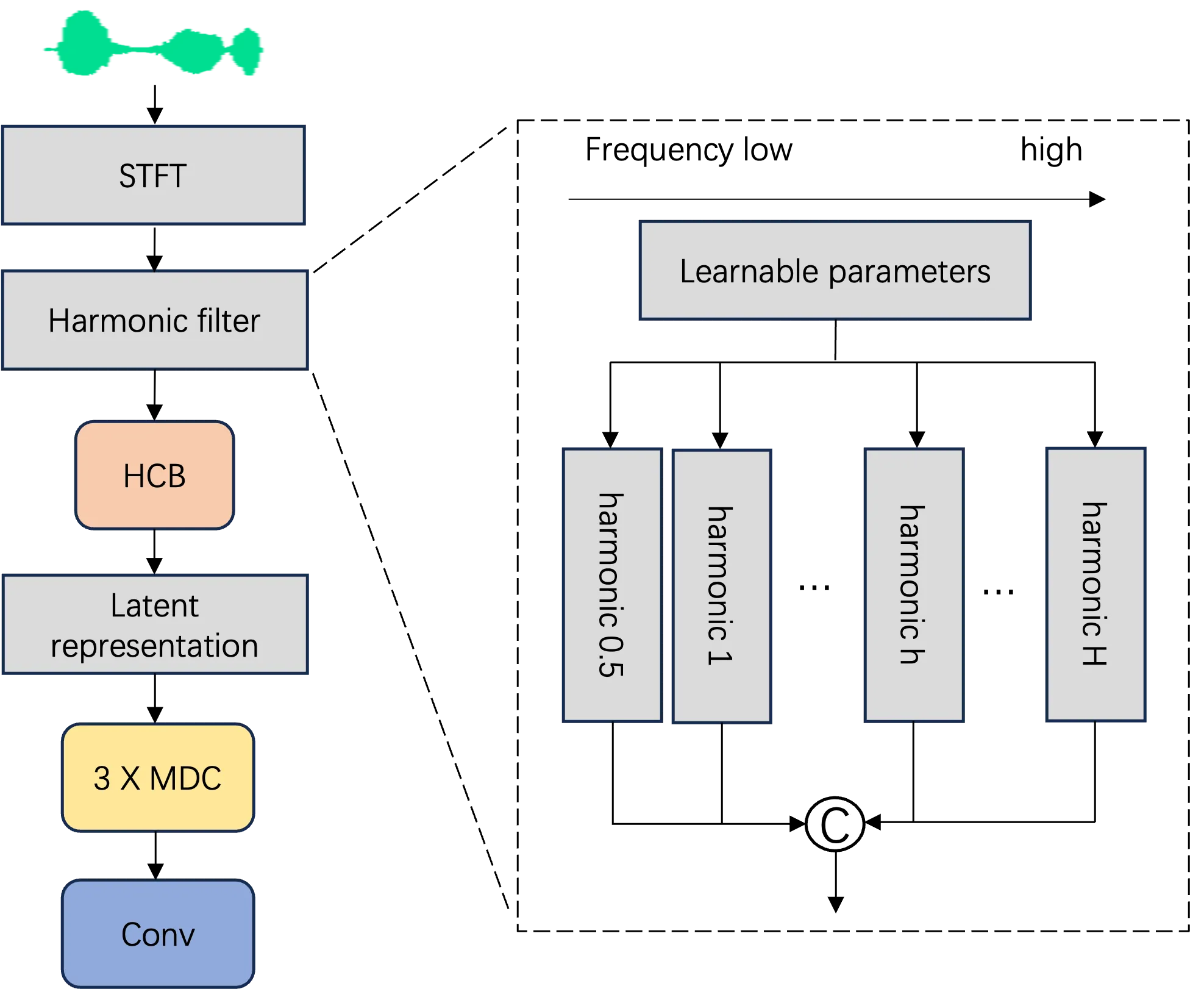
With the emergence of GAN-based vocoders, the discriminator, as a crucial component, has been developed recently. In our work, we focus on improving the time-frequency based discriminator. Particularly, Short-Time Fourier Transform (STFT) representation is usually used as input of time-frequency based discriminator. However, the STFT spectrogram has the same frequency resolution at different frequency bins, which results in an inferior performance, especially for singing voices. Motivated by this, we propose a universal harmonic discriminator for dynamic frequency resolution modeling and harmonic tracking. Specifically, we design a harmonic filter with learnable triangular band-pass filter banks, where each frequency bin has a flexible bandwidth. Additionally, we add a half-harmonic to capture fine-grained harmonic relationships at low-frequency band. Experiments on speech and singing datasets validate the effectiveness of the proposed discriminator on both subjective and objective metrics.
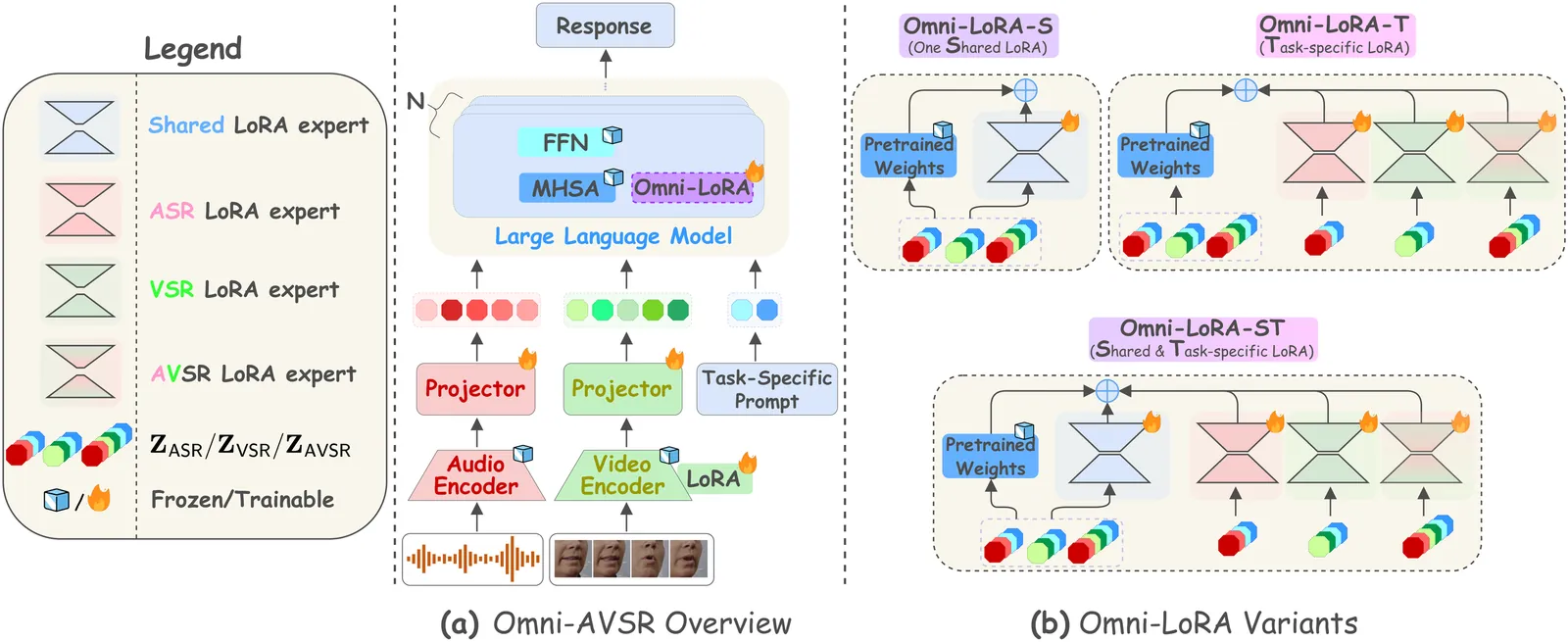
Large language models (LLMs) have recently achieved impressive results in speech recognition across multiple modalities, including Auditory Speech Recognition (ASR), Visual Speech Recognition (VSR), and Audio-Visual Speech Recognition (AVSR). Despite this progress, current LLM-based approaches typically address each task independently, training separate models that raise computational and deployment resource use while missing potential cross-task synergies. They also rely on fixed-rate token compression, which restricts flexibility in balancing accuracy with efficiency. These limitations highlight the need for a unified framework that can support ASR, VSR, and AVSR while enabling elastic inference. To this end, we present Omni-AVSR, a unified audio-visual LLM that combines efficient multi-granularity training with parameter-efficient adaptation. Specifically, we adapt the matryoshka representation learning paradigm to efficiently train across multiple audio and visual granularities, reducing its inherent training resource use. Furthermore, we explore three LoRA-based strategies for adapting the backbone LLM, balancing shared and task-specific specialization. Experiments on LRS2 and LRS3 show that Omni-AVSR achieves comparable or superior accuracy to state-of-the-art baselines while training a single model at substantially lower training and deployment resource use. The model also remains robust under acoustic noise, and we analyze its scaling behavior as LLM size increases, providing insights into the trade-off between performance and efficiency.